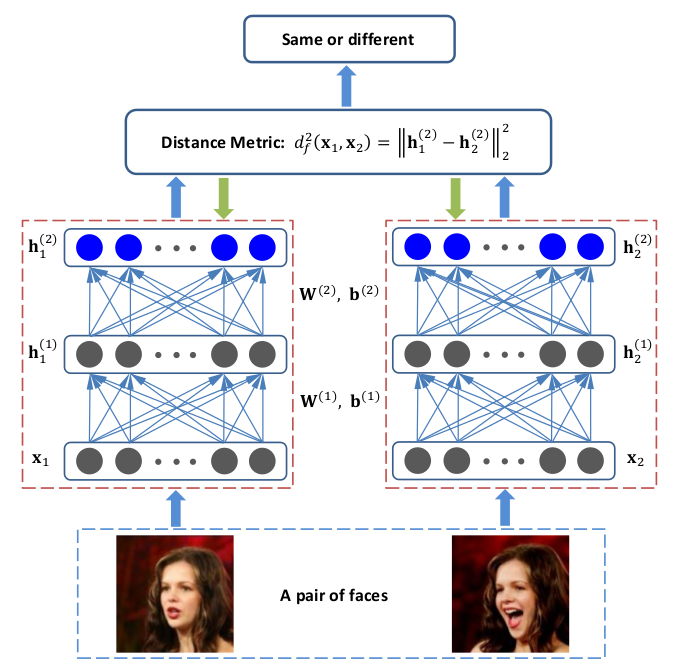
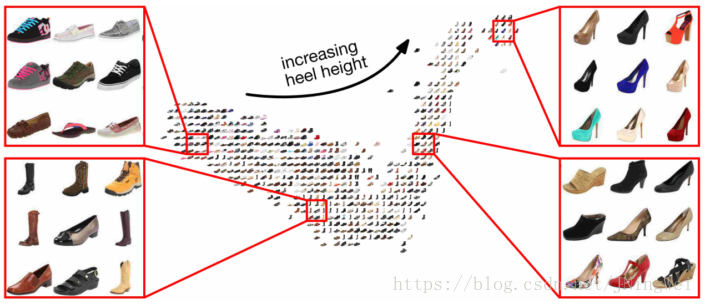
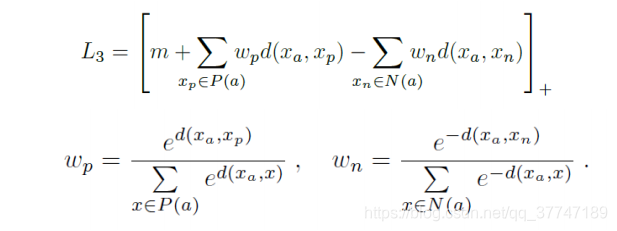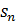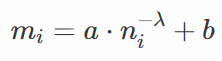度量学习是学习一种特征空间的映射,把特征映射到具有度量属性的空间中,所谓度量属性是指在某种度量距离(可以是欧氏距离、余弦相似性等)下类内距离更小,类间距离更大。有了这种属性之后,就可以仅根据特征间的距离来判断样本是否属于同一类,常用在少样本学习任务中,解决由于样本数量少而无法或不足以建立从特征到类别的参数化映射的问题。有一个开源的度量学习库pytorch-metric-learning,集成了当前常用的各种度量学习方法,是一个非常好用的工具。
度量学习作为一个大领域,网上有不少介绍的文章,pytorch-metric-learning库的官方文档也有比较详细的说明和demo,所以本文不打算再对它们做细致严谨的入门级介绍,而是记录我在学习过程中的一些思考和观点,以及代码的便捷使用,欢迎讨论。
1 度量学习的主要原理
如前所述,度量学习的目的是把特征约束到具有度量属性的空间中。
首先什么是特征?通常我们认为,深度学习网络中(如ResNet50),前面的卷积部分作用是逐层深入的提取越来越高级的特征,最后的全连接层的作用则是建立特征到具体类别间的规则关系。那么我们度量学习要处理的特征当然应该选择经卷积层完全处理完毕,输入给全连接网络的这层特征,如果这层特征的维度太高而导致运算量太大(如ResNet50的卷积层最后输出有2048通道),也可以先用全连接层降维。我们把这层特征提取出来,通常称为嵌入特征embbeding features。
然后是如何约束?神经网络通过加入损失函数作为约束条件,以类别标签作为监督信息,使用监督学习的方法训练网络参数,使网络输出的嵌入特征逐渐满足约束条件。所谓约束条件就是指类内距离小、类间距离大,那么损失函数就是要满足这两个目标,但具体设计起来仍有很多技术在里面,主要是怎么让训练收敛更快、更稳定,收敛的结果更好。
2 几种损失函数
2.1 Contrastive Loss
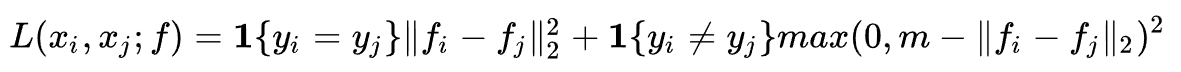
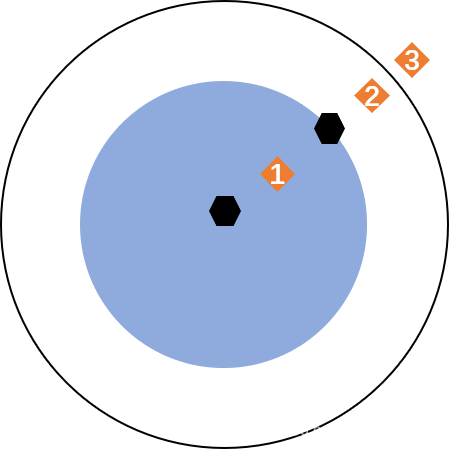
只考虑两两之间的类别和距离。注意其中加入margin的思路(即max(0,margin-loss)的方式),我觉得这个思路很有意思,值得学习。我理解加入margin的目的是这样的:因为我们优化类间距离的目的是越大越好,而通常损失函数在梯度下降算法中是趋向于越来越小的,所以必须让损失函数也变成一个减函数,如果我们直接取一个负号,则会让损失函数变成一个负的特别大的数,这通常会导致训练不稳定。而且我们也不需要类间距离非常大,只要大于一定值能够和类内距离明显区分就可以了,所以这里加入一个margin,让目标函数限定到(0,margin)区间内,避免训练不稳定。在网络设计中我们经常也会遇到想让一个目标函数越来越大的情况,我觉得可以尝试这种取负号再加margin的方案,当然另一种思路是取倒数,即1/loss,我没对比过哪个更有效,以后有机会可以试一试。
2.2 Triplet Loss
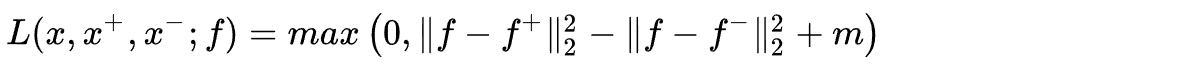
考虑三元组,锚样本、正样本和负样本之间的互相距离。由于每次同时考虑了正样本对和负样本对的距离都满足约束关系,训练效率比Contrastive loss要高。注意Triplet loss的目的是让类间距离比类内距离更大,对应的也是一个越大越好的目标函数,这里也使用了取负号再加margin并截断负值的思路把它变成一个区间减函数形式的损失函数。
2.3 更多损失函数
在Triplet loss之后,又发展出来了各种各样更多的损失函数,如N-pair Loss, ranklist loss, multisimilarity loss ,cirlce loss等,总的趋势是考虑更多的对之间的距离关系,并考虑各样本学习的难易不同,提高难例的权重。circle loss还考虑了类别标签的使用,也就是综合了分类损失。
2.4 在pytorch-metric-learning中使用各种损失函数
使用pip install pytorch-metric-learning安装该库,支持的多种损失函数可查阅pytorch-metric-learning的官方文档。如果对各种损失函数不太了解,直接使用Circle loss就好了。
from pytorch_metric_learning import losses
loss_func = losses.CircleLoss()
for data, labels in train_loader:embeddings,_ = model(data)loss = loss_func(embeddings, labels)
注意默认的度量距离使用余弦相似性,如不特殊指定的话,也应在推理阶段使用余弦相似性对生成的嵌入特征进行处理。
3 难例挖掘方法
我们可以看到,在当前度量学习的损失函数设计中都是含有margin的,那么网络在学习的时候对于易例,损失函数已经能够达到margin的程度,梯度会变成0,就不会再对网络有任何训练的作用了,只有那些难例,梯度较大,才会对网络起到较大的训练作用,所以为了提高训练效率,需要只把难例加入训练。pytorch-metric-learning库提供的挖掘方法在miners文件中,有很多,具体可以查看官方文档。我在未经充分试验的情况下发现MultiSimilarityMiner效果不错,如果对各种挖掘方法不是很了解,可以先用这个。加入之后的训练方法如下:
from pytorch_metric_learning import losses, miners
loss_func = losses.CircleLoss()
mining_func = miners.MultiSimilarityMiner()
for data, labels in train_loader:embeddings,_ = model(data)hard_tuples = mining_func(embeddings, labels)loss = loss_func(embeddings, labels, hard_tuples)
4 采样器设计
如果训练样本的类别较多的时候,随机采样的话可能在一个mini batch内遇不到几个正样本对,例如有100类,而batch size只有64。而损失函数设计都是考虑到正样本对的,这会导致训练效果受很大影响,所以要调整采样器,保证一个mini batch内有一定比例的正样本对,比如可以指定每一类都固定采样m个样本,通常m=4效果较好,这样batch size = 64时,每次能够采样16类,每类4个样本。pytorch-metric-learning库中集成了一个采样器MPerClassSampler,它对torch.utils.data.sampler修改而来,调用方法如下:
from pytorch_metric_learning import samplers
sampler = samplers.MPerClassSampler(labels, m=4,length_before_new_iter=len(train_dataset))
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size,sampler=sampler, **kwargs)
还有其他一些采样器可参考官方文档,如果还需要给采样器加入更多的功能,比如在MPerClassSampler的基础上还想保证训练的时候各类别平衡采样以解决长尾问题,可以再魔改一下官方MPerClassSampler代码文件,也不难。
5 度量-分类联合训练
度量学习只考虑一对数据是否是同类或异类,并不考虑每个数据具体是哪一类,显然它没有充分利用标签提供的信息。所以如果只用度量学习的损失函数进行训练,网络提取的特征不充分,如果同时加入全连接层构成的分类器,并使用交叉熵损失接受标签的分类监督信息,可以提高网络的特征提取能力。(circle loss可以部分弥补这一点,但仍没有加入分类联合训练效果好)
from pytorch import nn
from pytorch_metric_learning import losses, miners
loss_func = losses.CircleLoss()
mining_func = miners.MultiSimilarityMiner()
criterion = nn.CrossEntropyLoss()
for data, labels in train_loader:embeddings,out = model(data)hard_tuples = mining_func(embeddings, labels)loss1 = loss_func(embeddings, labels, hard_tuples)loss2 = criterion(out,labels)loss = 0.1*loss1 + loss2
代码中的embeddings指嵌入层特征,out指网络最后和类别数同维度的输出。
6 度量学习的思考
1,为什么度量学习能够泛化?它有多强的泛化能力?
度量学习常被用在少样本学习领域,因为它在已知类别上训练完成的度量空间映射能力同样可以在未知类别上使用。这是因为度量学习通过同类和异类的对比,把数据集中共性特征放大,个性特征抑制,而分类学习更关注对每类的个性特征,所以相比度量学习有更好的泛化能力。而如果测试集和训练集不仅存在类别差异,还存在特征分布差异(域偏差)的时候,度量学习也不能够泛化。
2,度量学习在推理阶段仅使用样本间的距离进行判断,显然浪费了特征中蕴含的很多信息量,并不是一种最优方案。
更理想的方案应该是并不对特征压缩转换为单维度的标量(如距离),仍使用特征丰富的全维度信息进行推理。比如可以使用一个fc层或多fc层的MLP网络来实现对特征到某个单类的规则映射,这个fc层的参数不使用梯度下降训练法得到(只有少样本也很难训练),而是解方程得到一个最小二乘解,这个方法也许会有更好的效果,先放到这里,有待后续研究。