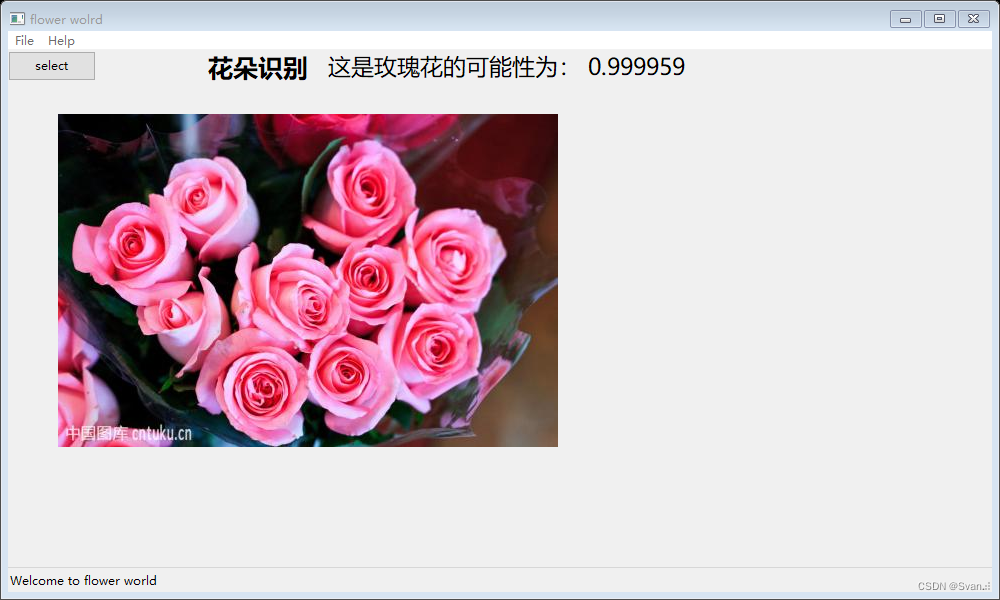
AlexNet实现花卉识别
本人水平有限,如有错误,欢迎指出!
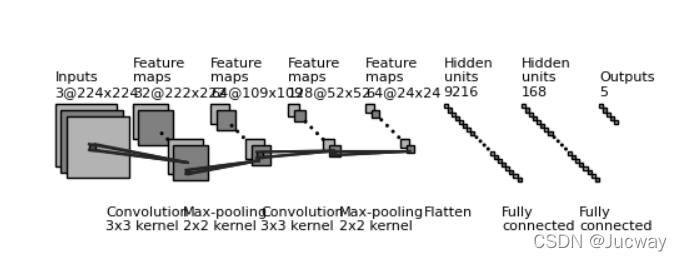
1. AlexNet
1.1 简介
AlexNet是由UToronto的Alex Krizhevsky、Hinton等人在2012年提出的8层神经网络模型,并获得了ILSVRC12挑战赛ImageNet数据集分类任务的冠军,并推动了神经网络朝更深层的网络模型发展。
1.2 网络结构
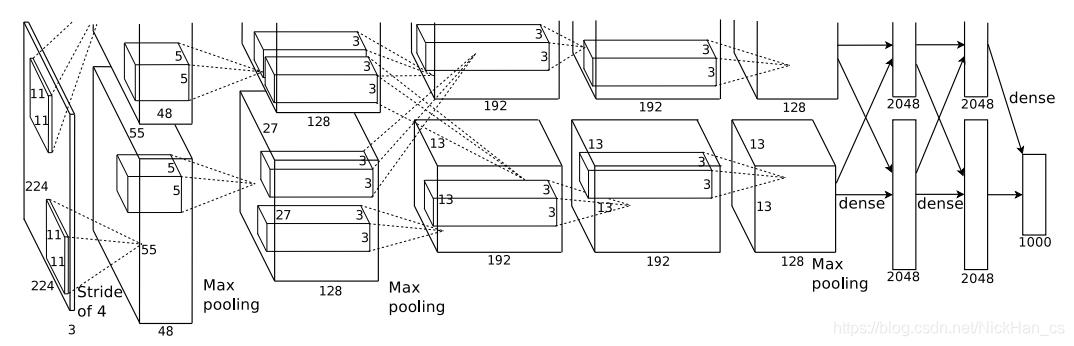
AlexNet整体上包含8层,前5层是卷积层,后3层是全连接层。但由于当时计算机硬件性能有限,所以用了两块GPU来跑,而现在的计算机水平可以在单CPU或单GPU上跑(但实践表明,1050Ti的显卡还是跑不动,所以之后就用CPU跑了)。
以上是最初的AlexNet网络模型,但是实战部分采用的数据集图片格式是171 * 171 * 3,并实现5分类,所以需要对网络结构进行调整
(数据集可从https://github.com/NickHan-cs/Deep_Learning_Datasets上下载)
本题采用的网络结构:
图片输入:171 * 171 * 3
卷积层1:使用48个9 * 9 * 3的过滤器,步长为3,padding为valid,输出的图像为55 * 55 * 48,激活函数是relu
最大池化层1:使用3 * 3的过滤器,步长为2,输出图像为27 * 27 * 48
BatchNormalization层1
卷积层2:使用128个5 * 5 * 48的过滤器,步长为1,padding为same,输出的图像为27 * 27 * 128,激活函数是relu
最大池化层2:使用3 * 3的过滤器,步长为2,输出的图像为13 * 13 * 128
卷积层3:使用192个3 * 3 * 128的过滤器,步长为1,padding为same,输出的图像为13 * 13 * 192,激活函数是relu
卷积层4:使用192个3 * 3 * 192的过滤器,步长为1,padding为same,输出的图像为13 * 13 * 192,激活函数是relu
卷积层5:使用128个3 * 3 * 192的过滤器,步长为1,padding为same,输出的图像为13 * 13 * 128,激活函数是relu
最大池化层3:使用3 * 3的过滤器,步长为2,输出的图像为6 * 6 * 128
Flatten层:将图像从3维展平为1维
全连接层:2048个神经元,激活函数是relu
Dropout层:比例为0.5
全连接层:256个神经元,激活函数是relu
Dropout层:比例为0.5
全连接层:5个神经元,激活函数是softmax
2. Tensorflow2实现AlexNet
2.1 读取数据
下载数据集并保存至本地后,通过函数read_img读取数据集。由于不同图片的尺寸不同,统一尺寸为171 * 171 * 3,并将像素缩小到0~1,便于训练。
def read_img(path):imgs = []labels = []cate = [path+x for x in os.listdir(path) if os.path.isdir(path+x)]for index, i in enumerate(cate):for j in os.listdir(i):im = cv2.imread(i + '/' + j)img1 = cv2.resize(im, (171, 171)) / 255imgs.append(img1)labels.append(index)return np.asarray(imgs, np.float32), np.asarray(labels, np.int32)path = r'D:/TensorFlow_datasets/flower_photos/'
data, label = read_img(path)
2.2 划分训练集和测试集
打乱读取的数据集的顺序,取80%作为训练集,20%作为测试集
num_example = data.shape[0]
arr = np.arange(num_example)
np.random.shuffle(arr)
data = data[arr]
label = label[arr]
ratio = 0.8
s = np.int(num_example * ratio)
train_data = data[:s]
train_label = label[:s]
test_data = data[s:]
test_label = label[s:]
2.3 训练集数据增强
在数据集有限的情况下,可以通过数据增强来帮助训练神经网络模型。在本题中,将训练集的每一张图进行水平和垂直的镜像对称产生新的图片,并加入到训练集中,然后再随机打乱顺序,产生最终的训练集。
def data_augmentation(train_imgs, train_labels):final_imgs = []final_labels = []for i in range(train_imgs.shape[0]):img = train_imgs[i]label = train_labels[i]final_imgs.append(img)final_labels.append(label)img1 = tf.image.flip_left_right(img).numpy()final_imgs.append(img1)final_labels.append(label)img2 = tf.image.flip_up_down(img).numpy()final_imgs.append(img2)final_labels.append(label)return np.asarray(final_imgs, np.float32), np.asarray(final_labels, np.int32)train_data, train_label = data_augmentation(train_data, train_label)
num_example = train_data.shape[0]
arr = np.arange(num_example)
np.random.shuffle(arr)
train_data = train_data[arr]
train_label = train_label[arr]
2.4 网络搭建
根据修改后的AlexNet网络结构搭建神经网络,通过继承tf.keras.Model这个类来定义模型。
class AlexNet(tf.keras.Model):def __init__(self):super().__init__()self.conv1 = tf.keras.layers.Conv2D(filters=48,kernel_size=[9, 9],strides=3,activation=tf.nn.relu,padding='valid')self.pool1 = tf.keras.layers.MaxPooling2D(pool_size=[3, 3], strides=2, padding='valid')self.bn1 = tf.keras.layers.BatchNormalization()self.conv2 = tf.keras.layers.Conv2D(filters=128,kernel_size=[5, 5],strides=1,activation=tf.nn.relu,padding='same')self.pool2 = tf.keras.layers.MaxPooling2D(pool_size=[3, 3], strides=2, padding='valid')self.bn2 = tf.keras.layers.BatchNormalization()self.conv3 = tf.keras.layers.Conv2D(filters=192,kernel_size=[3, 3],strides=1,activation=tf.nn.relu,padding='same')self.conv4 = tf.keras.layers.Conv2D(filters=192,kernel_size=[3, 3],strides=1,activation=tf.nn.relu,padding='same')self.conv5 = tf.keras.layers.Conv2D(filters=128,kernel_size=[3, 3],strides=1,activation=tf.nn.relu,padding='same')self.pool3 = tf.keras.layers.MaxPooling2D(pool_size=[3, 3], strides=2, padding='valid')self.flatten = tf.keras.layers.Flatten()self.dense1 = tf.keras.layers.Dense(units=2048, activation=tf.nn.relu)self.drop1 = tf.keras.layers.Dropout(0.5)self.dense2 = tf.keras.layers.Dense(units=256, activation=tf.nn.relu)self.drop2 = tf.keras.layers.Dropout(0.5)self.dense3 = tf.keras.layers.Dense(units=5, activation=tf.nn.softmax)def call(self, inputs):x = self.conv1(inputs)x = self.pool1(x)x = self.bn1(x)x = self.conv2(x)x = self.pool2(x)x = self.bn2(x)x = self.conv3(x)x = self.conv4(x)x = self.conv5(x)x = self.pool3(x)x = self.flatten(x)x = self.dense1(x)x = self.drop1(x)x = self.dense2(x)x = self.drop2(x)x = self.dense3(x)return xmodel = AlexNet()
2.5 模型装配
在本模型中采用Adam优化算法,初始的学习率为1e-3,由于label采用的是数字编码,所以使用sparse_categorical_crossentropy。
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),loss=tf.keras.losses.sparse_categorical_crossentropy,metrics=[tf.keras.metrics.sparse_categorical_accuracy]
)
2.6 模型训练
在模型训练的过程中,每32组数据为1个batch,训练25次,并选出训练集10%的数据作为验证集,剩下的数据继续作为训练集。
在本模型中采取了学习率衰减机制,如果连续3次训练验证集分类的准确率没有提高,学习率就变为原先的0.2倍。同时,为了防止过拟合,模型中还采用了EarlyStopping机制,在连续6次训练时,如果验证集分类的准确率没有提高,就终止训练。
reduce_lr = tf.keras.callbacks.ReduceLROnPlateau(monitor='val_sparse_categorical_accuracy', factor=0.2, patience=3)
early_stopping = tf.keras.callbacks.EarlyStopping(monitor='val_sparse_categorical_accuracy', patience=6)
history = model.fit(train_data, train_label, batch_size=32, epochs=25, verbose=2, validation_split=0.1, callbacks=[reduce_lr, early_stopping])
2.7 测试效果
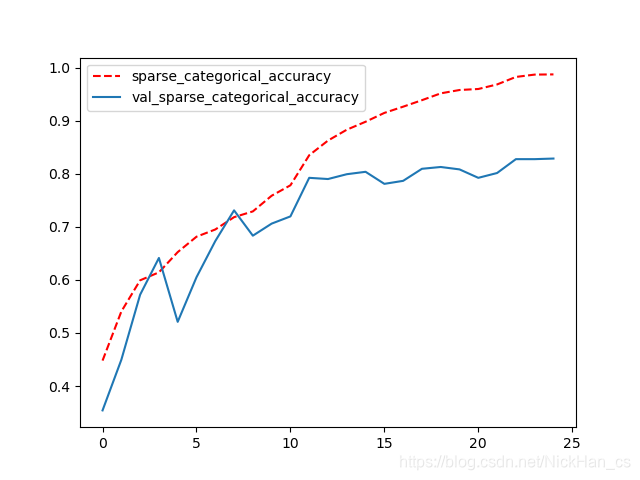
经过训练,花卉识别的准确率可达到78%以上,训练集与验证集的分类准确率变化过程和代码运行信息如下所示,完整代码可见https://github.com/NickHan-cs/Tensorflow2.x-Projects。
Epoch 1/25
248/248 - 99s - loss: 1.3392 - sparse_categorical_accuracy: 0.4480 - val_loss: 1.4327 - val_sparse_categorical_accuracy: 0.3541 - lr: 0.0010
Epoch 2/25
248/248 - 96s - loss: 1.1419 - sparse_categorical_accuracy: 0.5404 - val_loss: 1.4808 - val_sparse_categorical_accuracy: 0.4495 - lr: 0.0010
Epoch 3/25
248/248 - 105s - loss: 1.0248 - sparse_categorical_accuracy: 0.5992 - val_loss: 1.1228 - val_sparse_categorical_accuracy: 0.5721 - lr: 0.0010
Epoch 4/25
248/248 - 100s - loss: 0.9782 - sparse_categorical_accuracy: 0.6142 - val_loss: 0.9482 - val_sparse_categorical_accuracy: 0.6413 - lr: 0.0010
Epoch 5/25
248/248 - 95s - loss: 0.8944 - sparse_categorical_accuracy: 0.6523 - val_loss: 1.6296 - val_sparse_categorical_accuracy: 0.5210 - lr: 0.0010
Epoch 6/25
248/248 - 97s - loss: 0.8622 - sparse_categorical_accuracy: 0.6813 - val_loss: 1.0007 - val_sparse_categorical_accuracy: 0.6050 - lr: 0.0010
Epoch 7/25
248/248 - 96s - loss: 0.8047 - sparse_categorical_accuracy: 0.6950 - val_loss: 0.8723 - val_sparse_categorical_accuracy: 0.6731 - lr: 0.0010
Epoch 8/25
248/248 - 98s - loss: 0.7303 - sparse_categorical_accuracy: 0.7182 - val_loss: 0.7109 - val_sparse_categorical_accuracy: 0.7310 - lr: 0.0010
Epoch 9/25
248/248 - 96s - loss: 0.7205 - sparse_categorical_accuracy: 0.7290 - val_loss: 0.7903 - val_sparse_categorical_accuracy: 0.6833 - lr: 0.0010
Epoch 10/25
248/248 - 100s - loss: 0.6462 - sparse_categorical_accuracy: 0.7585 - val_loss: 0.9007 - val_sparse_categorical_accuracy: 0.7060 - lr: 0.0010
Epoch 11/25
248/248 - 98s - loss: 0.6075 - sparse_categorical_accuracy: 0.7782 - val_loss: 0.7761 - val_sparse_categorical_accuracy: 0.7196 - lr: 0.0010
Epoch 12/25
248/248 - 97s - loss: 0.4432 - sparse_categorical_accuracy: 0.8349 - val_loss: 0.5708 - val_sparse_categorical_accuracy: 0.7923 - lr: 2.0000e-04
Epoch 13/25
248/248 - 99s - loss: 0.3608 - sparse_categorical_accuracy: 0.8625 - val_loss: 0.6199 - val_sparse_categorical_accuracy: 0.7900 - lr: 2.0000e-04
Epoch 14/25
248/248 - 95s - loss: 0.3129 - sparse_categorical_accuracy: 0.8829 - val_loss: 0.5957 - val_sparse_categorical_accuracy: 0.7991 - lr: 2.0000e-04
Epoch 15/25
248/248 - 95s - loss: 0.2730 - sparse_categorical_accuracy: 0.8979 - val_loss: 0.5896 - val_sparse_categorical_accuracy: 0.8036 - lr: 2.0000e-04
Epoch 16/25
248/248 - 94s - loss: 0.2312 - sparse_categorical_accuracy: 0.9146 - val_loss: 0.6924 - val_sparse_categorical_accuracy: 0.7809 - lr: 2.0000e-04
Epoch 17/25
248/248 - 95s - loss: 0.2018 - sparse_categorical_accuracy: 0.9263 - val_loss: 0.6511 - val_sparse_categorical_accuracy: 0.7866 - lr: 2.0000e-04
Epoch 18/25
248/248 - 95s - loss: 0.1698 - sparse_categorical_accuracy: 0.9386 - val_loss: 0.6746 - val_sparse_categorical_accuracy: 0.8093 - lr: 2.0000e-04
Epoch 19/25
248/248 - 95s - loss: 0.1384 - sparse_categorical_accuracy: 0.9514 - val_loss: 0.7350 - val_sparse_categorical_accuracy: 0.8127 - lr: 2.0000e-04
Epoch 20/25
248/248 - 95s - loss: 0.1211 - sparse_categorical_accuracy: 0.9577 - val_loss: 0.7823 - val_sparse_categorical_accuracy: 0.8082 - lr: 2.0000e-04
Epoch 21/25
248/248 - 94s - loss: 0.1205 - sparse_categorical_accuracy: 0.9596 - val_loss: 0.8226 - val_sparse_categorical_accuracy: 0.7923 - lr: 2.0000e-04
Epoch 22/25
248/248 - 96s - loss: 0.0924 - sparse_categorical_accuracy: 0.9682 - val_loss: 0.7948 - val_sparse_categorical_accuracy: 0.8014 - lr: 2.0000e-04
Epoch 23/25
248/248 - 96s - loss: 0.0579 - sparse_categorical_accuracy: 0.9823 - val_loss: 0.7752 - val_sparse_categorical_accuracy: 0.8275 - lr: 4.0000e-05
Epoch 24/25
248/248 - 96s - loss: 0.0443 - sparse_categorical_accuracy: 0.9868 - val_loss: 0.7888 - val_sparse_categorical_accuracy: 0.8275 - lr: 4.0000e-05
Epoch 25/25
248/248 - 96s - loss: 0.0408 - sparse_categorical_accuracy: 0.9871 - val_loss: 0.8016 - val_sparse_categorical_accuracy: 0.8286 - lr: 4.0000e-05
23/23 - 2s - loss: 1.1473 - sparse_categorical_accuracy: 0.7861