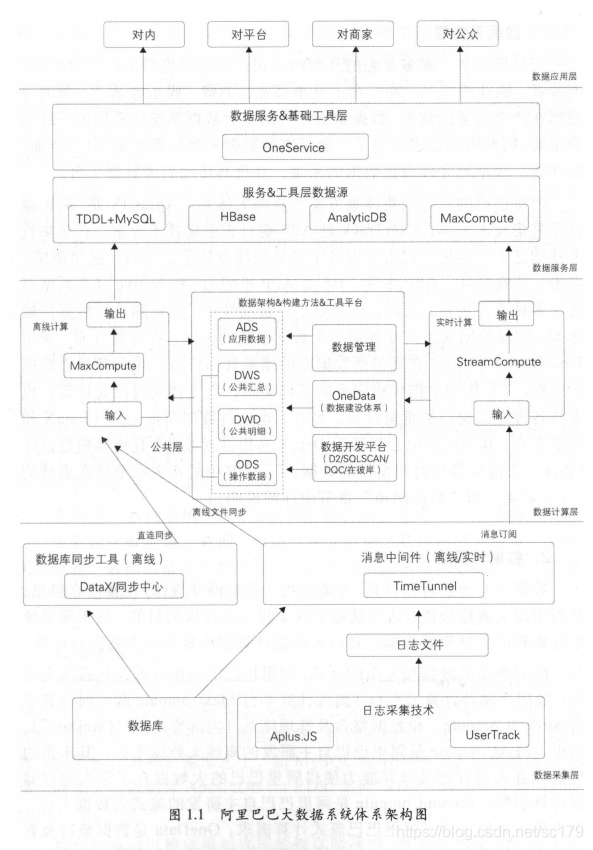
自从大数据出来后,数据管理界发生了巨大的变化,技术驱动成为大数据管理系统的一个主要变革力量。
传统的数据库管理系统以结构化数据为主,因此关系数据库系统(RDBMS)可以一统天下满足各类应用需求。然而,大数据往往是半结构化和非结构化数据为主,结构化数据为辅,而且各种大数据应用通常需要对不同类型的数据内容检索、交叉比对、深度挖掘与综合分析。面对这类应用需求,传统数据库无论在技术上还是功能上都难以为继。因此,近几年出现了oldSQL、NoSQL 与NewSQL 并存的局面。(这几个术语后面专题讨论)
总体上,按数据类型与计算方式的不同,面向大数据的管理系统与处理采用不同的技术路线,大致可以分为四类。
1、MPP并行数据库和内存数据库
第一类技术路线主要面对的是大规模的结构化数据。针对这类大数据,通常采用新型数据库集群。它们通过列存储或行列混合存储以及粗粒度索引等技术,结合MPP(Massive Parallel Processing)架构高效的分布式计算模式,实现对PB 量级数据的存储和管理。列存储数据库技术针对数据分析的特点,能够对数据进行高性能的压缩,查询也只需访问必要的列,节省了很多I/O,分析性能比传统行存储数据库有了很大的提升(可以多达两个数据量级)。
同时,随着内存成本的降低、单机内存的增大,以SAP HANA为代表的内存数据库也采用了列存储技术,支持更高性能的数据分析。这些技术的发展,使得它们成为TB级别数据仓库的最先进技术,已经涵盖了绝大多数OLAP市场,在企业分析类应用领域已获得广泛应用。
然而,MPP并行数据库和内存数据库依赖昂贵的硬件配置,其中的很多商业软件还有价格高昂的使用许可证,这些成本并不是每个公司都能够承担或者愿意承担的;而开源大数据系统采用通用、廉价的硬件设施,使得人们更容易尝试和使用这些系统,数据和业务迁移的成本也更低。同时,以Hadoop为代表的开源大数据系统形成较大的社区之后,就会有各种相关系统补充进来,构成生态圈,满足人们不同的需求,具有非常好的开放性。因此,就出现了第二类以Hadoop为典型的开源系统技术路线,并逐渐得到认可,并成为大数据分析的新宠儿。
2、基于Hadoop开源体系的大数据系统
第二类技术路线要面对的是半结构化和非结构化数据。应对这类应用场景,基于Hadoop开源体系的系统平台更为擅长。它们通过对Hadoop生态体系的技术扩展和封装,实现对半结构化和非结构化数据的存储、管理、计算等功能。
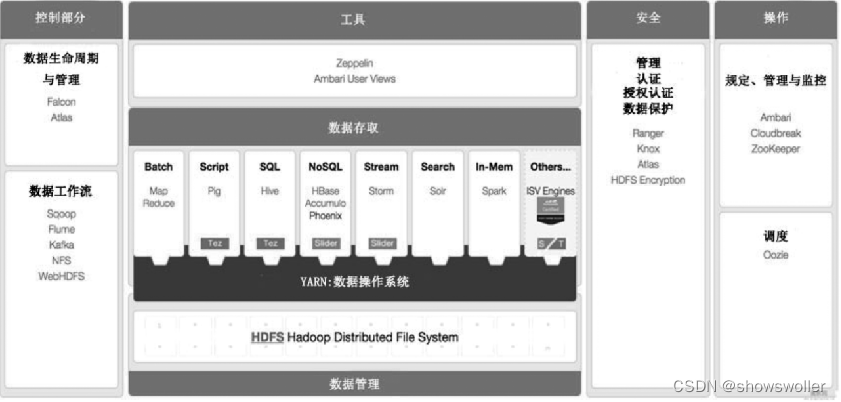
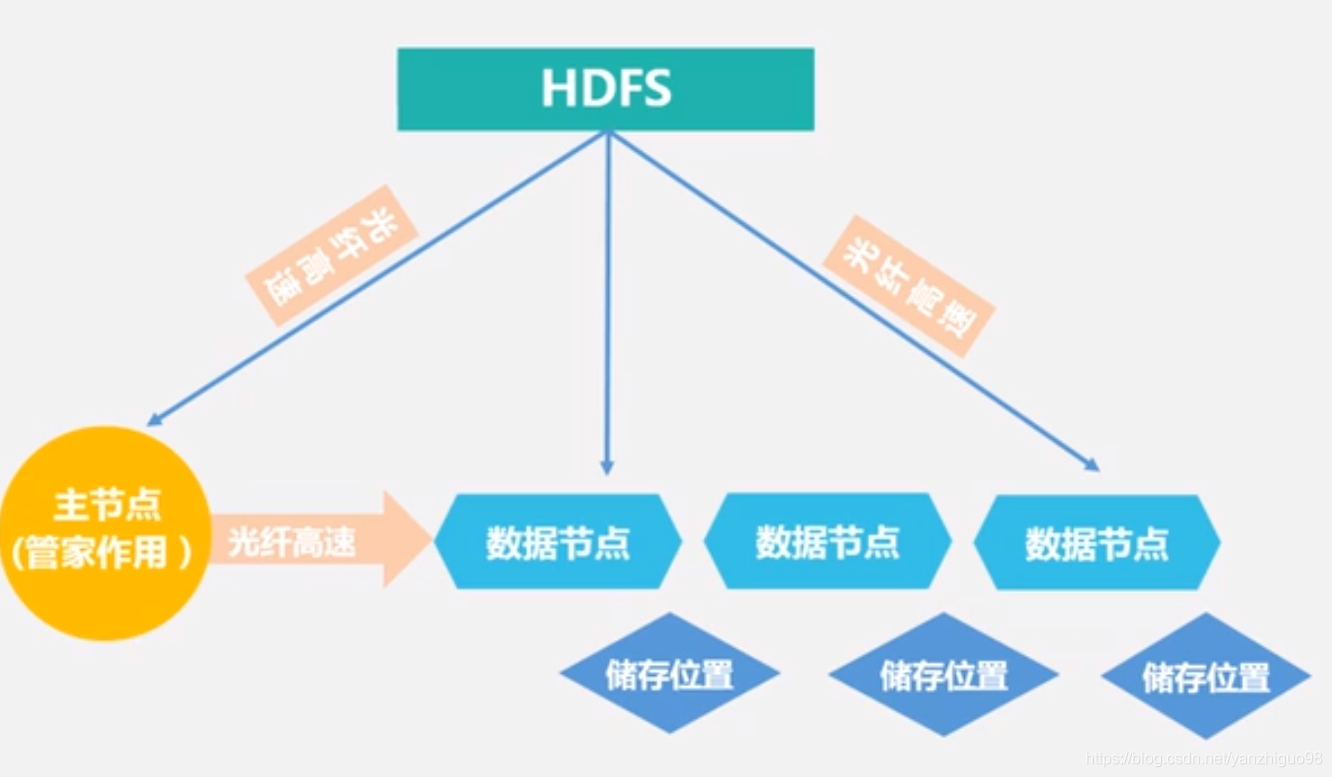
目前,Hadoop、MapReduce这类分布式处理方式已经成为大数据处理各环节的通用处理方法。Hadoop是一个由Apache基金会开发的大数据分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,轻松地在Hadoop上开发和运行处理大规模数据的分布式程序,充分利用集群的威力高速运算和存储。Hadoop是一个数据管理系统,作为数据分析的核心,汇集了结构化和非结构化的数据,这些数据分布在传统的企业数据栈的每一层。Hadoop也是一个大规模并行处理框架,拥有超级计算能力,定位于推动企业级应用的执行。Hadoop又是一个开源社区,主要为解决大数据的问题提供工具和软件。虽然Hadoop提供了很多功能,但仍然应该把它归类为多个组件组成的Hadoop生态圈,这些组件包括数据存储、数据集成、数据处理和其他进行数据分析的专门工具。一个典型的Hadoop 生态系统主要由HDFS、MapReduce、Hbase、Zookeeper、Oozie、Pig、Hive等核心组件构成,另外还包括Sqoop、Flume等框架,用来与其他企业融合。(很多新名词,可以自行Google)
低成本、高可靠、高扩展、高有效、高容错等特性让Hadoop成为最流行的大数据分析系统,然而其赖以生存的HDFS 和MapReduce 组件却让其一度陷入困境——批处理的工作方式让其只适用于离线数据处理,在要求实时性的场景下毫无用武之地。因此,各种基于Hadoop的工具应运而生。为了减少管理成本,提升资源的利用率,有当下众多的资源统一管理调度系统,例如Twitter的Apache Mesos、Apache的YARN、Google 的Borg、腾讯搜搜的Torca、Facebook Corona等。Apache Mesos是Apache孵化器中的一个开源项目,使用ZooKeeper实现容错复制,使用Linux Containers 来隔离任务,支持多种资源计划分配(内存和CPU)。提供高效、跨分布式应用程序和框架的资源隔离和共享,支持Hadoop、MPI、Hypertable、Spark 等。YARN又被称为MapReduce 2.0,借鉴Mesos,YARN 提出了资源隔离解决方案Container,提供Java 虚拟机内存的隔离。在YARN平台上可以运行多个计算框架,如MR、Tez、Storm、Spark等。
此外,由Cloudera开发的Impala是一个开源的Massively Parallel Processing(MPP)查询引擎。与Hive 相同的元数据、SQL语法,可以直接在HDFS或HBase上提供快速、交互式SQL 查询。Impala是在Dremel的启发下开发的,不再使用缓慢的Hive + MapReduce 批处理,而是通过与商用并行关系数据库中类似的分布式查询引擎,可以直接从HDFS 或者HBase 中用SELECT、JOIN 和统计函数查询数据,从而大大降低了延迟。Hadoop社区正努力扩展现有的计算模式框架和平台,以便解决现有版本在计算性能、计算模式、系统构架和处理能力上的诸多不足。
3、MPP并行数据库与Hadoop的混合集群
第三类技术路线主要面对的是结构化和非结构化混合的大数据。采用MPP并行数据库与Hadoop的混合集群来实现对百PB量级、EB量级数据的存储和管理。用MPP来管理计算高质量的结构化数据,提供强大的SQL和OLTP型服务;同时,用Hadoop实现对半结构化和非结构化数据的处理,以支持诸如内容检索、深度挖掘与综合分析等新型应用。
4、内存计算与Hadoop的混合
第四类技术路线Hadoop与内存计算模式的混合,目前已经成为实现高实时性的大数据查询和计算分析新的趋势。这种混合计算模式之集大成者当属UC Berkeley AMP Lab开发的Spark生态系统。
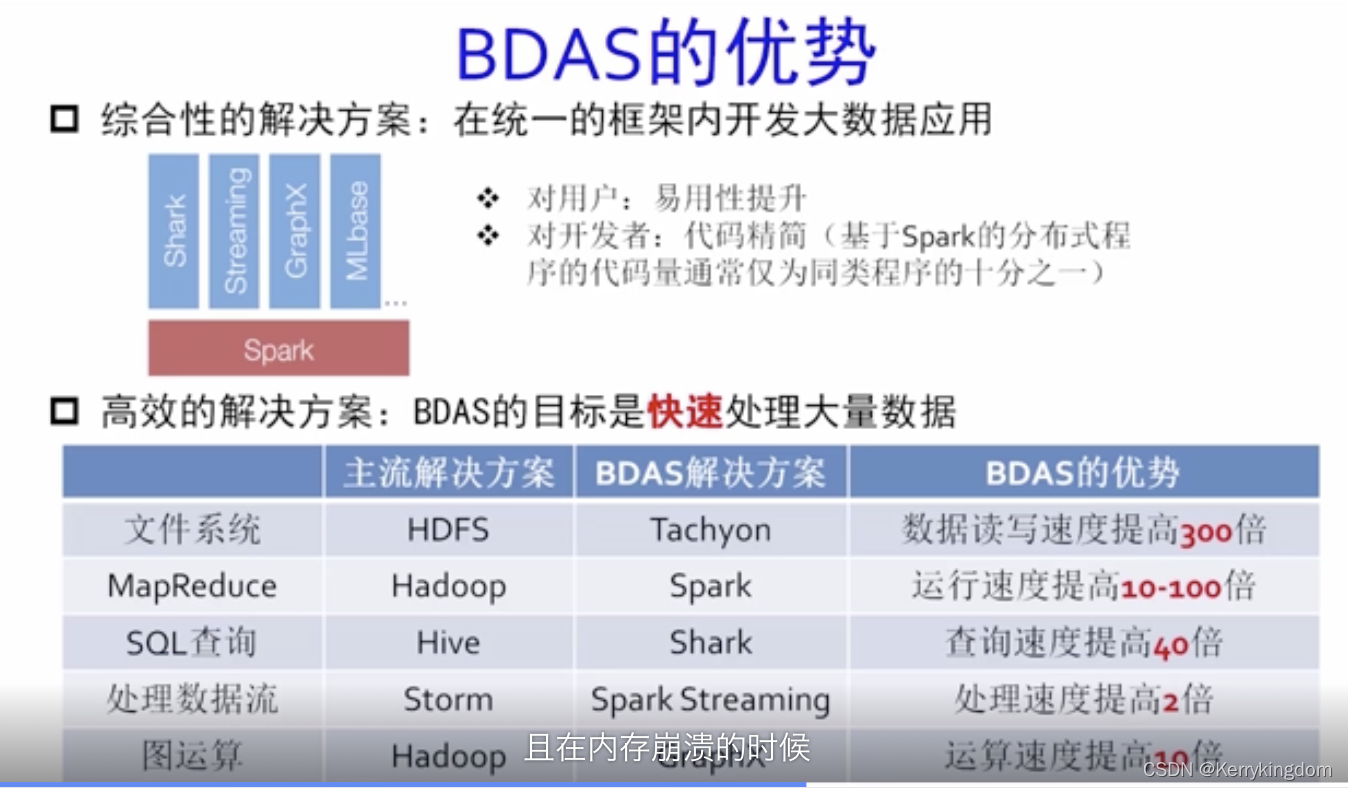
Spark是开源的类似Hadoop的通用的数据分析集群计算框架,用于构建大规模、低延时的数据分析应用,建立于HDFS之上。Spark提供强大的内存计算引擎,几乎涵盖了所有典型的大数据计算模式,包括迭代计算、批处理计算、内存计算、流式计算(Spark Streaming)、数据查询分析计算(Shark)以及图计算(GraphX)。Spark 使用Scala 作为应用框架,采用基于内存的分布式数据集,优化了迭代式的工作负载以及交互式查询。Spark支持分布式数据集上的迭代式任务,实际上可以在Hadoop文件系统上与Hadoop一起运行(通过YARN、Mesos等实现)。另外,基于性能、兼容性、数据类型的研究,还有Shark、Phoenix、Apache Accumulo、Apache Drill、Apache Giraph、Apache Hama、Apache Tez、Apache Ambari 等其他开源解决方案。未来相当长一段时间内,主流的Hadoop平台改进后将与各种新的计算模式和系统共存,并相互融合,形成新一代的大数据处理系统和平台。同时,由于有Spark SQL的支持,Spark是既可以处理非结构化数据,也可以处理结构化数据的,为统一这两类数据处理平台提供了非常好的技术方案,成为目前的一个新的趋势。
总之,我们可以得出以下结论(或预测):
-
Hadoop、Spark这类分布式处理系统已经成为大数据处理各环节的通用处理方法,并进一步构成生态圈;
-
结构化大数据与非结构化大数据处理平台将逐渐融合与统一,而不必为每类数据单独构建大数据平台;
-
MapReduce将逐渐被淘汰,被Spark这类高性能内存计算模式取代,同时Hadoop的HDFS将继续向前发展,成为大数据存储的标准;
-
传统的SQL技术将在大数据时代继续发扬光大,有了SQL on Hadoop/Spark的技术支持,SQL将继续作为大数据时代的霸主,同时也被NoSQL补充;
-
以SQL、Hadoop/Spark为核心的大数据系统将逐渐挑战传统数据库市场,并逐步代替传统的数据仓库。
技术!技术!