数据库与缓存一致性解决方案
文章目录
- 数据库与缓存一致性解决方案
- 前言
- 几种方案的分析
- 方案的实现
前言
项目中如果用到了缓存,就会涉及到数据库与缓存的双写,由于这两个操作不是原子性的,在并发的场景下,容易产生数据库与缓存不一致的情况。
几种方案的分析
数据库与缓存的双写有很多种方案,我们先来看几种最常见的:
1. 先更新数据库再更新缓存
这种方案最容易想到,但是也很容易出问题,比如写请求A先更新了数据库,这时候,写请求B也更新了数据库,接着又更新了缓存,最后写请求A又更新了一次缓存,这个时候缓存中就出现了脏数据。

2. 先更新缓存再更新数据库
假如缓存更新成功,数据库更新失败,那么肯定会照成数据不一致。
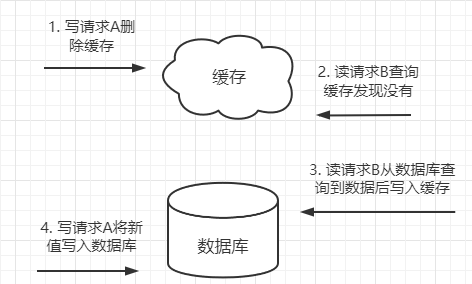
3. 先删除缓存再更新数据库
写请求A进行写操作,删除缓存,读请求B查询缓存发现不存在,B去数据库查询得到旧值然后写入缓存,最后写请求A才将新值写入数据库,这个时候缓存中就是脏数据。
由于对数据库的读一般比写要快,所以这种情况是比较容易发生的。
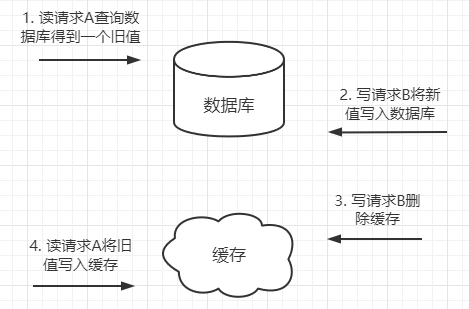
4. 先更新数据库再删除缓存
读请求A查询数据库,得到一个旧值,写请求B将新值写入数据库,写请求B删除缓存,请求A将查询到的旧值写入数据库,这个时候缓存中就出现了脏数据。
但是这种情况发生的概率比较低,因为数据库的读操作一般比写操作快,所以操作1完成之后,马上就会进行操作4。所以最推荐就是这种方式。
删缓存还是写缓存?
现在我们发现,对缓存的操作有两种,一种是更新缓存,一种是删除缓存。其实一般采取的是删缓存,原因有两点:
- 并发环境下,无论是先操作数据库还是后操作数据库而言,如果加上更新缓存,那就更加容易导致数据库与缓存数据不一致问题。(删除缓存直接和简单很多)。
- 如果每次更新了数据库,都要更新缓存(这里指的是写多读少的场景),倒不如直接删除掉。等再次读取时,缓存里没有,就去数据库找,在数据库找到再写到缓存里边(体现懒加载)。
删除缓存失败
明确了删缓存的方案之后,现在面临最大的问题就是缓存删除失败了该怎么办,如果删除失败了就一定会出现不一致的情况,在这里,其实可以做一个保障删除缓存失败后重试的机制,请看方案5。
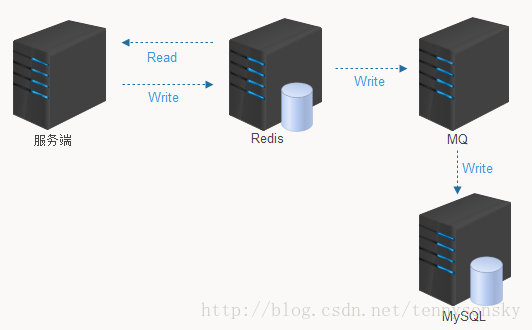
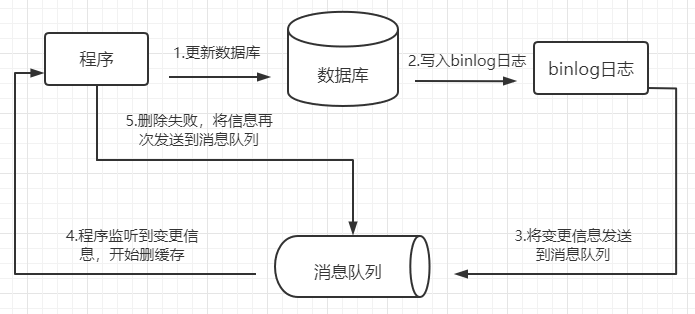
5. 订阅MySql的binlog日志,发送到消息队列再做删除
首先更新数据库的数据,数据库会将数据表数据的变更信息写入binlog日志中,监听到日志文件的变化后,把数据库变更信息发送到消息队列中,程序接收到消息队列中的数据,对缓存做删除。如果删除失败了,程序就把数据再次发送到消息队列中,再做一次删除,实现删除失败后的重试。
这种方案还有一种好处就是不会对业务代码造成过多的侵入,我们可以专门起一条协程来监听消息队列,如果收到消息队列中的数据,直接去删除对应的缓存即可,而不必在业务代码中去写。
方案的实现
下面我们来实现一下刚刚列举的最后一种方案:
1.mysql的配置
mysql需要开启binlog,首先查看一下mysql是否开启了binlog:
# 如果log_bin的值为OFF是未开启,为ON是已开启
SHOW VARIABLES LIKE '%log_bin%'
如果未开启的话,可以修改一下/etc/my.cnf:
[mysqld]
log-bin=mysql-bin
binlog-format=ROW
server_id=1
配置好之后重启一下mysql。
接着创建用于同步的mysql账号:
mysql -uroot -p password
create user canal@'%' IDENTIFIED by 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT,SUPER ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;
2.rabbitmq的配置
我们把canal订阅的binlog更新信息发送到rabbitmq中,再由程序去读取。为了方便,将rabbitmq安装在docker中。
首先创建一个目录用于与容器中的rabbitmq配置文件形成映射:
mkdir /opt/module/rabbitmq/data -p
接着在docker中运行rabbitmq镜像:
# 5672是rabbitmq 默认TCP监听端口,到时候程序连接的也是这个端口
# 15672是rabbitmq提供的ui管理界面的端口
# 25672是rabbitmq集群之间通信的端口
# 如果docker跑在云服务器上,记得在安全组中开放5672和15672端口
docker run -d --hostname rabbit-svr --name rabbit -p 5672:5672 -p 15672:15672 -p 25672:25672 -v /opt/module/rabbitmq/data:/var/lib/rabbitmq rabbitmq:management
然后就可以在浏览器中访问rabbitmq的ui控制界面了,默认账号和密码都是guest:
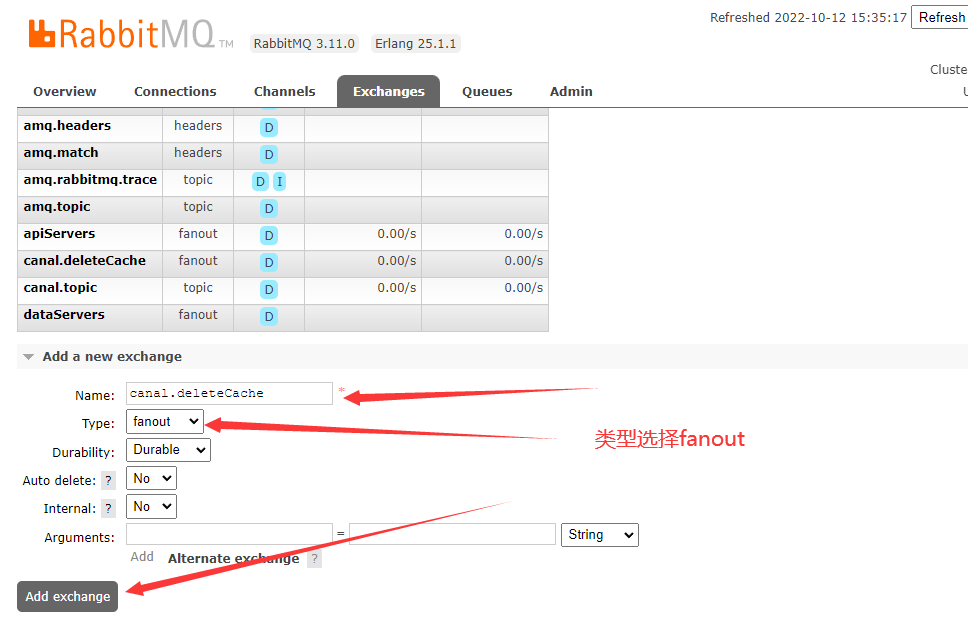
我们先创建一个exchange,类型选择fanout:
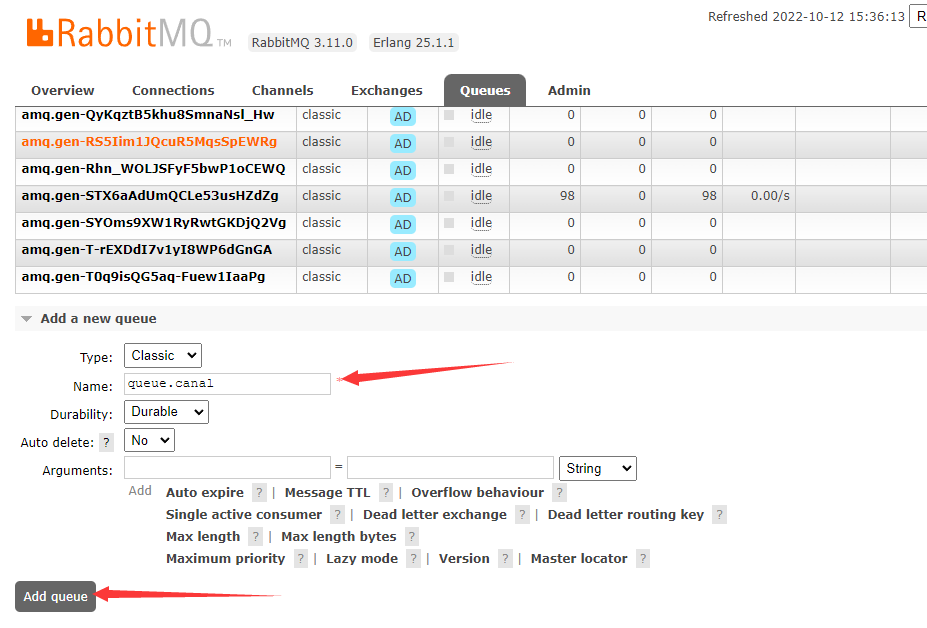
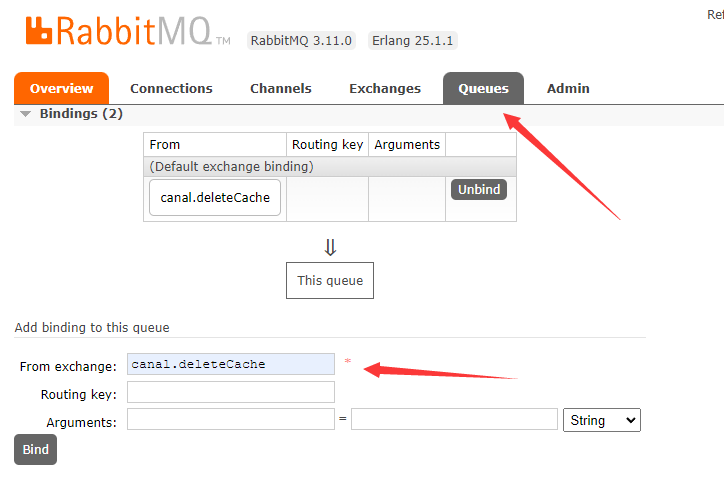
接着创建一个queue用于监听exchang中的消息,创建好queue之后需要点进去绑定一下刚刚创建的canal.deleteCache:
3.canal配置
canal是阿里巴巴旗下的一款开源项目,纯Java开发。基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了MySQL。
它可以订阅mysql的binlog日志,然后将更新的数据发送到消息队列中。
下载地址:https://github.com/alibaba/canal/releases/download/canal-1.1.5-alpha-2/canal.deployer-1.1.5-SNAPSHOT.tar.gz
由于这个工具是java开发的,所以我们还需要在linux环境下配置一下java环境,我配置的是jdk1.8。
首先将jdk目录放在/usr/local/java/目录下,接着编辑/etc/profile文件配置一下环境变量:
export JAVA_HOME=/usr/local/java/jdk1.8.0_181
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
执行一下这个配置脚本:source /etc/profile。
执行echo $JAVA_HOME命令,可以看到jdk文件的路径:

自此,java的环境就配好了,接着来配置一下 canal:
先将.tar.gz文件解压到/opt/module/canal/目录下,首先来编辑conf/目录下的canal.properties文件:
canal.serverMode = rabbitMQrabbitmq.host = 127.0.0.1
rabbitmq.virtual.host = /
# rabbitmq 中新建的 Exchange
rabbitmq.exchange = canal.deleteCache
rabbitmq.username = guest
rabbitmq.password = guest
接着编辑conf/example/目录下的instance.properties文件:
canal.instance.master.address=127.0.0.1:3306# mysql中配置的用于同步的canal用户
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal# rabbitmq中配置的 绑定的 routingkey,如果是topic模式就需要配置,fanout模式不用配置
# canal.mq.topic=test.routingKey# 指定要订阅哪个库下哪个表的更新记录,默认是今天所有库
# canal.instance.filter.regex=.*\\..*
canal.instance.filter.regex=cloud-disk.user_repository
在启动canal之前,最好把mysql的binlog文件清理一下,不然可能会出现匹配不到当前位置的错误:
mysql -uroot -p password
# 该命令会删除所有binlog
RESET MASTER;
# 删除mysql-bin.010之前所有日志
PURGE MASTER LOGS TO 'mysql-bin.010';
# 删除2003-04-02 22:46:26之前产生的所有日志
PURGE MASTER LOGS BEFORE '2003-04-02 22:46:26';
最后启动bin目录下的startup.sh脚本,查看logs/canal目录下的的canal.log,出现以下内容说明启动成功:

至此,环境准备完成。
4.测试数据
Go语言可以使用github.com/streadway/amqp库来操作rabbitmq,执行以下命令来安装:
go get github.com/streadway/amqp
然后我们对这个库做一个二次封装方便使用,将以下程序写到mq/rabbitmq.go中:
package mqimport ("encoding/json""github.com/streadway/amqp"
)// RabbitMQ RabbitMQ结构图
type RabbitMQ struct {channel *amqp.ChannelName stringexchange string
}// New 连接RabbitMQ服务,声明一个消息队列
func New(s, name string) *RabbitMQ {conn, e := amqp.Dial(s)if e != nil {panic(e)}ch, e := conn.Channel()if e != nil {panic(e)}q, e := ch.QueueDeclare(name,false,true,false,false,nil)if e != nil {panic(e)}mq := new(RabbitMQ)mq.channel = chmq.Name = q.Namereturn mq
}// Bind 消息队列绑定交换机
func (q *RabbitMQ) Bind(exchange, key string) {e := q.channel.QueueBind(q.Name,key,exchange,false,nil)if e != nil {panic(e)}q.exchange = exchange
}// Send 向消息队列发布消息
func (q *RabbitMQ) Send(queue string, body interface{}) {str, e := json.Marshal(body)if e != nil {panic(e)}e = q.channel.Publish("",queue,false,false,amqp.Publishing{ReplyTo: q.Name,Body: []byte(str),})if e != nil {panic(e)}
}// Publish 向交换机发送消息
func (q *RabbitMQ) Publish(excahnge string, body interface{}) {str, e := json.Marshal(body)if e != nil {panic(e)}e = q.channel.Publish(excahnge,"",false,false,amqp.Publishing{ReplyTo: q.Name,Body: []byte(str),})if e != nil {panic(e)}
}// Consume 消费消息
func (q *RabbitMQ) Consume() <-chan amqp.Delivery {c, e := q.channel.Consume(q.Name,"",true,false,false,false,nil)if e != nil {panic(e)}return c
}// Close 关闭连接
func (q *RabbitMQ) Close() {q.channel.Close()
}
然后创建一个WatchBinLog函数来获取mq中的数据,一旦监听到数据,就可以对缓存进行删除,如果缓存删除失败,就再次向绑定的exchange中发送binlog的更新信息,实现删除重试:
func WatchBinLog(conf config.Config) {q := New(config.Conf.RabbitMQ.RabbitURL, "queue.deleteCache")defer q.Close()q.Bind(config.Conf.RabbitMQ.CanalExchange, "")c := q.Consume()cacheDB := models.InitCacheDB(conf)conn := cacheDB.RedisPool.Get()for msg := range c {payload := getPayload(msg.Body)var err error// 监听到了mq发送过来的binlog变动,删除缓存_, err = conn.Do("HDEL", payload.UserIdentity, payload.ParentId+"file")_, err = conn.Do("HDEL", payload.UserIdentity, payload.ParentId+"folder")// 如果失败,往mq中重新发送if err != nil {logx.Error("删除缓存失败, payload: ", payload)retryMq := New(config.Conf.RabbitMQ.RabbitURL, "")retryMq.Publish(config.Conf.RabbitMQ.CanalExchange, string(msg.Body))}}
}
最后在main函数中起一个协程来运行WatchBinLog函数,不对业务代码进行侵入:
go mq.WatchBinLog(config.Conf)
程序启动之后,改变数据库中的数据,就会发现缓存会被自动删除。