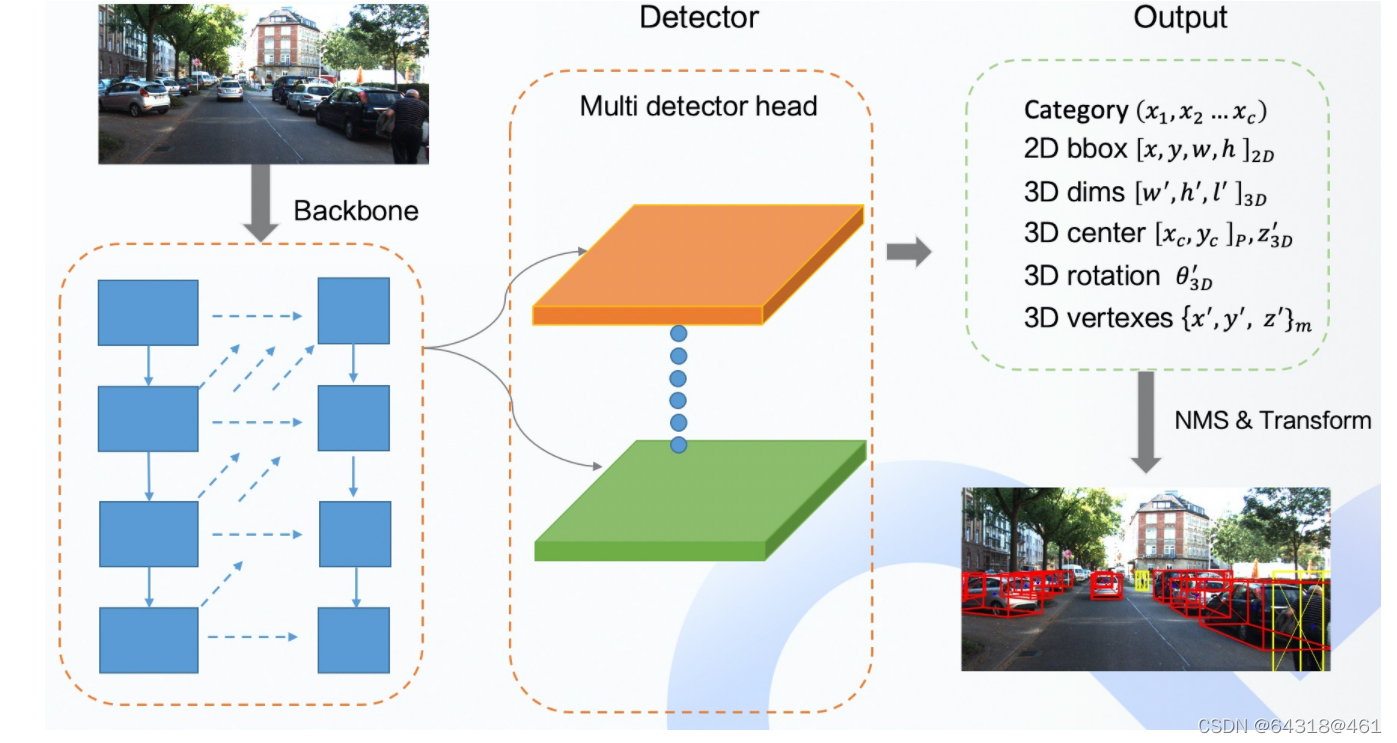
论文地址:https://arxiv.org/pdf/1904.08189.pdf
在本文中,作者将一个对象建模为一个单点,即其包围框的中心点。并使用关键点估计来找到中心点,并回归到所有其他对象属性,如大小、3D位置、方向,甚至姿势。CenterNet,比相应的基于边界盒的检测器更简单、更快、更精确。
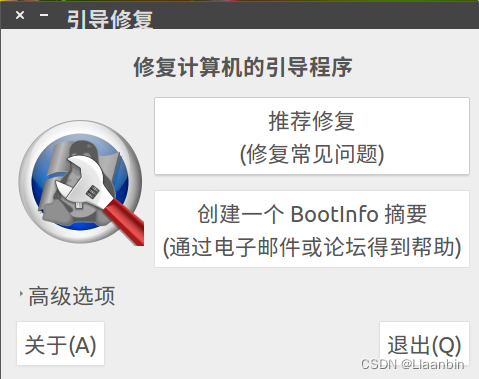
一、实现细节:
设 I ∈ R W × H × 3 I ∈R^{W×H×3} I∈RW×H×3为宽度为W、高度为H的输入图像,生成一个关键点热图 Y ∈ [ 0 , 1 ] ( W / R ) × ( H / R ) × C Y∈ [0,1] ^{(W/R) ×(H/R)×C} Y∈[0,1](W/R)×(H/R)×C,其中R为输出步幅,C为关键点类型的数量。例如物体检测中的C = 80个物体类别。本文的输出步幅R = 4。下采样输出预测步长由R决定。预测 Y x , y , c = 1 Y_{x, y,c} = 1 Yx,y,c=1对应一个检测到的关键点,而Y_{x, y,c} = 0 是 背 景 。 本 文 使 用 几 种 不 同 的 全 卷 积 编 码 器 − 解 码 器 网 络 从 图 像 是背景。本文使用几种不同的全卷积编码器-解码器网络从图像 是背景。本文使用几种不同的全卷积编码器−解码器网络从图像I 中 预 测 中预测 中预测Y:stacked hourglass network 、ResNet和深层聚合网络(DLA)。
对于c类的每个ground truth keypoint为 p ∈ R 2 p∈R^2 p∈R2,在低分辨率图像上等效 p = [ p / R ] p= [ p/R ] p=[p/R]。把所有的ground truth keypoint都放在一个热图上 Y ∈ [ 0 , 1 ] ( W / R ) × ( H / R ) × C Y∈ [0,1] ^{(W/R) ×(H/R)×C} Y∈[0,1](W/R)×(H/R)×C使用高斯核:

其中σ是一个对象大小自适应的标准差,如果同一类的两个高斯函数重叠,则取元素方向的最大。训练目标是减少惩罚的像素逻辑回归与焦点损失:
其中,α和β为 focal loss的超参数,N为图像i中的关键点个数,选择N进行归一化,将所有positive focal loss实例归一化为1。在所有的实验中使用α = 2和β = 4。为了复原由输出步幅引起的离散化误差,在每个center point还预测了一个局部偏移:

所有类c共享相同的偏移量预测。用L1 loss来训练偏移量:


![[1] A Keypoint-based Global Association Network for Lane Detection](https://img-blog.csdnimg.cn/e7796a74547a4a8eb9fd71f577bf4f04.png)