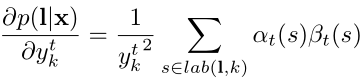文章目录
- 1 概述
- 2 模型介绍
- 2.1 输入
- 2.2 Feature extraction
- 2.3 Sequence modeling
- 2.4 Transcription
- 2.4.1 训练部分
- 2.4.2 预测部分
- 3 模型效果
- 参考资料
1 概述
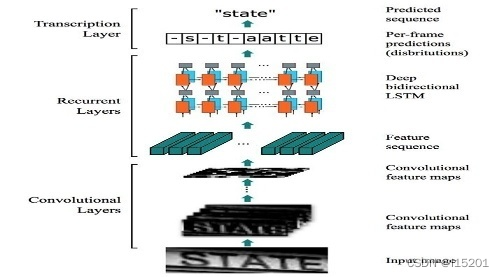
CRNN(Convolutional Recurrent Neural Network)是2015年华科的白翔老师团队提出的,直至今日,仍旧是文本识别领域最常用也最好用的方法。CRNN主要由三部分组成,分别是feature extraction,sequence modeling和transcription,如下图1-1所示。
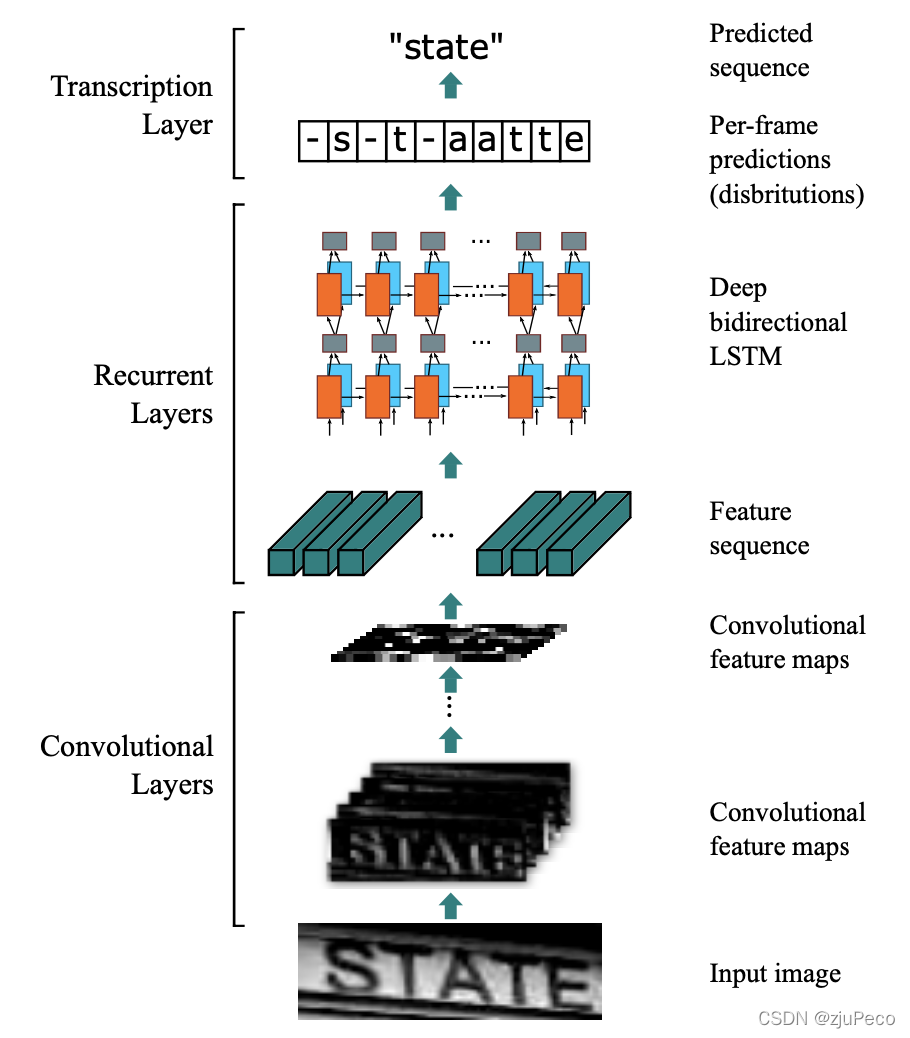
feature extraction用于按宽度抽取图像特征,sequence modeling用于融合这些特征并输出label的预测分布,transcription用于将这个特征序列转化为文本。
CRNN强大的地方就是它只是一个框架,其中的feature extraction和sequence modeling部分都是可以替换成不同的模型的,比如feature extraction部分,可以换成任意的抽取图像特征的模型,想要追求性能就换成小模型,想要追求效果就换成大模型,非常灵活。
2 模型介绍
2.1 输入
输入是一般是文本检测的输出,一个长条形的图片,是横向长条的,因为我们的文字都是横着写的。而且这一长条里只能有一行文字,不能多行。多行就得要切成多个单行的长条分别输入。
文本有一些倾斜问题不大,但最好是在文本检测部分调整,即在文本检测部分检测多边形,再仿射变换成长条形,使得文本部分不倾斜。也有论文提出在CRNN的前面前置一个STN。STN要真的有效,需要有好的训练数据。就算有好的数据,也降低了模型的总体性能,增大了模型的训练难度。STN可以看成一个极简版的物体检测模块。
输入的尺寸一般为 h × w × c = 32 × 280 × 3 h \times w \times c = 32 \times 280 \times 3 h×w×c=32×280×3,不是这个尺寸的就resize and pad成这个尺寸,尽量不要只resize,这会使得文字变形。输入尺寸 w w w会根据需求做调整,如果文本都是短文本,则可以考虑 w = 100 w=100 w=100。
2.2 Feature extraction
Feature extraction就是对 32 × 280 × 3 32 \times 280 \times 3 32×280×3的输入进行特征抽取的一个deep convolutional neural networks,输出 1 × w / 4 × d = 1 × 70 × 512 1 \times w/4 \times d=1 \times 70 \times 512 1×w/4×d=1×70×512的向量。 w / 4 w/4 w/4表示对 32 × 4 32 \times 4 32×4的一小块图片区域抽取一个512维的特征。这一小块区域被称为receptive field(感受野),或是帧。
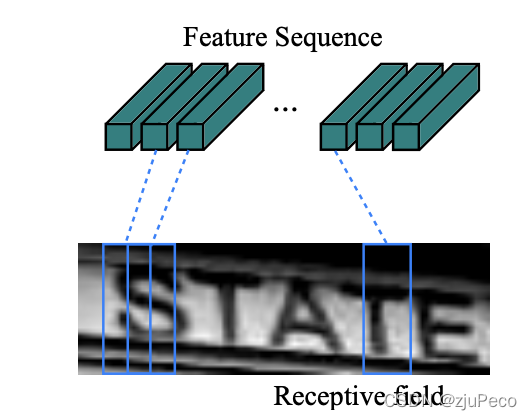
帧的尺寸是可以变的,输出的特征维度也是可以变的,这些都是超参数。也正是因为CRNN这种抽取特征的方式,使得它没法办法处理竖向的文本,所有高度上的像素都被压到一个特征里了,分不开了。帧的尺寸决定了模型的精度,比如有两个文字完全都在同一帧内,那模型就没法把这两个文字分开了,识别就有问题了。
要处理竖向的文本,需要训练一个识别文本方向的分类网络,然后根据文本的方向对竖向的文本进行旋转或者切片拼接等不同的操作。目的就是变成CRNN可以处理的输入。
2.3 Sequence modeling
我们令feature extraction部分的输出为 x = x 1 , x 2 , . . . , x T \bold{x}=x_1, x_2, ..., x_T x=x1,x2,...,xT, T = 70 T=70 T=70, x t x_t xt表示第 t t t帧的特征,为一个512维的向量。假设字典的长度为 N N N,Sequence modeling就是一个双向的LSTM,输出 y = y 1 , . . , y T \bold{y} = y_1, .., y_T y=y1,..,yT, y t y_t yt表示第 i i i帧为每个字典中字符的概率,是一个 N + 1 N+1 N+1维的向量。
Sequence modeling部分的总输出是一个 T × ( N + 1 ) T \times (N+1) T×(N+1)的概率图。
使用双向LSTM的好处是:
(1)文本是一个序列,抽取特征的CNN模型只能看到附近几帧的图片特征,而双向LSTM可以融合更远的特征,使得模型看到完整的整个字;
(2)LSTM可以和CNN使用Back-Propagation Through Time (BPTT)的方法拼接起来一起训练;
(3)LSTM可以处理任意长度的输入。
2.4 Transcription
这部分是使用CTC来做的,它在训练和预测时有着不同的处理方法。2.3中的 y \bold{y} y之所以维度为 N + 1 N+1 N+1就是因为CTC需要一个空白符" ϕ \phi ϕ"。CTC的对齐基于两个规则:
(1)先合并所有的重复字符;
(2)再删除所有的空白符。
比如,下面两个序列 s \bold{s} s经过对齐之后,都是"Hello"。
H ϕ e e e ϕ l l l ϕ ϕ ϕ l l l ϕ o o H e e ϕ ϕ l l l ϕ ϕ l l l l ϕ o o o H \phi eee \phi lll \phi\phi\phi lll \phi oo \\ H ee \phi\phi lll \phi\phi llll \phi ooo HϕeeeϕlllϕϕϕlllϕooHeeϕϕlllϕϕllllϕooo
2.4.1 训练部分
训练时,我们是知道文本标签的。
假设我们的训练数据为 { I i , l i } \{\bold{I}_i, \bold{l}_i\} {Ii,li}, I i \bold{I}_i Ii为第 i i i张训练图片, l i \bold{l}_i li为第 i i i张图片的文本标签, y i \bold{y}_i yi为第 i i i张图片的预测概率图(序列都用粗体进行了表示)。我们的目标就是
a r g min − ∑ i l o g p ( l i ∣ y i ) (2-1) arg\min -\sum_{i} log p(\bold{l}_i|\bold{y}_i) \tag{2-1} argmin−i∑logp(li∣yi)(2-1)
其中, p ( l i ∣ y i ) p(\bold{l}_i|\bold{y}_i) p(li∣yi)表示用概率图 y i \bold{y}_i yi得到文本序列 l i \bold{l}_i li的概率。
p ( l i ∣ y i ) = ∑ s : B ( s ) = l i p ( s ∣ y i ) (2-2) p(\bold{l}_i|\bold{y}_i) = \sum_{\bold{s} : \Beta(\bold{s})=\bold{l}_i} p(\bold{s}|\bold{y}_i) \tag{2-2} p(li∣yi)=s:B(s)=li∑p(s∣yi)(2-2)
s \bold{s} s表示可以变成文本 l \bold{l} l的一条路径, B ( s ) \Beta(\bold{s}) B(s)表示对 s \bold{s} s进行CTC对齐操作。 p ( l i ∣ y i ) p(\bold{l}_i|\bold{y}_i) p(li∣yi)也就是所有可以从 s \bold{s} s变为 l i \bold{l}_i li的路径概率和。
p ( s ∣ y i ) = ∏ t = 1 T y s t t (2-3) p(\bold{s}|\bold{y}_i) = \prod_{t=1}^T y_{s_t}^t \tag{2-3} p(s∣yi)=t=1∏Tystt(2-3)
要找到所有可以从 s \bold{s} s变为 l i \bold{l}_i li的路径,用枚举法是不行的,这里一般会用HMM中的前向后向算法,也就是动态规划。
2.4.2 预测部分
预测时,我们是不知道文本标签的。
这个时候要去计算所有可能的文本序列的概率,再找到最大的,简直无法想象。所以预测时,我们只能寄希望于模型训练的足够好,每一帧都预测得很准。然后用greedy search或者beam search的方法来找到最有路径。
greedy search是实际最常用的方法,就是取每帧概率最大的标签。
beam search是在每帧去概率最大的前n条路径,一直保留n条概率最大的路径,直到最后一帧,当n取1时,beam search就退化为greedy search。
以上说的都是只有字典的情况,当我们有词表lexicon时,我们可以根据结果,取编辑距离小于 δ \delta δ的所有词,然后再看取这些词时,概率最大的是哪个词,以此确定最终的输出。
3 模型效果
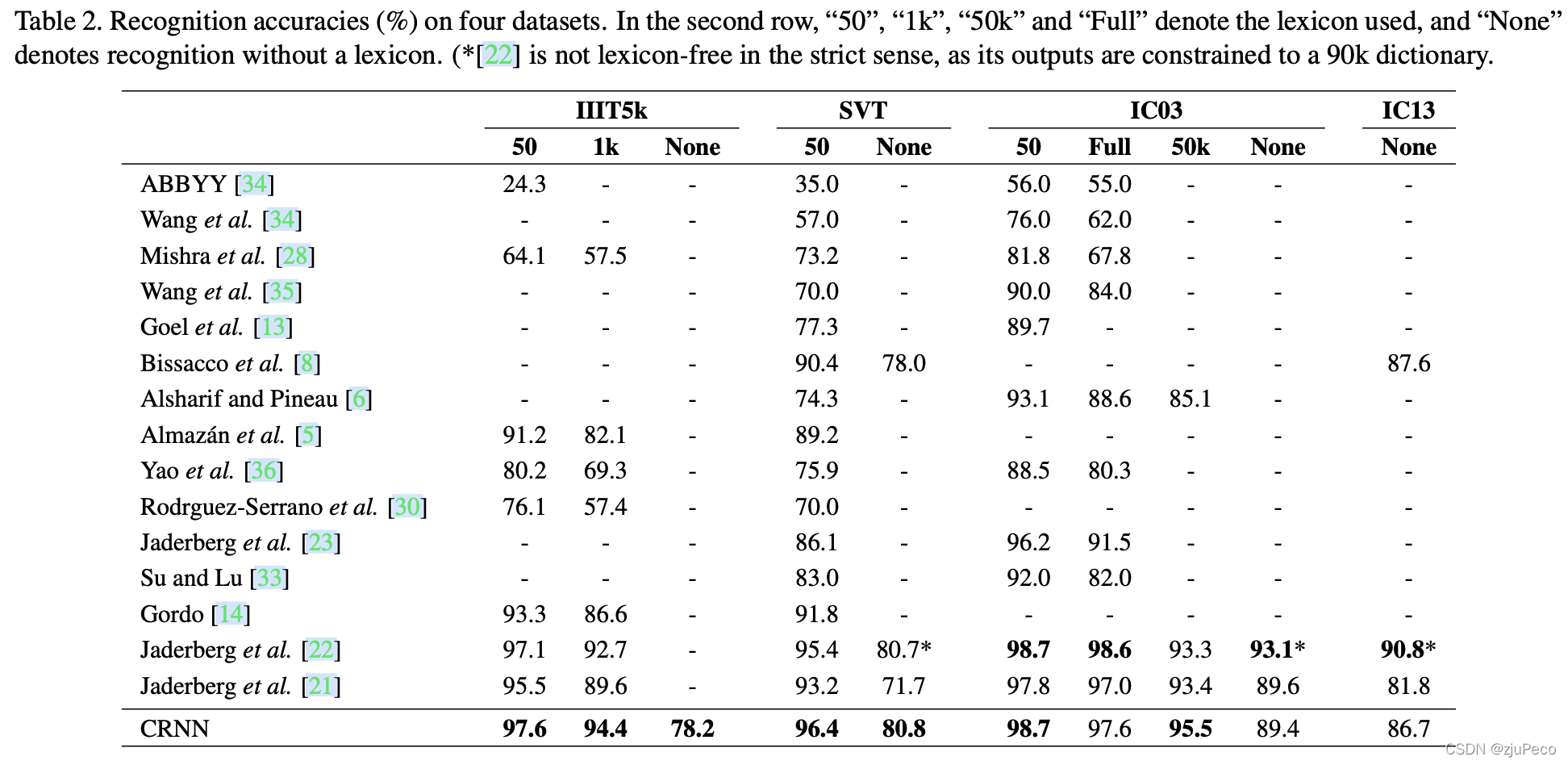
作者还对比了不同数据集下,CRNN对比其他模型的效果,不过这都是2015年的时候的了,看看即可。
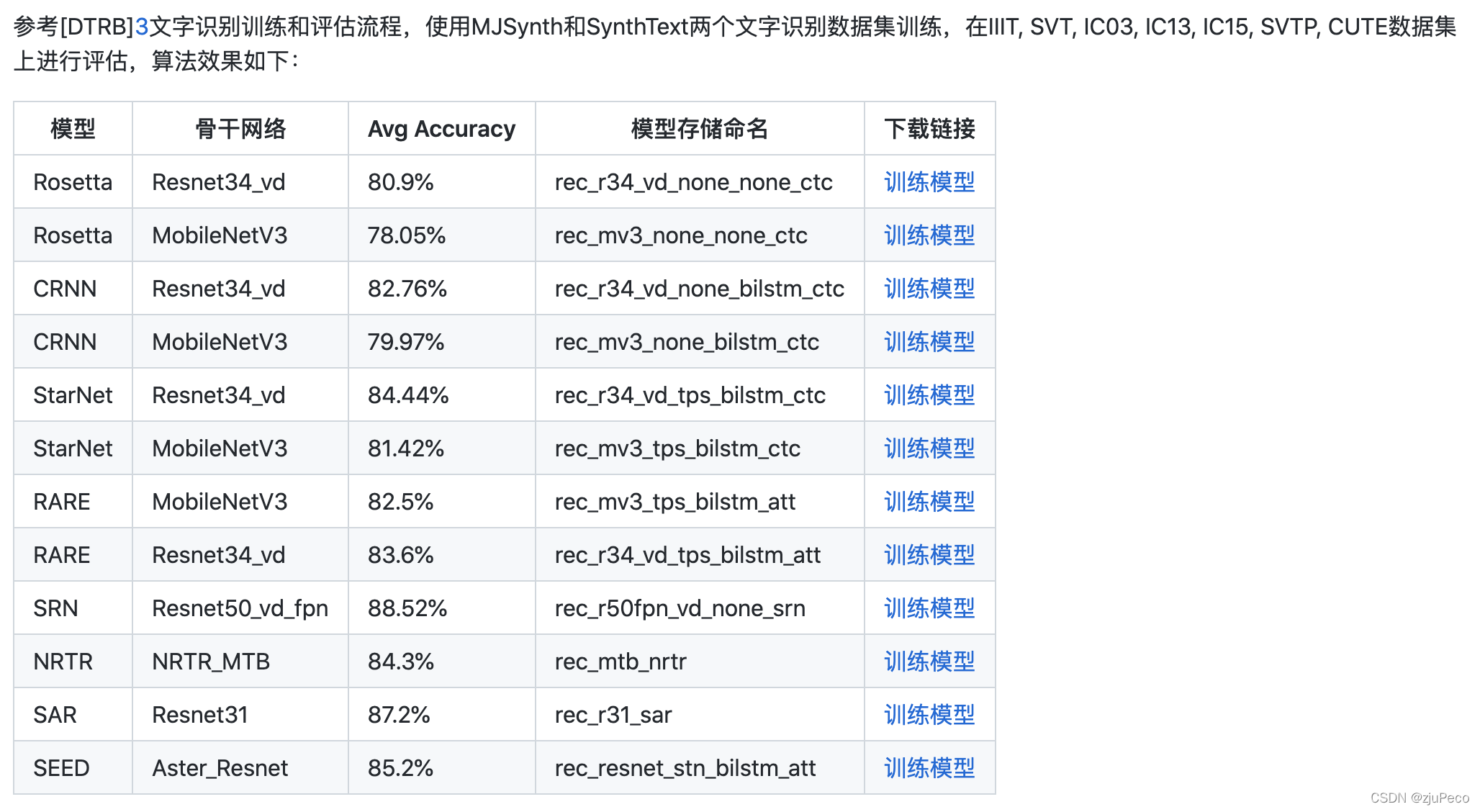
不如看下百度开源的paddle-ocr里的对比结果。CRNN虽然不是准确率最高的,但是是paddle-ocr最推荐的算法。它的效果和性能的综合优势是最高的。
参考资料
[1] An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
[2] 一文读懂CRNN+CTC文字识别
[3] PaddleOCR