关于敏感词过滤的一点思考与实践
- 业务场景
- 思考与研究
- 逻辑分析
- 代码实现(php)
- 构建敏感词树
- 分割字符串
- 敏感词树长分支的递归实现
- 读取敏感词库
- 敏感词树的查询
- 查询实现
- 调用
- 测试、分析与总结
业务场景
最近在公司维护的小程序上,遇到一个需要用到敏感词过滤功能的业务模块,虽然有微信提供的敏感词过滤的api可供使用,但是如果我们想加入自定义的敏感词库,或者我们想要知道是什么违规词汇,后对他和谐处理,那要如何实现呢?
思考与研究
我们知道,如果要查询某段文本中的敏感词汇,马上能想到的有如下几种:
1.用正则匹配的方式去实现,简单粗暴地对每一个敏感词库中的敏感词在文本中进行匹配。
2.转变成某种格式,利用开发语言内置的某些“值是否存在的”方法实现
3.将数据存入数据库中利用数据库查询
4.其它的方法欢迎评论区补充。
但是以上的方法都有着或多或少的问题,例如正则匹配,如果输入文本很大、敏感词库很大,那么全部查一遍的时间复杂度显然会超出预期,又例如利用开发语言的内置方法,且不说不同的语言有没有内置这种方法,在算法设计上,我们也不能只考虑单一语言的实现,优秀的算法在不同语言中实现的效果都是出色的,而数据库查询基本类似于第一种,所以不考虑。
经过一番网络上对各种帖子的研究,发现敏感词过滤大多使用的是类DFA算法的思想实现,要了解DFA算法的原理和使用场景不在此篇讨论的范畴中,因此不予篇幅描述。
那么我们如何利用类DFA的思想实现呢?
逻辑分析
根据DFA算法的思想,我们可以将敏感词库设计成一个特殊的树形结构,称之为敏感词查询树。
基本逻辑是将敏感词拆分成单独的字,然后根据顺序构建一个树分支,如果有些敏感词是前几个字相同的,则构建成同一个分支下的小分支,以此类推:
例如将:乒乓球大赛、乒乓球冠军、乒乓大满贯、篮球冠军、篮联、足球、足力健等词语构建成树形结构,则抽象效果图如下:
预估:由于将敏感词设计成了抽象的特殊树的分支结构(也可以说有点像hash,本文不对具体的定义做讨论),在查询时树的最大深度就是敏感词条的字符长度,这样一来时间复杂度降低了数个level,完全可以满足高效查询的需求。在消耗内存空间的问题上,我们还可以将该词库放入redis中使用hash结构保存,在频繁调用的时候只需要很小的内存空间就能高速完成查询。
有了清晰结构,下一步讨论 完成敏感词树的建立和查询的实现方法,这样我们的讨论才有意义。
代码实现(php)
准备:
考虑到需要自定义敏感词库,所以在实现算法时通过读取文本的方式建立敏感词库(提供敏感词库下载链接,直接打开中文乱码,建议网盘)
敏感词库.txt
博文中出现的敏感词,已用拼音代替过审
构建敏感词树
构建树的方法需要将敏感词分割成单个字符按照顺序建立分支,按照我们树的基本规则,每个字符为一个节点,相同字符长在同一个分支上,敏感词树分支按照顺序延伸。
分割字符串
/*** 分割字符串,将用户输入的字符去掉符号之后* * @param String $str 切割的字符串* @param int $split_len 切割后的长度* @return array|false*/
function utf8StrSplit($str, $split_len = 1)
{ if (!preg_match('/^[0-9]+$/', $split_len) || $split_len < 1) return FALSE; $len = mb_strlen($str, 'UTF-8'); if ($len <= $split_len) return array($str); preg_match_all('/.{'.$split_len.'}|[^x00]{1,'.$split_len.'}$/us', $str, $ar); return $ar[0];
}
敏感词树长分支的递归实现
/*** 敏感词入树* @param &$node 当前节点的引用* @param &$wordsArr 用户输入文本的字符数组引用* @return null*/function addTreeBranch(&$node, &$wordsArr){//弹出数组中的第一个字符$word = array_shift($wordsArr);if ($word == null){return;}if (isset($node[$word])){ //如果已存在这个字符节点,则节点引用转移到此节点$nextNode = &$node[$word];return $this->addTreeBranch($nextNode ,$wordsArr);}else{//如果不存在该字符节点,则长出该片叶子,赋值为空,再转移节引用到该字符节点$node[$word] = [];$nextNode = &$node[$word];return $this->addTreeBranch($nextNode ,$wordsArr);}}
读取敏感词库
调用上述两个方法生成敏感词库(以text文件为例)
function createSearchTree (){$sensitiveWordsTree = [];//敏感词树//读取敏感词库,生成查找树$sensitive = file( 'test.txt'); //按行读取内容foreach ( $sensitive as $line => $value ){//去除换行符$value = preg_replace("/[,!?:#%& *]/","",$value); //拆分每行内容 $tempArr = $this->utf8StrSplit($value);//树长分支$this->addTreeBranch($sensitiveWordsTree, $tempArr);}return json_encode($sensitiveWordsTree);}
我们来看一下生成的敏感词树的结构:
{"乒": {"乓": {"球": {"大": {"赛": []},"冠": {"军": []}},"大": {"满": {"贯": []}}}},"篮": {"球": {"大": {"赛": []}},"联": []},"足": {"球": [],"力": {"健": []}}
}
可以看到树的结构与我们的逻辑结构的概念图基本一致。那么敏感词的生成方法就完成了。
敏感词树的查询
有了结构之后,接下来要对某段文本进行敏感词匹配,这是我们过滤或者和谐它的基础。
匹配的方法和构造树的方法原理类似,都是通过数组键值的访问递归判断,不过查询比构建麻烦的地方在于匹配的关键词需要完全一致、匹配结束之后需要跳转回根节点继续查找、匹配成功的敏感词需要保存起来等。
来看如何实现
查询实现
/*** 敏感词匹配,递归匹配敏感词树,如匹配则保存敏感词信息* author Ray* create_time 2020-7-16 11:24* @param array $userInput 用户输入的内容拆分后的字符数组* @param array $sensitiveWordsInfo 用于保存匹配到的敏感词的数组,子数组为用户输入内容的敏感词语,子数组个数为匹配的敏感词个数* @param array $node 敏感词树查询定位节点* @param array $sensitiveWordsArr 保存敏感词的临时数组* @param int $index 查询树的深度* @return String 当未查询到的时候返回null,当查询到时返回匹配敏感词数组*/
private function searchTreeBranch(&$userInput, &$sensitiveWordsInfo, &$node, $sensitiveWordsArr, $index)
{//用户输入字符过滤完成,或者避免死循环出现,结束递归if (empty($userInput) || $index > 100){//搜索结束,返回匹配到的结果数组return $sensitiveWordsInfo;}//逐个字符匹配,取出当前判断的字符$word = array_shift($userInput);//若当前节点有该字符分支if (isset($node[$word])){ //若匹配的字符分支为叶子节点if (empty($node[$word])){//将当前敏感字保存进敏感词匹配数组中array_push($sensitiveWordsArr, $word);//保存匹配的敏感词array_push($sensitiveWordsInfo, implode('', $sensitiveWordsArr));//匹配完一个敏感词,继续查询下一个字符, 重新从根节点递归return $this->searchTreeBranch($userInput, $sensitiveWordsInfo, $this->sensitiveWordsTree, [], 0);}else{//当前字符有匹配,且下一个节点非空,则过渡到这个字符节点$nextNode = &$node[$word];//将当前敏感字保存array_push($sensitiveWordsArr,$word);return $this->searchTreeBranch($userInput, $sensitiveWordsInfo, $nextNode, $sensitiveWordsArr, $index++);}}else{ //没有匹配,查询下一个字符, 重新从根节点查询if (!empty($sensitiveWordsArr)){//匹配“fa lun gon”、“中国”时,类似“法轮中国”中,“fa lun gon”不能完全匹配,//但是“中”字会被跳过,所以类似此种情况回填“轮中”二字继续查询array_shift($sensitiveWordsArr);array_unshift($userInput,$word);$userInput = array_merge($sensitiveWordsArr,$userInput);}return $this->searchTreeBranch($userInput, $sensitiveWordsInfo, $this->sensitiveWordsTree, [], 0);}
}调用
过滤查询文本中的中文字符、英文字符、特殊字符,调用递归查询方法
/*** 用户敏感词判断方法* @param content 待判断的文本* @return boolen 是否是敏感词,true为是*/
private function inSensitive($content)
{$sensitiveWordsInfo = [];//敏感词在用户输入文本中的位置//去除英文字符$content = preg_replace("/[\s|\~|`|\!|\@|\#|\$|\%|\^|\&|\*|\(|\)|\-|\_|\+|\=|\||\|\[|\]|\{|\}|\;|\:|\"|\'|\,|\<|\>|\/|\?]/","",$content);//去除中文标点符号$content = urlencode($content);//将关键字编码$content = preg_replace("/(%7E|%60|%21|%40|%23|%24|%25|%5E|%26|%27|%2A|%28|%29|%2B|%7C|%5C|%3D|\-|_|%5B|%5D|%7D|%7B|%3B|%22|%3A|%3F|%3E|%3C|%2C|\.|%2F|%A3%BF|%A1%B7|%A1%B6|%A1%A2|%A1%A3|%A3%AC|%7D|%A1%B0|%A3%BA|%A3%BB|%A1%AE|%A1%AF|%A1%B1|%A3%FC|%A3%BD|%A1%AA|%A3%A9|%A3%A8|%A1%AD|%A3%A4|%A1%A4|%A3%A1|%E3%80%82|%EF%BC%81|%EF%BC%8C|%EF%BC%9B|%EF%BC%9F|%EF%BC%9A|%E3%80%81|%E2%80%A6%E2%80%A6|%E2%80%9D|%E2%80%9C|%E2%80%98|%E2%80%99)+/",'',$content);$content = urldecode($content);//将过滤后的关键字解码if (empty($content)){return [];}//拆分用户输入$userInput = $this->utf8_str_split($content);//匹配用户输入是否为敏感词$this->searchTreeBranch($userInput, $sensitiveWordsInfo, $this->sensitiveWordsTree, [], 0);return $sensitiveWordsInfo;
}
主要的难点在于查询实现中递归的结束 (输入文本检索完成)、继续递归 (敏感词成功匹配) 的跳转(匹配成功的跳转、未完全匹配需要回退的跳转)之间的状态转换,在方法中已做了详细的注释,本文不讨论具体查询方法,代码供参考。
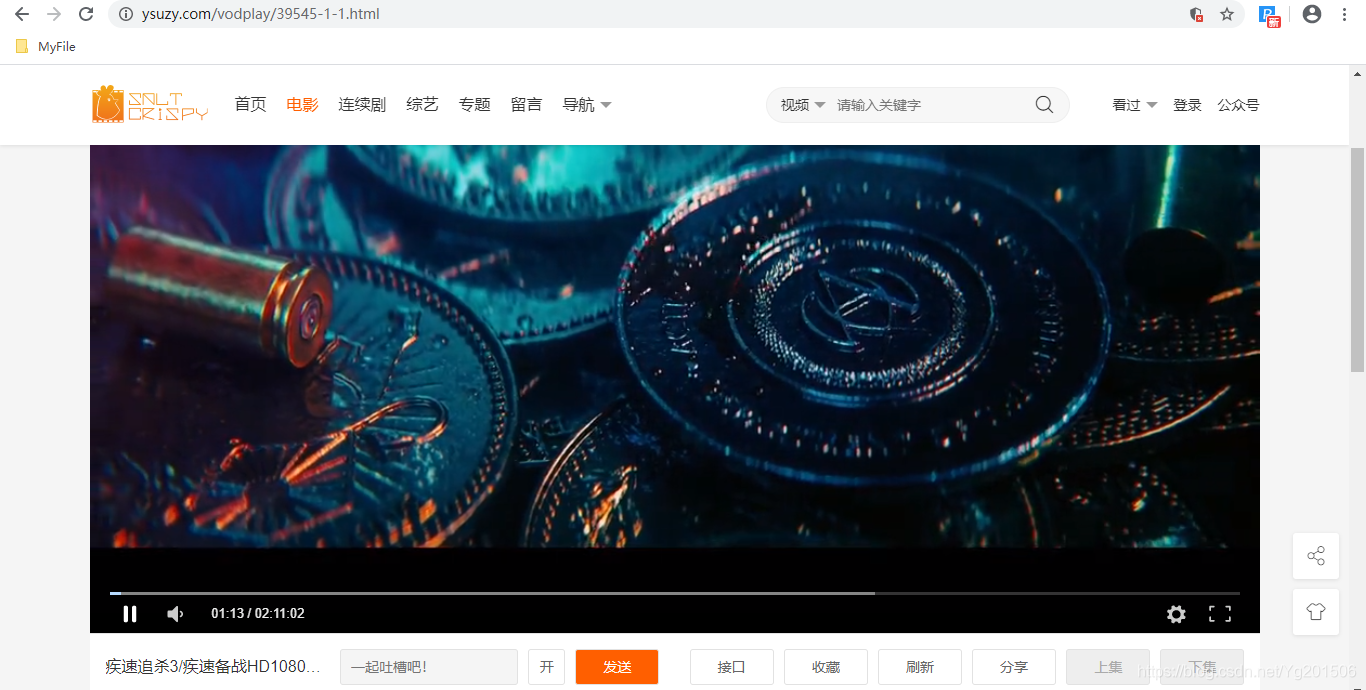
正式运行完成之后测试的结果如:
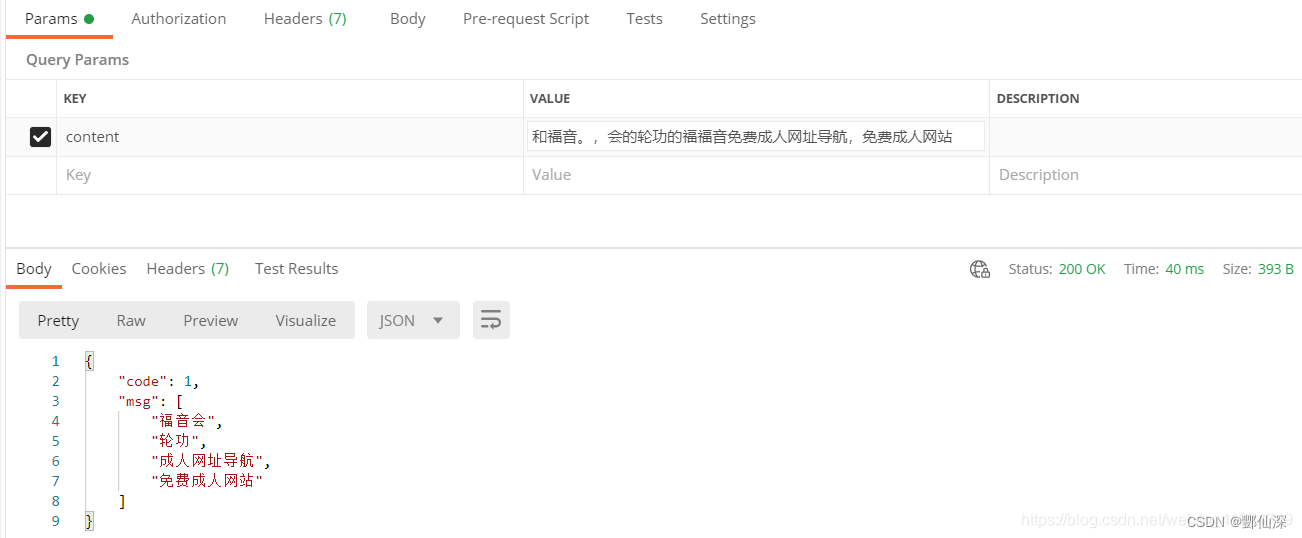,然后匹配成功“chen ren 网址导航”。

再者,我们一个完整的查询请求消耗的时间只有40ms,基本满足业务场景快速响应的需要。
测试、分析与总结
通过测试,在响应时间上基本可以满足要求,但是占用内存会比较多,如果后续通过redis建立hash类型的数据,建立快速读取的方式,应该对性能有一定提升。
另外如果要对一段文本中的敏感词进行替换处理(俗称*河蟹),可以用上面的方法将匹配的敏感词组再对文本进行替换处理,由于较为简单就不做演示了。