目录
items.py
flhz.py
pipelines.py
目标:爬取 福利吧论坛 里的 福利汇总 文,将所有 福利汇总 文里的热门视频标题、链接以json格式保存,所有 福利汇总 文里面的图片按目录(目录名为当前图片所在页url中的7位数字),如某篇福利文 url 为http://fulibus.net/2019015.html,则该页内图片保存在当前项目目录下的 2019015 目录内
items.py
# -*- coding: utf-8 -*-
import scrapyclass ArticleItem(scrapy.Item):title = scrapy.Field()publish_time = scrapy.Field()videos = scrapy.Field()
flhz.py
# -*- coding: utf-8 -*-
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from fulibus.items import ArticleItem
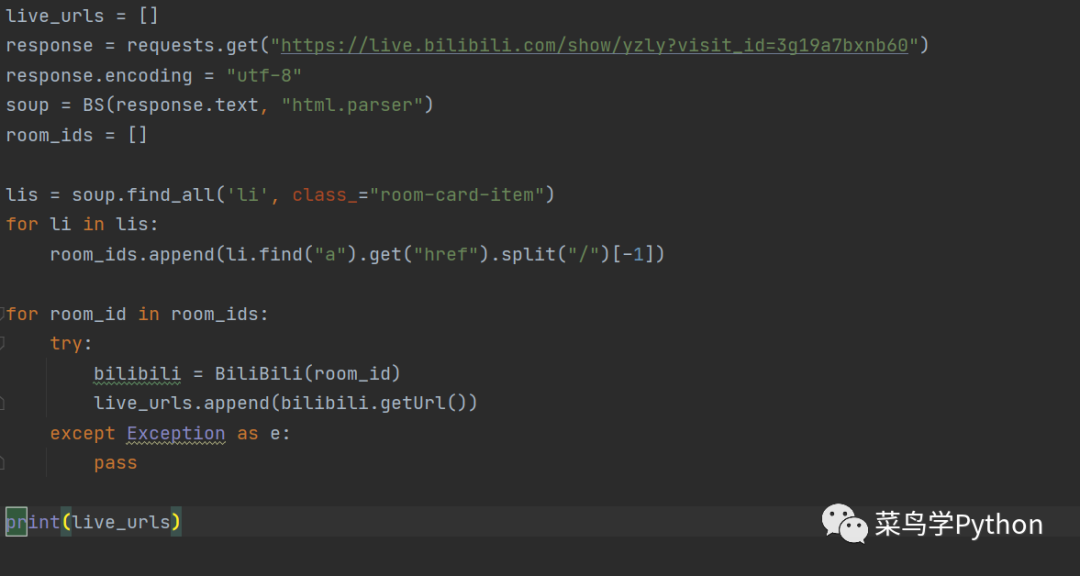
import osclass FlhzSpider(CrawlSpider):name = 'flhz'allowed_domains = ['fulibus.net', 'sinaimg.cn', ]start_urls = ['http://fulibus.net/category/flhz']pages_list = LinkExtractor("category/flhz")# http://fulibus.net/2019004.html http://fulibus.net/tugirl.htmlarticles_list = LinkExtractor(allow="\d{6,7}\.html",restrict_xpaths="//article[contains(@class, 'excerpt')]")images_list = LinkExtractor(allow="sinaimg\.cn/mw690/", restrict_xpaths="//article",tags="img", attrs="src", deny_extensions="")rules = (Rule(pages_list),Rule(articles_list, callback='parse_content', follow=True),Rule(images_list, callback="parse_image") # 提取福利文中的图片链接,发送请求,用parse_images解析响应)def parse_content(self, response):article = ArticleItem()article["title"] = response.xpath("//h1/a/text()")[0].extract()article["publish_time"] = response.xpath('//span[@class="item"][1]/text()')[0].extract()video_list = []video_title_list = response.xpath('//blockquote//a/text()').extract()video_link_list = response.xpath('//blockquote//a/@href').extract()video_tuple_list = zip(video_title_list, video_link_list)for video_title, video_link in video_tuple_list:video_list.append({video_title: video_link})article["videos"] = video_listyield articledef parse_image(self, response):# 获取请求每1张图片的请求头里面的 Referer ,截取其中的7位数字作为保存目录# 灵感来源见下图# dirname = response.request.headers.get("Referer")[-12:-5]dirname = response.request.headers['Referer'][-12:-5]try:with open(dirname + "/" + response.url[-10:], "w") as f:f.write(response.body)except:os.mkdir(dirname)with open(dirname + "/" + response.url[-10:], "w") as f:f.write(response.body)
pipelines.py
# -*- coding: utf-8 -*-
import jsonclass FlhzPipeline(object):def __init__(self):self.file = open("/mnt/hgfs/Ubuntu8Windows/articles.json", "w")self.file.write("[")def process_item(self, item, spider):data = json.dumps(dict(item), ensure_ascii=False)self.file.write(data.encode("utf-8")+", ")return itemdef close_spider(self, spider):self.file.write("]")self.file.close()