目录
- BeautifulSoup库
- 安装BeautifulSoup库
- BeautifulSoup库简介
- 选择解释器
- 基础用法
- 节点选择器
- 获取节点名称属性内容
- 获取所有子节点
- 获取所有子孙节点
- 父节点与兄弟节点
- 方法选择器
- find_all()方法
- find()方法
- CSS选择器
- 嵌套选择节点
- 获取属性与文本
- 通过浏览器直接Copy-CSS选择器
- 实战:抓取酷狗飙升榜榜单
BeautifulSoup库
虽然说XPath比正则表达式用起来方便,但是没有最方便,只有更方便。我们的BeautifulSoup库就能做到更方便的爬取想要的东西。
安装BeautifulSoup库
使用之前,还是老规矩,先安装BeautifulSoup库,指令如下:
pip install beautifulsoup4
其中文开发文档:
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
BeautifulSoup库简介
BeautifulSoup库是一个强大的Python语言的XML和HTML解析库。它提供了一些简单的函数来处理导航、搜索、修改分析树等功能。
BeautifulSoup库还能自动将输入的文档转换为Unicode编码,输出文档转换为UTF-8编码。
所以,在使用BeautifulSoup库的过程中,不需要开发中考虑编码的问题,除非你解析的文档,本身就没有指定编码方式,这才需要开发中进行编码处理。
下面,我们来详细介绍BeautifulSoup库的使用规则。
选择解释器
下面,我们来详细介绍BeautifulSoup库的重点知识。
首先,BeautifulSoup库中一个重要的概念就是选择解释器。因为其底层依赖的全是这些解释器,我们有必要认识一下。博主专门列出了一个表格:
| 解释器 | 使用方式 | 优点 | 缺点 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(code,‘html.parser’) | Python的内置标准库,执行速度适中,容错能力强 | Python2.7.3以及Python3.2.2之前的版本容错能力差 |
| lxml HTML解析器 | BeautifulSoup(code,‘lxml’) | 解析速度快,容错能力强 | 需要安装C语言库 |
| lxml XML解析器 | BeautifulSoup(code,‘xml’) | 解析速度快,唯一支持XML的解析器 | 需要安装C语言库 |
| html5lib | BeautifulSoup(code,‘html5lib’) | 最好的容错性,以浏览器的方式解析文档,生成HTML5格式的文档 | 解析速度慢 |
从上面表格观察,我们一般爬虫使用lxml HTML解析器即可,不仅速度快,而且兼容性强大,只是需要安装C语言库这一个缺点(不能叫缺点,应该叫麻烦)。
基础用法
要使用BeautifulSoup库,需要和其他库一样进行导入,但你虽然安装的是beautifulsoup4,但导入的名称并不是beautifulsoup4,而是bs4。用法如下:
from bs4 import BeautifulSoupsoup = BeautifulSoup('<h1>Hello World</h1>', 'lxml')
print(soup.h1.string)
运行之后,输出文本如下:

节点选择器
基础的用法很简单,这里不在赘述。从现在开始,我们来详细学习BeautifulSoup库的所有重要知识点,第一个就是节点选择器。
所谓节点选择器,就是直接通过节点的名称选择节点,然后再用string属性就可以得到节点内的文本,这种方式获取最快。
比如,基础用法中,我们使用h1直接获取了h1节点,然后通过h1.string即可得到它的文本。但这种用法有一个明显的缺点,就是层次复杂不适合。
所以,我们在使用节点选择器之前,需要将文档缩小。比如一个文档很多很大,但我们获取的内容只在id为blog的div中,那么我们先获取这个div,再在div内部使用节点选择器就非常合适了。
HTML示例代码:
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="utf-8">
<title>我是一个测试页面</title>
</head>
<body>
<ul class="ul"><li class="li1"><a href="https://liyuanjinglyj.blog.csdn.net/">我的主页</a></li><li class="li2"><a href="https://www.csdn.net/">CSDN首页</a></li><li class="li3"><a href="https://www.csdn.net/nav/python" class="aaa">Python板块</a></li>
</ul>
</body>
</html>
下面的一些示例,我们还是使用这个HTML代码进行节点选择器的讲解。
获取节点名称属性内容
这里,我们先来教会大家如何获取节点的名称属性以及内容,示例如下:
from bs4 import BeautifulSoupwith open('demo.html', 'r', encoding='utf-8') as f:html = f.read()
soup = BeautifulSoup(html, 'lxml')
# 获取节点的名称
print(soup.title.name)
# 获取节点的属性
print(soup.meta.attrs)
print(soup.meta.attrs['charset'])
# 获取节点的内容(如果文档有多个相同属性,默认获取第一个)
print(soup.a.string)
# 也可以一层一层的套下去
print(soup.body.ul.li.a.string)
运行之后,效果如下:

这里的注释代码都很详细,就不在赘述。
获取所有子节点
一般来说一个节点的子节点有可能很多,通过上面的方式获取,只能得到第一个。如果要获取一个标签的所有子节点,这里有2种方式。先来看代码:
from bs4 import BeautifulSoupwith open('demo.html', 'r', encoding='utf-8') as f:html = f.read()
soup = BeautifulSoup(html, 'lxml')
# 获取直接子节点
print("获取直接子节点")
contents = soup.head.contents
print(contents)
for content in contents:print(content)
children = soup.head.children
print(children)
for child in children:print(child)
运行之后,效果如下:
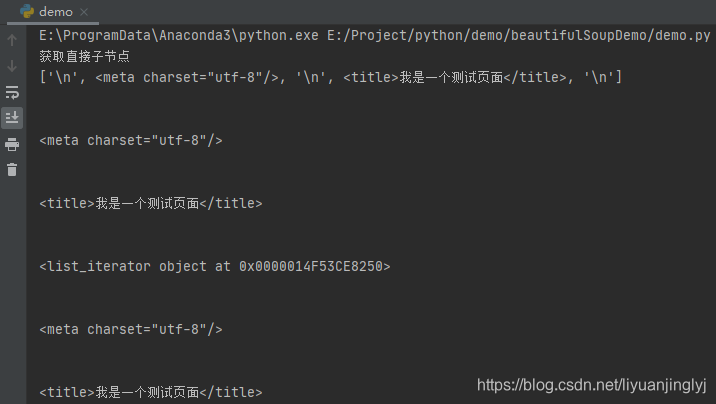
如上面代码所示,我们有2种方式获取所有子节点,一种是通过contents属性,一种是通过children属性,2者遍历的结果都是一样的。
但需要特别注意,这里获取所有子节点,它是把换行符一起算进去了,所以你会看到控制台输出了很多空行。所以,在实际的爬虫中,遍历之时一定要删除这些空行。
获取所有子孙节点
既然能获取直接子节点,那么获取所有子孙节点也是肯定可以的。BeautifulSoup库给我们提供了descendants属性获取子孙节点,示例如下:
from bs4 import BeautifulSoupwith open('demo.html', 'r', encoding='utf-8') as f:html = f.read()
soup = BeautifulSoup(html, 'lxml')
# 获取ul的所有子孙节点
print('获取ul的所有子孙节点')
lis = soup.body.ul.descendants
print(lis)
for li in lis:print(li)
运行之后,效果如下:
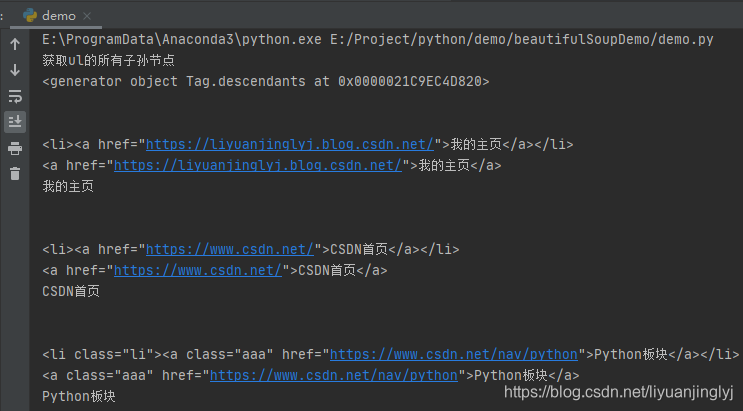
同样的,descendants获取子孙节点也算入了换行符。而且需要特别注意的是,descendants属性把文本内容本身也算作子孙节点。
父节点与兄弟节点
同样的,在实际的爬虫程序中,我们有时候也需要通过逆向查找父节点,或者查找兄弟节点。
BeautifulSoup库,给我们提供了parent属性获取父节点,同时提供了next_sibling属性获取当前节点的下一个兄弟节点,previous_sibling属性获取上一个兄弟节点。
示例代码如下:
from bs4 import BeautifulSoupwith open('demo.html', 'r', encoding='utf-8') as f:html = f.read()
soup = BeautifulSoup(html, 'lxml')
# 获取第一个a标签的父亲节点的class属性
print(soup.a.parent['class'])
li1 = soup.li
li3 = li1.next_sibling.next_sibling.next_sibling.next_sibling
li2 = li3.previous_sibling.previous_sibling
print(li1)
print(li2)
print(li3)
for sibling in li3.previous_siblings:print(sibling)
运行之后,效果如下:
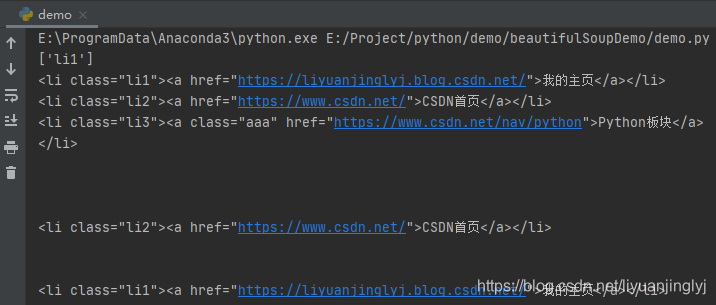
前面已经提示了,节点选择器是把换行符‘\n’也算一个节点,所以第一个li需要通过两个next_sibling才能获取到下一个li节点。同样的,上一个也是。其实还有一个更简单的方法,能避免这些换行符被统计在内,那就是在获取网页源代码的时候,直接去掉换行与空格即可。
方法选择器
对于节点选择器,博主已经介绍了相对于文本内容较少的完全可以这么做。但实际的爬虫爬的网址都是大量的数据,开始使用节点选择器就不合适了。所以,我们要考虑通过方法选择器进行先一步的处理。
find_all()方法
find_all()方法主要用于根据节点的名称、属性、文本内容等选择所有符合要求的节点。其完整的定义如下所示:
def find_all(self, name=None, attrs={}, recursive=True, text=None,limit=None, **kwargs):
| 参数 | 意义 |
|---|---|
| name | 指定节点名称 |
| attrs | 指定属性名称与值,比如查找value="text"的节点,attrs={“value”:“text”} |
| recursive | 布尔类型,值True查找子孙节点,值False直接子节点,默认为True |
| text | 指定需要查找的文本 |
| limit | 因为find_all返回的是一个列表,所以可长可短,而limit与数据库语法类似,限制获取的数量。不设置返回所有 |
【实战】还是测试上面的HTML,我们获取name=a,attr={“class”:“aaa”},并且文本等于text="Python板块"板块的节点。
示例代码如下所示:
from bs4 import BeautifulSoupwith open('demo.html', 'r', encoding='utf-8') as f:html = f.read()
soup = BeautifulSoup(html.strip(), 'lxml')
a_list = soup.find_all(name='a', attrs={"class": 'aaa'}, text='Python板块')
for a in a_list:print(a)
运行之后,效果如下所示:

find()方法
find()与find_all()仅差一个all,但结果却有2点不同:
- find()只查找符合条件的第一个节点,而find_all()是查找符合条件的所有节点
- find()方法返回的是bs4.element.Tag对象,而find_all()返回的是bs4.element.ResultSet对象
下面,我们来查找上面HTML中的a标签,看看返回结果有何不同,示例如下:
from bs4 import BeautifulSoupwith open('demo.html', 'r', encoding='utf-8') as f:html = f.read()
soup = BeautifulSoup(html.strip(), 'lxml')
a_list = soup.find_all(name='a')
print("find_all()方法")
for a in a_list:print(a)
print("find()方法")
a = soup.find(name='a')
print(a)
运行之后,效果如下:

CSS选择器
首先,我们来了解一下CSS选择器的规则:
- .classname:选取样式名为classname的节点,也就是class属性值是classname的节点
- #idname:选取id属性为idname的节点
- nodename:选取节点名为nodename的节点
一般来说,在BeautifulSoup库中,我们使用函数select()进行CSS选择器的操作。示例如下:
from bs4 import BeautifulSoupwith open('demo.html', 'r', encoding='utf-8') as f:html = f.read()
soup = BeautifulSoup(html.strip(), 'lxml')
li = soup.select('.li1')
print(li)
这里,我们选择class等于li1的节点。运行之后,效果如下:

嵌套选择节点
因为,我们需要实现嵌套CSS选择器的用法,但上面的HTML不合适。这里,我们略作修改,仅仅更改<ul>标签内的代码。
<ul class="ul"><li class="li"><a href="https://liyuanjinglyj.blog.csdn.net/">我的主页</a></li><li class="li"><a href="https://www.csdn.net/">CSDN首页</a></li><li class="li"><a href="https://www.csdn.net/nav/python" class="aaa">Python板块</a>
</ul>
我们仅仅删除了li后面的数字,现在我们可以实现一个嵌套选择节点的效果了。示例代码如下所示:
from bs4 import BeautifulSoupwith open('demo.html', 'r', encoding='utf-8') as f:html = f.read()
soup = BeautifulSoup(html.strip(), 'lxml')
ul = soup.select('.ul')
for tag in ul:a_list = tag.select('a')for a in a_list:print(a)
运行之后,效果如下:

获取属性与文本
我们再次将上面的代码改造一下,因为上面获取的标签,现在我们来获取其中的文本以及href属性的值,示例如下:
from bs4 import BeautifulSoupwith open('demo.html', 'r', encoding='utf-8') as f:html = f.read()
soup = BeautifulSoup(html.strip(), 'lxml')
ul = soup.select('.ul')
for tag in ul:a_list = tag.select('a')for a in a_list:print(a['href'], a.get_text())
运行之后,效果如下:

可以看到,我们通过[‘属性名’]进行属性值的获取,通过get_text()获取文本。
通过浏览器直接Copy-CSS选择器
与XPath类似,我们可以直接通过F12浏览器进行Copy任何节点的CSS选择器代码。具体操作如下图所示:


copy之后,直接将上面复制的内容粘贴到select()方法中即可使用。
实战:抓取酷狗飙升榜榜单
上面基本上是BeautifulSoup库的全部用法,既然我们已经学习掌握了,不抓紧爬点什么,总感觉自己很亏,所以我们选择酷狗飙升榜榜单进行爬取。

如上图所示,我们的榜单信息全在id="rankWrap"的div标签下的ul之中。所以,首先我们必须获取ul。示例代码如下:
from bs4 import BeautifulSoup
import requestsurl = "https://www.kugou.com/yy/html/rank.html"
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
result = requests.get(url=url, headers=headers)
print(result.text)
soup = BeautifulSoup(result.text.strip(), 'lxml')
ul = soup.select('#rankWrap > div.pc_temp_songlist.pc_rank_songlist_short > ul')
print(tbody)
获取ul之后,我们就可以在获取其中的所有li节点信息,然后分解li的标签,获取重要的歌曲作者,歌曲名称等。不过,我们先来分析网页li内部代码:

可以看到,我们要的歌曲名称与作者就在li的title属性中,而歌曲的网页链接在li下,第4个span的标签下的a节点的href属性之中(也可以直接就是第一个a标签之中)。知道这些之后,我们可以完善代码了。
from bs4 import BeautifulSoup
import requestsurl = "https://www.kugou.com/yy/html/rank.html"
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
result = requests.get(url=url, headers=headers)
soup = BeautifulSoup(result.text.strip(), 'lxml')
ul = soup.select('#rankWrap > div.pc_temp_songlist.pc_rank_songlist_short > ul')
lis = ul[0].select('li')
for li in lis:print("歌曲名称与歌曲作者:", li['title'])print("歌曲链接:", li.find('a')['href'])
如上面代码所示,我们只用了不到14行代码,就可以爬取酷狗音乐的飙升榜单,BeautifulSoup库是不是非常的强大呢?