PyTorch官方教程(中文版)
- TENSOR概述
- 初始化向量
- 对Tensor的操作
- 转移存储位置到GPU
- 张量的切片操作
- 张量的合并操作
- 张量乘法
- 将单元素tensor转换为基本数据类型
- 与NumPy的联系
- tensor转numpy
- numpy转tensor
- DATASETS & DATALOADERS
- 载入数据集
- 迭代和可视化数据集
- 创建自定义数据集的文件
- 使用DataLoaders准备数据
- 通过DataLoader进行迭代
- TRANSFORMS
- BUILD THE NEURAL NETWORK
- 确定训练位置
- 定义神经网络类
- AUTOMATIC Differentiation
- 张量、函数和计算图
- 梯度计算
- 禁用梯度跟踪
- 方法1
- 方法2
- 关于计算图的知识
- OPTIMIZING MODEL PARAMETERS
- 超参数
- 优化循环
- 损失函数
- 优化器
- 完整代码
- SAVE AND LOAD THE MODEL
- 保存和加载模型权重
- 保存
- 加载
- 保存和加载模型
TENSOR概述
Tensors 是一种特殊的数据结构,与数组和矩阵非常类似。在PyTorch中,我们使用张量来编码模型的输入、输出,也包括模型参数。
初始化向量
import torch
import numpy as np# 方式1:直接使用数据初始化
data = [[1, 2],[3, 4]]
x_data = torch.tensor(data)# 方式2:使用Numpy数组
np_array = np.array(data)
x_np = torch.from_numpy(np_array)# 方式3:使用另一个tensor
x_ones = torch.ones_like(x_data)
print(f"Ones Tensor: \n {x_ones} \n") # 保留了x_data维度、数据类型的任意1值张量
x_rand = torch.rand_like(x_data, dtype=torch.float) # 覆写了x_data数据类型为float,维度不变的任意值张量
print(f"Random Tensor: \n {x_rand} \n")# shape定义了张良的维度
shape = (2,3,)
rand_tensor = torch.rand(shape)
ones_tensor = torch.ones(shape)
zeros_tensor = torch.zeros(shape)print(f"Random Tensor: \n {rand_tensor} \n") # 生成元素为随机值的符合shape维度的张量
print(f"Ones Tensor: \n {ones_tensor} \n") # 生成元素为1的符合shape维度的张量
print(f"Zeros Tensor: \n {zeros_tensor}") # 生成元素为0的符合shape维度的张量# 创建一个任意的(3, 4)维度的张量,展示其属性如下
tensor = torch.rand(3,4)
print(f"Shape of tensor: {tensor.shape}") # 张量的维度
print(f"Datatype of tensor: {tensor.dtype}") # 张量的数据类型
print(f"Device tensor is stored on: {tensor.device}") # 张量的存储设备对Tensor的操作
对Tensor的100种操作,包括算数运算、线性代数、矩阵操作、采样等,这些操作点这里均有对其的详细描述。
转移存储位置到GPU
默认情况下tensor是在CPU创建的,需要使用以下方法将其转到GPU:
if torch.cuda.is_available():tensor = tensor.to('cuda')
张量的切片操作
其实与Numpy相当类似
# tensor的操作大多类似于numpy:
tensor = torch.ones(4, 4)
print('First row: ',tensor[0])
print('First column: ', tensor[:, 0])
print('Last column:', tensor[..., -1])
tensor[:,1] = 0
print(tensor)# 输出为
First row: tensor([1., 1., 1., 1.])
First column: tensor([1., 1., 1., 1.])
Last column: tensor([1., 1., 1., 1.])
tensor([[1., 0., 1., 1.],[1., 0., 1., 1.],[1., 0., 1., 1.],[1., 0., 1., 1.]])
张量的合并操作
t1 = torch.cat([tensor, tensor, tensor], dim=1)
print(t1)
其中,dim参数用于表示张量的维数(从0开始)
例如:对于二维张量0表示行,1表示列
对于三维张量0表示深度,1表示行,2表示列
对于高维张量,每个维度表示不同的方向或轴
张量乘法
# 两个张量之间的区镇乘法,即tensor与其转置之间的乘积
y1 = tensor @ tensor.T
y2 = tensor.matmul(tensor.T)y3 = torch.rand_like(tensor)
torch.matmul(tensor, tensor.T, out=y3)# 两个张量对应位置元素相乘
z1 = tensor * tensor
z2 = tensor.mul(tensor)z3 = torch.rand_like(tensor)
torch.mul(tensor, tensor, out=z3)
将单元素tensor转换为基本数据类型
agg = tensor.sum()
agg_item = agg.item()
print(agg_item, type(agg_item)) # 输出:12.0 <class 'float'>
与NumPy的联系
tensor转numpy
t = torch.ones(5)
print(f"t: {t}")
n = t.numpy()
print(f"n: {n}")# tensor与numpy共用一个底层内存,此处更改tensor对应n的值也会修改
t.add_(1)
print(f"t: {t}")
print(f"n: {n}")
numpy转tensor
n = np.ones(5)
t = torch.from_numpy(n)# tensor与numpy共用一个底层内存,此处更改n对应t的值也会修改
np.add(n, 1, out=n)
print(f"t: {t}")
print(f"n: {n}")
DATASETS & DATALOADERS
两者存在的意义在于将数据集代码与模型训练代码解耦,提高代码可读性与模块化性。
PyTorch提供的Dataset库包含了一些预加载的数据集(例如FashionMNIST)
载入数据集
以下是一个从TorchVision加载Fashion-MNIST数据集的例子。
将使用以下参数加载Fashion-MNIST数据集:
- root 数据集(训练/测试)数据集存储目录
- train 指定训练集还是测试集
- download=True 如果root中没有数据集时进行下载
- transform and target_transform指定特征和标签的转换操作,其中transform用于对输入的图像数据进行预处理或增强操作,target_transform参数用于对标签进行转换操作,例如将标签进行编码或者进行其他预处理。
import torch
from torch.utils.data import Dataset
from torchvision import datasets
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plttraining_data = datasets.FashionMNIST(root="data",train=True, # 这里表示加载训练集download=True,transform=ToTensor()
)test_data = datasets.FashionMNIST(root="data",train=False, # 这里表示不加载训练集download=True,transform=ToTensor()
)
迭代和可视化数据集
将dataset视为一个列表而使用 training_data[index] 来get数据
使用matplotlib可视化训练数据中的样例
# 定义一个标签映射字典labels_map
labels_map = {0: "T-Shirt",1: "Trouser",2: "Pullover",3: "Dress",4: "Coat",5: "Sandal",6: "Shirt",7: "Sneaker",8: "Bag",9: "Ankle Boot",
}
# 创建一个名为figure的图像对象,设置大小为8*8英寸
figure = plt.figure(figsize=(8, 8))
# 定义要显示的子图列数和行数(如下图所示)
cols, rows = 3, 3
for i in range(1, cols * rows + 1):# 此处,len(training_data)用于返回训练集长度,size = (1,).item指定生成一个一维# 随机数张量并将其转换为python标量用于获取索引值(int型)sample_idx = torch.randint(len(training_data), size=(1,)).item() # 在pytorch中,使用索引访问一个数据集对象时,该对象返回的是一个tuple包含图像+标签img, label = training_data[sample_idx]# 添加子图到figure中figure.add_subplot(rows, cols, i)# 设置子图标题为label对应标签plt.title(labels_map[label])plt.axis("off") # 关闭子图的坐标轴显示,使子图不显示坐标轴刻度和标签# 将压缩后的图像数据以灰度映射的形式显示plt.imshow(img.squeeze(), cmap="gray") # squeeze用于压缩图像维度
plt.show()

创建自定义数据集的文件
一个自定义数据集文件必须包含三个函数:init,len,and getitem
import os
import pandas as pd
from torchvision.io import read_imageclass CustomImageDataset(Dataset):# annotations_file表示包含图像标签的CSV文件路径# img_dir表示图像文件所在的目录路径# transform表示对图像进行的变换操作# target_transform表示对标签进行的变换操作def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):self.img_labels = pd.read_csv(annotations_file)self.img_dir = img_dirself.transform = transformself.target_transform = target_transformdef __len__(self): # 返回数据集中样本数量return len(self.img_labels)# 根据给定的索引idx获取图像和标签def __getitem__(self, idx):img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])# 获取索引idx图像对应相对目录:self.img_dir+self.img_labels.iloc[idx, 0 ]即第idx+1行的第一列数据image = read_image(img_path) # 读取图像label = self.img_labels.iloc[idx, 1] # 获取标签
# 这些转换操作的目的是根据需求对数据进行预处理或编码,
# 以便在模型训练或推断过程中能够更好地处理和使用数据。
# 具体的转换方式可以根据实际需求和数据的特点来确定,即是给定的。if self.transform:image = self.transform(image)if self.target_transform:label = self.target_transform(label)return image, label
使用DataLoaders准备数据
使用原因:以小批量方式输入数据,而不是一次性将整个数据集加载到内存中。
在每个epoch(训练周期)开始前重新洗牌数据可以减少模型过拟合,这些都可以通过DataLoaders实现
from torch.utils.data import DataLoadertrain_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)
通过DataLoader进行迭代
# 展示从DataLoader中加载的一个样本的图像和标签
# next(iter(...))即从迭代器中获取下一个元素,即获取DataLoader中的一个批次数据
train_features, train_labels = next(iter(train_dataloader))# 获取图像和标签的维度信息,以方便知道如何进行处理
print(f"Feature batch shape: {train_features.size()}")
print(f"Labels batch shape: {train_labels.size()}")# 使用squeeze()函数将图像维度去除以满足imshow()函数的输入要求
img = train_features[0].squeeze()
label = train_labels[0]
plt.imshow(img, cmap="gray")
plt.show()
print(f"Label: {label}")
TRANSFORMS
在初始化时有提供的参数,其中包含对图像的处理transform和对标签的处理target_transform
import torch
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda# MNIST数据集中默认图像格式是PIL,标签格式是整数,此处我们编写代码将图像转换为tensor,
# 标签转化为独热编码(one-hot encoded)
ds = datasets.FashionMNIST(root="data",train=True,download=True,transform=ToTensor(),# 此处定义了一个lambda函数,将标签转换为一个大小为10的全0张量# torch.zeros(x, dtype = y)创建一个大小为x类型为y的全零张量# 使用scatter_(x, y, value = z)函数将位置y的元素更改为数值z,x表示在哪个维度更改,这里为行target_transform=Lambda(lambda y: torch.zeros(10, dtype=torch.float).scatter_(0, torch.tensor(y), value=1))
)
BUILD THE NEURAL NETWORK
首先我们导入所需包
import os
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
确定训练位置
device = ("cuda"if torch.cuda.is_available()else "mps"if torch.backends.mps.is_available()else "cpu"
)
print(f"Using {device} device")
定义神经网络类
我们通过继承nn.Module来定义我们的神经网络,并在__init__中初始化神经网络层。并通过重写forward函数定义对数据的操作
class NeuralNetwork(nn.Module):def __init__(self):super().__init__()# nn.Flatten()用于将二维图像数据展平为一维,以方便使用其作为全连接层的输入self.flatten = nn.Flatten()self.linear_relu_stack = nn.Sequential(nn.Linear(28*28, 512),nn.ReLU(),nn.Linear(512, 512),nn.ReLU(),nn.Linear(512, 10),)def forward(self, x):x = self.flatten(x)logits = self.linear_relu_stack(x)return logitsmodel = NeuralNetwork().to(device)
print(model)
AUTOMATIC Differentiation
(自动微分)在训练神经网络时,最常使用的算法是反向传播。在该算法中,根据损失函数相对于给定参数的梯度(gradient)来调整参数(模型权重)。
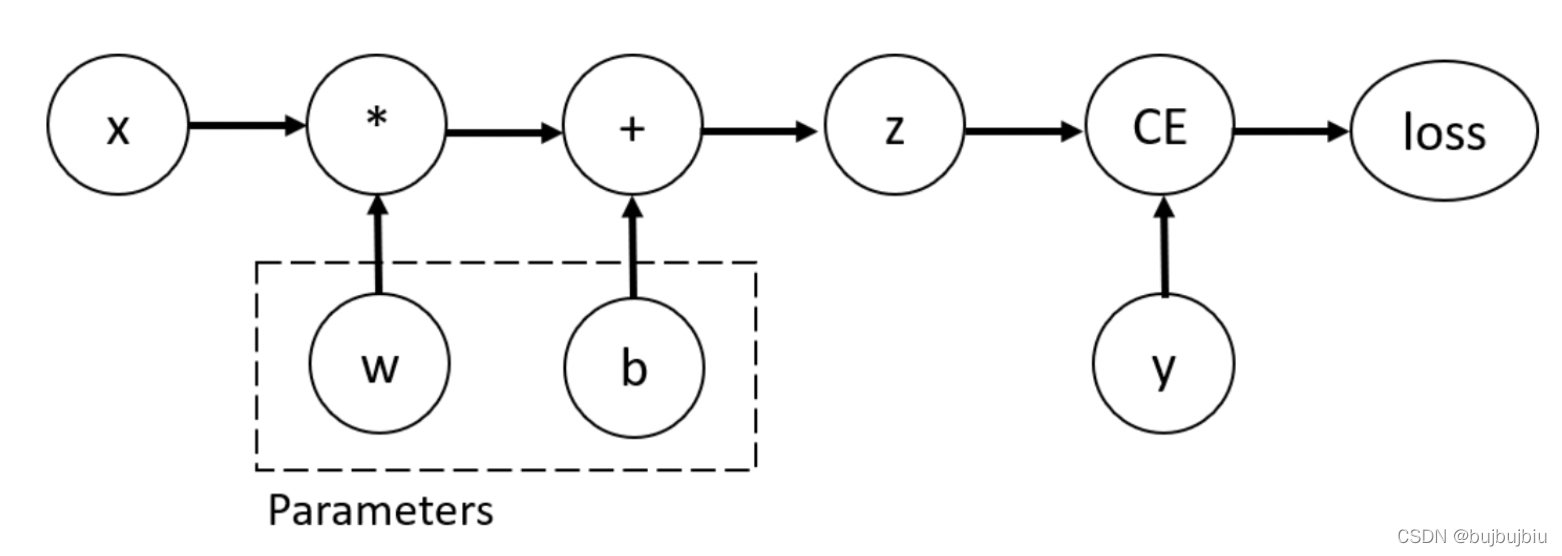
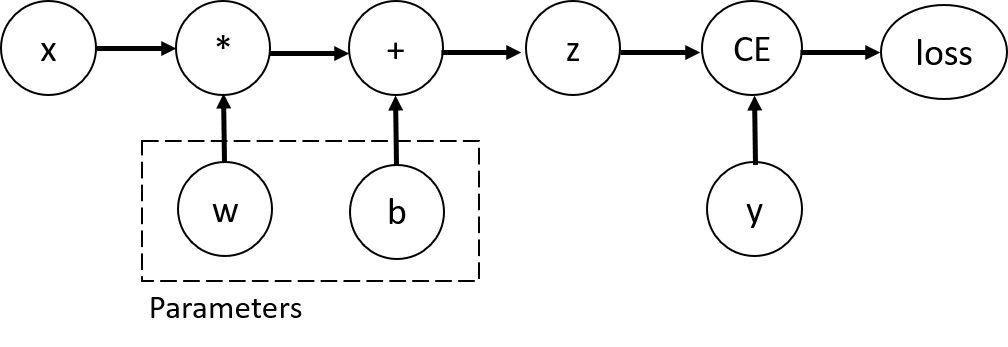
为了计算梯度,pytorch提供了torch.autograd内置函数来计算梯度,它支持对任何计算图进行自动计算梯度。考虑一个最简单的单层神经网络,它包含输入x、参数w和b以及一些损失函数。可以使用PyTorch按照以下方式定义它:
import torchx = torch.ones(5) # input tensor
y = torch.zeros(3) # expected output
# requires_grad=True表示希望对该张量进行梯度计算
w = torch.randn(5, 3, requires_grad=True) # 权重张量
b = torch.randn(3, requires_grad=True) # 偏置张量
z = torch.matmul(x, w)+b# 使用二进制交叉熵损失函数计算预测张量z和目标输出张量y之间的损失。
loss = torch.nn.functional.binary_cross_entropy_with_logits(z, y)
张量、函数和计算图
上述代码定义了以下计算图:
梯度计算
loss.backward()
print(w.grad)
print(b.grad)
我们只能获取计算图中叶节点(leaf nodes)的grad属性,这些叶节点的requires_grad属性被设置为True。对于计算图中的其他节点,梯度将不可用。
出于性能原因,我们只能对给定的计算图执行一次反向传播操作。如果我们需要在同一计算图上进行多次反向传播调用,我们需要在backward调用中传递retain_graph=True参数。
禁用梯度跟踪
使用场景:
1、将神经网络中的某些参数标记为冻结参数。
2、在只进行前向传播时加快计算速度,因为不跟踪梯度的张量的计算会更高效。
方法1
默认情况下,所有requires_grad=True的张量都会跟踪其计算历史并支持梯度计算。(即pytorch会自动计算梯度并进行反向传播,实现例如梯度下降的优化算法来更新模型参数有)而某些情况下,我们不需要反向传播,例如在推理阶段只进行前向计算而不需要反向传播。此时,我们可以使用torch.no_grad()块来临时禁用梯度跟踪,以提高计算效率:
z = torch.matmul(x, w)+b
print(z.requires_grad)with torch.no_grad(): # 上下文管理器,临时禁用梯度跟踪z = torch.matmul(x, w)+b
print(z.requires_grad)
方法2
另一个达到相同结果的方法是使用在张量上使用detach()方法:
z = torch.matmul(x, w)+b
z_det = z.detach()
print(z_det.requires_grad)
关于计算图的知识
在概念上,自动求导(autograd)在一个有向无环图(DAG)中保留了数据(张量)和执行的所有操作(以及生成的新张量)。在这个图中,叶子节点是输入张量,根节点是输出张量。通过从根节点到叶子节点的追踪,可以使用链式法则自动计算梯度。
在前向传播中,自动求导同时执行两个操作:
- 运行所请求的操作以计算结果张量
- 在DAG中维护操作的梯度函数。
当在DAG的根节点上调用.backward()时,反向传播开始。然后,自动求导执行以下操作:
-
从每个.grad_fn计算梯度,
-
将梯度累积到相应张量的.grad属性中,
-
使用链式法则传播到叶子张量。
通过自动求导,可以自动计算出模型参数相对于损失函数的梯度,从而使用梯度下降等优化算法来更新模型的参数。这种自动计算梯度的功能使得神经网络的训练和优化变得更加便捷和高效。
在PyTorch中,DAG(有向无环图)是动态的。需要注意的一点是,图是从头开始重新创建的;在每次调用.backward()后,自动求导会开始构建一个新的图。这正是允许您在模型中使用控制流语句的原因;如果需要,您可以在每次迭代中更改形状、大小和操作。这种动态的图结构使得模型能够灵活地适应不同的输入和计算需求。
OPTIMIZING MODEL PARAMETERS
超参数
超参数是可以调整的参数,用于控制模型优化过程。不同的超参数值可以影响模型的训练和收敛速度(可以关于超参数调优的内容)。
我们为训练定义了以下超参数:
-
Epochs(训练轮数):迭代数据集的次数。
-
Batch Size(批大小):在更新参数之前通过网络传播的数据样本数。
-
Learning Rate(学习率):控制每个批次/轮次中更新模型参数的幅度。较小的学习率会导致学习速度较慢,而较大的学习率可能在训练过程中产生不可预测的行为。
learning_rate = 1e-3
batch_size = 64
epochs = 5
优化循环
初始化超参数后,我们可以使用循环训练并优化我们的模型。每一个循环的迭代叫做一个epoch,每一个epoch包含两个主要部分:
- The Train Loop:遍历训练数据集并尝试收敛到最优参数
- The Validation/Test Loop:遍历测试数据集以检查模型性能是否有所改善
损失函数
损失函数衡量了预测值与目标值的不相似程度,训练过程中的目标便是最小化损失函数。
常见的损失函数包括
- 用于回归任务(例如房价预测)的nn.MSELoss
- 用于分类任务的nn.NLLLoss
- 综合前两者的n.CrossEntropyLoss
# Initialize the loss function
loss_fn = nn.CrossEntropyLoss()
优化器
优化器是用于调整模型参数以减少训练步骤中的模型误差的过程。优化算法定义了这个过程的执行方式(在这个例子中,我们使用随机梯度下降算法)。所有的优化逻辑都封装在优化器对象中。在这里,我们使用SGD优化器;此外,PyTorch还提供了许多不同的优化器,如ADAM和RMSProp,它们针对不同类型的模型和数据效果更好。
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate) # 自动识别损失函数
在训练循环中,优化过程包含三个步骤(优化器自己完成的):
1、调用optimizer.zero_grad()将模型参数的梯度重置为零。默认情况下,梯度会累加;为了防止重复计算,我们在每次迭代时显式地将它们清零。
2、通过调用loss.backward()对预测损失进行反向传播。PyTorch会计算损失相对于每个参数的梯度。
3、一旦获得了梯度,我们调用optimizer.step()根据反向传播收集的梯度来调整参数。
完整代码
import torch
from torchvision import datasets
from torchvision.transforms import ToTensor
from torch import nn
from torch.utils.data import DataLoader# 数据集下载
training_data = datasets.FashionMNIST(root='data',train=True,download=True,transform=ToTensor()
)test_data = datasets.FashionMNIST(root='data',train=False,download=True,transform=ToTensor()
)train_dataloader = DataLoader(training_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)# 定义神经网络
class NeuralNetwork(nn.Module):def __init__(self) -> None:super().__init__() # 继承初始化函数self.flatten = nn.Flatten() # 展平层self.linear_relu_stack = nn.Sequential(nn.Linear(28*28, 512),nn.ReLU(),nn.Linear(512, 512),nn.ReLU(),nn.Linear(512, 10),)def forward(self, x):x = self.flatten(x)logits = self.linear_relu_stack(x) # 得到模型对输入张量的预测结果return logits# 定义优化循环以优化参数
def train_loop(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset)for batch, (X, y) in enumerate(dataloader):# Compute prediction and losspred = model(X)loss = loss_fn(pred, y)# Backpropagationloss.backward()optimizer.step()optimizer.zero_grad()if batch % 100 == 0:loss, current = loss.item(), (batch + 1) * len(X)print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")# 定义测试循环以查看参数优化情况
def test_loop(dataloader, model, loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)test_loss, correct = 0, 0with torch.no_grad():for X, y in dataloader:pred = model(X)test_loss += loss_fn(pred, y).item()correct += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss /= num_batchescorrect /= sizeprint(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")# 实例化对象
model = NeuralNetwork()
learning_rate = 1e-3
batch_size = 64
epochs = 5
# 初始化损失函数和优化器,并将其传递给train_loop与test_loop
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)epochs = 10
for t in range(epochs):print(f"Epoch {t+1}\n-------------------------------")train_loop(train_dataloader, model, loss_fn, optimizer)test_loop(test_dataloader, model, loss_fn)
print("Done!")
SAVE AND LOAD THE MODEL
保存和加载模型权重
保存
通过torch.save()将参数保存在名为state_dict的内部状态字典中
model = models.vgg16(weights='IMAGENET1K_V1')
torch.save(model.state_dict(), 'model_weights.pth')
加载
要加载模型权重,需要先创建相同模型实例,然后使用load_state_dict()方法加载参数
model = models.vgg16() # we do not specify ``weights``, i.e. create untrained model
model.load_state_dict(torch.load('model_weights.pth'))
model.eval()
保存和加载模型
这里介绍一种将模型传递给保存函数而不是参数的方法:
torch.save(model, 'model.pth') # 保存模型
model = torch.load('model.pth') # 加载模型