代码是正经代码,但是程序员正不正经就不知道了。

前言
在使用爬虫对某些网站进行爬取时,为了不让网站发现我们的ip,模拟其他用户ip地址去访问网站。也就相当于间接的去访问网站,流程如图:
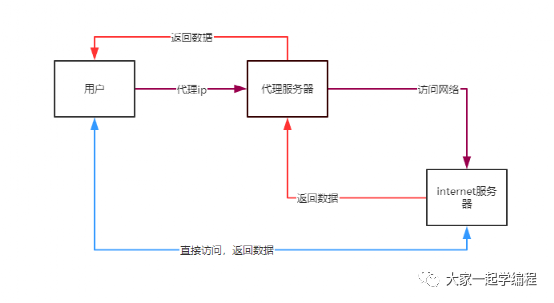
我们使用到代理服务器,去间接访问网络,并通过代理返回数据。而不是走直接访问这条流程。
正文阅读
第一、什么是代理服务器
代理服务器(Proxy Server)的功能是代理网络用户去取得网络信息。形象地说,它是网络信息的中转站,是个人网络和Internet服务商之间的中间代理机构,负责转发合法的网络信息,对转发进行控制和登记。

第二、Requests请求使用代理。
在已经知道一个代理ip之后,我们如何使用呢?
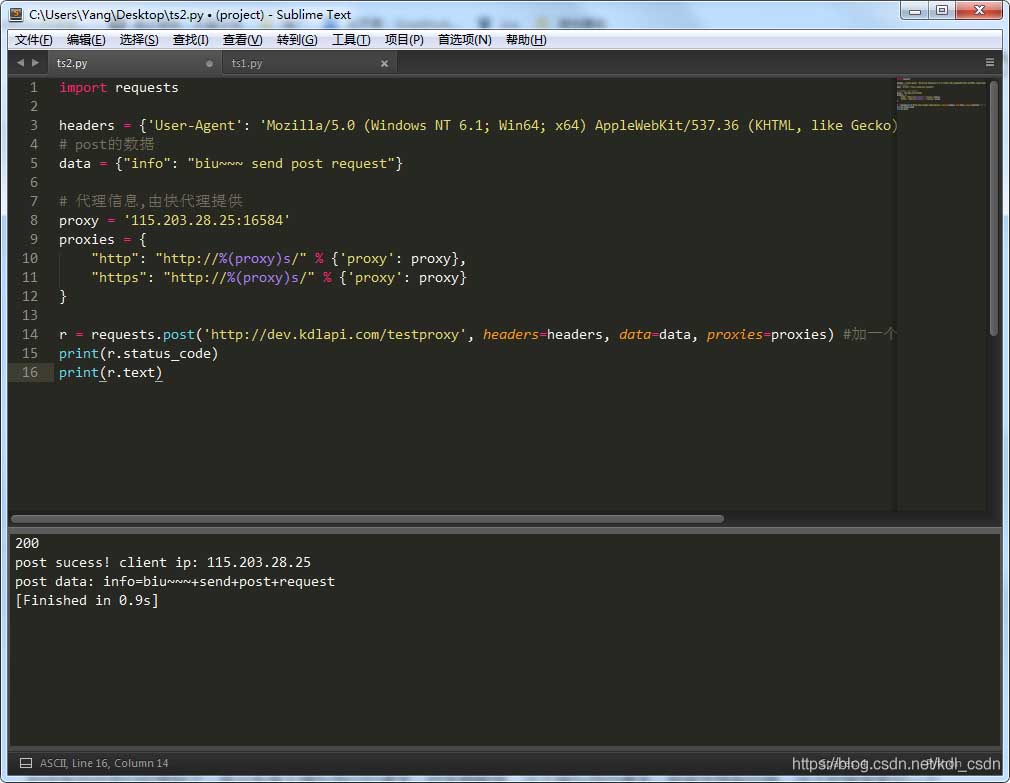
import requests
response=requests.get("http://www.baidu.com",proxies={"http":"127.0.0.1:1245"})
print(response.text)
在使用requests模块去请求接口时,便可以通过参数proxies 来进行传输,将所需要的代理ip进行设置。
第三、本地计算机如何使用代理服务器。
已经学会了如何请求接口时,添加代理,那如何为本地结算机设置代理呢。
找到我们的代理ip,然后按照下面的操作进行。
方法1:手动设置代理
1、按win键,或者打开ie浏览器
2、搜索internet选项,或者在ie浏览器右上角设置选择internet选项。
3、点击连接,找到局域网设置
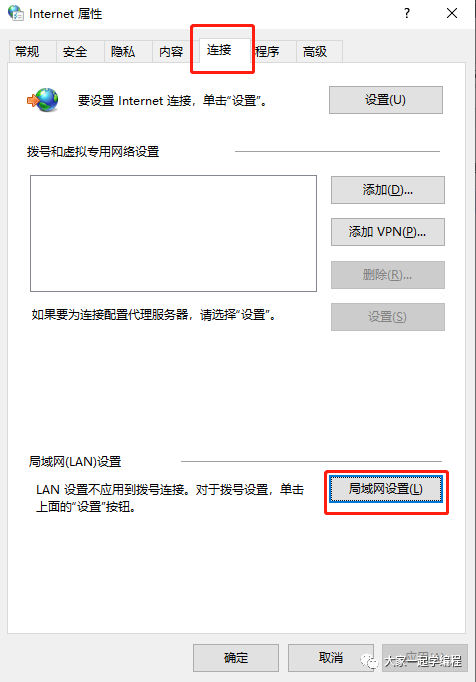
4、勾选代理,并设置ip地址,端口。
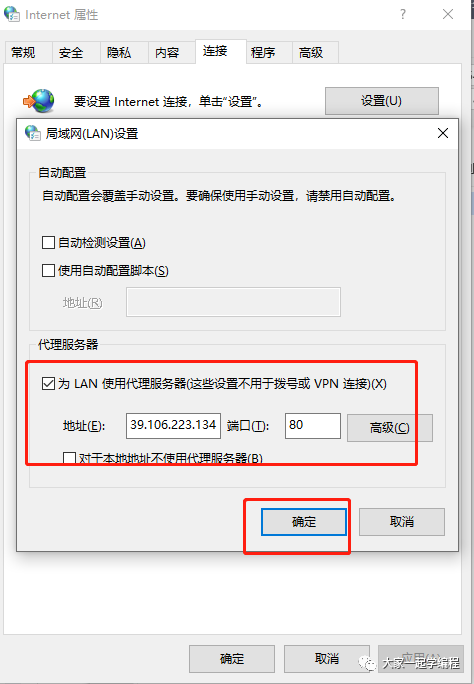
这样,我们就成功设置了代理,接下来访问的所有数据都会传输到这个代理ip中。
方法2:直接使用命令行修改
这么修改也太麻烦了一点,直接使用命令行来解决是不是要简单一点呢?
设置代理:
@echo off
echo 设置代理服务器……
reg add "HKCU\Software\Microsoft\Windows\CurrentVersion\Internet Settings" /v ProxyEnable /t REG_DWORD /d 1 /f
reg add "HKCU\Software\Microsoft\Windows\CurrentVersion\Internet Settings" /v ProxyServer /d "39.106.223.1342:80" /f
start iexplore.exe
Pause取消代理:
@echo off
echo 取消代理服务器……
reg add "hkcu\Software\Microsoft\Windows\CurrentVersion\Internet Settings" /v ProxyEnable /t REG_DWORD /d 0x0 /f
start iexplore.exe
Pause这里为什么要启动一下ie浏览器呢?主要是为了让我们的配置生效,找了一些方法都不能生效,启动一下ie浏览器生效比较快,还简单。
第四、验证计算机代理ip是否有用,服务器接收情况。
我们已经设置成功了,那我们访问网站时是否有效呢?抱着这个因为,我们继续来往下看。
需要做验证,那我们需要用到服务端。当我们请求服务器时,显示的ip,我们就可以知道是否生效。
服务器端:我们需要在服务器端搭建一个简易网站,我们可以通过服务器打印的日志看出当前请求的ip,这里我们使用的是windows服务器,如果有兴趣研究学习的,可以先花五十元,去买一个月那种便宜的服务器玩一下。当然用途不只是研究本课题,还有其他用途。
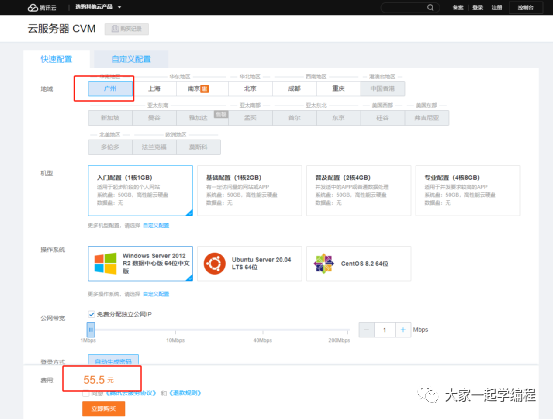
代码如下:
from flask import *
app = Flask(__name__)
@app.route('/')
def index():ip = request.remote_addr#获取用户ipreturn "你的ip为"+ip
if __name__ == '__main__':app.run(host="0.0.0.0",port=8088)#0000,允许所有用户访问,127.0.0.1允许本地用户访问。这里,使用我的服务器ip便可以访问,http://123.207.31.148:8088/,网站:http://www.djyqxbc.vip当我们访问这个链接,然后就可以查询到ip。
1、原始ip
用户端显示:

服务器端请求情况:
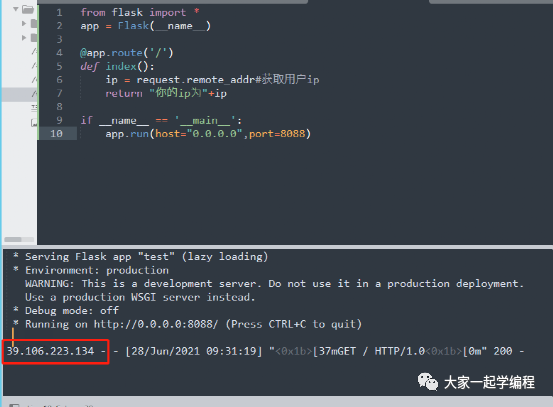
Ok,成功获取到我们的ip,接下来,我们换一个代理ip试一下。
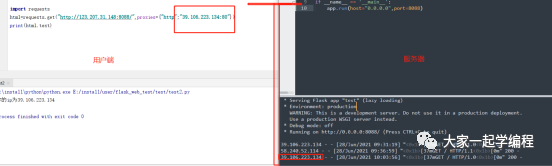
2、代理ip
我们使用代理ip为58.240.52.114:80。
用户端显示:

服务器端显示情况:

我们可以通过这个简单的例子看出,我们本地使用的代理ip是生效的,那使用requests模块请求呢,如图,我们可以看到,是相同的结果。那说明代理ip对于服务器端来说,的确能起到掩盖ip的作用。
第五、Fiddle代理,安全,以及相关工具。
在本地设置代理方法有很多,比如上面提到的第三条。然后还有:
Fiddle工具,如图,我们可以通过设置代理端口来设置,本地请求的数据,都会发送到127.0.0.1:8888:
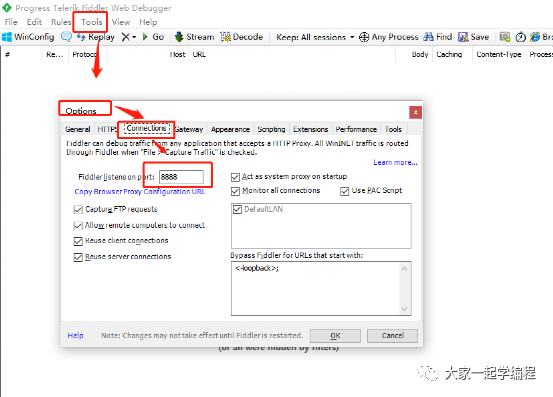
Fiddle只是其中一个,也是我们测试同学常用的一个软件。另外还有jmeter也同样可以设置代理,添加一个代理服务器。

当然,还有其他很多工具,这里就不一一列举了。
Fiddle常用于爬虫分析,安全分析,测试同学测试抓包。
这里能不能拦截使用代理呢。当你使用了代理进行访问时,禁止访问。
1、Js,app判断是否系统设置代理,如果设置代理,给出警告,不加载数据
优点:快,缺点:用户修改js代码,替换js,依然可以访问。但一般用户操作不了。多数人都是正常访问的。
2、限制代理ip访问,建立一个代理ip库,将市面上的代理ip存储进去,用户访问时,与代理ip库对比。如果有就直接禁制。
优点,能限制大多数代理ip。缺点:额外增加查询步骤,速度降低。
3、不限制。普通用户一般不这样操作,也不会,做好用户检验,没有这个用户,你有代理ip也还是这个用户。你换用户,随你换好了。
当然大家还有什么好的方式也可以在评论区讨论哦。
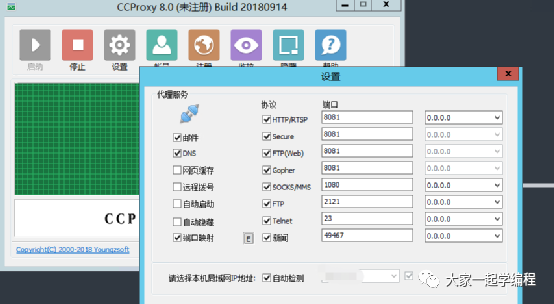
第六、搭建一个自己的代理服务器
搭建代理服务器,需要使用到一款软件,ccproxy。
资源链接(已破解):公众号回复“代理服务器”便可获取
将这款软件安装到你的服务器上,并启动,通过设置,我们可以设置代理端口号。根据对应需要服务进行设置端口号。
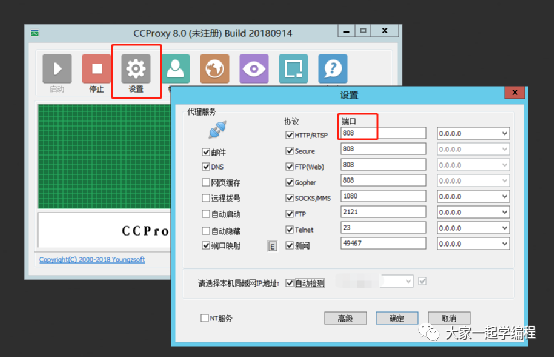
这样,我们的代理服务器就搭建好了,代理ip:123.207.31.148:808然后我们来验证我们代理是否有效。
第七、代理服务器有效性验证。
想要验证我们自己搭建的代理服务器是否有效,那我们这次直接来看,request模块是否有效,需要做的是对比代理服务器启动前后的变化来判断。
1、代理服务未启动时
关闭代理,并请求接口,会提示代理服务器错误,就说明没有这个代理:
import requests
response=requests.get("http://123.207.31.148:8088/",proxies={"http":"123.207.31.148:808"})
print(response.text)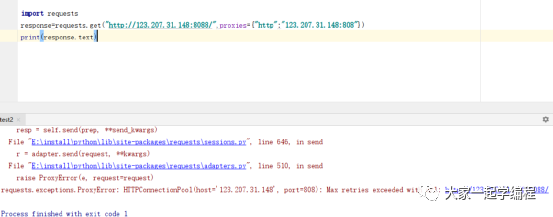
2、代理服务器启动时
我们启动代理服务器,再来请求一下,我们可以从下面两幅图,以及和上面做出对比,ip也是我们设置的代理服务器,我们的代理服务器有效。
用户端:
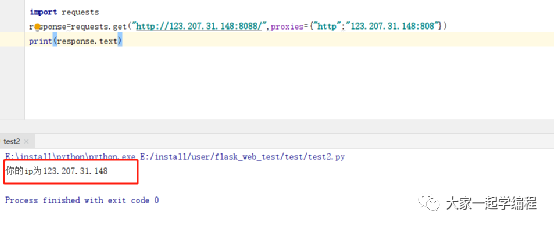
服务器端:

3、修改代理服务器端口
我们将原来的808端口修改为8081,再来试一下。808也就不再生效。
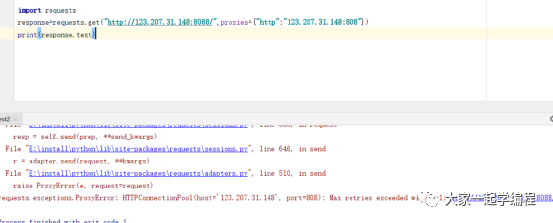
8081请求:
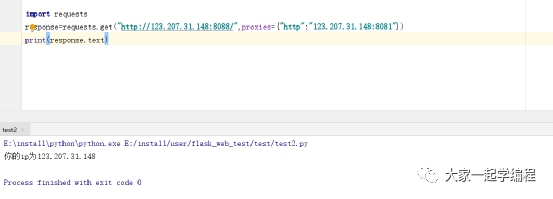
这样,我们的代理服务器也就说明设置是有效的。
第八、爬取代理服务器
我们一个代理服务器已经搞定了,相同的,当我们有几百,上千个服务器,都搭建了代理服务器,那我们是不是拥有了自己的代理ip池。但我们没那么多钱,也没必要。只能去用别人的了。
代理ip池获取,代码如下:
import requests
from bs4 import BeautifulSoup
def proxy_ip(protocol=["http"],anonlv1=[],country=["CN"]):""":param protocol: 请求方式:http,https,socks4,socks5:param anonlv1: 级别:1,2,3,4 L1 – 透明,L2 – 匿名,L3 – 扭曲,L4 – 精英:param country: 国家,无为全部,CN 中国:return:ip_list,ip列表"""text=""for i in protocol:text+="protocol="+i+"&"for i in anonlv1:text+="anonlv1="+i+"&"for i in country:text+="country="+i+"&"global headersheaders={'Cookie': '_ga=GA1.2.1786575828.1619658683; _gid=GA1.2.555491280.1623999959; _gat=1','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36'}response=requests.get("http://proxydb.net/?"+text,headers=headers)Soup = BeautifulSoup(response.text, "html.parser")table = Soup.find_all("table")[0].find_all("a")list=[]for i in table:ip=i.get_text()list.append(ip)return list文章总结
通过本文,你可以了解到
1、requests模块如何设置代理。
2、代理ip设置是否真有效。
3、如何搭建自己的代理服务器。
4、代理ip池的获取。
处于安全方面来说,因为我们请求时,数据会发送到代理服务器,如果请求在账号密码是明文的情况下,代理服务器就可以获取到你的账号信息。
同理,翻墙软件也是一种代理,只不过他代理到国外去了。翻墙软件也是能获取到你的用户信息的哦,所以大家需要注意个人信息安全呀。

相关推荐:
(tkinter)撩妹弹窗(3)之不要越过三八线,canvas的使用方法
过分了,别人用来做桌面应用开发,这家伙却用来撩妹(2)-上帝给你开了各种撩妹窗口(Tkinter)
过分了,别人用来做桌面应用开发,这家伙却用来撩妹(1)--上帝给你开一个窗口(Tkinter)—tkinter常用函数解析
定时任务