提示:文末有福利!最新Python爬虫资料/学习指南>>戳我直达
文章目录
- 前言
- Urllib2库
- 学习目的
- urlopen
- GET请求方式
- 利用urllib2.Request类,添加Header信息
- POST请求方式
- 抓取招聘信息
- 思考一下
- 小结
- 总结
前言
Urllib2库
urllib2是python2.7自带的模块(不需要下载),它支持多种网络协议,比如 FTP、HTTP、HTTPS等
urllib2在python3.x中被改为urllib.request
话不多说,开始学习

Urllib2库
学习目的
利用urllib2提供了一个接口 urlopen函数
urllib2 官方文档
https://docs.python.org/2/library/urllib2.html
urlopen
urlopen(url, data, timeout,....)
(1)第一个参数url即为URL,第一个参数URL是必须要传送的
(2)第二个参数data是访问URL时要传送的数据,data默认为空None
(3)第三个timeout是设置超时时间,timeout默认为 60s(socket._GLOBAL_DEFAULT_TIMEOUT)
GET请求方式
以抓取 http://www.itcast.cn为例
import urllib2
response = urllib2.urlopen('http://www.itcast.cn/')
data = response.read()
print data
print response.code
保存成 demo.py,进入该文件的目录,执行如下命令查看运行结果,感受一下。
python demo.py

利用urllib2.Request类,添加Header信息
利用urllib2.Request方法,可以用来构造一个Http请求消息
help(urllib2.Request)

正则:headers 转dict
^(.*):\s(.*)$
"\1":"\2",
# -*- coding: utf-8 -*-
import urllib2
get_headers={'Host': 'www.itcast.cn','Connection': 'keep-alive','Pragma': 'no-cache','Cache-Control': 'no-cache','Upgrade-Insecure-Requests': '1','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36','Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',#此处是压缩算法;不便于查看,要做解压#'Accept-Encoding': 'gzip, deflate, sdch','Accept-Language': 'zh-CN,zh;q=0.8','Cookie': 'pgv_pvi=7044633600; tencentSig=6792114176; IESESSION=alive; pgv_si=s3489918976; CNZZDATA4617777=cnzz_eid%3D768417915-1468987955-%26ntime%3D1470191347; _qdda=3-1.1; _qddab=3-dyl6uh.ireawgo0; _qddamta_800068868=3-0'}
request = urllib2.Request("http://www.itcast.cn/",headers=get_headers)
#request.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36')
response = urllib2.urlopen(request)
print response.code
data = response.read()
print data
Q:为什么这两种写法都对?
A:一个headers没写,另一个写了都好使;原因是web服务器能够理解请求数据,并且没有做验证机制
POST请求方式
抓取招聘信息
http://www.lagou.com/jobs/list_?px=new&city=%E5%85%A8%E5%9B%BD#order
# -*- coding: utf-8 -*-
import urllib2
import urllib
proxy_handler = urllib2.ProxyHandler({"http" : 'http://192.168.17.1:8888'})
opener = urllib2.build_opener(proxy_handler)
urllib2.install_opener(opener)
Sum = 1
output = open('lagou.json', 'w')
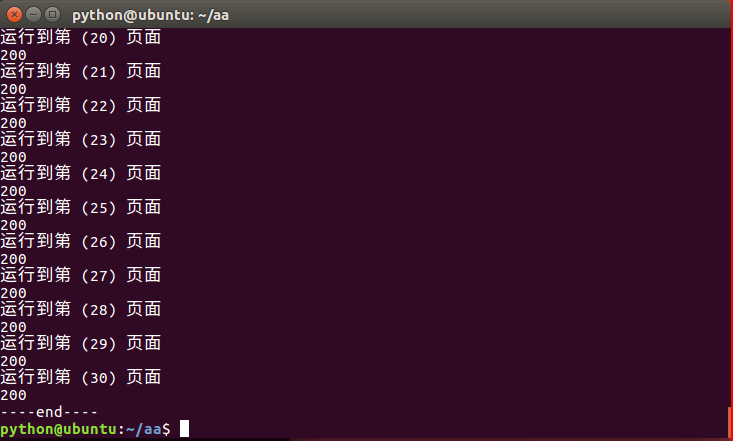
for page in range(1,Sum+1): formdata = 'first=false&pn='+str(page)+'&kd='print '运行到第 (%2d) 页面' %(page)send_headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36','Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8','Accept': 'application/json, text/javascript, */*; q=0.01',' X-Requested-With': 'XMLHttpRequest'}request =urllib2.Request('http://www.lagou.com/jobs/positionAjax.json?px=new&needAddtionalResult=false',headers=send_headers)#request.add_header('X-Requested-With','XMLHttpRequest')#request.headers=send_headersrequest.add_data(formdata)print request.get_data()response = urllib2.urlopen(request)print response.coderesHtml =response.read()#print resHtmloutput.write(resHtml+'\n')
output.close()
print '-'*4 + 'end'+'-'*4
思考一下
- 如果要采集的是 北京>>朝阳区>>望京 地区的职位,以这个网站为例,该如何理解这个url
http://www.lagou.com/jobs/list_?px=default&city=%E5%8C%97%E4%BA%AC&district=%E6%9C%9D%E9%98%B3%E5%8C%BA&bizArea=%E6%9C%9B%E4%BA%AC#filterBox
urlencode编码/解码在线工具
# -*- coding: utf-8 -*-
import urllib2
import urllib
query = {'city':'北京','district':'朝阳区','bizArea':'望京'
}
print urllib.urlencode(query)
page =3
values = {'first':'false','pn':str(page),'kd':'后端开发',
}
formdata = urllib.urlencode(values)
print formdata
小结
Content-Length: 是指报头Header以外的内容长度,指 表单数据长度
X-Requested-With: XMLHttpRequest :表示Ajax异步请求
Content-Type: application/x-www-form-urlencoded
表示:提交的表单数据 会按照name/value 值对 形式进行编码
例如:
name1=value1&name2=value2...
name 和 value 都进行了 URL 编码(utf-8、gb2312)
在线测试字符串长度

总结
Urllib2库丨Python爬虫基础入门系列(12) 就到这啦,在学爬虫的老铁记得持续关注噢!阿星祝你早日修炼成为爬虫大佬!当然,如果你准备系统地学爬虫及更多Python编程技术,可戳我文末的名片,Free领取最新Python爬虫资料/免费咨询/学习规划~