文章目录
- 概念
- Two Examples
- Example 1
- Example 2
- ROC曲线
- PR曲线
- References
概念
混淆矩阵(Confusion-Matrix)
| 符号 | 含义 |
|---|---|
| TP(True Positives) | 【真正】样本为正,预测结果为正 |
| FP(False Positives) | 【假正】样本为负,预测结果为正 |
| TN(True Negatives) | 【真负】样本为负,预测结果为负 |
| FN(False Negatives) | 【假负】样本为正,预测结果为负 |
具体来说:
| 正确的、相关的(wanted) | 不正确的、不相关的 | |
|---|---|---|
| 检测出来的 | TP(True Positives) | FP(False Positives) |
| 未检测出来的 | TN(True Negatives) | FN(False Negatives) |
-
准确率
A c c u r a c y = T P + T N T P + F P + T N + F N Accuracy=\frac{TP+TN}{TP+FP+TN+FN} Accuracy=TP+FP+TN+FNTP+TN -
错误率(错误率与准确率相反,对某一个实例来说,二者互斥)
E r r o r r a t e = F P + F N T P + F P + T N + F N = 1 − A c c u r a c y Error rate=\frac{FP+FN}{TP+FP+TN+FN}=1-Accuracy Errorrate=TP+FP+TN+FNFP+FN=1−Accuracy -
灵敏度(Sensitive 表示的是所有正例中被分对的比例,衡量了分类器对正例的识别能力,在数值上等于召回率Recall)
T P R = T P T P + F N TPR =\frac{TP}{TP+FN} TPR=TP+FNTP -
特异度(Specificity 表示的是将负例识别为负例的情况占所有负例的比例,衡量了分类器对负例的识别能力)
T N R = T N T N + F P TNR =\frac{TN}{TN+FP} TNR=TN+FPTN -
精准率(Precision其实就是在识别出来的图片中,True positives所占的比率:)
P r e c i s i o n = T P T P + F P Precision=\frac{TP}{TP+FP} Precision=TP+FPTP -
召回率(Recall 召回率是覆盖面的度量,可以看做是被正确识别出来的样本个数与测试集中所有要识别样本个数的比值)
R e c a l l = T P T P + F N Recall=\frac{TP}{TP+FN} Recall=TP+FNTP -
综合评价指标:F-measure
P和R指标有时候会出现的矛盾的情况,这样就需要综合考虑他们,最常见的方法就是F-Measure(又称为F-Score)
F-Measure是Precision和Recall加权调和平均:
F = ( α 2 + 1 ) P ∗ R α 2 P + R F=\frac{(\alpha^2+1)P*R}{\alpha^2P+R} F=α2P+R(α2+1)P∗R
当参数 α = 1 \alpha =1 α=1时,就是最常见的F1:precision和recall调和均值的2倍,即
F 1 = 2 ∗ P ∗ R P + R F1=\frac{2*P*R}{P+R} F1=P+R2∗P∗R
Recall召回率 实际等同于 查全率
Precision精准率 实际等同于 查准率
Two Examples
下面举两个例子来帮助理解:
Example 1
假设一个班级有10个学生,5男5女。你用机器找女生,机器返回了一下结果:
| 男 | 女 | 女 | 男 | 女 | 男 |
| T | F | |
|---|---|---|
| P | 3 | 3 |
| N | 2 | 2 |
| Recall = TP/(TP+FN)=3/5 = 0.6 | ||
| Precise = TP/(TP+FP)=3/6=0.5 | ||
| 查准率为:3/6 = 0.5(返回的6个结果只有3个正确) | ||
| 查全率为: 3/5 = 0.6 (所有女生有5个,但只找到3个) |
Example 2
此例子来自:https://blog.csdn.net/hysteric314/article/details/54093734
- 大雁与飞机
假设现在有这样一个测试集,测试集中的图片只由大雁和飞机两种图片组成,如下图所示:

假设你的分类系统最终的目的是:能取出测试集中所有飞机的图片,而不是大雁的图片。
于是,根据之前我们定义:
True positives : 飞机的图片被正确的识别成了飞机。
True negatives: 大雁的图片没有被识别出来,系统正确地认为它们是大雁。
False positives: 大雁的图片被错误地识别成了飞机。
False negatives: 飞机的图片没有被识别出来,系统错误地认为它们是大雁。
假设你的分类系统使用了上述假设识别出了四个结果,如下图所示:
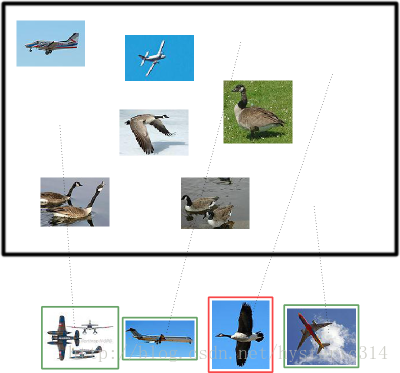
那么在识别出的这四张照片中:
True positives : 有三个,画绿色框的飞机。
False positives: 有一个,画红色框的大雁。
没被识别出来的六张图片中:
True negatives : 有四个,这四个大雁的图片,系统正确地没有把它们识别成飞机。
False negatives: 有两个,两个飞机没有被识别出来,系统错误地认为它们是大雁。
归纳一下就是:
| T | F | |
|---|---|---|
| P | 3 | 1 |
| N | 4 | 2 |
Recall = TP/(TP+FN)=3/5 = 0.6
Precise = TP/(TP+FP)=3/4=0.75
查准率为:3/4=0.75(返回的4个结果只有3个正确)
查全率为: 3/5 = 0.6 (所有飞机有5个,但只找到3个)
- 调整阈值
我们通过调整阈值,来选择让系统识别出多少图片,进而改变Precision 或 Recall 的值。
在某种阈值的前提下(蓝色虚线),系统识别出了四张图片,如下图中所示:

分类系统认为大于阈值(蓝色虚线之上)的四个图片更像飞机。
我们可以通过改变阈值(也可以看作上下移动蓝色的虚线),来选择让系统识别能出多少个图片,当然阈值的变化会导致Precision与Recall值发生变化。比如,把蓝色虚线放到第一张图片下面,也就是说让系统只识别出最上面的那张飞机图片,那么Precision的值就是100%,而Recall的值则是20%。如果把蓝色虚线放到第二张图片下面,也就是说让系统只识别出最上面的前两张图片,那么Precision的值还是100%,而Recall的值则增长到是40%。
| Retrieval | Precision | Recall |
|---|---|---|
| TOP 1 Image | 100% | 20% |
| TOP 2 Image | 100% | 40% |
| TOP 3 Image | 66% | 40% |
| TOP 4 Image | 75% | 60% |
| TOP 5 Image | 60% | 60% |
| TOP 6 Image | 66% | 80% |
| TOP 7 Image | 57% | 80% |
| TOP 8 Image | 50% | 80% |
| TOP 9 Image | 44% | 80% |
| TOP 10 Image | 50% | 100% |
ROC曲线
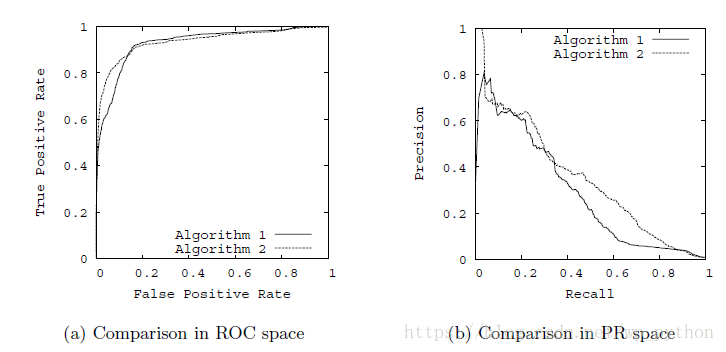
ROC曲线(receiver operating characteristic curve,简称ROC曲线),以TPR为y轴,以FPR为x轴,我们就直接得到了RoC曲线。从FPR和TPR的定义可以理解,TPR越高,FPR越小,我们的模型和算法就越高效。也就是画出来的RoC曲线越靠近左上越好。如下图左图所示。从几何的角度讲,RoC曲线下方的面积越大越大,则模型越优。所以有时候我们用RoC曲线下的面积,即AUC(Area Under Curve)值来作为算法和模型好坏的标准。
PR曲线
以精确率(precision)为y轴,以召回率(recall)为x轴,我们就得到了PR曲线。精准率和召回率是互相影响的,理想情况下肯定是希望做到两者都高,这样我们的模型和算法就越高效。但是一般情况下准确率高、召回率就低,召回率低、准确率高。
如果一个分类器的性能比较好,会让Recall值增长的同时保持Precision的值在一个很高的水平;而性能比较差的分类器可能会损失很多Precision值才能换来Recall值的提高。通常情况下,文章中都会使用Precision-recall曲线,来显示出分类器在Precision与Recall之间的权衡。
References
-
《机器学习》周志华
-
https://blog.csdn.net/hysteric314/article/details/54093734
-
https://www.cnblogs.com/Zhi-Z/p/8728168.html