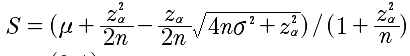你这蠢货,是不是又把酸葡萄和葡萄酸弄“混淆”啦!!!这里的混淆,我们细品,帮助我们理解名词“混淆矩阵”
上面日常情况中的混淆就是:是否把某两件东西或者多件东西给弄混了,迷糊了。把“酸葡萄”误认为了“葡萄酸”,或者是把“葡萄酸”误认为了“酸葡萄”,此时就会可能出现2种大可能,和4种小可能。分别是:
- 分类正确了
- “酸葡萄”正确认为是“酸葡萄”
- “葡萄酸”正确认为是“葡萄酸”
- 分类错误了
- 把“酸葡萄”误认为了“葡萄酸”
- 把“葡萄酸”误认为了“酸葡萄”
对于任何一个分类任务,都可能会存在上述4种情况。那在机器学习中,该如何描述他们呢?那就用混淆矩阵。
一、混淆矩阵
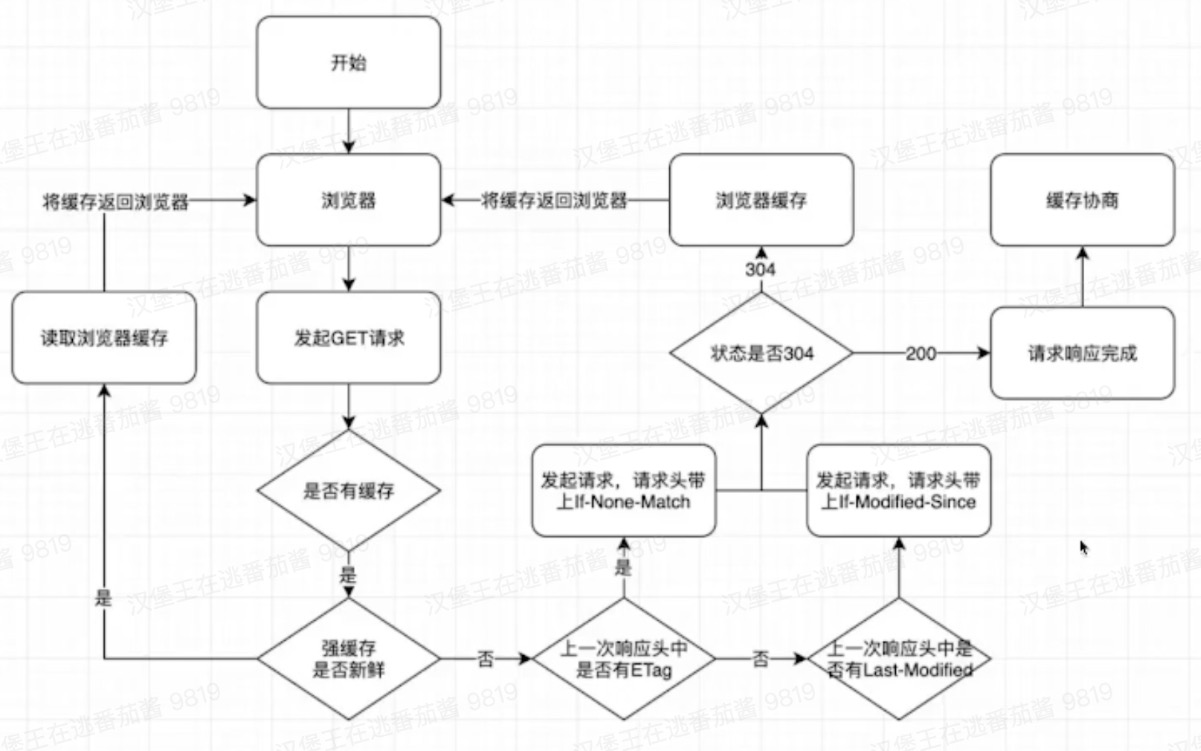
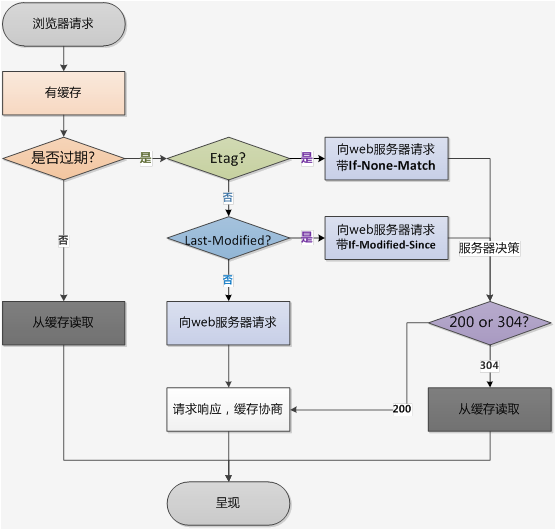
混淆矩阵是一个误差矩阵, 常用来可视化地评估监督学习算法的性能。混淆矩阵大小为 (n_classes, n_classes) 的方阵, 其中 n_classes 表示类的数量。
其中:
- 这个矩阵的一行表示预测类中的实例(可以理解为模型预测输出,predict, PD),
- 另一列表示对该预测结果对应的标签(Ground Truth, GT)。
- 于是综合
PD和GT进行判定模型的预测结果是否与标注结果一致,正确为True,错误为False。
此时,就引入混淆矩阵的四个元素:TP、FP、TN、FN。根据混淆矩阵,进一步计算:精确率(Precision),召回率(Recall),准确率(Accuracy)等等评价指标,我们在后面分别详述。
以猫、非猫二分类为例(不是猫,就是其他,没有更多的可能了),假定:
- cat为正例-Positive,那么not cat为负例-Negative;
- 预测正确为-True,反之,预测错误为-False。
我们针对cat或not cat,就可以得到下面这样一个表示TP、FP、TN、FN的表:

在计算混淆矩阵的时候,我们可以使用 scikit-learn 科学计算包,计算混淆矩阵函数 sklearn.metrics.confusion_matrix API 接口,可以快速帮助我们绘制混淆矩阵。接口定义如下:
skearn.metrics.confusion_matrix(y_true, # array, Gound true (correct) target valuesy_pred, # array, Estimated targets as returned by a classifierlabels=None, # array, List of labels to index the matrix.sample_weight=None # array-like of shape = [n_samples], Optional sample weights
)
完整示例代码如下:
import seaborn as sns
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as pltsns.set()f, (ax1, ax2) = plt.subplots(figsize=(10, 8), nrows=2)
y_pred = ["cat", "cat", "not cat", "cat", "cat", "cat", "cat"]
y_true = ["not cat", "not cat", "not cat", "cat", "cat", "cat", "cat"]
C2 = confusion_matrix(y_true, y_pred, labels=["not cat", "cat"])
print(C2)
print(C2.ravel())
sns.heatmap(C2, annot=True)ax2.set_title('sns_heatmap_confusion_matrix')
ax2.set_xlabel('pd')
ax2.set_ylabel('gt')
f.savefig('sns_heatmap_confusion_matrix.jpg', bbox_inches='tight')
保存的图像如下所示:
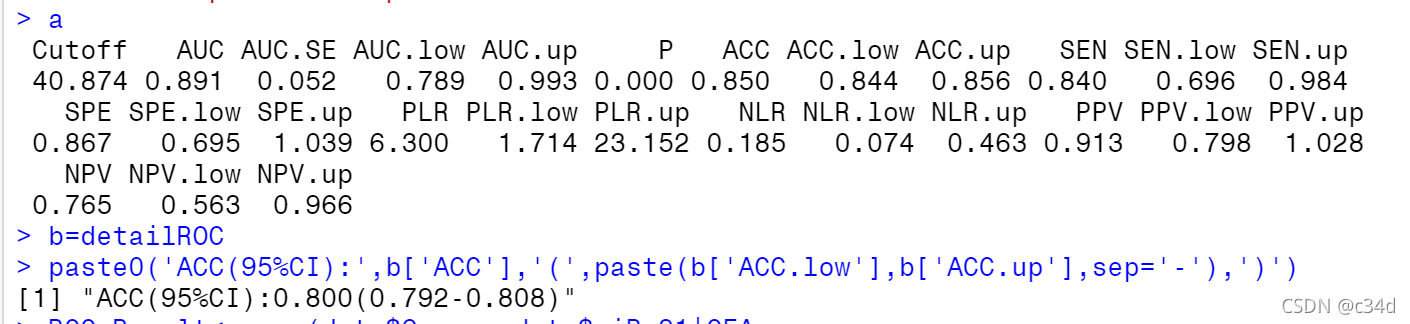
 这个时候我们还是不知道
这个时候我们还是不知道skearn.metrics.confusion_matrix做了些什么,这个时候print(C2),打印看下C2究竟里面包含着什么。最终的打印结果如下所示:
pd"not cat" "cat"
gt "not cat" 1 2"cat" 0 4
解释下上面这几个数字的意思:
C2 = confusion_matrix(y_true, y_pred, labels=["not cat", "cat"])中的labels的顺序就分布是0、1,negative和positive注:labels=[]可加可不加,不加情况下会自动识别,自己定义
在计算cat的混淆矩阵的时候,cat就是阳性,not cat就是阴性,如下面这样:
- cat为1-positive,其中真实值中cat有4个,4个被预测为cat,预测正确T,0个被预测为not cat,预测错误F;
- not cat为0-negative,其中真实值中dog有3个,1个被预测为not cat,预测正确T,2个被预测为cat,预测错误F。
定义:
- TP:正确的预测为正例,也就是预测为正例,预测对了
- TN:正确的预测为反例,也就是预测为反例,预测对了
- FP:错误的预测为正例,也就是预测为正例,预测错了
- FN:预测的预测为反例,也就是预测为反例,预测错了
所以:在分别以not cat和猫cat为正例,预测错位为反例中,会分别得到如下两个混淆矩阵:
dog-1,其他为0:
y_true = ["1", "1", "1", "0", "0", "0", "0"]
y_pred = ["0", "0", "1", "0", "0", "0", "0"]TP:1
TN:4
FP:0
FN:2cat-1,其他为0:
y_true = ["0", "0", "0", "1", "1", "1", "1"]
y_pred = ["1", "1", "0", "1", "1", "1", "1"]TP:4
TN:1
FP:2
FN:0
注意:混淆矩阵是评价某一模型预测结果好坏的方法,预测对与错的参照标准是标注结果。其中,需要对预测置信度进行阈值分割。
- 大于该阈值的,为预测阳性
- 小于该阈值的,为预测阴性
所以,确定该类的阈值是多少,很重要,直接决定了混淆矩阵的数值分布。其中,该阈值可根据ROC曲线进行确定,这块下文会详述,继续往后看。
从这里就可以看出,混淆矩阵的衡量是很片面的,依据混淆矩阵计算的精确率、召回率、准确率等等评价方法,也是很片面的。这就是他们的缺点,需要一个更加全面的评价指标的出现。
二、引申:准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1score
2.1、准确率(Accuracy)
这三个指标里最直观的就是准确率: 模型判断正确的数据(TP+TN)占总数据的比例
"Accuracy: "+str(round((tp+tn)/(tp+fp+fn+tn), 3))
2.2、召回率(Recall)
针对数据集中的所有正例label(TP+FN)而言,模型正确判断出的正例(TP)占数据集中所有正例的比例;FN表示被模型误认为是负例但实际是正例的数据;
召回率也叫查全率,以物体检测为例,我们往往把图片中的物体作为正例,此时召回率高代表着模型可以找出图片中更多的物体!
"Recall: "+str(round((tp)/(tp+fn), 3))
2.3、精确率(Precision)
针对模型判断出的所有正例(TP+FP)而言,其中真正例(TP)占的比例。精确率也叫查准率,还是以物体检测为例,精确率高表示模型检测出的物体中大部分确实是物体,只有少量不是物体的对象被当成物体。
"Precision: "+str(round((tp)/(tp+fp), 3))
2.4、敏感度、特异度、假阳性率、阳性预测值、阴性预测值
还有,敏感度Sensitivity、特异度Specificity、假阳性率False positive rate,FPR、阳性预测值Positive predictive value,PPV、阴性预测值Negative predictive value,NPV,分别的计算方法如下所示:
敏感度(recall):("Sensitivity: "+str(round(tp/(tp+fn+0.01), 3)))
特异度:("Specificity: "+str(round(1-(fp/(fp+tn+0.01)), 3)))
假阳性率:("False positive rate: "+str(round(fp/(fp+tn+0.01), 3)))
阳性预测值:("Positive predictive value: "+str(round(tp/(tp+fp+0.01), 3)))
阴性预测值:("Negative predictive value: "+str(round(tn/(fn+tn+0.01), 3)))
其中:
- 敏感度=召回率,都是看label标记是阳性中,预测pd有多少真是阳性 ;
- 特异度是看label标记是阴性中,预测pd有多少是真的阴性,这里的阴性可以是一大类。假设需要评估的类是马路上的人,那除人之外,其他类别均可以作为人相对应的阴性;
- 在医学领域,敏感度更关注漏诊率(有病之人不能漏),特异度更关注误诊率(无病之人不能误)
- 假阳性率 = 1 - 特异度,假阳性越多,误诊越多
- 阳性预测值 = 精确率,是看预测为阳性中,有多少是真阳性
- 阴性预测值是看预测为阴性中,有多少是真阴性
2.5、F1score
要计算F1score,需要先计算精确率和召回率。其中:
Precision = tp/tp+fpRecall = tp/tp+fn进而计算得到:F1score = 2 * Precision * Recall /(Precision + Recall)
那么,你有没有想过,F1score中,recall和Precision对其的影响是怎么样的。我们用如下代码,绘制出来看看。
import numpy as np
import matplotlib.pyplot as pltfig = plt.figure() #定义新的三维坐标轴
ax3 = plt.axes(projection='3d')#定义三维数据
precision = np.arange(0.01, 1, 0.1)
recall = np.arange(0.01, 1, 0.1)
X, Y = np.meshgrid(precision, recall) # 用两个坐标轴上的点在平面上画网格
Z = 2*X*Y/(X+Y)# 作图
ax3.plot_surface(X, Y, Z, rstride = 1, cstride = 1, cmap='rainbow')
plt.xlabel('precision')
plt.ylabel('recall')
plt.title('F1 score')
plt.show()
数据分布图如下:

可以看出,精准度和recall,无论任何一个低,F1score都不会高,只有两个都高的时候,分数才会高,这也能够说明,为啥很多评价都是采用F1 score。
三、总结
混淆矩阵和以此计算的敏感度、特异度、精确度等等指标,都是统计学中最基本的,相信这篇文章描述的很详细了,你应该是懂了。有几个注意的点,需要强调下:
- 敏感度、特异度、精确度等等指标的计算,前提是要得到混淆矩阵;
- 计算混淆矩阵,首先需要知道分类中的阈值,0-1中,是0.5,还是0.3,直接关系到最后的混淆矩阵
- 那究竟是选0.5,还是0.3作为计算混淆矩阵的截断阈值呢?那就有很多的方法,其中最常用的,就是ROC曲线
ROC曲线后续就讲到,敬请期待吧。
插播一个小故事:
我们早期在做一个多任务的模型评估时候,一直评估的结果不太好,最后换了个评估指标,一下子就清楚了很多,也能知道最终的结果,相比于之前是好是坏了。主要的改动两处:
- 一是通过ROC选择阈值
- 二是由准确率,改为使用敏感度和特异度分开评估,尤其是对于测试数据中正负样本极度不均衡的情况,分开评价会一目了然
- 所以说,分析任务类型,选择合适的模型评价指标,至关重要