一、进程的创建
阻塞状态:正在运行的进程由于某些原因调用阻塞原语把自己阻塞(如果不把自己阻塞的话会一直占用处理机),等待相应的事件出现后才被唤醒,事件完成回到就绪状态。
通常这种处于阻塞状态的进程也排成一个队列。有的系统则根据阻塞原因的不同而处于阻塞状态进程排成多个队列。挂起状态是被迫被外界挂起,阻塞是正常流程中的一部分,是自愿阻塞。
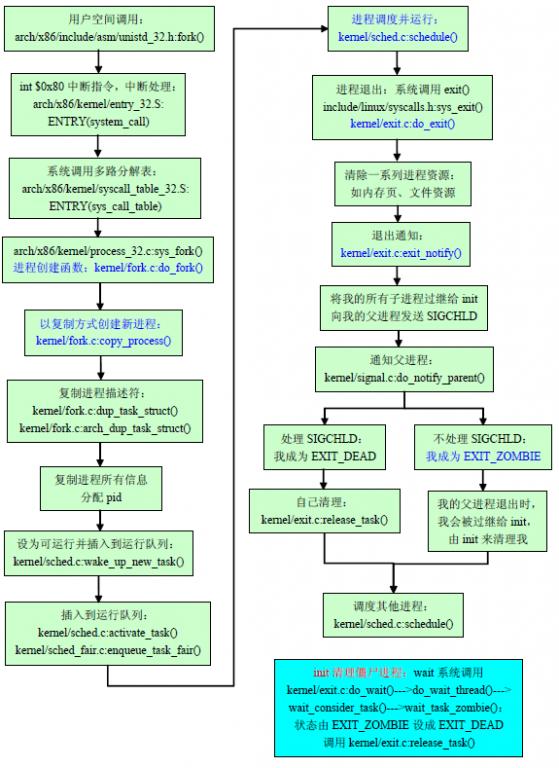
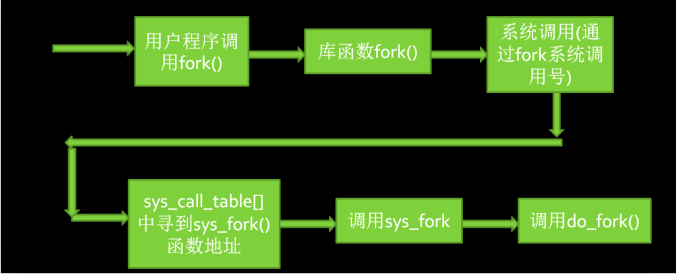
系统中同时运行着很多进程,这些进程都是从一个进程开始一个一个复制出来的。进程通过fork系列的系统调用(fork、clone、vfork)来创建,内核(或内核模块)也可以通过kernel_thread函数创建内核进程。这些创建子进程的函数本质上都完成了相同的功能——将调用进程复制一份,得到子进程。(可以通过选项参数来决定各种资源是共享、还是私有)fork的作用是根据一个现有的进程复制出一个新进程,原来的进程称为父进程(Parent Process),新进程称为子进程(ChildProcess)。一个进程调用fork()函数后,系统先给新的进程分配资源,例如存储数据和代码的空间。然后把原来的进程的所有值都复制到新的新进程中,只有少数值与原来的进程的值不同。相当于克隆了一个自己。
#include <unistd.h>
pid_t fork(void);子进程复制父进程的0到3g空间和父进程内核中的PCB,但id号不同。fork调用一次返回两次:父进程中返回子进程ID,子进程中返回0。读时共享,写时复制。在Shell下输入命令可以运行一个程序是因为Shell进程在读取用户输入的命令之后会调用fork复制出一个新的Shell进程,然后新的Shell进程调用exec执行新的程序。父进程读取命令,子进程执行命令。父进程在调用fork创建子进程时会把自己的环境变量表也复制给子进程。
fork(写时复制):父进程调用fork()后
在虚拟地址空间 子进程会复制父进程的代码段 数据段 内核中的pcb文件描述度表也会复制但是其中的进程id不同。在物理存储空间 子进程和父进程会先共享父进程的物理空间 等到父子进程中出现对物理空间的修改时,再为子进程相应的段分配物理空间。
比如子进程执行exec就是对物理空间进行修改 这个时候再去为子进程创建物理空间。fork以后严格意义上说父子进程调度顺序是不确定的 但是一般是先执行子进程 因为假设父进程对物理空间做了变动,然后按照上面所说要为子进程分配物理空间 然后子进程执行exec 还是要覆盖掉刚刚赋值的内容。vfork在写时复制的基础上进行改进,子进程连虚拟地址空间也不复制了 也共享父进程的。
fork出错可能有两种原因:
1)当前的进程数已经达到了系统规定的上限,这时errno的值被设置为EAGAIN。
2)系统内存不足,这时errno的值被设置为ENOMEM。
创建新进程成功后,系统中出现两个基本完全相同的进程,这两个进程执行没有固定的先后顺序,哪个进程先执行要看系统的进程调度策略。
fork()与vfock()都是创建一个进程,有以下区别:
1. fork():子进程拷贝父进程的数据段,代码段,vfork ():子进程与父进程共享数据段
2. fork()父子进程的执行次序不确定
vfork 保证子进程先运行,在调用exec 或exit 之前与父进程数据是共享的,在它调用exec或exit 之后父进程才可能被调度运行。 如果在调用这两个函数之前子进程依赖于父进程的进一步动作,则会导致死锁。
子进程拷贝父进程的代码段的例子:
1. #include<sys/types.h>
2. #include<unistd.h>
3. #include<stdio.h>
4.
5. int main()
6. {
7. pid_t pid;
8. pid = fork();
9. if(pid<0)
10. printf("error in fork!\n");
11. else if(pid == 0)
12. printf("I am the child process,ID is %d\n",getpid());
13. else
14. printf("I am the parent process,ID is %d\n",getpid());
15. return 0;
16.
17. }
1. [root@localhost fork]# gcc -o fork fork.c
2. [root@localhost fork]# ./fork
1. I am the child process,ID is 4711
2. I am the parent process,ID is 4710fork()函数用于从已存在的进程中创建一个新的进程,返回值有两个,子进程返回0,父进程返回子进程的进程号,进程号都是非零的正整数,所以父进程返回的值一定大于零。在pid=fork();之后,父进程和新创建的子进程都在运行,所以如果pid==0,那么肯定是子进程,若pid !=0(事实上大于0),那么是父进程在运行。而fork()函数子进程是拷贝父进程的代码段的,所以子进程中同样有
if(pid<0)
printf("error in fork!");
else if(pid==0)
printf("I am the child process,ID is %d\n",getpid());
else
printf("I am the parent process,ID is %d\n",getpid());
这么一段代码,所以上面这段代码会被父进程和子进程各执行一次,最终由于子进程的pid==0,
而打印出第一句话,父进程的pid>0,而打印出第二句话。于是得到了上面的运行结果。
看一个拷贝数据段的例子:
1. #include<sys/types.h>
2. #include<unistd.h>
3. #include<stdio.h>
4.
5. int main()
6. {
7. pid_t pid;
8. int cnt = 0;
9. pid = fork();
10. if(pid<0)
11. printf("error in fork!\n");
12. else if(pid == 0)
13. {
14. cnt++;
15. printf("cnt=%d\n",cnt);
16. printf("I am the child process,ID is %d\n",getpid());
17. }
18. else
19. {
20. cnt++;
21. printf("cnt=%d\n",cnt);
22. printf("I am the parent process,ID is %d\n",getpid());
23. }
24. return 0;
25. }
1. [root@localhost fork]# ./fork2
2. cnt=1
3. I am the child process,ID is 5077
4. cnt=1
5. I am the parent process,ID is 5076 为什么不是2 ?因为fork ()函数子进程拷贝父进程的数据段代码段,所以
cnt++;
printf("cnt= %d\n",cnt);
return 0
将被父子进程各执行一次,但是子进程执行时使自己的数据段里面的(这个数据段是从父进程那copy 过来的一模一样)count+1,同样父进程执行时使自己的数据段里面的count+1, 他们互不影响,便出现了如上的结果。
如果将上面程序中的fork ()改成vfork():
1. [root@localhost fork]# gcc -o fork3 fork3.c
2. [root@localhost fork]# ./fork3
3. cnt=1
4. I am the child process,ID is 4711
5. cnt=1
6. I am the parent process,ID is 4710
7. 段错误
vfock()是共享数据段的, vfork 和fork 之间的另一个区别是:vfork 保证子进程先运行,在调用exec 或exit 之后父进程才可能被调度运行。如果在调用这两个函数之前子进程依赖于父进程的进一步动作,则会导致死锁。 上面程序中的fork ()改成vfork()后,vfork()创建子进程并没有调用exec或exit,所以最终将导致死锁。 怎么改呢:
1. #include<sys/types.h>
2. #include<unistd.h>
3. #include<stdio.h>
4.
5. int main()
6. {
7. pid_t pid;
8. int cnt = 0;
9. pid = vfork();
10. if(pid<0)
11. printf("error in fork!\n");
12. else if(pid == 0)
13. {
14. cnt++;
15. printf("cnt=%d\n",cnt);
16. printf("I am the child process,ID is %d\n",getpid());
17. _exit(0);
18. }
19. else
20. {
21. cnt++;
22. printf("cnt=%d\n",cnt);
23. printf("I am the parent process,ID is %d\n",getpid());
24. }
25. return 0;
26.
27. }
1. [root@localhost fork]# gcc -o fork3 fork3.c
2. [root@localhost fork]# ./fork3
3. cnt=1
4. I am the child process,ID is 4711
5. cnt=2
6. I am the parent process,ID is 4710如果没有_exit(0)的话,子进程没有调用exec 或exit,所以父进程是不可能执行的,在子进程调用exec 或exit 之后父进程才可能被调度运行。 所以加上_exit(0);使得子进程退出,父进程执行,这样else 后的语句就会被父进程执行, 又因在子进程调用exec 或exit之前与父进程数据是共享的,所以子进程退出后把父进程的数 据段count改成1 了,子进程退出后,父进程又执行,最终就将count变成了2。
为什么会有vfork,因为以前的fork 创建一个子进程时,将会创建一个新的地址空间,并且拷贝父进程的资源,而往往在子进程中会执行exec 调用,这样前面的拷贝工作就白费力气了。这种情况下就想出了vfork,它产生的子进程刚开始暂时与父进程共享地址空间(其实就是线程的概念了)。因为这时候子进程在父进程的地址空间中运行,所以子进程不能进行写操作,并且在儿子霸占着老子的房子时候,要委屈老子在外面歇着(阻塞)。一旦儿子执行了exec 或者exit 后,相于儿子买了自己的房子,这时候就相于分家了。
写时复制是有一块内存,由多个进程共享,属性是只读的,当有一个进程对这块内存进行写的时候,系统会先申请一块新的内存给他写。比如进程fork的时候,父子进程对应的物理地址都一样,这时候会在页表项中记录该物理地址是只读的,有一个进程写的时候,就会触发写保护异常。执行写时复制。
二、进程状态
1.运行态
运行态的进程可以分为3种情况:内核运行态、用户运行态、就绪态。只有在该状态的进程才可能在CPU上运行。而同一时刻可能有多个进程处于可执行状态,这些进程的task_struct结构(进程控制块)被放入对应CPU的可执行队列中(一个进程最多只能出现在一个CPU的可执行队列中)。进程调度器的任务就是从各个CPU的可执行队列中分别选择一个进程在该CPU上运行。
正在CPU上执行的进程定义为RUNNING状态、可执行但是尚未被调度执行的进程定义为READY状态,这两种状态在linux下统一为 TASK_RUNNING状态。Linux 中把所有处于运行、就绪状态的进程链接成一个双向链表,称为可运行队列(run_queue)。使用任务结构体中的两个指针:
Struct task_struct *next_run;/*指向后一个任务结构体的指针*/
Struct task_struct *prev_run;/*指向前一个任务结构体的指针*/
该链表的首结点为 init_task。系统设置全局变量 nr_running 记录处于运行、就绪态的进程数。

用fork创建子进程后执行的是和父进程相同的程序(但有可能执行不同的代码分支),子进程往往要调用一种exec函数以执行另一个程序。当进程调用一种exec函数时,该进程的用户空间代码和数据完全被新程序替换,从新程序的启动例程开始执行。调用exec并不创建新进程,所以调用exec前后该进程的id并未改变。

2.睡眠与暂停状态
(TASK_INTERRUPTIBLE)可中断的睡眠状态
当进程调用一个阻塞的系统函数时,该进程被置于睡眠(Sleep)状态,这时内核调度其它进程运行,直到该进程等待的事件发生了(比如网络上接收到数据包,或者调用sleep指定的睡眠时间到了)它才继续运行。处于这个状态的进程因为等待某事件的发生(比如等待socket连接、信号量)而被挂起。这些进程的task_struct结构被放入对应事件的等待队列中。当这些事件发生时(由外部中断触发、或由其他进程触发),对应的等待队列中的一个或多个进程将被唤醒。
一般情况下,进程列表中的绝大多数进程都处于TASK_INTERRUPTIBLE状态(除非机器的负载很高)。毕竟CPU就这么一两个,进程动辄几十上百个,如果不是绝大多数进程都在睡眠,CPU又怎么响应得过来。

(TASK_UNINTERRUPTIBLE)不可中断的睡眠状态
不可中断,指的不是CPU不响应外部硬件的中断,而是指进程不响应异步信号。绝大多数情况下,进程处在睡眠状态时,总是应该能够响应异步信号的。否则发现,kill -9竟然杀不死一个正在睡眠的进程了.
TASK_UNINTERRUPTIBLE状态存在的意义在于,内核的某些处理流程是不能被打断的。如果响应异步信号,程序的执行流程中就会被插入一段用于处理异步信号的流程(这个插入的流程可能只存在于内核态,也可能延伸到用户态),于是原有的流程就被中断了。
在进程对某些硬件进行操作时(比如进程调用read系统调用对某个设备文件进行读操作,而read系统调用最终执行到对应设备驱动的代码,并与对应的物理设备进行交互),可能需要使用TASK_UNINTERRUPTIBLE状态对进程进行保护,以避免进程与设备交互的过程被打断,造成设备陷入不可控的状态。这种情况下的TASK_UNINTERRUPTIBLE状态总是非常短暂的,通过ps命令基本上不可能捕捉到。
linux系统中也存在容易捕捉的TASK_UNINTERRUPTIBLE状态。执行vfork系统调用后,父进程将进入TASK_UNINTERRUPTIBLE状态,直到子进程调用exit或exec。通过下面的代码就能得到处于TASK_UNINTERRUPTIBLE状态的进程:#include void main() { if (!vfork()) sleep(100); }
(TASK_STOPPED or TASK_TRACED)暂停状态或跟踪状态
向进程发送一个SIGSTOP信号,它就会因响应该信号而进入TASK_STOPPED状态(除非该进程本身处于TASK_UNINTERRUPTIBLE状态而不响应信号)。(SIGSTOP与SIGKILL信号一样,是强制的,不允许用户进程通过signal系列的系统调用重新设置对应的信号处理函数)向进程发送一个SIGCONT信号,可以让其从TASK_STOPPED状态恢复到TASK_RUNNING状态。
当进程正在被跟踪时,它处于TASK_TRACED这个特殊的状态。“正在被跟踪”指的是进程暂停下来,等待跟踪它的进程对它进行操作。比如在gdb中对被跟踪的进程下一个断点,进程在断点处停下来的时候就处于TASK_TRACED状态。而在其他时候,被跟踪的进程还是处于前面提到的那些状态。
对于进程本身来说,TASK_STOPPED和TASK_TRACED状态很类似,都是表示进程暂停下来。而TASK_TRACED状态相当于在TASK_STOPPED之上多了一层保护,处于TASK_TRACED状态的进程不能响应SIGCONT信号而被唤醒。只能等到调试进程通过ptrace系统调用执行PTRACE_CONT、PTRACE_DETACH等操作(通过ptrace系统调用的参数指定操作),或调试进程退出,被调试的进程才能恢复TASK_RUNNING状态。
3.退出状态
一个进程在执行系统调用exit函数结束自己的生命的时候,并没有真正的被销毁, 而是留下一个称为僵尸进程(Zombie)的数据结构(系统调用exit,它的作用是使进程退出,但也仅仅限于将一个正常的进程变成一个僵尸进程,并不能将其完全销毁)。在这个退出过程中,进程占有的所有资源,除了task_struct结构(以及少数资源)以外将被回收。于是只剩下task_struct这么个空壳,故称为僵尸。
保留task_struct是因为task_struct里面保存了进程的退出码以及一些统计信息。其父进程很可能会关心这些信息。比如在shell中,$?变量就保存了最后一个退出的前台进程的退出码,而这个退出码往往被作为if语句的判断条件。内核也可以将这些信息保存在别的地方,而将task_struct结构释放掉,以节省一些空间。但是使用task_struct结构更为方便,因为在内核中已经建立了从pid到task_struct查找关系,还有进程间的父子关系。释放掉task_struct,则需要建立一些新的数据结构,以便让父进程找到它的子进程的退出信息。
在子进程中调用exit/return 可以终结子进程,但是这种终结不是销毁 ,子进程此时变成僵尸态。如果父进程一直没有去主动获取子进程的结束状态值,那么子进程就一直保持僵尸状态。通过wait/waitpid函数就可以获取退出状态值从而回收僵尸进程。一个进程在终止时会关闭所有文件描述符,释放在用户空间分配的内存,但它的PCB还保留着,内核在其中保存了一些信息:如果是正常终止则保存着退出状态,如果是异常终止则保存着导致该进程终止的信号是哪个。这个进程的父进程可以调用wait或waitpid获取这些信息,然后清除掉这个进程。一个进程的退出状态可以在Shell中用特殊变量$?查看,因为Shell是它的父进程,当它终止时Shell调用wait或waitpid得到它的退出状态同时彻底清除掉这个进程。如果一个进程已经终止,但是它的父进程尚未调用wait或waitpid对它进行清理,这时的进程状态称为僵尸(Zombie)进程。任何进程在刚终止时都是僵尸进程。
销毁僵尸进程
父进程可以通过wait系列的系统调用(如wait、waitpid)来等待某个或某些子进程的退出,并获取它的退出信息。然后wait系列的系统调用会顺便将子进程的尸体(task_struct)也释放掉。父进程通过wait和waitpid等函数等待子进程结束,这会导致父进程挂起,相关用法可以通过man命令查看。
子进程在退出的过程中,内核会给其父进程发送一个信号,通知父进程来“收尸”。这个信号默认是SIGCHLD,但是在通过clone系统调用创建子进程时,可以设置这个信号。可以用signal函数为SIGCHLD安装handler回调函数,子进程结束后父进程会收到该信号,可以在handler中调用wait回收。
如果父进程不关心子进程什么时候结束,那么可以用signal(SIGCHLD,SIG_IGN) 通知内核,自己对子进程的结束不感兴趣,那么子进程结束后内核会回收, 并不再给父进程发送信号。fork两次,父进程fork一个子进程,然后继续工作,子进程fork一 个孙进程后退出,那么孙进程被init接管,孙进程结束后init会回收。不过子进程的回收还要自己做。
僵尸进程和孤儿进程区别
僵尸进程: 一个进程使用fork创建子进程,如果子进程退出,而父进程没有调用wait或者waitpid获取子进程的状态,那么子进程的进程描述符仍然保存在系统中,这种进程称为僵尸进程。
孤儿进程: 父进程先于子进程结束,则子进程成为孤儿进程,子进程的父进程成为1号进程init进程,称为init进程领养孤儿进程。子进程的死亡需要父进程来处理,当父进程先于子进程死亡时,子进程死亡没有父进程处理,这个死亡的子进程就是孤儿进程。
僵尸进程占用一个进程ID号,占用资源,危害系统。孤儿进程与僵尸进程不同的是,由于父进程已经死亡,子系统会帮助父进程回收处理孤儿进程。所以孤儿进程实际上是不占用资源的,因为它最终是被系统回收了,不会像僵尸进程那样占用ID。
exit对_exit进行了一些包装,使得整个退出的过程显得不那么粗暴,共同点就是都会关闭文件描述符,都会清空内存,但是exit还会额外地清空输入输出流缓存,移除临时创建的文件,调用注册好的出口函数等等。
wait()函数功能是:父进程一旦调用了wait就立即阻塞自己,由wait自动分析是否当前进程的某个子进程已经退出,如果让它找到了这样一个已经变成僵尸的子进程,wait就会收集这个子进程的信息,并把它彻底销毁后返回;如果没有找到这样一个子进程,wait就会一直阻塞在这里,直到有一个出现为止。
4.(TASK_DEAD - EXIT_DEAD),退出状态,进程即将被完全销毁
进程在退出过程中也可能不会保留它的task_struct。比如这个进程是多线程程序中被detach过的进程。或者父进程通过设置SIGCHLD信号的handler为SIG_IGN,显式的忽略了SIGCHLD信号。(这是posix的规定,尽管子进程的退出信号可以被设置为SIGCHLD以外的其他信号)此时进程将被置于EXIT_DEAD退出状态,这意味着接下来的代码立即就会将该进程彻底释放。所以EXIT_DEAD状态是非常短暂的,几乎不可能通过ps命令捕捉到。







![[培训-DSP快速入门-7]:C54x DSP开发环境与第一个汇编语言程序](https://img-blog.csdnimg.cn/20210723084107837.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0hpV2FuZ1dlbkJpbmc=,size_16,color_FFFFFF,t_70)
![[培训-DSP快速入门-6]:C54x DSP开发中C语言库函数的使用](https://img-blog.csdnimg.cn/20210722233353958.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0hpV2FuZ1dlbkJpbmc=,size_16,color_FFFFFF,t_70)