关于Rasa你必须要知道的几件事
1、为什么选择Rasa
2、Understanding the Rasa NLU Pipeline
3、Components in Rasa
4、DIET in Rasa
5、Dialogue Management in Rasa 2.0
6、TED Policy in Rasa
本文从一个high-level的角度对使用Rasa构建聊天助手的整个过程进行了总结,文章结构也是按照使用Rasa构建聊天助手时依次涉及到的模块来安排的,本文不太适合刚刚了解Rasa的小白,如果你之前有用Rasa构建过聊天助手,那么在阅读时会很轻松。
针对文中的部分章节,又另起篇幅给出了更深入的介绍,点击下面连接跳转到对应内容:
6. Understanding the Rasa NLU Pipeline
7. DIET in Rasa
8. Dialogue Management in Rasa 2.0
9. TED Policy in Rasa
后续需要补充的内容:NLU模型评估
1、为什么选择Rasa
1)从开发者角度讲
- Rasa包含了最新的NLU研究,包括行业领先的机器学习研究,语义理解、意图分类、捕获上下文,支持多种语言
- 建立在开源之上,Rasa由经验丰富的一流开发人员开发并开源,自推出以来,下载量超过一千万
- 可定制化的基础架构,Rasa拥有模块化,可扩展的架构,强大的内置功能,支持自定义集成
2)从用户隐私的角度讲
- Rasa允许在自己的基础架构上运行聊天助手,不需要将客户消息发送到托管的第三方服务进行处理
- 数据永远不会被共享,开发者可以完全控制模型
3)从规模化的角度讲
- Rasa可以提供多渠道的客户体验,Rasa有10个内置的消息通道,以及用于自定义通道的端点。
- Rasa拥有可扩展体系结构以满足高流量需求
- Rasa拥有多功能,可重用的基础架构,避免重复造轮子
2、Understanding the Rasa NLU Pipeline
关于Rasa NLU管道详细的解释可以看这篇文章:
6、Understanding the Rasa NLU Pipeline
在这里做一个提纲挈领的总结:
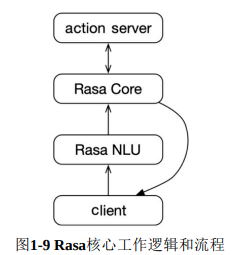
Rasa NLU管道定义了将非结构化用户消息转换为意图和实体的处理步骤。 它由一系列组件组成,主要包括:
- Tokenizers 分词器
- Featurizers 特征提取器
- Intent Classifiers 意图分类器
- Entity Extractors 实体提取器

这里的每一类组件都支持开发人员对其进行配置和定制,前一个组件的输出是后一个组件的输入,最开始的输入是原始的用户消息,NLU管道最终得到意图和实体的预测结果,会作为对话管理模块(Dialogue Management)中Policy的输入,用来预测下一步将要采取的Action。
总的来说,Rasa NLU管道就是一个完整的意图分类和实体提取的机器学习项目,只不过Rasa对每一部分进行了模块化处理,方便开发者使用和自定义自己的某个特定组件。
3、Components in Rasa
本小节对上一小节中提到的组件做一个解释,组件构成了NLU管道,并按顺序工作,将用户输入处理为结构化输出。 Rasa中有用于实体提取,意图分类,响应选择(response selection),预处理等的组件。

1、Language Models
Language Models主要用于加载预训练模型
2、Tokenizers
分词器
3、Featurizers
文本特征提取器,Rasa里面的文本特征提取器分两种:稀疏特征提取器和密集特征提取器,由于文本的稀疏特征向量要占用大量的内存,Rasa的做法是仅存储非零值及其在向量中的位置。 因此,节省了大量内存,并且能够在更大的数据集上进行训练。
所有的featurizer都可以返回两种不同的特征:序列特征和句子特征。
- 序列特征是一个[number-of-tokens x feature-dimension]大小的矩阵,该矩阵包含序列中每个token的特征向量,这使得我们可以训练序列模型。
- 句子特征由[1 x feature-dimension]大小的矩阵表示,它包含用户消息的完整特征向量,句子特征可以在任何词袋模型中使用。
因此,相应的分类器可以决定使用哪种类型的特征。 注意:序列和句子特征的特征尺寸不必相同。
4、Intent Classifiers
意图分类器,把domain.yml文件中定义的意图之一分配给传入的用户消息
5、Entity Extractors
实体提取器从用户消息中提取实体,例如人名或位置。
6、Combined Intent Classifiers and Entity Extractors
Rasa目前只有一个分类器可以同时实现意图分类和实体提取:DIETClassifier
7、Selectors
Selectors根据一组候选的response预测机器人的response,在Rasa中,狭义上的动作是指定义在domian—>actions中的动作,但是广义上,定义在domian—>responses中的response也是动作。
8、Custom Components
在最后的Custom Components部分,不仅可以自定义已有的组件类型,也可以自定义Rasa没有的组件,比如sentiment analysis
4、DIET in Rasa
关于DIET详细的解释可以看这篇文章:7. DIET in Rasa
Rasa文档链接:DIETClassifier
原论文:DIET: Lightweight Language Understanding for Dialogue Systems
代码:DIET-code
DIET全称是Dual Intent and Entity Transformer:双重意图和实体Transformer,是一种多任务的transformer体系结构,可同时处理意图分类和实体识别。它的优点是:
- 它是一种模块化体系结构,适合典型的软件开发工作流程;
- 在准确性和性能方面,能达到大规模预训练语言模型的效果;
- 改进了现有技术,胜过当时的SOTA,并且训练速度提高了6倍。
DIET的输入是用户消息,输出是实体、意图、意图排名
{"intent": {"name": "greet", "confidence": 0.8343},"intent_ranking": [{"confidence": 0.385910906220309,"name": "goodbye"},{"confidence": 0.28161531595656784,"name": "restaurant_search"}],"entities": [{"end": 53,"entity": "time","start": 48,"value": "2017-04-10T00:00:00.000+02:00","confidence": 1.0,"extractor": "DIETClassifier"}]
}


FFNN Characteristics
- FFNN不是全连接的,dropout=0.8,目的是让FFNN更轻巧
- 所有FFNN具有相同的权重
Featurization
输入是token序列,根据特征pipeline的不同,token可以是单词或子词,在每个句子的末尾添加一个特殊的分类标记 CLS。 每个输入token都有稀疏特征和/或密集特征。
- 稀疏特征有token级的one-hot 编码和字符级 n-gram ( n ≤ 5) multi-hot 编码。 字符 n-gram 包含许多冗余信息,因此为了避免过拟合,对这些稀疏特征使用了dropout。
- 密集特征可以是任意预训练的 word embeddings:ConveRT、BERT、GloVe
稀疏特征通过一个全连接层,这个全连接层与其它全连接层共享权重,以匹配密集特征的维度。 该全连接层的输出与预训练模型的密集特征连接在一起之后一起进入到一个新的全连接层,以匹配后面transformer 层的维度。
Transformer
为了对整个句子中的上下文进行编码,DIET使用了两层具有相对位置attention的transformer
NER
用Transformer输出向量,接一个CRF层进行NER
意图分类
Transformer 输出的用于表示 CLS token的 和意图标签
被嵌入到一个语义向量空间中:
训练阶段,使用点积损失
最大化与正标签的相似度:
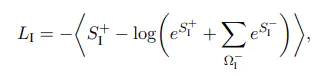
公式中的求和是在负样本上进行的,最外面的取平均<.>是在所有样本上进行的。
推理阶段,点积相似度用于在所有可能的意图标签上进行排序
Masking
受masked language modelling task的启发,DIET额外增加一个MASK损失函数来预测被随机mask掉的输入tokens。在序列中随机选择输入tokens的 15%。
对于选定的tokens,在70%的情况下将输入替换为 __MASK__token 对应的向量,在10%情况下将输入替换为随机token的向量,其余的 20% 情况下保留原始输入。
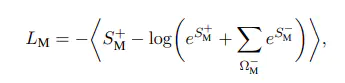
训练阶段,使用点积损失
最大化与正标签的相似度:总的损失函数
DIET通过使总损失函数最小化来以多任务方式训练模型
数据集
1、NLU-Benchmark 数据集
该数据集有 25,716 个语句,涵盖多个家庭助理任务,例如播放音乐或日历查询、聊天、以及向机器人发出的命令。总共64 个意图和 54 种实体类型
2、ATIS
训练、开发和测试集分别包含 4,478、500 和 893 个语句,训练数据集包含 21 个意图和 79 个实体。
3、SNIPS
此数据集是从 Snips 个人语音助手收集的,包含 13,784 个训练和 700 个测试样本,包含 7 个意图和 39 个实体。
5、Dialogue Management in Rasa 2.0
Dialogue Management,简称DM,中文叫对话管理,在聊天机器人中非常重要,尤其是在多轮对话中。在DM中通过Policy来确定在对话的每个步骤中应采取的动作,在Rasa Open Source 2.0中,有三种主要的对话策略:
RulePolicy处理与预定义规则模式匹配的对话。 它根据
rules.yml文件中的规则进行预测。MemoizationPolicy检查当前对话是否与训练数据中的任意story相匹配。 如果匹配,它将根据匹配的story预测下一个动作。
TEDPolicy使用机器学习来预测下一个最佳动作。 在Rasa的论文和视频中对TEDPolicy进行了详细的解释。
这些Policy按层次结构运行,每个Policy都会做出预测,但是如果两个Policy给出相同的置信度,则最终动作是具有最高优先级的Policy选择的动作,三者的优先级是:
RulePolicy——> MemoizationPolicy——>TEDPolicy

关于Rasa中对话管理的详细解释可以看这篇文章:
8. Dialogue Management in Rasa 2.0
6、TED Policy in Rasa
TED Policy全称是Transformer Embedding Dialogue Policy,是Rasa对话管理中用于选择助手下一步动作的一种机器学习对话策略。
每次对话时,TED策略都会将三条信息作为输入:
- 用户的消息
- 之前预测的系统动作
- 保存到助手内存中作为插槽的所有值
所有这些输入在被送到Transformer中之前都经过特征化和拼接。
自注意力机制的作用:Transformer在每个回合动态地访问对话历史的不同部分,然后评估并重新计算先前回合的相关性。 这允许TED策略在这一轮时考虑用户的话语,而在另一轮时完全忽略它,这使得Transformer成为处理对话历史记录的有效架构。
接下来,将稠密层应用于Transformer的输出,以获取用于对话上下文和系统动作的embeddings。 计算embeddings之间的差异,TED策略是基于Starspace算法的技术,可最大程度地提高与目标标签的相似度,并最大程度降低与错误标签的相似度。 比较embeddings之间相似性的过程类似于Rasa NLU管道中EmbeddingIntentClassifier预测意图分类的方式。
当需要预测下一个系统动作时,将根据所有可能的系统动作的相似性对它们进行排名,然后选择相似度最高的动作。
如下所示,在每个对话回合中都会重复此过程。

出自: https://www.jianshu.com/p/3372a5c772ad
参考:
rasa算法_(十八)基于RASA开始中文机器人实现机制
【小贝出品】定制你的对话机器人 - 基于RASA搭建
DIET-paper
DIET:Dual Intent and Entity Transformer——中文翻译
DIET:Dual Intent and Entity Transformer——RASA论文翻译
Dialogue Transformers——RASA TED policy 论文翻译
(五)RASA NLU特征生成器
(六)RASA NLU意图分类器
(七)RASA NLU实体提取器