2014年Ahmand Yasin在它的IEEE论文《A top-down method for performance analysis and counter architercture》中,革命性地给出了一个从CPU指令执行的顺畅程度来评估和发现瓶颈的方法,允许我们从黑盒的角度来看问题。
TMAM:自顶向下的微体系架构分析方法(Top-Down Microarchitecture AnalysisMethod,TMAM)
TMA: Top-down Microarchitecture Analysis Method
PMU:性能监控单元(Performance Monitoring Unit, PMU)。当前各CPU都提供PMU,用来支持TopDown的性能分析。
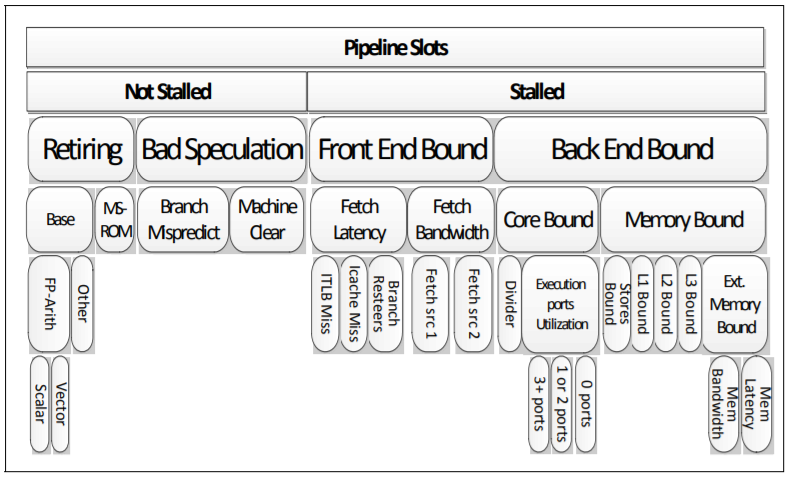
其中涉及的一些主要名词如下:
uOps micro-ops,micro-operations,微指令
比如ADD eax,[mem1] 就可以解码成两条微指令,一条是从内存[mem1]加载数据到临时寄存器,另外一条就是执行运算,这样就可以在加载数据的时候运算单元可以执行另外一条指令的运算uops,多个不同的资源单元可以并行工作。
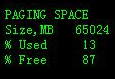
cpu时钟周期
时钟周期也称为振荡周期,定义为时钟频率的倒数,受电子器件的物理性质所决定。时钟周期是计算机中最基本的、最小的时间单位。在一个时钟周期内,CPU仅完成一个最基本的动作。
pipeline slots 流水线宽度。
一个时钟周期可以同时运行的微指令条数。一个pipeline slot代表了处理一个微操作所需要的全部硬件资源。一个核配合其他的硬件电路可以拥有多个pipeline slot,比如4个。pipeline slots与指令执行被分为几级流水线是不同的概念。
Retiring
表示运行有效的uOps的pipeline slots与总的pipeline slots的占比。它可以用于评估程序对CPU的相对比较真实的有效率。需要注意的是,Retiring这一分类的占比高并不意味着没有优化的空间。例如retiring中Microcode assists的类别实际上是对性能有损耗的,我们需要避免这类操作。
前端(Front-end)和后端(Back-end)
Front-end 负责获取程序代码指令,并将其解码为一个或多个称为微操作(uOps)的底层硬件指令。uOps 被分配给 Back-end 进行执行,Back-end 负责监控 uOp 的数据何时可用,并在可用的执行单元中执行 uOp。
Stall停顿
如果在一个 CPU 周期内某个 pipeline slot 是空的,称之为一次停顿(stall)。
Bad Speculation
表示由于分支预测错误导致的 pipeline slot 被浪费,主要包括 (1) 执行最终被取消的 uOps 的 pipeline slot,以及 (2) 由于从先前的错误猜测中恢复而导致阻塞的 pipeline slot。
Front-end Bound
表示 pipeline 的 Front-end 不足以供应 Back-end。
Back-end Bound
表示由于缺乏接受执行新操作所需的后端资源而导致停顿的 pipeline slot。
IPC英文全称"Instruction Per Clock"
就是每个时钟的指令,即CPU单核在每个时钟周期执行的微指令条数。其上限是pipeline slots。
Icache dcache
icache用来缓存指令, dcache用来缓存数据。
推荐书籍:
Denis Bakhvalov - Performance Analysis and Tuning on Modern CPUs