文章目录
- 一、MapReduce设计理念
- 二、MpaReduce计算流程
- 1 原始数据File
- 2 数据块Block
- 3 切片Split
- 4 MapTask
- 5 环形数据缓冲区KvBuffer
- 6 分区Partation
- 7 排序Sort
- 8 溢写Spill
- 9 合并Merge
- 10 组合器Combiner
- 11 拉取Fetch
- 12 合并 merge
- 13 归并Reduce
- 14 写出Output
- 15 MapReduce过程图解
- 三、MapReduce架构特点
- 1 MapReduce1.x
- 2 MapReduce2.x
- 四、Hadoop搭建yarn环境
一、MapReduce设计理念
MR架构——kv格式(key+value): map–>映射;reduce–>归纳
MapReduce: Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架。
Mapreduce核心功能: 将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上
二、MpaReduce计算流程

以 “计算1T数据中每个单词出现的次数” 为例
1 原始数据File
1T数据被切分成块存放在HDFS上,每一个块有128M大小
2 数据块Block
- hdfs上数据存储的一个单元,同一个文件中块的大小相同
- 数据存储到hafs上不可变,所以有可能块的数量和集群的计算能力不匹配
- 需要一个动态调整本次参与计算节点数量的一个单位
- 可以动态的改变这个单位,也就是节点参与的数量
3 切片Split
切片: 切片是一个逻辑概念,在不改变现有数据存储的情况下,控制参与计算的节点数目,具体通过控制切片的大小实现,有多少个切片就会执行多少个map任务
- 如果Split大小>Block大小,计算节点少了
- 如果Split大小<Block大小,计算节点多了
- 默认情况下,Split切片的大小等于Block的大小,默认128M
- 一个切片对应一个MapTask
4 MapTask
- map默认从所属切片读取数据,每次读取一行到内存中
- 可以根据自己书写的分词逻辑计算每个单词出现的次数
- 产生Map<String,Integer>临时数据,存放在内存中
- 但是内存大小是有限的,如果多个任务同时执行可能存在内存溢出(OOM)
- 把数据直接存放在硬盘上效率太低 在OOM和效率低之间平衡,提供一个有效方案:先在内存中写入一部分,然后写出到硬盘
5 环形数据缓冲区KvBuffer
可以利用这块内存区域,减少数据溢写时map的停止时间
- 每一个map可以独享的一个内存区域
- 在内存中构建的一个环形数据缓冲区(KvBuffer),默认大小为100M
- 设置缓冲区的阈值为80%,当缓冲区的数据达到80M开始向外溢写到硬盘
- 溢写的时候还有20M的空间可以被使用,效率并不会被减缓
- 数据将会循环写入到硬盘,不用担心OOM问题
6 分区Partation
- 根据key直接计算出对应的reduce
- 分区的数量和reduce的数量是相等的 hash(key)%partation=num
- 分区的默认算法是Hash然后取余:如果两个对象相同,其hashcode一定相等;如果两个对象的hashcode相等,但是这两个对象不一定相同
7 排序Sort
- 对要溢写的数据进行排序(quicksort)
- 按照先partation后key的顺序进行排序,相同分区在一起,相同key在一起
- 这样会保证溢写出来的小文件也都是有序的
8 溢写Spill
- 将内存中的数据循环写入到硬盘,不用担心OOM的问题
- 每次会产生一个80M的文件
- 若本次map产生的数据较多,可能会溢写多个文件
9 合并Merge
- 将小文件直接合并成大文件,将来拉取的数据直接从大文件拉取即可
- 合并小文件的时候同样进行排序(归并排序),最终产生一个有序的大文件
10 组合器Combiner
- 集群的带宽限制了mapreduce作业的数量,因此应该尽量避免map和reduce任务之间的数据传输。hadoop允许用户对map的输出数据进行处理,用户可自定义combiner函数(如同map函数和reduce函数一般), 其逻辑一般和reduce函数一样,combiner的输入是map的输出,combiner的输出作为reduce的输入, 很多情况下可以直接将reduce函数作为conbiner函数来使用
(job.setCombinerClass(FlowCountReducer.class;) - combiner属于优化方案, 所以无法确定combiner函数会调用多少次,可以在环形缓存区溢出文件时调用combiner函数,也可以在溢出的小文件合并成大文件时调用combiner。但要保证不管调用几次combiner函数都不会影响最终的结果,所以不是所有处理逻辑都可以使用combiner组件,有些逻辑如果在使用了combiner函数后会改变最后reduce的输出结果(如求几个数的平均值,就不能先用combiner求一次各个map输出结果的平均值,再求这些平均值的平均值,这将导致结果错误)。
- combiner的意义就是对每一个maptask的输出进行局部汇 总,以减小网络传输量。
比如原先传给reduce的数据是a1 a1 a1a1 a1
第一次combiner组合之后变为a{1,1,1,1,1,1}
第二次combiner后传给reduce的数据变为a{4,2,3,5…}
11 拉取Fetch
- 需要将map的临时结果拉取到reduce节点
- 原则:相同的key必须拉取到同一个reduce节点,但是一个reduce节点可以有多个key
- 拉取数据的时候必须对map产生的最终的合并文件做全序遍历,而且每一个reduce都要做一个全序遍历
- 如果map产生的大文件是有序的,每一个reduce只需要从文件中读取自己所需的即可
12 合并 merge
- reduce拉取时,会从多个map上拉取,每个map都会产生一个小文件(文件之间无序,文件内部有序),为了方便计算进行文件合并
- 将小文件直接合并成大文件,将来拉取的数据直接从大文件拉取即可
- 合并小文件的时候同样进行排序(归并排序),最终产生一个有序的大文件
13 归并Reduce
- 将文件中的数据读取到内存中
- 一次性将相同的key全部读取到内存中
- 直接将相同的key得到结果
14 写出Output
每个reduce将自己计算的结果存放到hdfs上
15 MapReduce过程图解
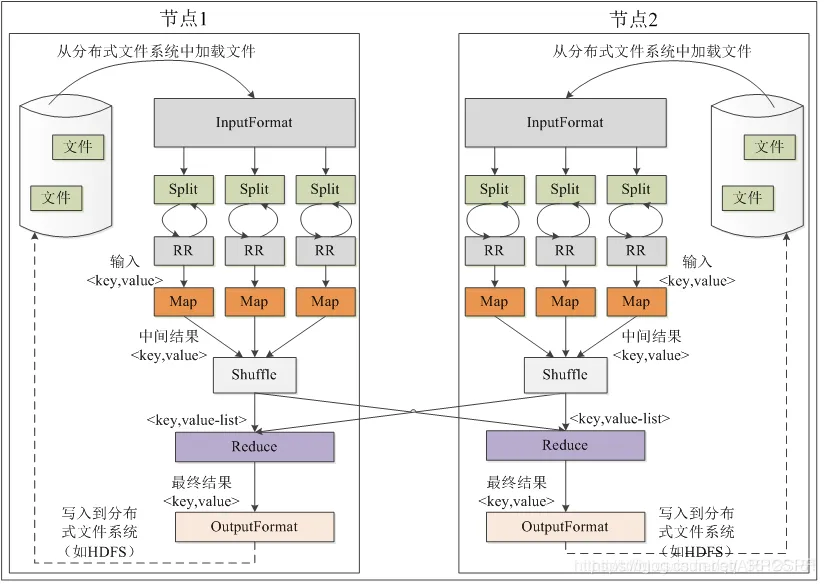
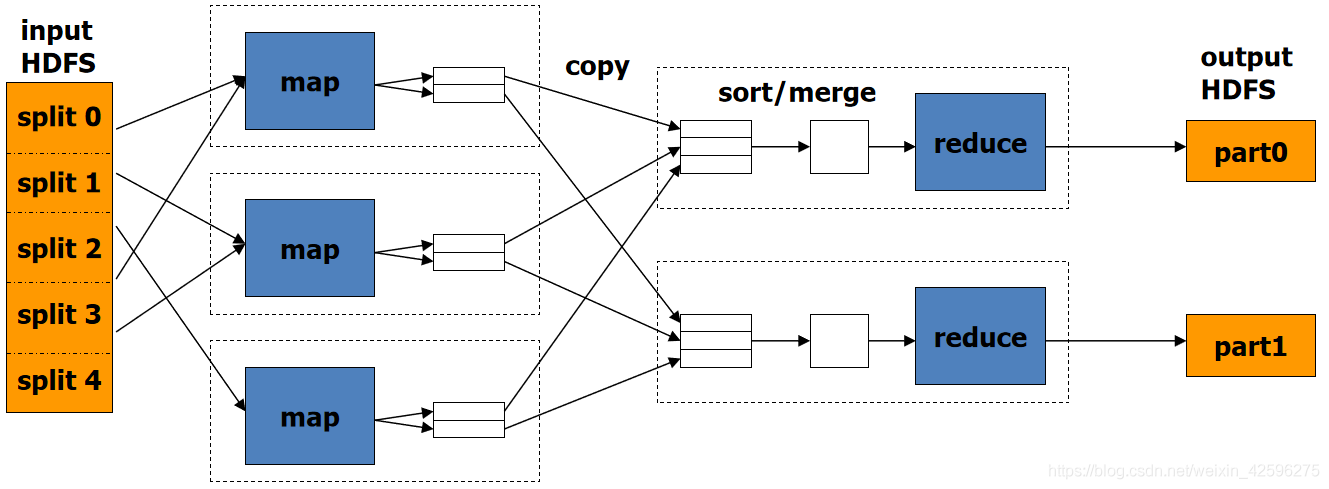
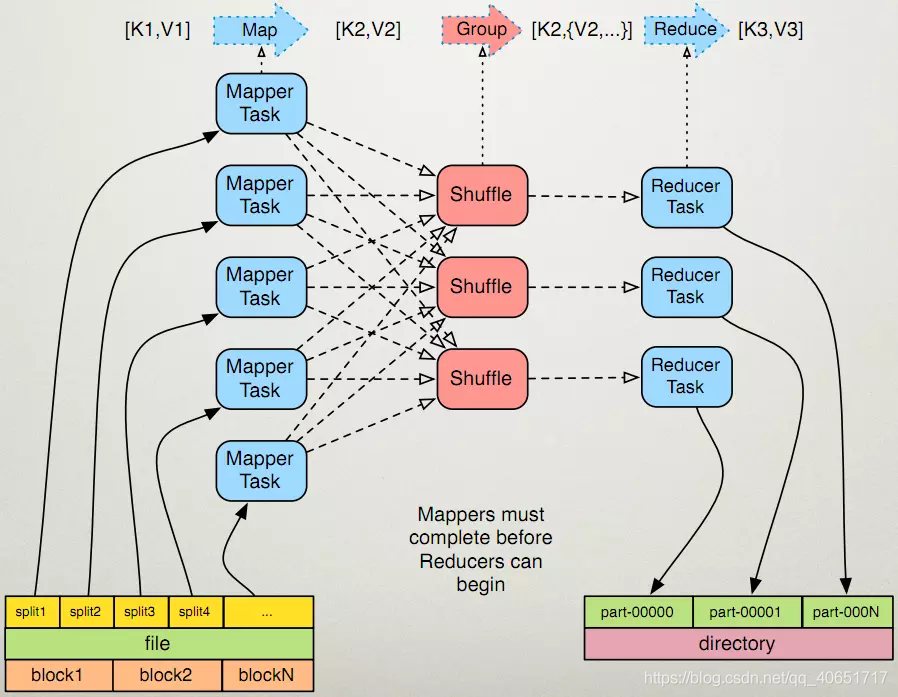

三、MapReduce架构特点
1 MapReduce1.x
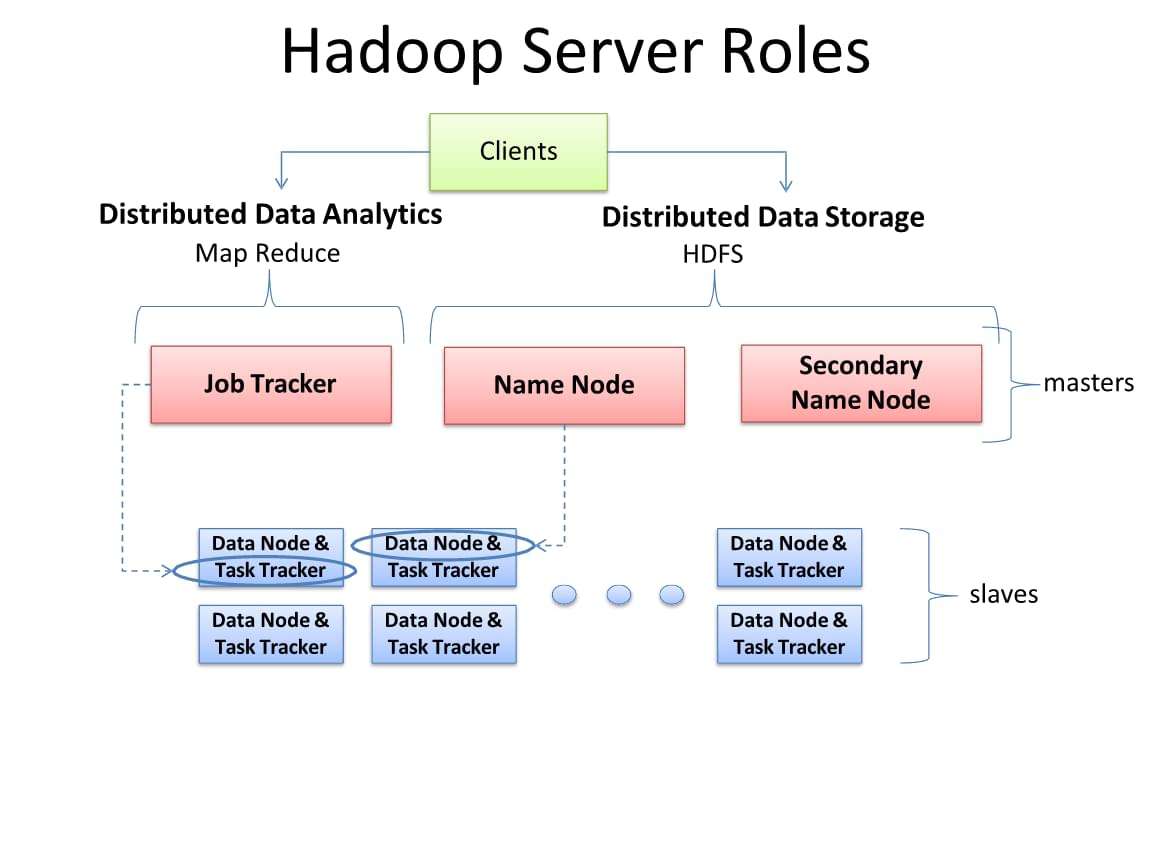
- client:负责发送mapreduce任务到集群(hadoop jar wordcount.jar)
- JobTracker:接受客户端的mapdurce任务,与Tasktracker保持心跳,接收汇报信息
- TaskTracker:保持心跳,汇报资源(当前机器内存,当前机器任务数);当分配资源之后,开始在本机分配对应的资源给Task;实时监控任务的执行,并汇报
- Slot(槽):属于JobTracker分配的资源,包括计算能力、IO能力;不管任务大小,资源是恒定的,不灵活但是好管理
- Task(MapTask–ReduceTask):开始按照MapReduce的流程执行业务,当任务完成时,JobTracker告诉TaskTracker回收资源
缺点:
- 单点故障
- 内存扩展
- 业务瓶颈
- 只能执行MapReduce的操作
- 若其它框架需要运行在Hadoop上需要独立开发自己的资源调度框架
2 MapReduce2.x
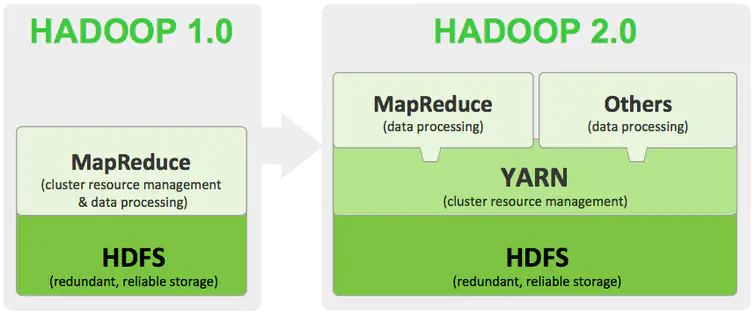

2.x开始使用Yarn统一管理资源,其它计算框架可以直接访问yarn获取当前集群的空闲节点
client:客户端发送MapReduce任务
ResourceManager:
- 资源协调框架的管理者,分为主节点与备用节点(主备切换基于Zookeeper进行管理)
- 时刻与NodeManager保持心跳,接受NodeManager的汇报
- 当有外部框架要使用资源的时候访问ResourceManager的汇报
- 若有MapReduce任务,先去ResourceManager申请资源,ResourceManager根据汇报分配资源
yarn(NodeManager):
- 资源协调框架的执行者
- 每一个DataNode上默认有一个NodeManager
Container: 2.x资源的代名词,是动态分配的
ApplicationMaster:
- 本次任务的主导者
- 负责调度本次被分配的资源Container
- 当所有节点任务全部完成,application告诉ResourceManager请求杀死当前ApplicationMaste线程
- 本次任务所有的资源都会被释放
Task(MapTask–ReduceTask): 开始按照MapReduce的流程执行业务,当任务完成时,ApplicationMaster接收到当前节点的回馈
四、Hadoop搭建yarn环境
| NN-1 | NN-2 | DN | ZKFC | ZK | JNN | RS | NM | |
|---|---|---|---|---|---|---|---|---|
| Node1 | * | * | * | * | * | * | * | |
| Node2 | * | * | * | * | * | * | ||
| Node3 | * | * | * | * | * |
yarn环境搭建基于HA环境
1.切换目录
cd /opt/hadoop-2.7.1/etc/hadoop/
2.拷贝配置文件
cp mapred-site.xml.template mapred-site.xml
3.修改 mapred-site.xml
vim mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>
4.修改yarn-site.xml
vim yarn-site.xml
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.ha.enabled</name><value>true</value></property><property><name>yarn.resourcemanager.cluster-id</name><value>mr_my_cluster</value></property><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value></property><property><name>yarn.resourcemanager.hostname.rm1</name><value>node1</value></property><property><name>yarn.resourcemanager.hostname.rm2</name><value>node3</value></property><property><name>yarn.resourcemanager.zk-address</name><value>node2:2181,node3:2181,node4:2181</value></property>
</configuration>
5.拷贝至其它节点
scp mapred-site.xml root@node2:`pwd` # [1]
scp mapred-site.xml root@node3:`pwd` # [1]scp yarn-site.xml root@node2:`pwd` # [1]
scp yarn-site.xml root@node3:`pwd` # [1]
6.启动zookeeper、启动集群
zkServer.sh start # [123]
start-dfs.sh # [1]
start-yarn.sh # [1]
yarn-daemon.sh start resourcemanager # [1]
7.关闭拍摄快照
stop-all.sh # [1]
yarn-daemon.sh stop resourcemanager # [1]
zkServer.sh stop # [123]