1 简介
今天向大家介绍一个帮助往届学生完成的毕业设计项目,基于hadoop大数据的音乐推荐系统。
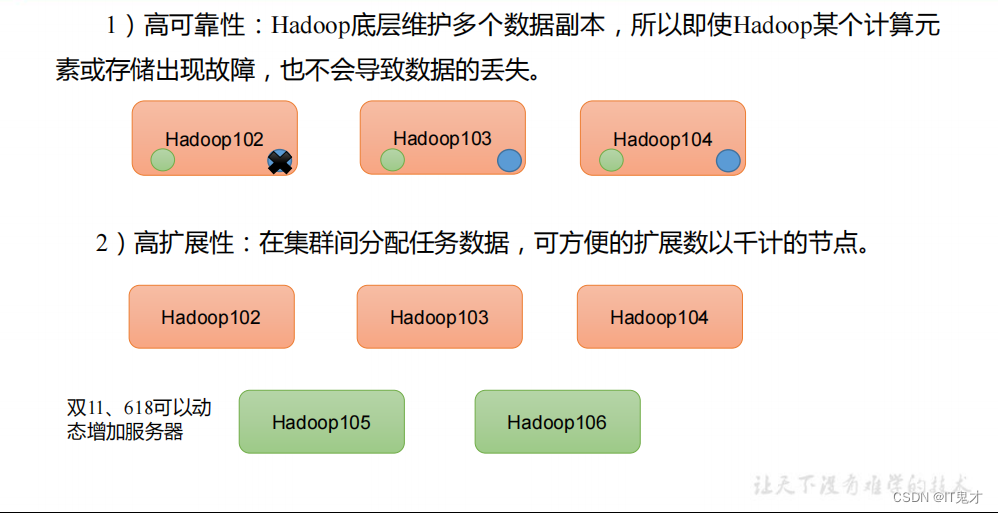
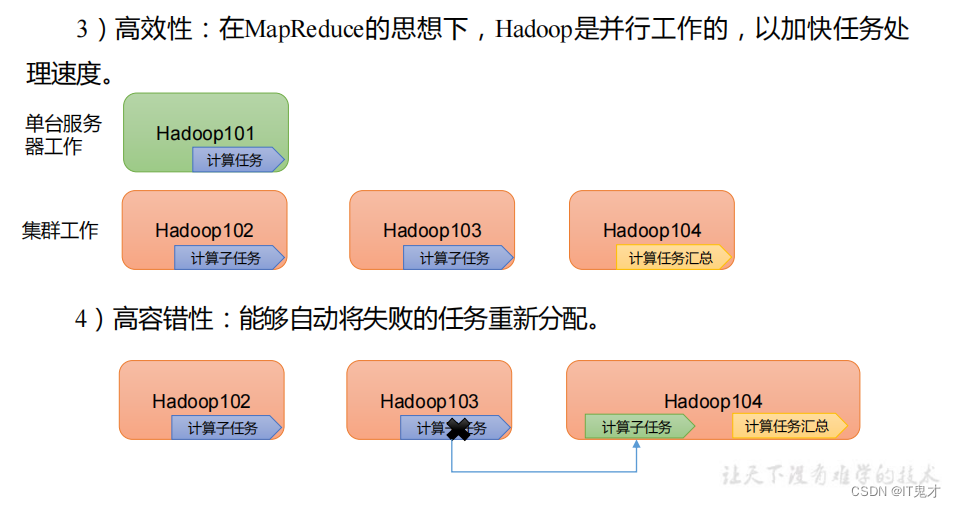
1.4 Hadoop优势(4高)
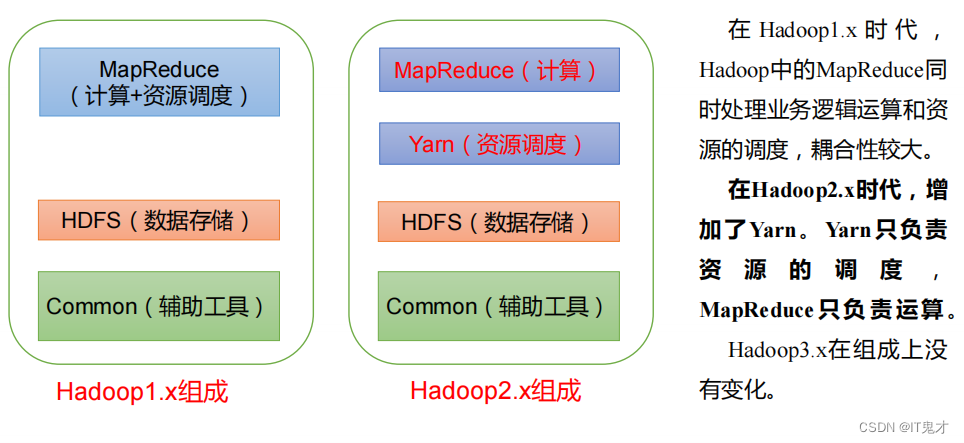
1.5 Hadoop 组成(面试重点)
1.5.1 HDFS 架构概述
Hadoop Distributed File System
,简称
HDFS
,是一个分布式文件系统(1
)
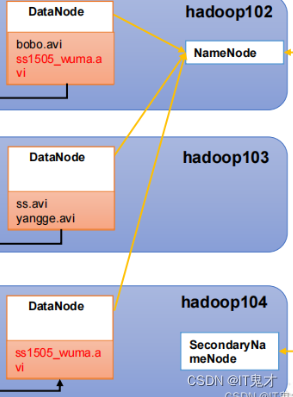
NameNode
(
nn
):存储文件的
元数据
,如
文件名,文件目录结构,文件属性
(生成时间、副本数、文件权限),以及每个文件的
块列表
和
块所在的
DataNode
等。(2
)
DataNode(dn)
:在本地文件系统
存储文件块数据
,以及
块数据的校验和
。(3
)
Secondary NameNode(2nn)
:
每隔一段时间对
NameNode
元数据备份
。简单的说就是NameNode就相当于一个目录,一个索引,负责标记每一个DataNode的存放位置而DataNode才是真正存放数据的,Secondary NameNode(2nn) :相当与老板的一个秘书,他会备份一部分数据,不会备份全部数据。
1.5.2 YARN 架构概述
Yet Another Resource Negotiator
简称
YARN
,另一种资源协调者,是
Hadoop
的资源管理器。
1.5.3 MapReduce 架构概述
MapReduce
将计算过程分为两个阶段:
Map
和
Reduce(1
)
Map
阶段并行处理输入数据(2
)
Reduce
阶段对
Map
结果进行汇总
1.5.4 HDFS**、YARN、**MapReduce 三者关系
HDFS
YARN
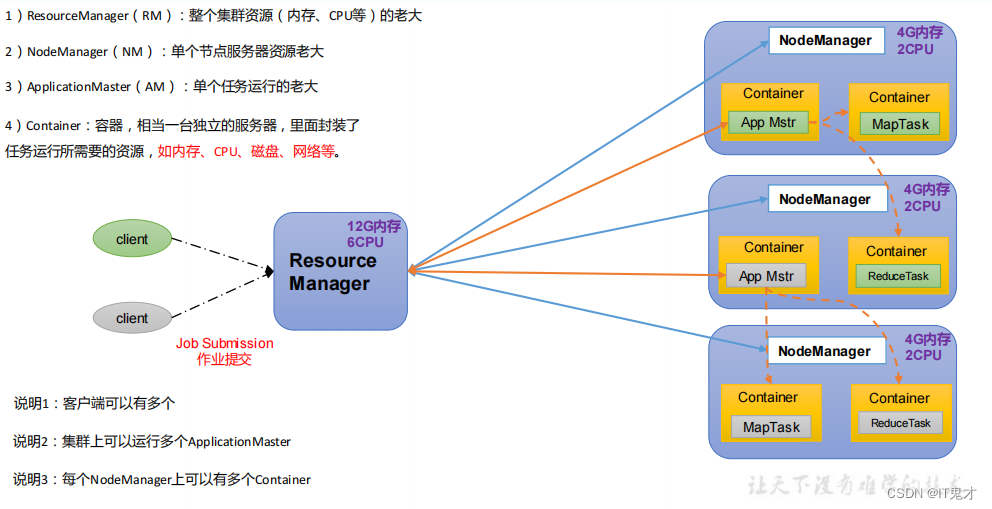
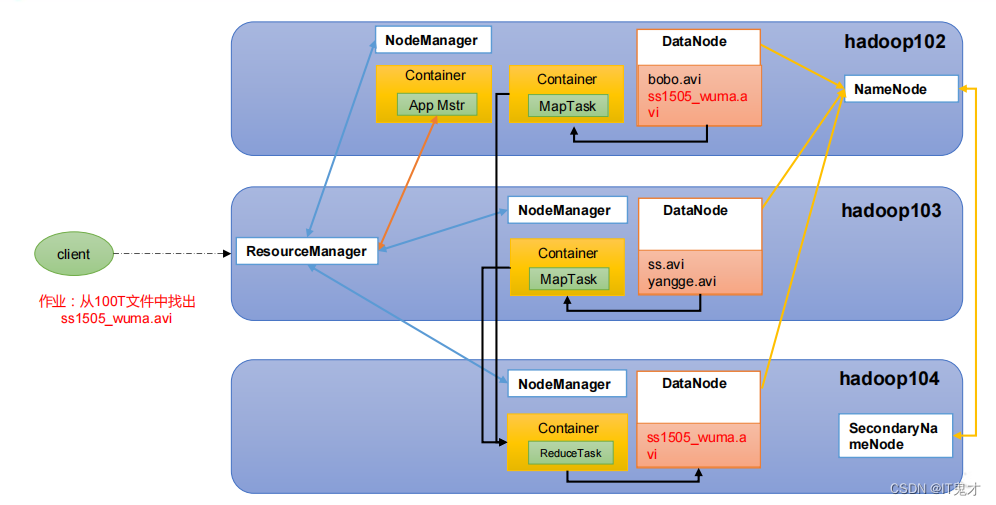
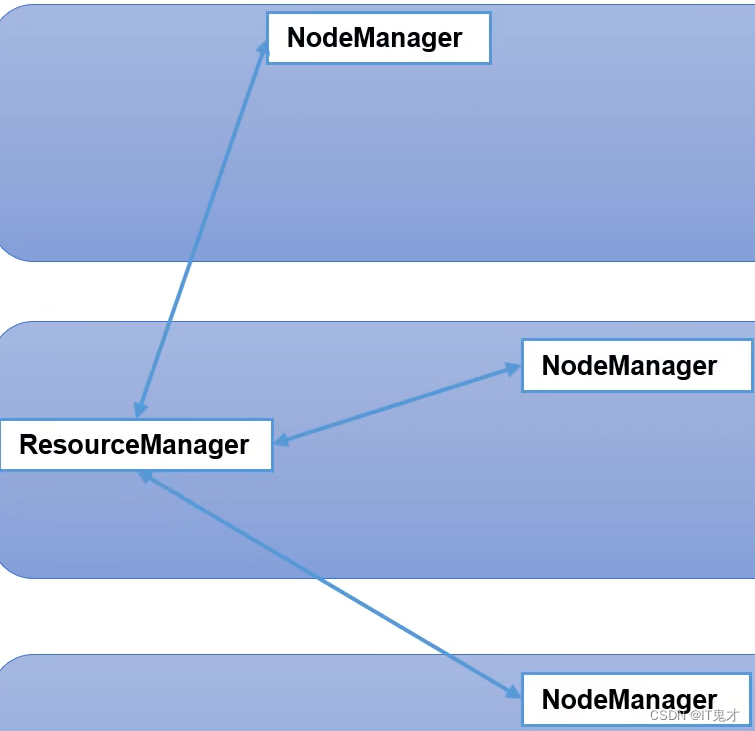
用户提交任务,任务给到ResourceManager,ResourceManager 会找一个节点**NodeManager,**开启一个Container ,把任务(App Mstr)放在Container App Mstr会向
ResourceManager申请说自己需要多少资源 ResourceManager 看哪一个DataNode有资源,给他分配资源 之后 App Mstr 会在被分配的资源节点上开启计算任务(MapTask ),这个其实就是MapReduce 的map阶段,之后会返回一个Reduce到各自对应的节点,这就是他们三者之间的关系

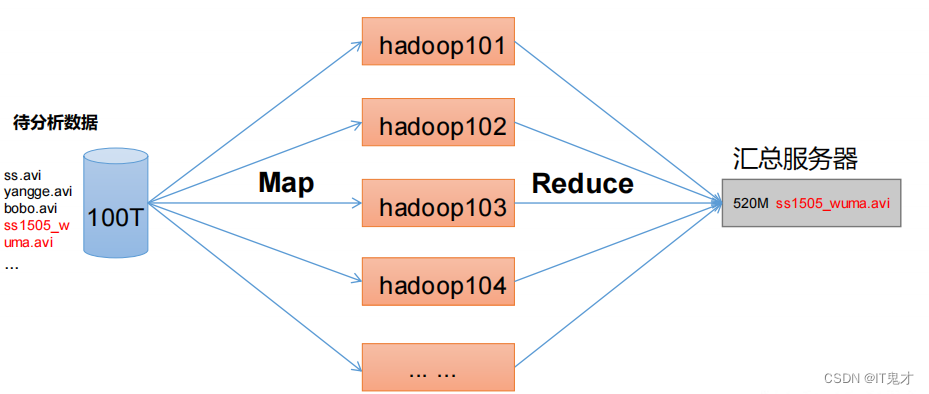
推荐系统广泛存在于各类网站中,作为一个应用为用户提供个性化的推荐。它需要一些用户的历史数据,一般由三个部分组成:基础数据、推荐算法系统、前台展示**。基础数据包括很多维度,包括用户的访问、浏览、下单、收藏,用户的历史订单信息,评价信息等很多信息;推荐算法系统主要是根据不同的推荐诉求由多个算法组成的推荐模型;前台展示主要是对客户端系统进行响应,返回相关的推荐信息以供展示。**
基础数据主要包括:
- 要推荐物品或内容的元数据,例如关键字,基因描述等;
- 系统用户的基本信息,例如性别,年龄等
- 用户对物品或者信息的偏好,根据应用本身的不同,可能包括用户对物品的评分,用户查看物品的记录,用户的购买记录等。
其实这些用户的偏好信息可以分为两类:
- 显式的用户反馈:这类是用户在网站上自然浏览或者使用网站以外,显式的提供反馈信息,例如用户对物品的评分,或者对物品的评论。
- 隐式的用户反馈:这类是用户在使用网站是产生的数据,隐式的反应了用户对物品的喜好,例如用户查看了某物品的信息等等。
显式的用户反馈能准确的反应用户对物品的真实喜好,但需要用户付出额外的代价,而隐式的用户行为,通过一些分析和处理,也能反映用户的喜好,只是数 据不是很精确,有些行为的分析存在较大的噪音。但只要选择正确的行为特征,隐式的用户反馈也能得到很好的效果,只是行为特征的选择可能在不同的应用中有很 大的不同,例如在电子商务的网站上,购买行为其实就是一个能很好表现用户喜好的隐式反馈。
2、推荐引擎的分类
推荐引擎的分类可以根据很多指标进行区分:
- 根据目标用户进行区分:根据这个指标可以分为基于大众行为的推荐引擎和个性化推荐引擎。
- 根据大众行为的推荐引擎,对每个用户都给出同样的推荐,这些推荐可以是静态的由系统管理员人工设定的,或者基于系统所有用户的反馈统计计算出的当下比较流行的物品。
- 个性化推荐引擎,对不同的用户,根据他们的口味和喜好给出更加精确的推荐,这时,系统需要了解需推荐内容和用户的特质,或者基于社会化网络,通过找到与当前用户相同喜好的用户,实现推荐。
这是一个最基本的推荐引擎分类,其实大部分人们讨论的推荐引擎都是将个性化的推荐引擎,因为从根本上说,只有个性化的推荐引擎才是更加智能的信息发现过程。
- 根据数据源进行区分:主要是根据数据之间的相关性进行推荐,因为大部分推荐引擎的工作原理还是基于物品或者用户的相似集进行推荐。
- 根据系统用户的基本信息发现用户的相关程度,这种被称为基于人口统计学的推荐(Demographic-based Recommendation)
- 根据推荐物品或内容的元数据,发现物品或者内容的相关性,这种被称为基于内容的推荐(Content-based Recommendation)
- 根据用户对物品或者信息的偏好,发现物品或者内容本身的相关性,或者是发现用户的相关性,这种被称为基于协同过滤的推荐(Collaborative Filtering-based Recommendation)。
- 根根据推荐模型进行区分:可以想象在海量物品和用户的系统中,推荐引擎的计算量是相当大的,要实现实时的推荐务必需要建立一个推荐模型,关于推荐模型的建立方式可以分为以下几种:
- 基于物品和用户本身的,这种推荐引擎将每个用户和每个物品都当作独立的实体,预测每个用户对于每个物品的喜好程度,这些信息往往 是用一个二维矩阵描述的。由于用户感兴趣的物品远远小于总物品的数目,这样的模型导致大量的数据空置,即我们得到的二维矩阵往往是一个很大的稀疏矩阵。同 时为了减小计算量,我们可以对物品和用户进行聚类, 然后记录和计算一类用户对一类物品的喜好程度,但这样的模型又会在推荐的准确性上有损失。
- 基于关联规则的推荐(Rule-based Recommendation):关联规则的挖掘已经是数据挖掘中的一个经典的问题,主要是挖掘一些数据的依赖关系,典型的场景就是“购物篮问题”,通过关联规则的挖掘,我们可以找到哪些物品经常被同时购买,或者用户购买了一些物品后通常会购买哪些其他的物品,当我们挖掘出这些关联规则之后,我们可以基于这些规则给用户进行推荐。
- 基于模型的推荐(Model-based Recommendation):这是一个典型的机器学习的问题,可以将已有的用户喜好信息作为训练样本,训练出一个预测用户喜好的模型,这样以后用户在 进入系统,可以基于此模型计算推荐。这种方法的问题在于如何将用户实时或者近期的喜好信息反馈给训练好的模型,从而提高推荐的准确度。
其实在现在的推荐系统中,很少有只使用了一个推荐策略的推荐引擎,一般都是在不同的场景下使用不同的推荐策略从而达到最好的推荐效果,例如 Amazon 的推荐,它将基于用户本身历史购买数据的推荐,和基于用户当前浏览的物品的推荐,以及基于大众喜好的当下比较流行的物品都在不同的区域推荐给用户,让用户 可以从全方位的推荐中找到自己真正感兴趣的物品。
3、常见的推荐算法
迄今为止,在个性化推荐系统中,协同过滤技术是应用最成功的技术。目前国内外有许多大型网站应用这项技术为用户更加智能的推荐内容。
3.1、基于用户的协同过滤算法
第一代协同过滤技术是基于用户的协同过滤算法,基于用户的协同过滤算法在推荐系统中获得了极大的成功,但它有自身的局限性。因为基于用户的协同过滤算法先计算的是用户与用户的相似度(兴趣相投,人以群分物以类聚),然后将相似度比较接近的用户A购买的物品推荐给用户B,专业的说法是该算法用最近邻居(nearest-neighbor)算法找出一个用户的邻居集合,该集合的用户和该用户有相似的喜好,算法根据邻居的偏好对该用户进行预测。
基于用户的推荐逻辑有两个问题:冷启动与计算量巨大。基于用户的算法只有已经被用户选择(购买)的物品才有机会推荐给其他用户。在大型电商网站上来讲,商品的数量实在是太多了,没有被相当数量的用户购买的物品实在是太多了,直接导致没有机会推荐给用户了,这个问题被称之为协同过滤的“冷启动”。另外,因为计算用户的相似度是通过目标用户的历史行为记录与其他每一个用户的记录相比较的出来的,对于一个拥有千万级活跃用户的电商网站来说,每计算一个用户都涉及到了上亿级别的计算,虽然我们可以先通过聚类算法经用户先分群,但是计算量也是足够的大。
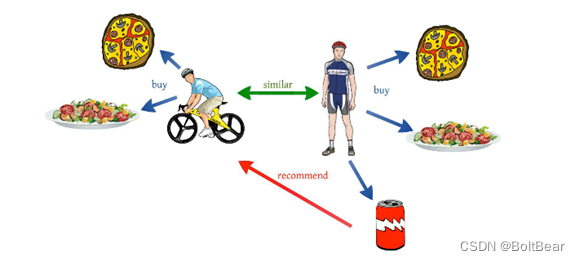
3.2、基于物品的协同过滤算法
第二代协同过滤技术是基于物品的协同过滤算法,基于物品的协同过滤算法与基于用户的协同过滤算法基本类似。他使用所有用户对物品或者信息的偏好,发现物品和物品之间的相似度,然后根据用户的历史偏好信息,将类似的物品推荐给用户。这听起来比较拗口,简单的说就是几件商品同时被人购买了,就可以认为这几件商品是相似的,可能这几件商品的商品名称风马牛不相及,产品属性有天壤之别,但通过模型算出来之后就是认为他们是相似的。什么?你觉得不可思议,无法理解。是的,就是这么神奇!
举个例子:假设用户 A 喜欢物品 A 和物品 C,用户 B 喜欢物品 A,物品 B 和物品 C,用户 C 喜欢物品 A,从这些用户的历史喜好可以分析出物品 A 和物品 C 时比较类似的,喜欢物品 A 的人都喜欢物品 C,基于这个数据可以推断用户 C 很有可能也喜欢物品 C,所以系统会将物品 C 推荐给用户 C。
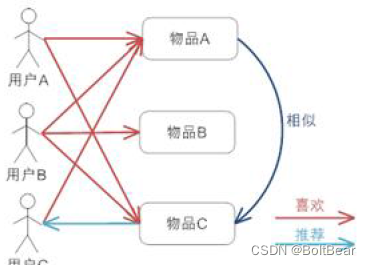
其实基于项目的协同过滤推荐机制是 Amazon 在基于用户的机制上改良的一种策略,因为在大部分的 Web 站点中,物品的个数是远远小于用户的数量的,而且物品的个数和相似度相对比较稳定,同时基于项目的机制比基于用户的实时性更好一些。但也不是所有的场景都 是这样的情况,可以设想一下在一些新闻推荐系统中,也许物品,也就是新闻的个数可能大于用户的个数,而且新闻的更新程度也有很快,所以它的形似度依然不稳 定。所以,其实可以看出,推荐策略的选择其实和具体的应用场景有很大的关系。
2 设计概要
本系统基于java技术,使用UML建模,采用springboot框架组合进行设计,Mysql数据库存储数据。
本系统的功能主要包括本系统的功能主要包括:
- 用户注册、登录、
- 信息维护、
- 会员搜索、
- 个性化推荐
- 管理员进行信息管理等
- 音乐管理
- 协同过滤推荐
- hadoop大数据分析数据
- mapreduce计算数据
3 系统关键技术
使用springboot,vue,mysql, mybaties, typescript, html ,css, js 等进行开发
4 开发工具
开发工具主要有:idea、jdk1.8、maven、mysql5.7、Navicat等。
5 代码展示
@RequestMapping("/strategy")
@RestController
@Scope("prototype")
public class StrategyController {@Autowiredprivate StrategyService strategyService;@Value("${web.upload-path}")private String path;@RequestMapping("/findPage")public ObjDat<Strategy> findPage(Strategy strategy, @RequestParam(value="page", defaultValue="1") int page, @RequestParam(value="limit", defaultValue="10") int limit){return strategyService.findPage(strategy,page-1,limit);}@RequestMapping("/edit")public JsonResult edit(HttpServletRequest request, Strategy strategy) throws IOException {User user=(User)request.getSession().getAttribute("user");if(user==null){return JsonResult.error("请登录");}String str=strategyService.edit(request,strategy);if(str.equals("成功")){return JsonResult.success("操作成功");}else{return JsonResult.error("操作失败");}}
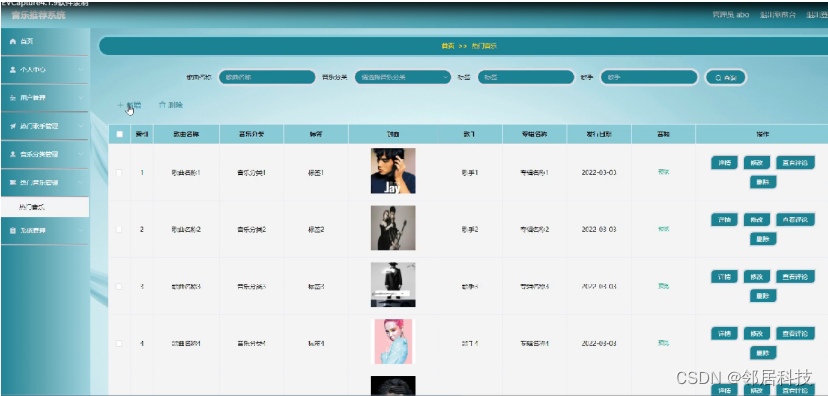
6 系统功能描述
项目功能演示