Gated-Attention Readers for Text Comprehension
文本理解中的门控attention阅读器
code
Abstract
本文研究的是完形填空问题式MRC,作者提出的门控注意力阅读器集中了多跳结构和一种新的注意力计算机制(基于query嵌入和RNN文档阅读器中间状态之间的乘积计算),这使阅读器能够在文档中构建特定于query的token表示形式。
1 Introduction
最近MRC模型的成功主要归因于两个原因:(1)多跳架构,允许模型迭代地扫描文档和问题以获得多次跳转。(2)注意力机制,使模型能够专注于上下文适当的子部分。直观地说,多跳体系结构允许reader递增地改进token表示,并且注意力机制根据文档中不同部分与query的相关性来重新加权文档中的不同部分。本文设计了一种新颖的注意力机制将多跳推理和注意力以互补的方式结合起来,该注意力可以在跳数之间对不断变化的token进行进行门控,该门控注意力( GA )允许query在语义级上直接与token嵌入的每个维度交互
2 Realated Work
完形填空风格的QA设计 ( d , q , a , C ) (d,q,a,\mathcal{C}) (d,q,a,C)形式的元组,其中 d d d是文档(上下文), q q q是对 d d d的内容的query,其中用占位符替换短语, a a a是 q q q的答案,其中 a a a来自一组候选 C \mathcal{C} C(完形填空:给一篇文章 d d d,给每个空提问题 q q q,在给出的答案集 C \mathcal{C} C中选出正确答案 a a a)。
*LSTMs with Attention:*使用LSTM单元来计算组合document-query表示 g ( d , q ) g(d,q) g(d,q),该document-query表示用于对候选答案进行rank。其中包括DeepLSTM Reader,其执行单次正向遍历连接的(document-query)对以获得 g ( d , q ) g(d,q) g(d,q);Attention Reader,其首先根据q的attention通过词的加权聚集来计算文档向量 d ( q ) d(q) d(q),然后组合 d ( q ) d(q) d(q)和 q q q以获得它们的联合表示 g ( d ( q ) , q ) g(d(q),q) g(d(q),q);Impatient Reader,document表示是递增构建的;Stanford Attentive Reader,简化了注意力reader的结构,使用较浅的循环单元与bilinear形式进行query-document attention。
Attention Sum:Attention-Sum(AS) Reader,使用两个双向GRU将 d d d和 q q q都编码成向量,通过计算 q q q和实体嵌入之间的点积并取softmax,获得 d d d中实体的概率分布,然后进一步应用一种称为指针和注意力的聚合机制对同一实体的概率进行求和,从而使文档中的频繁实体比稀有实体更受关注;在AS Reader的基础上,又引入了双向注意力机制,形成Attention-over-Attention(AoA) Reader。
Muliti-hop Architectures:Memory Networks,通过聚合附近的单词将文档中的每个句子编码到存储器中。
3 Gated-Attention Reader
本文提出的GA Reader在上下文(文档中的单词嵌入)上执行多个跳跃,跨跳迭代细化,直到到达最终的attention-sum模块,该模块将最后一跳中的上下文表示映射到候选答案上的概率分布。本文的门控注意力是通过query和上下文嵌入之间的multiplicative(乘性)交互实现,并在多步推理过程中以每跳作为细粒度信息filters。filters分别对文档中每个token的向量表示的各个分量进行加权。gated-attention layers的设计是基于向量空间表征之间乘法交互作用的有效性。
3.1 Model Details
该模型结构并不复杂,通过几个BiGRU进行交互,输入序列: X = [ x 1 , x 2 , . . . , x T ] X=[x_1,x_2,...,x_T] X=[x1,x2,...,xT],输出序列: H = [ h 1 , h 2 , . . . , h T ] H=[h_1,h_2,...,h_T] H=[h1,h2,...,hT],其通过GRU计算过程如下:
r t = σ ( W r x t + U r h t − 1 + b r ) z t = σ ( W z x z + U z h t − 1 + b z ) h ∼ t = t a n h ( W h x t + U h ( r t ⊙ h t − 1 ) + b h ) h t = ( 1 − z t ) ⊙ h t − 1 + z t ⊙ h ∼ t r_t=\sigma(W_rx_t+U_rh_{t-1}+b_r)\\ z_t=\sigma(W_zx_z+U_zh_{t-1}+b_z)\\ \overset{\sim}{h}_t=tanh(W_hx_t+U_h(r_t\odot h_{t-1})+b_h)\\ h_t=(1-z_t)\odot h_{t-1}+z_t\odot \overset{\sim}{h}_t rt=σ(Wrxt+Urht−1+br)zt=σ(Wzxz+Uzht−1+bz)h∼t=tanh(Whxt+Uh(rt⊙ht−1)+bh)ht=(1−zt)⊙ht−1+zt⊙h∼t
其中 r t r_t rt和 z t z_t zt称为复位门和更新门, h ∼ t \overset{\sim}{h}_t h∼t称为候选输出
将BiGRU两个序列进行连接:
G R U ↔ ( X ) = [ h 1 f ∣ ∣ h T b , . . . , h T f ∣ ∣ h 1 b ] ∈ R 2 n h × T \overset{\leftrightarrow}{GRU}(X)=[h_1^f||h_T^b,...,h_T^f||h_1^b]\in \mathbb{R}^{2n_h\times T} GRU↔(X)=[h1f∣∣hTb,...,hTf∣∣h1b]∈R2nh×T
设 X ( 0 ) = [ x 1 0 , x 2 0 , . . . , x ∣ D ∣ ( 0 ) ] X^{(0)}=[x_1^{0},x_2^{0},...,x_{|D|}^{(0)}] X(0)=[x10,x20,...,x∣D∣(0)]表示文档的token嵌入,也是document reader在第1层的输入; Y = [ y 1 , y 2 , . . . , y ∣ Q ∣ ] Y=[y_1,y_2,...,y_{|Q|}] Y=[y1,y2,...,y∣Q∣]表示query的token嵌入,其中 ∣ D ∣ |D| ∣D∣和 ∣ Q ∣ |Q| ∣Q∣表示文档的document和query的长度
3.1.1 Multi-Hop Architecture
模型图如图1所示:
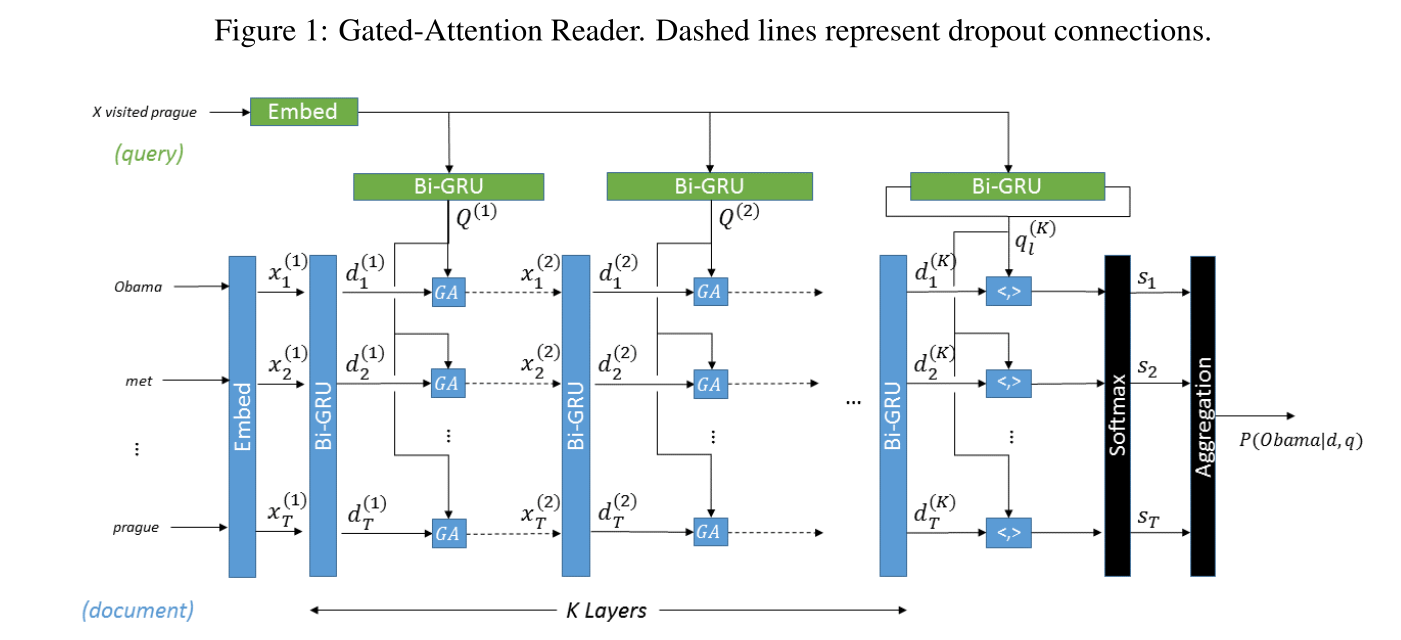
该模型优K层GA计算(读取document和query),上一层的输出作为下一层输入。
通过获取文档BiGRUns的全部输出转换为文档嵌入(蓝色部分):
D ( k ) = G R U ↔ D k ( X ( k − 1 ) ) D^{(k)}=\overset{\leftrightarrow}{GRU}_D^{k}(X^{(k-1)}) D(k)=GRU↔Dk(X(k−1))
特定层的query表示被计算为query的BiGRU的完整输出(绿色部分):
Q ( k ) = G R U ↔ Q k ( Y ) Q^{(k)}=\overset{\leftrightarrow}{GRU}_Q^{k}(Y) Q(k)=GRU↔Qk(Y)
通过将Gated-Attention应用于 D k D^{k} Dk和 Q k Q^{k} Qk,以计算下一层 X k X^{k} Xk的输入:
X k = G A ( D ( k ) , Q ( k ) ) X^{k}=GA(D^{(k)},Q^{(k)}) Xk=GA(D(k),Q(k))
3.1.2 Gated-Attention Module
为了表达方便,作者省略了section3.1.1的上标k,对于D中每个token d i d_i di,GA模块使用soft attention形成query q ∼ i \overset{\sim}{q}_i q∼i 的特定于token的表示,然后将该query表示与文档token表示逐个元素相乘:
α i = s o f t m a x ( Q T d i ) q ∼ i = Q α i x i = d i ⊙ q ∼ i \alpha_i=softmax(Q^Td_i)\\ \overset{\sim}{q}_i=Q\alpha_i\\ x_i=d_i\odot \overset{\sim}{q}_i αi=softmax(QTdi)q∼i=Qαixi=di⊙q∼i
启示
- related work写的很好
- 采用记忆网络的编码结构可以多次迭代更新query表示,从而提升推理潜力
- 门控注意力按位相乘的计算方法可以尝试使用