人工智能之知识图谱
知识图谱(knowledge graph )是人工智能领域的重要分支技术,概念最初由谷歌于2012年提出,成为创建大规模知识应用的必要技术,在自然语言处理,电子商务,搜索,智能助手等领域发挥着重要作用。知识图谱、大数据、深度学习成为推动人工智能技术的发展的核心驱动力。
知识图谱以结构化的形式描述现实世界中的实体,概念及其之间的关系,将互联网上的信息表达成一种更接近人类认知世界的形式,为机器提供了组织、管理和理解互联网信息的能力。
知识图谱的分类方式有多种,可以根据知识的种类、知识的创建方式进行分类。从知识领域上可以将知识图谱分为:通用领域知识图谱和特定领域知识图谱。特定领域知识图谱如:生命科学知识图谱,政府领域知识图谱,社交领域知识图谱等。从集合概念上讲所有特定领域知识图谱共同构成的集合就是通用领域知识图谱。
常用的知识图谱示意图由3
种要素:实体、概念和属性构成。实体指具有可区别性且能独立存在的物体。如一间房,一栋楼等。概念指具有相同特性的实体构成的集合,如:房间,楼房,教师等。属性用于描述概念所具有的特性,(对某概念来说)不同属性值类型对应不同类型属性的边,如果属性值对应的是概念或实体,则属性描述两实体或两概念或概念与实体之间的关系称为对象属性,如果属性值是数值则表示数据属性,即属性分为数据类型属性和对象类型属性。不同概念肯定具有不同数量或类型的属性。
根据维基百科对知识图谱的解释,知识图谱是google为增强其搜索引擎功能而建立的知识库,本质上是揭示实体之间关系的语义网络,可以实现对现实世界的事物及其之间关系的形式进行结构化的描述。现在被泛指为大规模的知识库。可作如下定义:是结构化的语义知识库,以符号的形式描述现实物理世界中的事物及其之间的关系的结构化数据。其基本组成单位是“实体-关系-实体”三元组,以及实体与属性值对,实体间通过关系相互连接,构成网状的知识网络。三元组是一种通用的表示知识图谱的方式,即:G∈(E,R,S),其中E表示知识库中实体的集合,R表示知识库中关系的集合,S⊆E×R×E 代表知识库中的三元组集合,它规定了实体的数量,关系的种类数量及构成的三元组的数量。三元组的基本形式有实体-关系-实体和概念-属性-属性值。实体是知识图谱中最基本的元素,不同实体间存在不同的关系。概念主要是指类别,对象类型等。属性指对象具有的属性、特性、特征、特点或参数,例如张三的国籍和生日等。属性值是指对象指定属性所具有的值,如张三生日属性的属性值2000年1月8日等。每个实体可以用一个全局唯一的ID来标识,属性-属性值对 可用来刻画实体的内在特性。而关系可用来连接两个实体,用来刻画它们之间的关联。
因此,知识图谱包含三层含义:
本身是具有属性的实体通过关系链接不同的实体构成的网络状知识库,本质上是一种概念网状图,其中节点表示现实世界中的实体,而实体间的语义关系则构成网络图的边;
其研究价值在于构建一种基于web基础之上的覆盖网络,借助知识图谱能够建立在web网页上的概念之间的链接关系,从而以一种更小的代价将互联网上的信息组织起来,成为可被利用的知识。
其应用价值在于改变现有的信息检索方式,一方面通过推理实现概念检索跳出字符串模糊匹配检索模式;另一方面以图形化的形式向用户展示经过分类整理的结构化的知识跳出人工过滤网页寻找答案的模式。
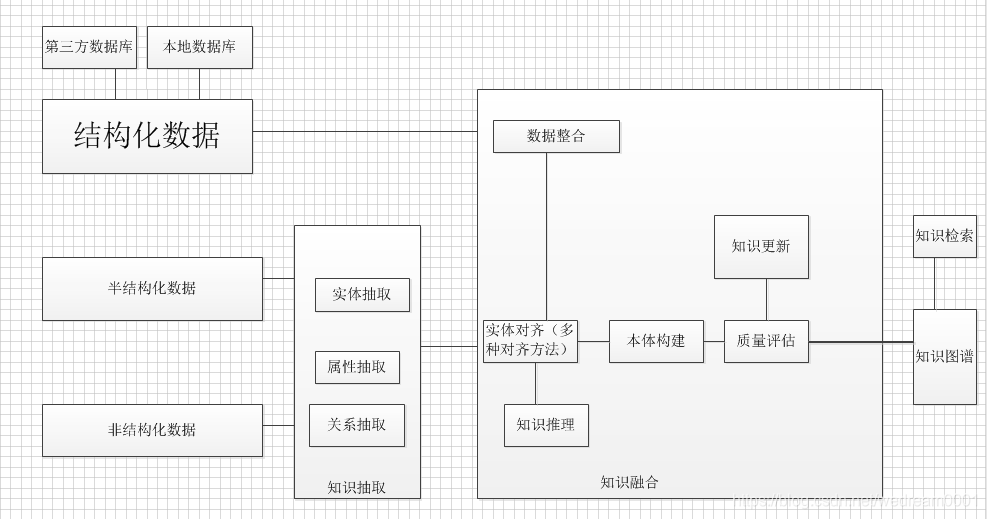
知识图谱架构的主要部分:
1,数据来源(结构化数据,半结构化数据,非结构化数据)
2,知识抽取(包括实体抽取,关系抽取,属性抽取等);
3,知识融合(知识消歧,本体构建,质量评估,知识推理,知识更新等);
4,知识图谱创建;
4,知识图谱应用。
已有的大规模知识库:
知识图谱的关键技术:
1,知识抽取:
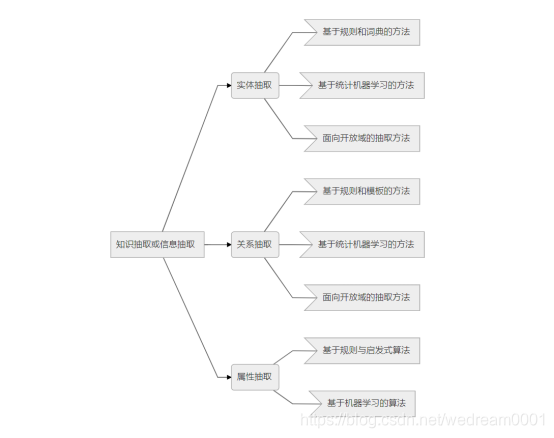
2,知识融合:
实体连接:
I,实体消歧:主要用于同名实体产生歧义的问题。主要采用聚类法,关键在于定义实体与指称项相似度,常用的方法有:空间向量模型或词袋模型、语义模型–语义模型与空间向量模型类似不同的是不仅包含词袋向量还包括部分语义特征、社交网络模型–该模型假设是物以类聚人以群分,在社会化的环境中实体指称项的意义由其相关联的实体所决定、百科知识模型(百科网页会为每一个实体创建一个单独的网页,其中包括指向其他实体的链接)–根据链接关系确定实体指称项之间的相似度。
II,实体对齐:主要是用于解决异构数据中实体冲突,指向不明确等不一致问题。可以从顶层构建一个大规模的知识库,帮助机器理解多源异质的数据,提高知识库的质量。实体对齐分为成对实体对齐和集体实体对齐,集体对齐又可以分为局部集体实体对齐和全局集体实体对齐。成对实体对齐可以基于传统的概率模型对齐方法或机器学习模型的对齐方法。局部实体对齐方法是为其本身的属性和与其关联的实体的属性设置不同的权重,并通过加权求和来计算相似度,还可以用向量空间模型或余弦相似性来判别大规模知识库中实体的相似度,算法为每个实体创建了名称向量和虚拟文档向量,名称向量用于标识实体的属性,虚拟文档向量用于标识属性值以及邻接点属性值的加权和值。全局实体集体对齐方法基于相似性传播的集体实体对齐方法或基于概率模型的集体对齐方法。
实体连接的方法也可以从整体层面上分类如下:概率模型方法,主题模型方法,图法,深度神经网络的方法
3,知识合并:
I,合并外部知识库:将外部知识库融合到本地知识库,需要注意两个问题:数据层的融合(包括实体的指称,属性,关系以及所属类别主要问题是避免实例及关系的冲突问题,造成不必要的冗余)和模式层的融合(将新得到的本体融合到本地已有的本体库中);
II,合并关系数据库:在知识图谱构建过程中,一个高质量的知识来源于企业或机构自己的关系数据库。为了将这些高质量的结构化的历史数据融入到知识图谱中可以采用资源描述架构(RDF)作为数据模型,称之为RDB2RDF,其实质就是将关系数据库中的数据转换为RDF的三元数据。
4,知识加工:
I,本体构建:本体定义了组成主题域的词汇表的基本术语及其关系,以及结合这些术语及关系来定义词汇表外延的规则。本体最大的特点是它的共享性,本体中反应的知识是明确定义的共识。本体是同一领域中不同实体进行语义交流的基础,相邻层次的节点(概念)之间具有严格的“IsA”关系 ,这种纯粹的关系有利于推理却不利于表达概念的多样性。本体的构建可以采用人工编辑的方式手动编辑(借助于本体编辑软件),也可以采用计算机辅助以数据驱动的方式自动构建。然后采用算法评估和人工审核相结合的方式予以确认和修正。还可以采用垮语言知识链接的方式来构建本体库。对当前本体构建的方式的研究主要集中在实体聚类的方式,主要挑战在于经过信息抽取后获得的实体描述非常简短,缺少必要的上下文信息,导致多数统计模型不可用(可以利用主题进行主题聚类);
II,知识推理:指从知识库中已存在的实体关系数据出发,经过计算机推理,建立实体间新的关系,从而拓展和丰富知识网络,知识推理是知识图谱构建的重要手段和关键环节,通过知识推理能够从现有的知识中发现新的知识;
III,质量评估:质量评估任务通常与实体对齐任务一起进行的,意义在于对于知识的可信度进行量化,保留置信度较高的知识,舍弃置信度较低的知识,从而提高知识库的质量。
5,知识更新:
人类所拥有的信息和知识量都是时间的单调递增函数,因此知识图谱也需要不断的更新,是一个不断迭代更新的过程。知识库的更新包括概念层的更新和数据层的更新,知识图谱的更新主要有数据驱动下的全面更新和增量更新两种方式。
6,知识表示:
三元组形式的知识表示受到了广泛的认可和接收,但是在计算效率和数据稀疏性方面存在着很多问题,以深度学习代表的学习技术能够将实体语义信息表示为稠密低维的实值向量,进而在低维空间中计算实体、关系及其之间复杂的语义关联,对知识库的构建,融合,推理和应用具有重要意义。分布式表示旨在用一个综合的向量表示实体语义信息,是一种模仿人脑工作的机制,通过知识表示而得到的分布式表示在知识图谱的计算,推理,补全等方面起着重要的作用,语义相似度计算和链接预测(知识图谱补全)等代表模型如下:
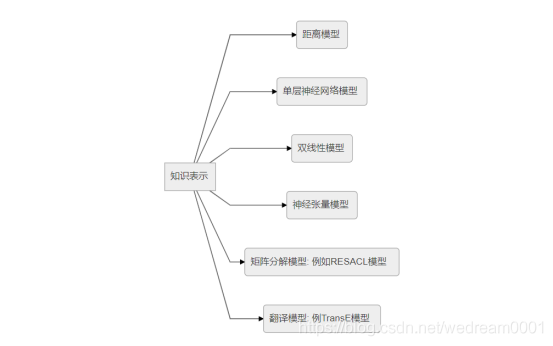
模型解释:
I,距离模型:首先将实体用向量进行表示,然后通过关系矩阵将实体投影到与实体向量同一纬度的向量空间中,最后通过计算投影向量之间的距离来判断实体间已经存在的关系的置信度。由于距离模型中的关系矩阵是两个不同的矩阵,故实体间的协同性较差,这也是该模型本身的主要缺陷。
II,单层神经网络:针对距离模型的缺陷,提出了采用单层神经网络的非线性模型(single layer model,SLM)。单层神经网络模型的非线性操作虽然能够进一步刻画实体在关系下的语义相关性,但是在计算开销上却大大增加。
III,双线性模型:又叫隐变量模型(latent factor model,LFM)。双线性模型主要是通过基于实体间关系的双线性变换来刻画实体在关系下的语义相关性,模型不仅形式简单、易于计算,而且能够有效刻画实体间的协同性。
神经张量模型:其基本思想是在不同维度下,将实体联系起来,表示实体间复杂的语义联系。神经张量模型在构建实体的向量表示时,是将该实体中的所有单词的向量取平均值,这样一方面可以重复使用单词向量构建实体,另一方面将有利于增强低维向量的稠密程度以及实体与关系的语义计算。
V,矩阵分解模型:通过矩阵分解的方式可以得到低维的向量表示,故不少研究者提出可以采用该方式进行知识表示学习,其中典型的代表是RESACL模型。
VI,翻译模型:受到平移变象限的启发,提出了TransE模型,即将知识库中实体之间的关系看成是从实体间的某种平移,并用向量表示。关系lr可以看成头实体向量lh到尾实体向量lt的翻译。该模型的参数较少,计算的复杂度显著降低,同时,TransE模型在大规模稀疏数据库上也同样具有较好的性能与可扩展性。
VII,复杂关系模型:知识库中实体关系类型可分为:1-to-1、1-to-N、N-to-1、N-to-N 4种类型。代表性模型有:TransH模型、TransR模型、TransD模型、TransG模型、KG2E模型。
空间向量模型:由Salton等人于20世纪70年代提出,并成功用于著名的smart文本检索系统。是把对文本的处理简化为向量空间中向量的运算,计算向量之间的相识度,具体的公式为 向量内积/向量模的乘积 得到的值如果为1则为一致,为0则不相似,即余弦相似性公式。余弦为零则表示检索词向量与文件向量垂直,即没有符合,也就是说该文件不含有此检索词,从而达到把文本数据转化为计算机能够处理的结构化文本数据,两个文档之间的相似性就转换为两个向量的相似性问题。