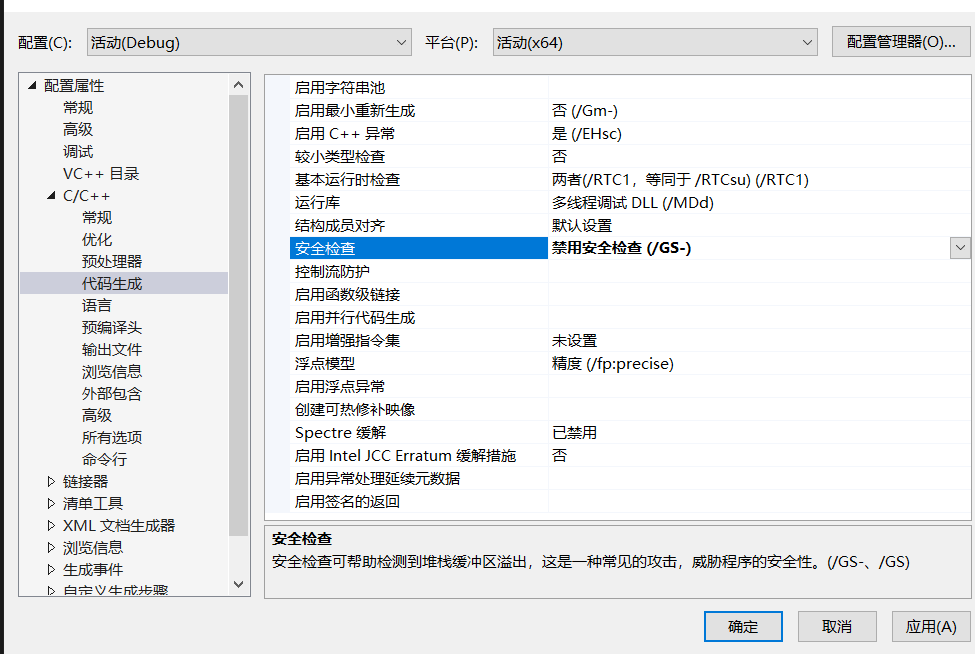
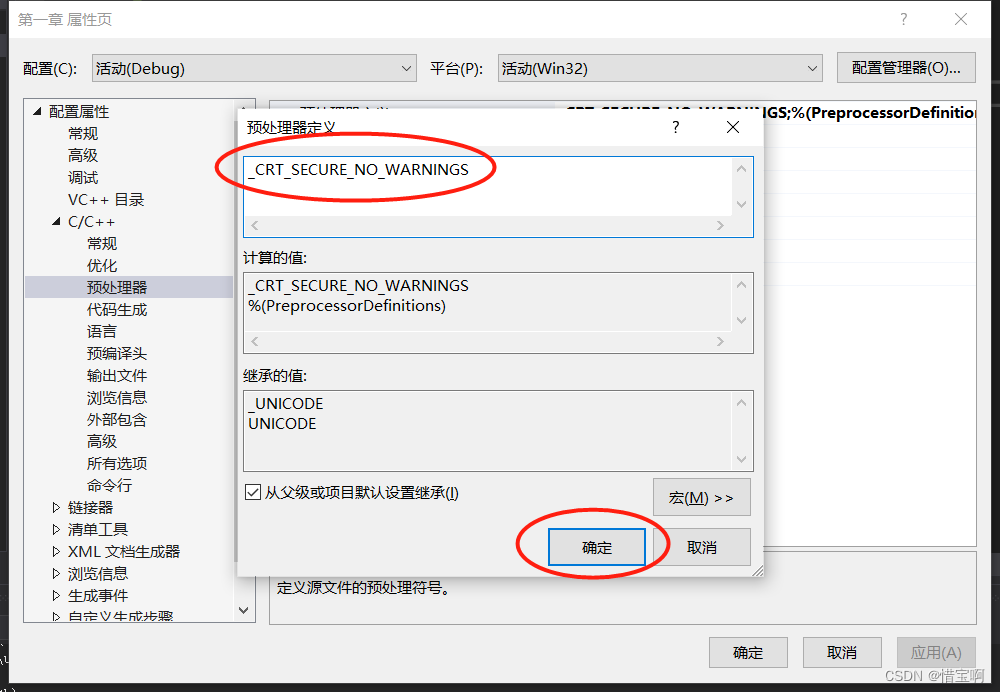
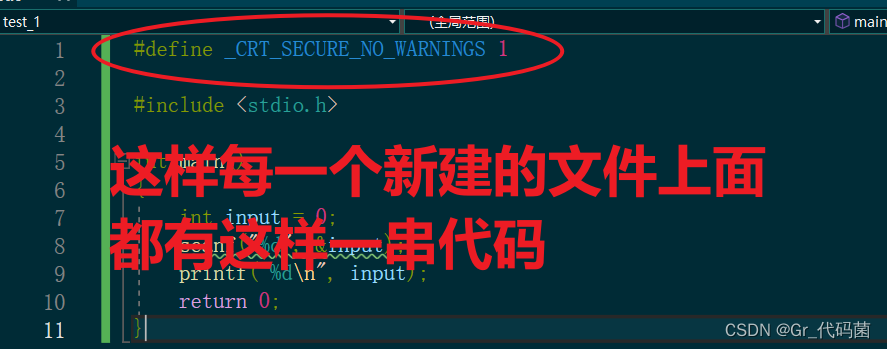
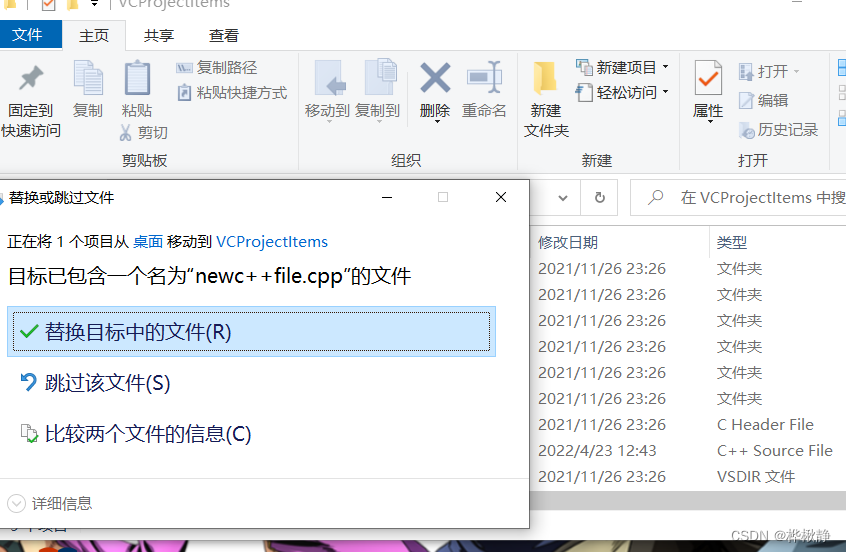
http://www.pythonchallenge.com/pc/def/ocr.html
recognize the characters. maybe they are in the book,
but MAYBE they are in the page source.
第2关:从现在开始,要从页面中寻找答案了。其实是在注释中。从页面源码中可以发现其有一段注释,还比较长。很麻烦。可以直接拷贝。它其实有两段注释,一段是告诉你做啥:<!--find rare characters in the mess below:-->,另一段则是要操作的。
直接拷贝使用""""""这个的变量中也可以。我这里使用urllib获取源码吧,虽然我更喜欢requests。
- 获取页面
import urllib.requestdef get_html_page(url):page = Noneresp = urllib.request.urlopen(url)if (resp.status == 200):page = resp.read().decode('utf-8')return page - 然后正则表达式获取注释内容
import redef get_comments(page):rs = re.findall('<!--\s*(.*?)\s*-->', page, re.S)print(rs)if rs:return rs[1]return None - 主函数:
def main():url = 'http://www.pythonchallenge.com/pc/def/ocr.html'page = get_html_page(url)comments = get_comments(page)print(comments)maps = {}for c in comments:maps[c] = maps.get(c, 0) + 1half = len(comments) // len(maps)rs = ""for k, v in maps.items():if v < half:rs += kprint(rs)
URL:http://www.pythonchallenge.com/pc/def/equality.html



![Python Challenge 题解 [0-4]](https://img-blog.csdnimg.cn/2021030718245530.jpg?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80NDU3MTI3Nw==,size_16,color_FFFFFF,t_70)