前言
PythonChallenge是国外的一位工程师设计的一套编程闯关游戏,网址:PythonChallenge,每一关都可以用一段Python程序解决问题得到下一关的入口,本博文作为一个学习笔记,通过边学边记的方式分享我的闯关经验。
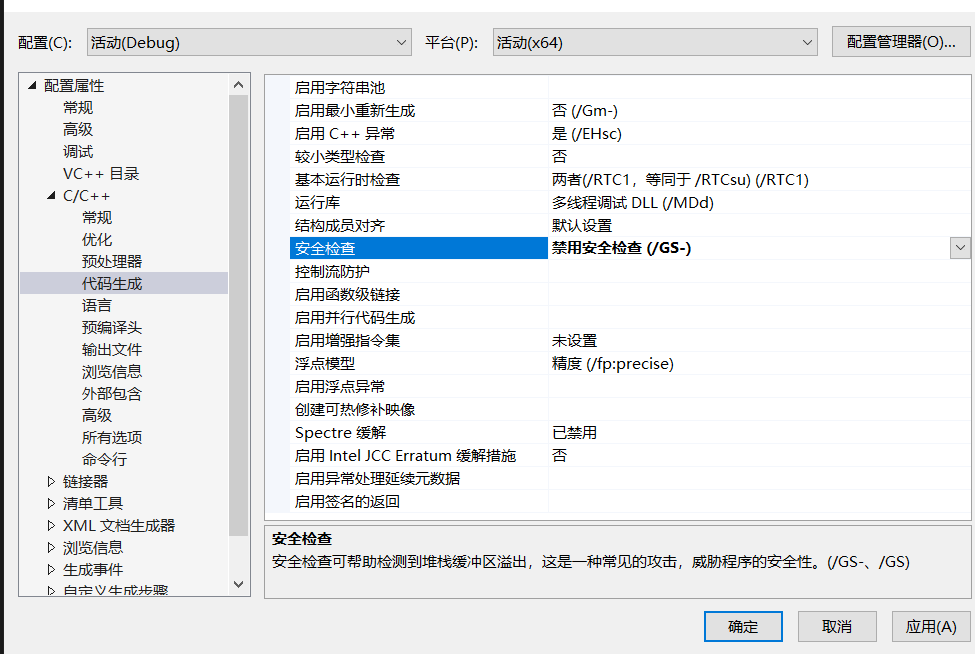
0 图片上是2 38的字样,下方提示为改变当前URL地址,很明显,用Python脚本计算下2的38次方,替换下URL中的0就可以了
2**38
得到274877906944,那么下一关地址:
http://www.pythonchallenge.com/pc/def/274877906944.html
1 仍然是一幅图,标记K->M O->Q E->G,下方有一串字母,看不出什么意思,很明显,这是让你解密,按照图片中的提示,将字母向后移动两位即可,注意y要对应a,z对应b,这样逻辑才能完整。刚开始用的是最原始的方法解题,解出来后作者推荐用maketrans的方法,试了下更好用。
import sys
from string import maketrans
str = "g fmnc wms bgblr rpylqjyrc gr zw fylb. rfyrq ufyr amknsrcpq ypc dmp. bmgle gr gl zw fylb gq glcddgagclr ylb rfyr'q ufw rfgq rcvr gq qm jmle. sqgle qrpgle.kyicrpylq() gq pcamkkclbcb. lmu ynnjw ml rfc spj."
intab = "abcdefghijklmnopqrstuvwxyz"
outab = "cdefghijklmnopqrstuvwxyzab"
transtab = maketrans(intab,outab)
print str.translate(transtab)
print "map".translate(transtab)
将网址中的“map”应用这种转换得到“ocr”,这就是下一关的入口了。
2 提示:识别字符,可能在书里,可能在页面源码里,果断F12,查看网页源码,在网页源码的注释中,提示找到出现次数最少的字符,有一大串字符,数数是肯定不行的,考虑用程序解决。
str = "balabalabala..."
cnt = {} # 用于保存字符出现的总次数
list = [] # 用于保存字符首次出现的先后顺序
for i in str:if i in cnt:cnt[i] += 1else:cnt[i] = 1list.append(i)
print cnt
print list
次数出现最少的是几个字母,只出现了一次,按照出现的先后顺序,拼成“equality”, 这就是下一关的入口了。
3 提示里直接翻译字面意思:找到这样的小写字母,它的两侧都被确定的三个大写字母包围。那么要在哪里找呢?按照上一关的经验, 我们再打开网页源码,仍然看到了一大串的字符;那么应用正则表达式匹配可以快速地找到符合条件的字母。
import re
str = "balabala..."
pattern = re.compile(r'[^A-Z][A-Z]{3}[a-z][A-Z]{3}[^A-Z]')
res = pattern.findall(str)
print(res)
最后找到的字母组合起来是:linkedlist,这就是下一关的入口了。
4 这一关作者使用了PHP,一开始只有一幅图片,没有其他任何提示,不过当点击图片的时候跳转到了另一个网页,只有一句话“and the next nothing is 44827”,那么把44827放到URL中的nothing中,又开始了跳转,还是只有一句话“and the next nothing is 45439”,这个五位数应该是下一个跳转的入口。我们总不能手动一个一个地跳转,别忘了我们的初衷,用python来自动地访问网页,不断提取下一个入口的钥匙,最终应该能找到下一关的入口,这个应该是作者的意图了。
在实际运行的过程中,作者设置了一些障碍:
a. 除以2,网页内容是“Divede by two and keep going”,这个时候要特殊处理下
b. misleading number,内容中出现误导数字,注意要严格匹配“the nothing is”后边的数字
import requests
import re
import time
url = "http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing="
key = "90990"
pattern = r'and the next nothing is ([0-9]+)'
while True:print(url + key)curtext = requests.get(url + key).textprint(curtext)if "Divide by two" in curtext: # handle "Divide by two"key = str(int(key)/2)continueif "and the next nothing" not in curtext:breakkey = re.search(pattern,curtext).group(1)
最后一个匹配的数字66831,这个时候网页内容是“peak.html”,这是下一关的入口了。
5 这一关仍是一副图片,提示为“pronounce it”, 没看懂,然后打开网页源码,有一个banner.p的网址,打开后一堆字符,然后提示“peak hell sounds familiar?”,恩,还是没懂。果断百度,查到peak hell是谐音python的一个pickle标准库,呃。。。我真的不知道这个库是干啥用的,果断再百度,原来这个库是用来序列化和反序列化的,赶脚类似于加解密一样的,贴一个比较有帮助的博客pickle学习
那么我们应该要做的是反序列化,看看真实内容是什么,反序列化的内容当然是那个banner.p的内容了。
反序列之后得到的是一个list,每个元素还是一个list,再向下的元素就是元组了,得到了这些还是不知道下一关入口在哪里,再去百度,原来每个元组的第一个元素是一个字符,第二个元素是数字,就是这个字符重复了多少次,问题到这里就比较清楚了,把这些打印出来就是了,代码如下:
import pickle
f = open("./123",'r')
bb = pickle.load(f)
f.close
print bb
for line in bb:print(''.join(x[0]*x[1] for x in line))
打印的结果是

下一关的入口就是channel了
6 这一关的图片是一幅拉链的图,下边是一个paypal的按钮,打开网页源码,上边注释里zip的提示,下边注释的一大段话的意思是作者请求对这个项目捐赠的内容,跟本题无关,也就是说,那个paypal的按钮是真的会跳转到付款页面的。。。
也就是说,有用的提示就是zip,zip也是拉链的意思,那么把url里的channel改成zip会怎样呢,是一段话“yes,find the zip.”,然后就没有然后了;
再把html改成zip呢,咦,会下载一个channel.zip的文件,解压缩后,里边有N多个txt文件,还有一个readme,每个txt的内容似曾相识,“Next nothing is XXXXX”,readme里有两个提示:一个是起始数字是90052,另一个是答案在zip里,那么,问题就很清楚了,通过不断地循环读取文件,直到找到下一关入口,跟第4关类似,不同的是,登网页改成读文件了。
import re
dirpath = "./channel/"
curnum = "90052"
pattern = r'Next nothing is ([0-9]+)'
while True:filepath = dirpath + curnum + ".txt"print filepathf = open(filepath,'r')content = f.read()cursch = re.search(pattern,content)f.closeif cursch == None:print contentbreakelse:curnum = cursch.group(1)
最后打开的文件是46145.txt,内容是“Collect the comments.”。嗯,这个也没懂什么意思,去百度了下,原来zip压缩文件都有一个注释,而这个注释可以通过python的zipfile取出来,那么我们再按照刚来检索文件的顺序,取每个文件的Comment,并收集打印出来,就是。。。

那么入口是hockey。。。吗? 输入hockey后,页面有一段话“it’s in the air. look at the letters.”,提示我们注意看字幕,那么下一关的入口就是oxygen了