requests
请求库
import requests
import recontent = requests.get('https://book.douban.com/').text
pattern = re.compile('<li.*?cover.*?href="(.*?)".*?title="(.*?)".*?more-meta.*?author">(.*?)</span>.*?year">(.*?)</span>.*?</li>', re.S) # 匹配换行
results = re.findall(pattern, content) # 返回一个元组
for result in results:url, name, author, date = resultauthor = re.sub('\s', '', author) # 替换date = re.sub('\s', '', date)print(url, name, author, date)结果
https://book.douban.com/subject/26925834/?icn=index-editionrecommend 别走出这一步 [英]S.J.沃森 2017-1
https://book.douban.com/subject/26953532/?icn=index-editionrecommend 白先勇细说红楼梦 白先勇 2017-2-1
https://book.douban.com/subject/26959159/?icn=index-editionrecommend 岁月凶猛 冯仑 2017-2
2
import requests
import recontent=requests.get('https://www.myaijarvis.com/').text
#print(content)
pattern=re.compile('<div.*?title-article.*?<div.*?list-pic.*?href="(.*?)".*?<h1>(.*?)</h1>', re.S)
results=re.findall(pattern,content)
#print(results)
for result in results:url,title=resultprint(url,title)结果
https://www.myaijarvis.com/archives/351/ JavaScript学习笔记
https://www.myaijarvis.com/archives/349/ 国风舞蹈—— 【霜降】 甜到你 ❤ 里呀 ~【紫颜】
https://www.myaijarvis.com/archives/324/ C++ 引用&&C语言二级指针(地址法理解)
XPath
快速获得需要的数据
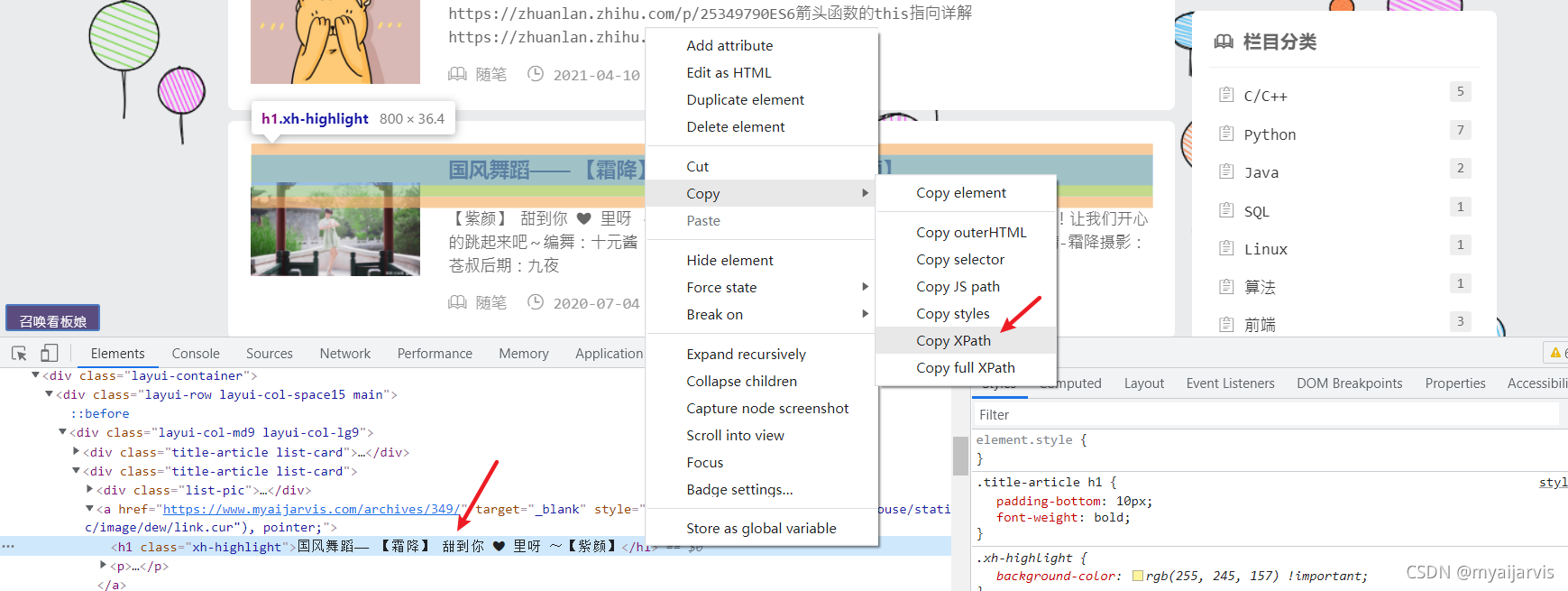
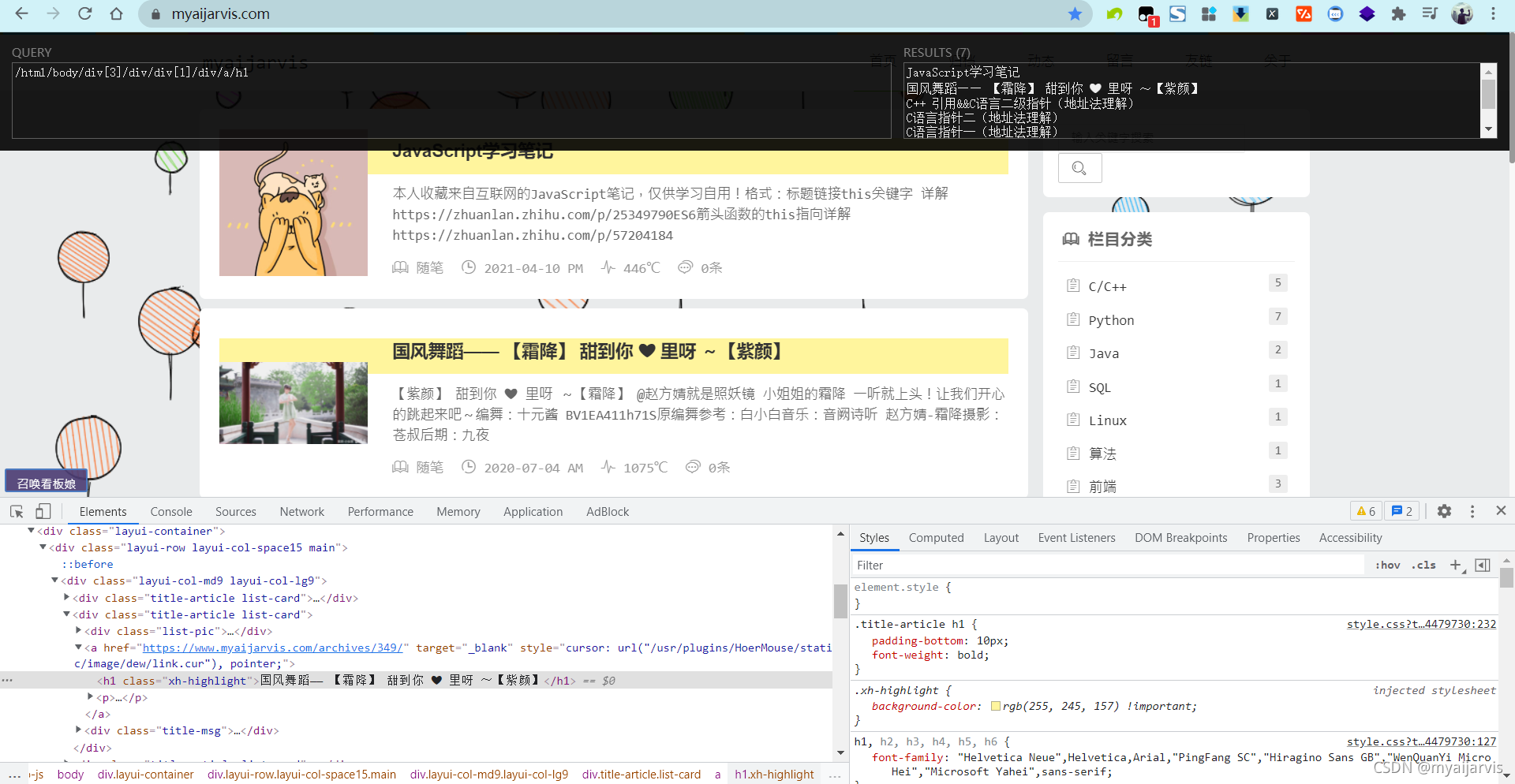
/html/body/div[3]/div/div[1]/div/a/h1JavaScript学习笔记
国风舞蹈—— 【霜降】 甜到你 ❤ 里呀 ~【紫颜】
C++ 引用&&C语言二级指针(地址法理解)
C语言指针二(地址法理解)
C语言指针一(地址法理解)
typecho开启伪静态,去掉那个讨厌的index.php
HTML5+CSS+JS基础教程笔记
BeautifulSoup
HTML和XML的解析库
https://cuiqingcai.com/1319.html
标准选择器
- 可根据标签名、属性、内容查找文档
find_all( name , attrs , recursive , text , **kwargs )
find( name , attrs , recursive , text , **kwargs )
find返回单个元素,find_all返回所有元素组成的列表
html='''
<div class="panel"><div class="panel-heading"><h4>Hello</h4></div><div class="panel-body"><ul class="list" id="list-1" name="elements"><li class="element">Foo</li><li class="element">Bar</li><li class="element">Jay</li></ul><ul class="list list-small" id="list-2"><li class="element">Foo</li><li class="element">Bar</li></ul></div>
</div>
'''from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')# 支持嵌套选择
for ul in soup.find_all('ul'):print(ul.find_all('li'))print(soup.find_all(attrs={'id': 'list-1'}))
print(soup.find_all(attrs={'name': 'elements'}))print(soup.find_all(id='list-1'))
print(soup.find_all(class_='element'))print(soup.find_all(text='Foo'))print(soup.find('ul'))
print(type(soup.find('ul')))
print(soup.find('page'))
find_parents() find_parent()
find_parents()返回所有祖先节点,find_parent()返回直接父节点。
find_next_siblings() find_next_sibling()
find_next_siblings()返回后面所有兄弟节点,find_next_sibling()返回后面第一个兄弟节点。
find_previous_siblings() find_previous_sibling()
find_previous_siblings()返回前面所有兄弟节点,find_previous_sibling()返回前面第一个兄弟节点。
find_all_next() find_next()
find_all_next()返回节点后所有符合条件的节点, find_next()返回第一个符合条件的节点
find_all_previous() 和 find_previous()
find_all_previous()返回节点后所有符合条件的节点, find_previous()返回第一个符合条件的节点
CSS选择器
通过select()直接传入CSS选择器即可完成选择
html='''
<div class="panel"><div class="panel-heading"><h4>Hello</h4></div><div class="panel-body"><ul class="list" id="list-1"><li class="element">Foo</li><li class="element">Bar</li><li class="element">Jay</li></ul><ul class="list list-small" id="list-2"><li class="element">Foo</li><li class="element">Bar</li></ul></div>
</div>
'''from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')print(soup.select('.panel .panel-heading'))
print(soup.select('ul li'))
print(soup.select('#list-2 .element'))
print(type(soup.select('ul')[0])) # <class 'bs4.element.Tag'># 支持嵌套选择
for ul in soup.select('ul'):print(ul.select('li'))# 获取属性
for ul in soup.select('ul'):print(ul['id'])print(ul.attrs['id'])
'''
list-1
list-1
list-2
list-2
'''# 获取内容
for li in soup.select('li'):print(li.string)print(li.get_text())
'''
Foo
Bar
Jay
Foo
Bar
'''
pyquery
解析库
通过doc()直接传入CSS选择器即可完成选择
初始化参数可以是字符串、URL、文件名
from pyquery import PyQuery as pq
doc = pq(url='http://www.baidu.com') # 初始化
print(doc('head')) # 选择节点
html = '''
<div id="container"><ul class="list"><li class="item-0">first item</li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li><li class="item-1 active"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul></div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
print(doc('#container .list li'))
print(type(doc('#container .list li'))) # <class 'pyquery.pyquery.PyQuery'>item=doc(CSS选择器)# 函数调用与jQuery中函数用法完全相同
item.find('.item-0')
item.children()
item.parent()
item.attr('href') # 获取属性
item.text()
item.html()
item.addClass('xxx')
item.removeClass('xxx')
...# 返回多个节点
lis = doc('li').items()
print(type(lis))
for li in lis:print(li) print(type(li))# <class 'pyquery.pyquery.PyQuery'>
Selenium
Selenium 是一个自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击、下拉等操作,同时还可以获取浏览器当前呈现的页面的源代码,做到可见即可爬。对于一些 JavaScript 动态渲染的页面来说,此种抓取方式非常有效。
https://cuiqingcai.com/5630.html
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWaitbrowser = webdriver.Chrome()
try:browser.get('https://www.baidu.com')input = browser.find_element_by_id('kw')input.send_keys('Python')input.send_keys(Keys.ENTER)wait = WebDriverWait(browser, 10)wait.until(EC.presence_of_element_located((By.ID, 'content_left')))print(browser.current_url)print(browser.get_cookies())print(browser.page_source)
finally:browser.close()
Scrapy
进入命令行调试
scrapy shell https://www.myaijarvis.com