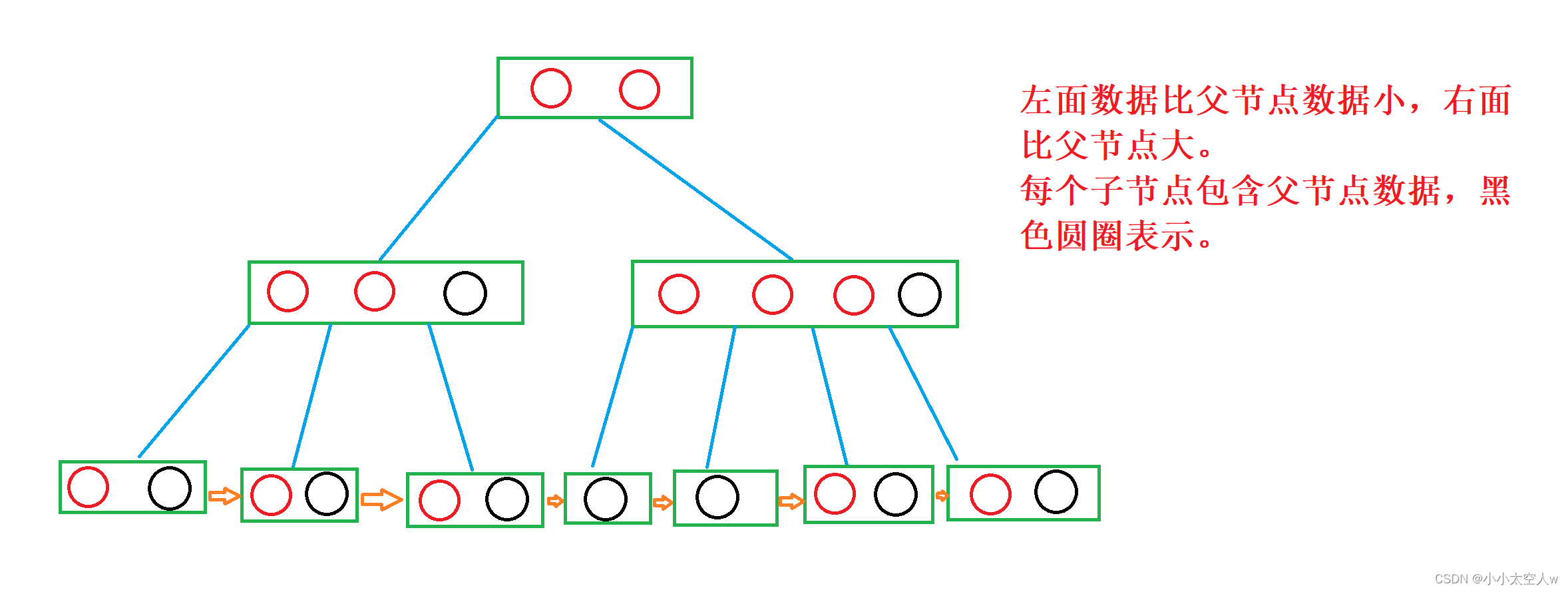
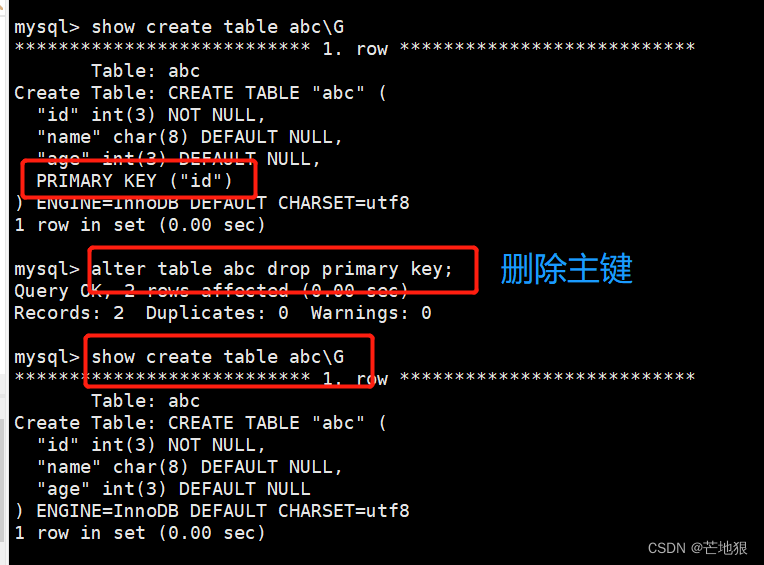
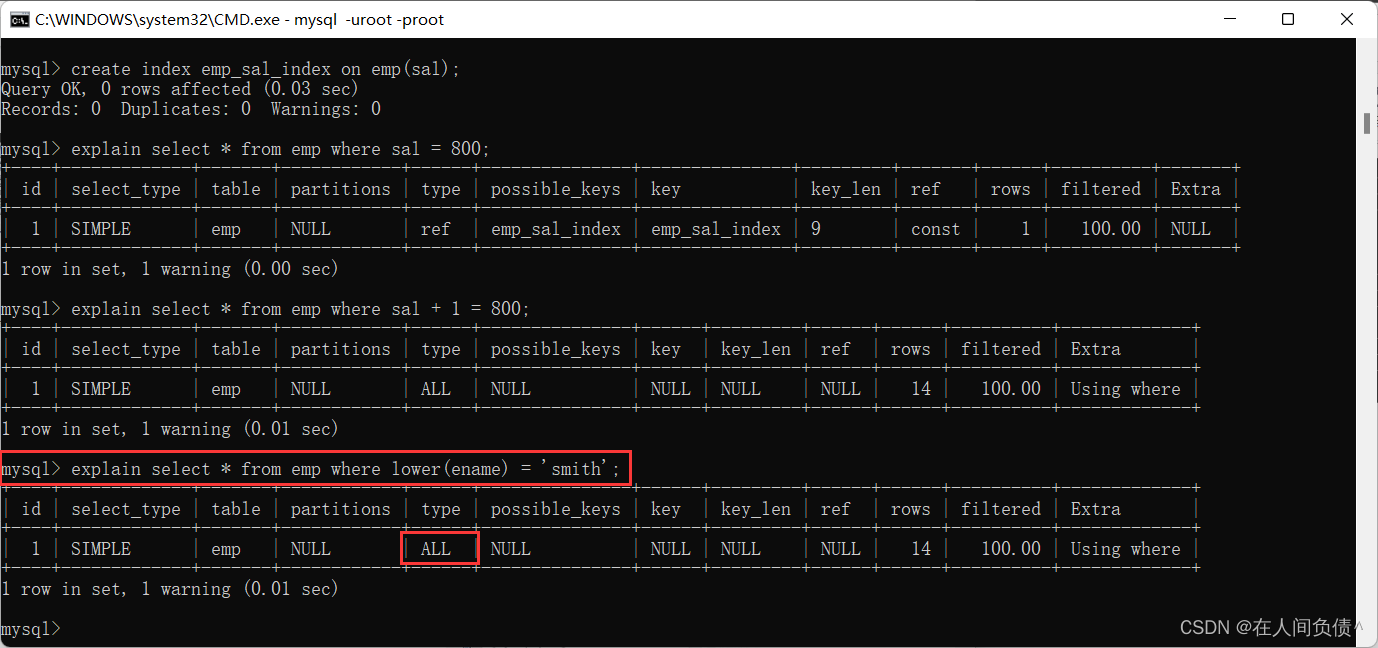
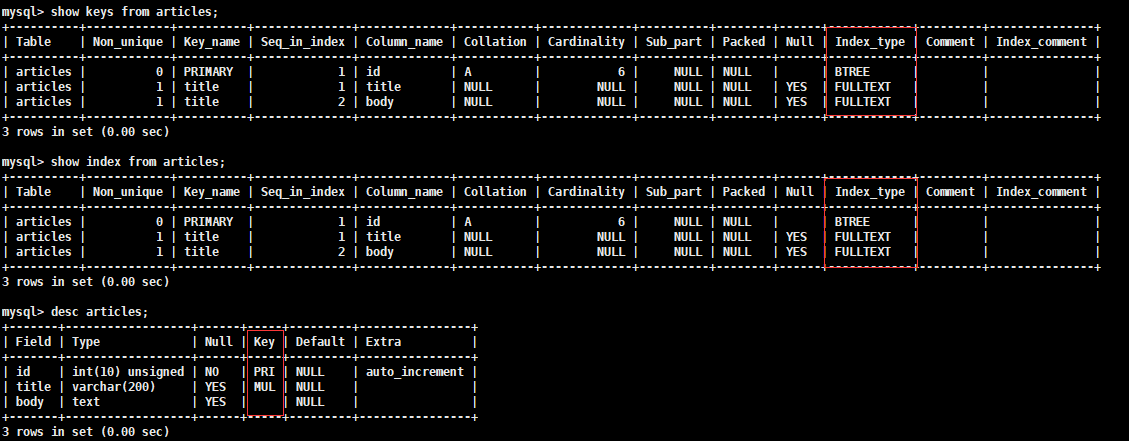
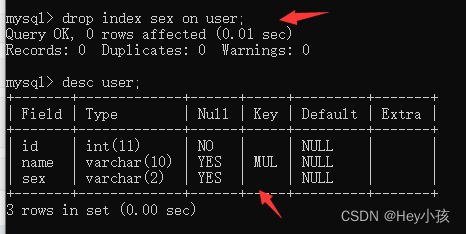
索引:实质上是一种排好序的数据结构。
B-tree:
叶子节点具有相同的深度,叶节点的指针为空
所有索引元素不重复
节点中的数据索引从左到右递增排列
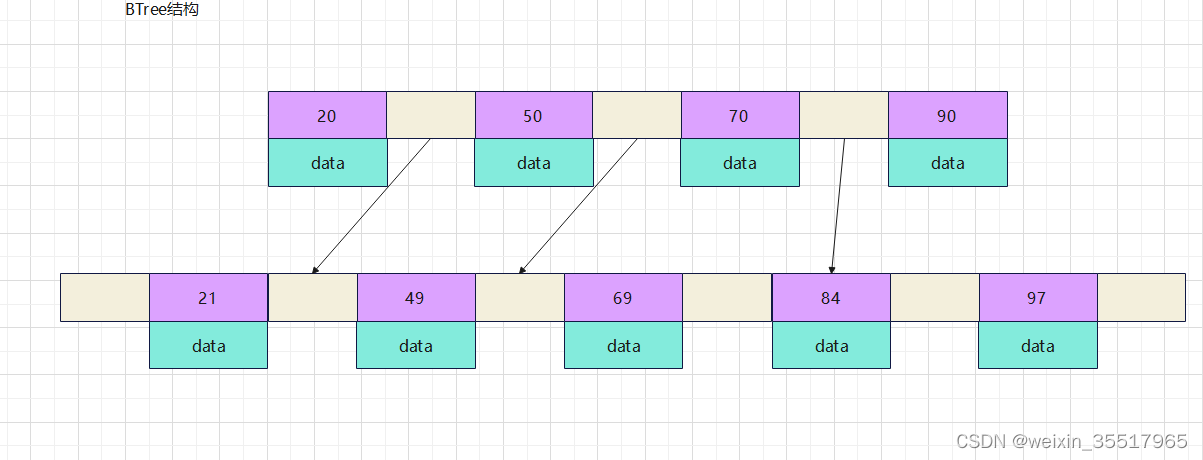
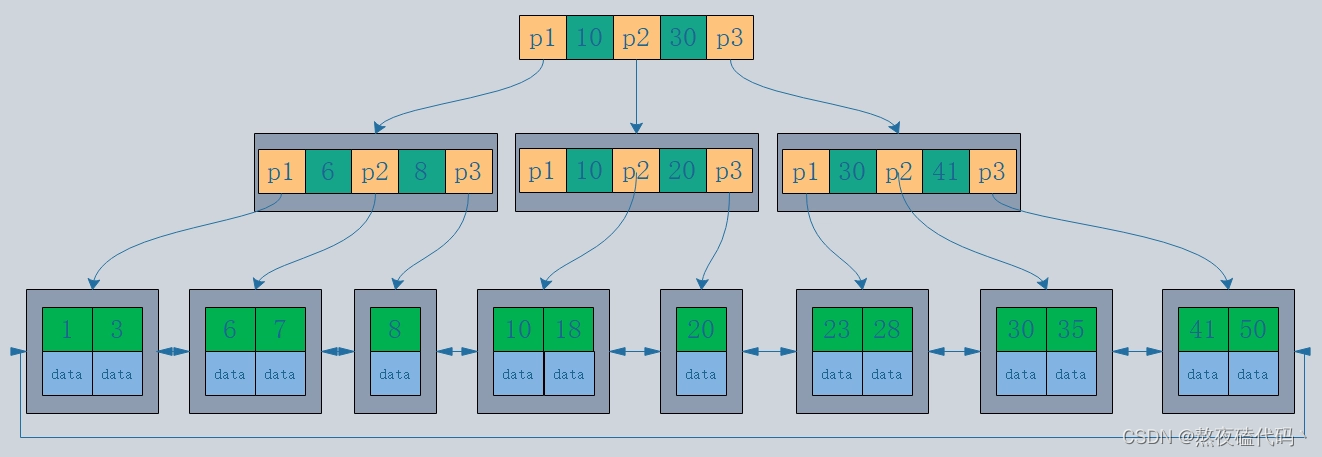
B+tree:
非叶子几点不存储data,只存储索引;
叶子节点中包含所有的索引字段;
叶子节点用指针链接,提升区间访问性能;
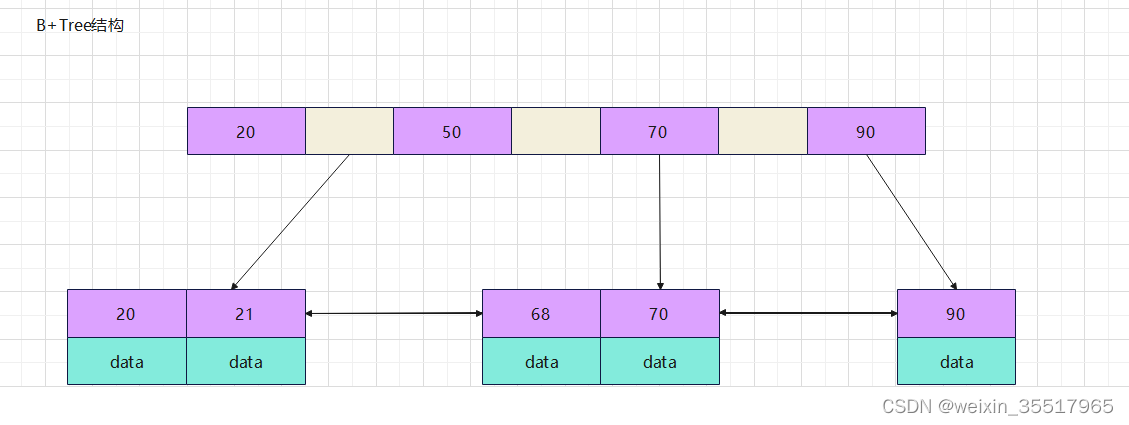
分析两种树结构有什么不同?
1.b-tree中叶子每个节点上都有数据,而b+tree上只有叶子节点有数据。
2.b-tree中叶子叶子节点上是没有枝干节点上的数据的,b+tree树上是有枝干上的数据的。
为什么Mysql数据库使用的是b+tree而不是b-tree呢?
mysql中定义索引是有页数存储的,每一页大小默认16k,b+tree中只存了索引没有存data,数据量小,所以在通层数中的数据存储量远远高于b-tree,搜索效率更快。
注意:
页上面是双线链表结构,
聚集索引:索引和数据在同一文件中
非聚集索引:索引和数据不在同一文件中

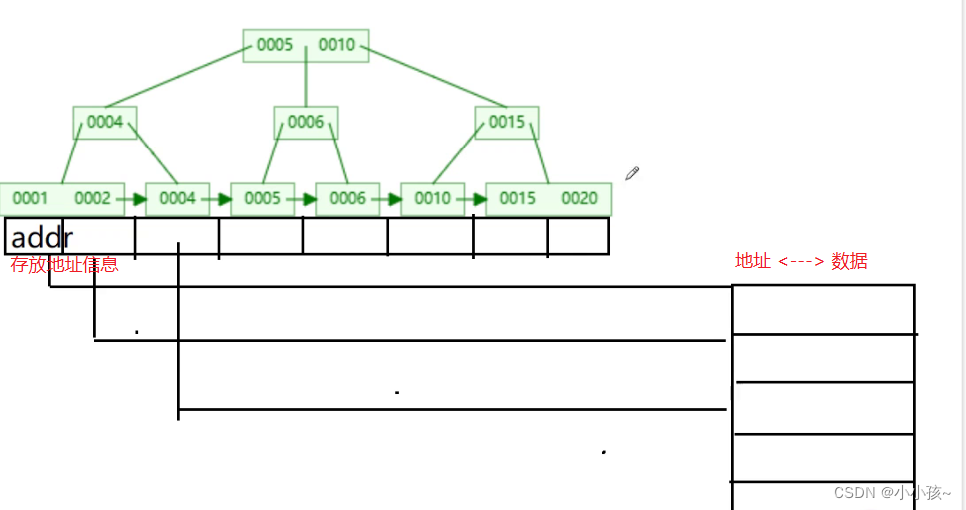
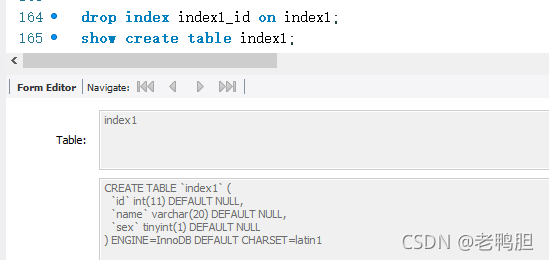
上面图中主键和名称索引就是innodbB+tree结构索引,为主键索引是聚集索引,名称索引里面存储的data是主键,查询的时候需要先定位到主键,然后再通过聚集索引查询完整数据。
后面的是MyISAM索引,但是因为是通过地址查询,不支持事务,所以Mysql中表索引一般不建议使用MyISAM。
B+tree 和 Hash 结构,理论上Hash查询速度可能更快,但是Hash不支持范围查询,所以不适用Hash。
为什么InnoDB索引推荐创建一个自增主键?
在查询非自增主键的时候可能会导致,索引树分裂并且重新平衡,影响速率。
联合索引数据结构是怎么样的?
name_age_sex,先比较左边的name,再比较中间的age,最后比较右面的sex,这就是最左前缀原理。
总结:
一个sql能不能使用索引,简单的来说就是看查询来的数据能不能符合索引的顺序结构。如果查询数据违背顺序,就不会使用索引,但是mysql使不使用索引,还是要有mysql决定的,里面有个计算cost成本的算法,举个例子,如果数据量少,mysql可能就会全表扫描,他会认为全表扫描的时候成本更低,所以可能不会使用索引,因为非主键索引可能会回表查询。