1. 概述
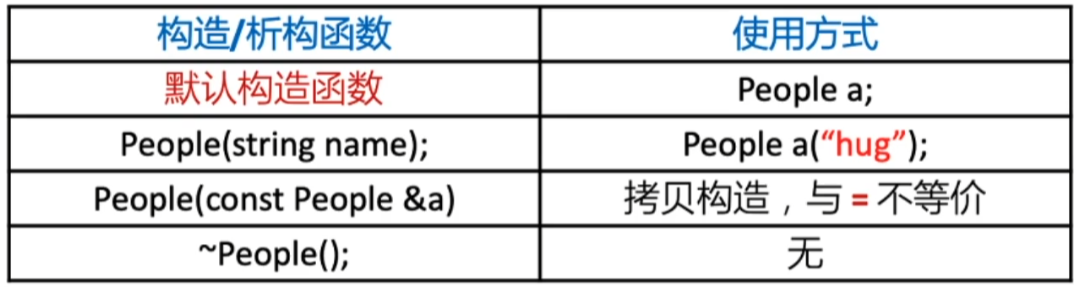
构造函数:用于初始化对象,没有返回值,函数名和类名相同,只有在对象初始化的时候才会被调用。构造函数的分类:
-
默认构造函数:是编译器自动生成,没有任何参数的构造函数。
-
有参构造函数:如果只一个参数的构造函数叫做转换构造。
-
拷贝构造函数:传入的参数类型和当前对象的类型一致时,这类有参构造叫做拷贝构造,是特殊的有参构造函数。之所以要传入引用,是为了防止出现”套娃“,即多次调用拷贝构造函数。
-
移动构造:与右值相关,后续再讲解。
析构函数:用于销毁对象,没有返回值,函数名和类名相同。
构造函数和析构函数会涉及到资源的申请和释放,但是在工业环境中,不会在构造函数中申请很大的资源,因为一旦构造函数出问题了,异常处理机制是很难捕获到这种异常的。取而代之的是额外编写一个方法来申请资源,同样地也会额外写一个伪析构方法来释放资源。设计模式中的工厂模式也是为了解决这个问题的。
在C++11之前,因为语言特性问题,所以STL性能不高。而在C++11中引入了左值和右值的概念,且引入了移动构造的概念,有了移动改造使得STL性能问题得到了大大的改善,所以C++11使得C++重回神坛。
2. 构造函数
构造函数的调用
#include<iostream>
using namespace std;class A {
public :A() {cout << this << " : constructor" << endl;}A (int x) {cout << this << " : transform constructor" << endl;}~A() {cout << this << " : destructor" << endl;}
};int main() {A a;A b;//如下两种写法都会调用转换构造//A c(3);A c = 3;cout << "end of main" << endl;return 0;
}
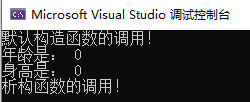
运行结果:构造顺序和析构顺序是相反的

有参构造
为什么只有一个参数的构造函数叫做转换构造呢?
A a; a = 123;,其中a = 123;就是将 123 赋值给对象 a,但是对象赋值只有在相同或者相近类型才可以完成,那么在逻辑上来讲 123 已经被转换为一个 A 类型的值,所以才能赋值给 A 类型的对象。而这个转换的过程就是通过转换构造函数来完成的。
#include<iostream>
using namespace std;class A {
public :A() {cout << this << " : constructor" << endl;}A (int x) {cout << this << " : transform constructor" << endl;}~A() {cout << this << " : destructor" << endl;}
};int main() {A a; A b;//A c(3);A c = 3;a = 123; //将123赋值给对象acout << "end of main" << endl;return 0;
}
运行结果:

也就是说:
A(int x) {} //可以将一个整型转换为A类型
A(string name) {} //可以将一个string类型转换为A类型
程序的处理流程
int main() {A a; //调用了默认构造函数A b; //调用了默认构造函数A c = 3; //调用了转换构造a = 123; //将123赋值给对象a,这行代码的处理流程?cout << "end of main" << endl;return 0;
}
a = 123; 的处理流程:
实际上a = 123;调用了一个重载的赋值运算符:
#include<iostream>
using namespace std;class A {
public :A() {cout << this << " : constructor" << endl;}A (int x) {cout << this << " : transform constructor" << endl;}A &operator=(const A &a) {cout << this << " : operator=" << endl;return *this;}~A() {cout << this << " : destructor" << endl;}
};int main() {A a;A b;//A c(3);A c = 3;a = 123; //将123赋值给对象acout << "end of main" << endl;return 0;
}
运行结果:
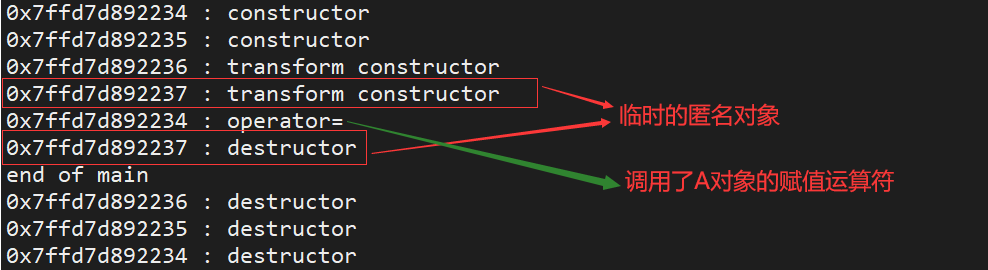
所以,a = 123的处理流程就是:
① 调用转换构造,将 123 转换为一个临时的匿名对象;
② 调用重载运算符=,将①中产生的临时匿名对象绑定到 operator= 方法参数 a 上;
③ 析构产生的临时匿名对象。
构造和析构的过程产生的就是中间的临时匿名对象。
拷贝构造
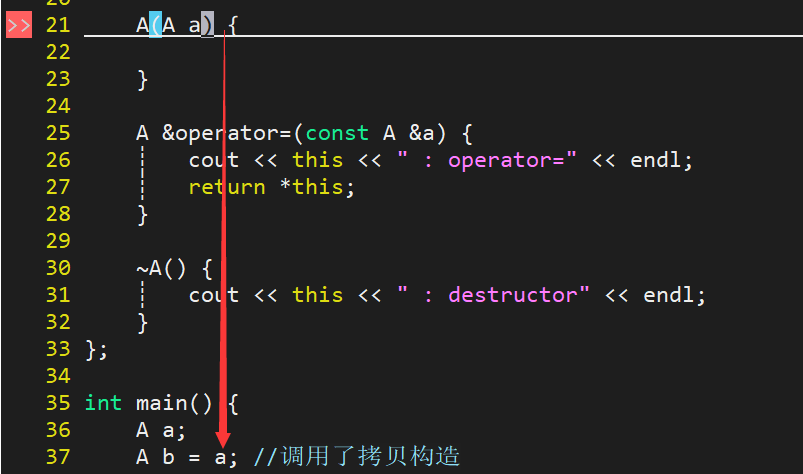
为什么拷贝构造函数A(A a){} 这样写出错?
A b = a;调用的是b对象的拷贝构造A(A a'),需要传参,就是将a拷贝给a'的过程,等价于A a' = a, 又会调用a'的拷贝构造,也涉及到传参的问题,所以就会无限递归下去了。
拷贝构造不能传值,因为一旦传的值的类型和参数的类型一样,会继续调用参数的拷贝构造,而调用参数的拷贝构造的时候,其类型又和参数的参数的类型一样,继续调用参数的参数的拷贝构造,无限递归下去。
左值引用
#include<iostream>
using namespace std;void add_one(int x) {x += 1;return ;
}int main() {int n = 3;cout << "n = " << n << endl;add_one(n);cout << "n = " << n << endl;return 0;
}
因为是值传递,所以 n = 3:

在C++中新增了一种引用形式:左值引用。
引用,相当于别名,如下的代码中,将 n 传给引用 x,就相当于 x 是 n 的一个别名,对 x 进行操作就是对 n 进行操作:
#include<iostream>
using namespace std;void add_one(int &x) {x += 1;return ;
}int main() {int n = 3;cout << "n = " << n << endl;add_one(n);cout << "n = " << n << endl;return 0;
}
运行结果:

引用类似于之前提到过的指针,但是引用相较于指针,会更加方便。
引用实际上就是给原来的变量贴了个标签,传引用是不产生任何拷贝行为的。
回到刚刚的拷贝构造,知道了拷贝构造是不能传值的,起码要传一个引用:
#include<iostream>
using namespace std;class A {
public :A() {cout << this << " : constructor" << endl;}A (int x) {cout << this << " : transform constructor" << endl;}A(const A &a) {cout << this << " : copy constructor" << endl;}A &operator=(const A &a) {cout << this << " : operator=" << endl;return *this;}~A() {cout << this << " : destructor" << endl;}
};int main() {A a;A b = a; //调用了拷贝构造A c = 3;a = 123;cout << "end of main" << endl;return 0;
}
运行结果:
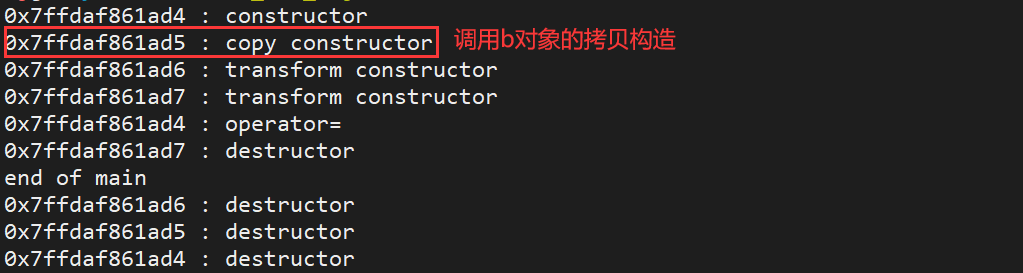
强调:
- 定义
b对象的过程中,无论是A b = a;还是A b(a);调用的都是拷贝构造。 - 在不是定义
b对象的过程中,即代码的其他位置写b = a,调用的是赋值运算符。
为什么拷贝构造一定要传const?
class A {A(A &a) {}
};int main() {const A a;A b = a; //会出现大bug,因为const对象不能绑定到非const的对象上return 0;
}
为了兼容对象的const和非const的情况,所以拷贝构造传入const。
构造函数的执行流程分析
class A {
public :A() {cout << this << " : constructor" << endl;}A (int x) {cout << this << " : transform constructor" << endl;}A(const A &a) {cout << this << " : copy constructor" << endl;}A &operator=(const A &a) {cout << this << " : operator=" << endl;return *this;}~A() {cout << this << " : destructor" << endl;}
};
如果声明一个对象 A a;,
- 逻辑上的完成构造(功能上的构造)是在第 5 行,有一些自定义的构造行为。
- 实际上的完成构造(编译器认为的构造)是在第 3 行,一旦进到构造函数的大括号内,则对象已经构造完成了,因为在里面是可以使用当前对象的。“对象能否使用” 即:是否可以使用当前对象的所有成员属性和成员方法。
一旦写了有参构造,编译器的默认构造就被删除了,如果想让构造的对象有默认的行为,就需要显式地写默认构造。
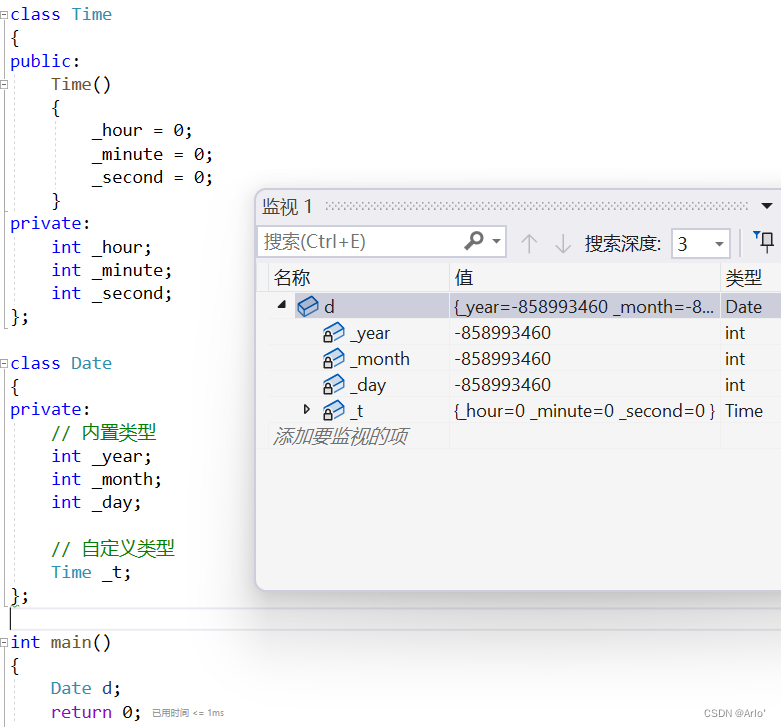
新增Data类,并且在类A中声明一个Data类型的成员属性
#include<iostream>
using namespace std;class Data {
public:Data(int x, int y) {this->x = x;this->y = y;}
private:int x, y;
};class A {
public :A() {cout << this << " : constructor" << endl;}A(int x) {cout << this << " : transform constructor" << endl;}A(const A &a) {cout << this << " : copy constructor" << endl;}A &operator=(const A &a) {cout << this << " : operator=" << endl;return *this;}~A() {cout << this << " : destructor" << endl;}Data d;
};int main() {A a;A b = a; //调用了拷贝构造A c = 3;a = 123;cout << "end of main" << endl;return 0;
}
编译会出现如下错误:

错误出现的原因:
结合上面讲解的实际上的构造完成,那么在 16 行之后,当前对象已经被构造了,则可以访问它的所有成员,即在17行的时候,是可以访问成员属性
d的,d就应该已经完成了构造。
那么d完成了构造,到底是调用了什么构造函数呢?
因为没有显式地调用任何构造函数,就会调用默认构造函数,但是成员属性d对应的类Data中没有默认构造,因为写了有参构造,它的默认构造就被编译器删除了,所以就产生了问题。
总结来说就是,成员属性d对应的类Data没有默认构造函数,A类的构造方法中要想访问对象的成员属性d行不通,无法到达第17行,因为无法完成构造行为。
这时候初始化列表就有用了。修改 A 类中的构造方法,增加初始化列表,使得显式调用 Data 类的有参构造:
class Data {
public:Data(int x, int y) : x(x), y(y) {}
private:int x, y;
};class A {
public :A() : d(3, 4) {cout << this << " : constructor" << endl;}A (int x) : d(x, x) {cout << this << " : transform constructor" << endl;}A(const A &a) : d(a.d) { //调用d对象的默认拷贝构造cout << this << " : copy constructor" << endl;}A &operator=(const A &a) {cout << this << " : operator=" << endl;return *this;}~A() {cout << this << " : destructor" << endl;}Data d;
};
一旦初始化列表中的内容执行完毕,实际上当前对象就构造完成,初始化列表是对当前对象的每个属性进行构造,对象的构造真正是发生在初始化列表。
编译器会自动生成默认构造和默认拷贝构造,一旦写了有参构造,编译器就会将默认构造删除,但是默认拷贝构造还是存在的。
初始化列表的构造顺序
成员属性的构造顺序和初始化列表无关,只和成员属性的声明顺序有关。
#include<iostream>
using namespace std;class Data {
public:Data(int x, int y) : x(x), y(y) {cout << "data : " << this << endl;}
private:int x, y;
};class A {
public :A() : d(3, 4), c(3, 4) {cout << this << " : constructor" << endl;cout << "c :" << &c << endl;cout << "d :" << &d << endl;}A(int x) : d(x, x), c(3, 4) {cout << this << " : transform constructor" << endl;}A(const A &a) : d(a.d), c(3, 4) { //调用d对象的默认拷贝构造cout << this << " : copy constructor" << endl;}A &operator=(const A &a) {cout << this << " : operator=" << endl;return *this;}~A() {cout << this << " : destructor" << endl;}Data c, d;
};int main() {A a;A b = a; //调用了拷贝构造A c = 3;a = 123;cout << "end of main" << endl;return 0;
}
运行结果:

default 和 delete关键字
用来显式说明什么样的构造函数使用功能编译器提供的默认行为,什么样的构造函数是需要删除的。
#include<iostream>
using namespace std;class A {
public://默认构造函数被删除A() = delete;//当前构造函数要使用编译器默认自带的规则,等价于编译器提供的默认拷贝构造A(const A &) = default;
};int main() {return 0;
}
设计一个类,该类的对象不能被拷贝
方法一:删除拷贝构造:不行,依然可以通过赋值运算符进行拷贝
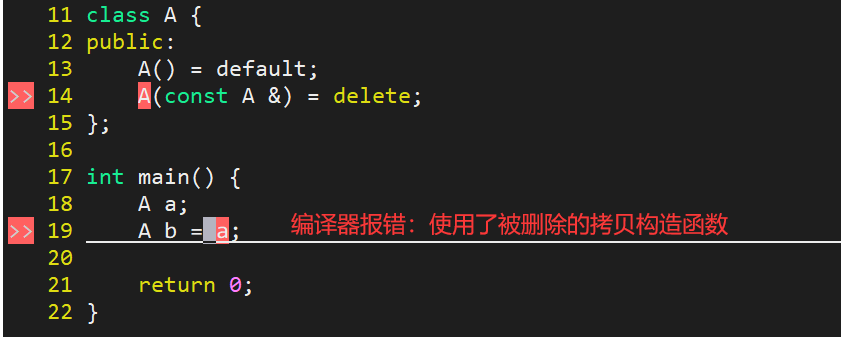
但是依然不能避免对象被拷贝,可以通过赋值运算符完成对象的拷贝:
#include<iostream>
using namespace std;class A {
public:A() = default;A(const A &) = delete;
};int main() {A a;A b;a = b;return 0;
}
所以,为了完成这个功能需求——对象不能被拷贝,通常是将拷贝构造方法和赋值运算符都放到 private 访问权限内。
方法二:拷贝构造和赋值运算符都放到 private 访问权限内
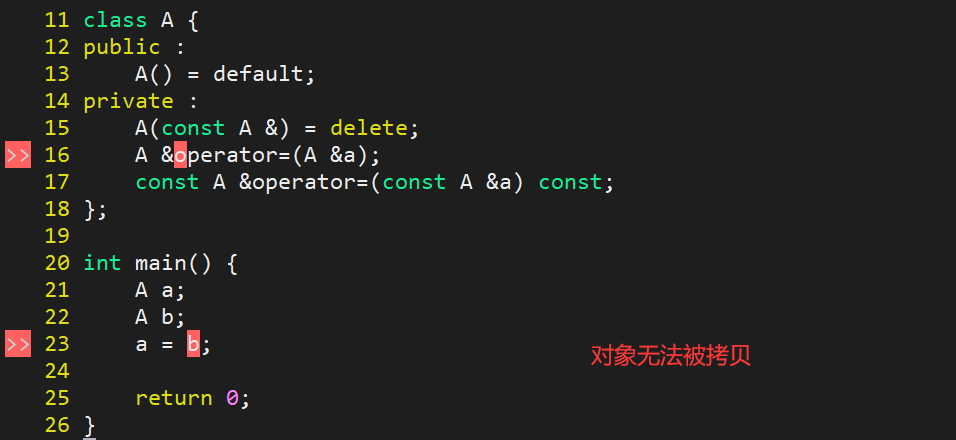
为什么赋值运算符的返回值是类引用
#include<iostream>
using namespace std;class A {
public :A() = default;A &operator=(int x) {this->x = x;return *this;}int x;
private :A(const A &) = delete;A &operator=(A &a);const A &operator=(const A &a) const;
};int main() {A a;(a = 123) = 456;cout << a.x << endl; //输出456return 0;
}
其中代码:
(a = 123) = 456;
的意思是:456 可以赋值给前面括号内部的返回值,而括号内的返回值是一个 A 类型的引用对象,因为返回的是 A 类的引用,所以括号内的表达式实际上返回的还是对象 a,也就是说将 456 赋值给对象 a。
malloc和new
malloc只能申请存储区不能对对象进行初始化,即不会调用构造函数;new既能申请存储区又能对对象进行初始化,即会调用构造函数。
#include<iostream>
using namespace std;class A {
public:A() {cout << "default constructor" << endl;}
};int main() {int n = 10;cout << "malloc int" << endl;int *data1 = (int *)malloc(sizeof(int) * n);cout << "new int" << endl;int *data2 = new int[n];cout << "malloc A" << endl;A *Adata1 = (A *)malloc(sizeof(A) * n); //这n个A对象没有被初始化,因为没有调用构造函数cout << "new A" << endl;A *Adata2 = new A[n];return 0;
}
运行结果:

- 空间的释放:
malloc对应free,new对应delete
#include<iostream>
using namespace std;class A {
public:A() {cout << "default constructor" << endl;}~A() {cout << "deconstructor" << endl;}
};int main() {int n = 10;cout << "malloc int" << endl;int *data1 = (int *)malloc(sizeof(int) * n);cout << "free int" << endl;free(data1);cout << "new int" << endl;int *data2 = new int[n];cout << "delete int" << endl;delete[] data2;cout << "malloc A" << endl;A *Adata1 = (A *)malloc(sizeof(A) * n); //这n个A对象没有被初始化,因为没有调用构造函数cout << "free A" << endl;free(Adata1);cout << "new A" << endl;A *Adata2 = new A[n];cout << "delete A" << endl;delete[] Adata2;A *Adata3 = new A(); //new了一个单一的对象delete Adata3; //delete不用添加方括号return 0;
}
运行结果:
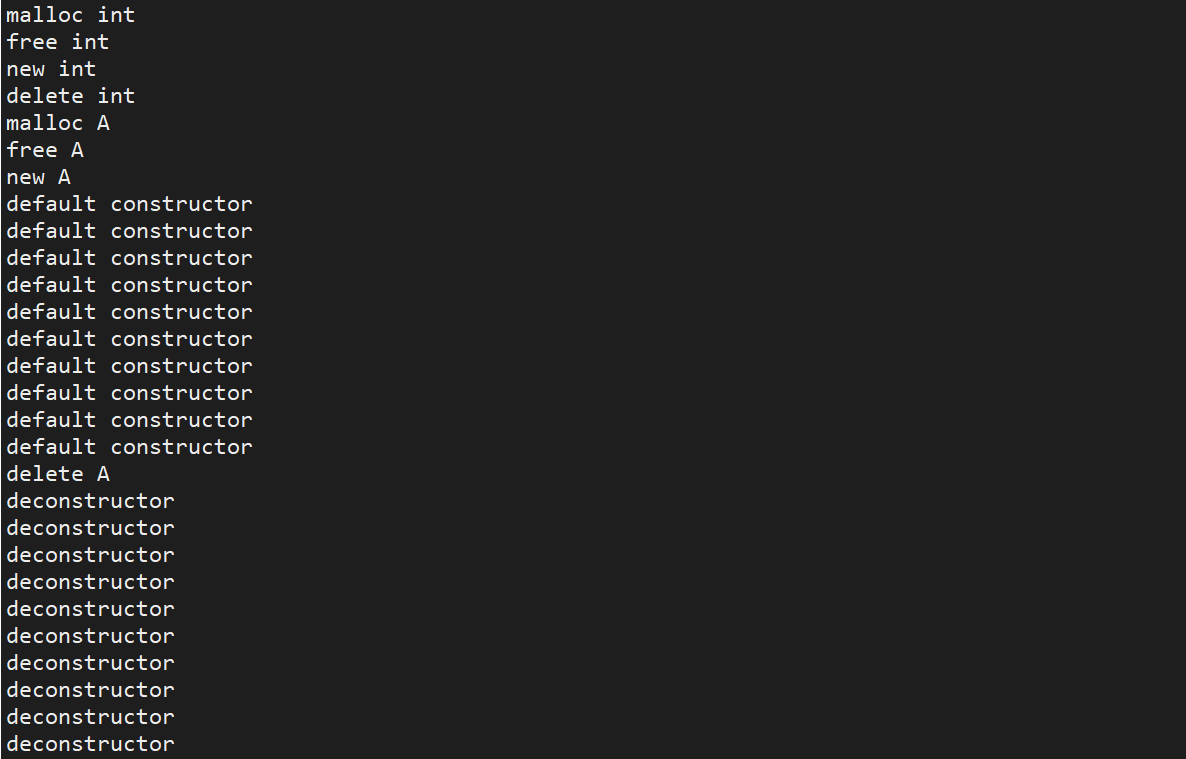
delete和free之间的差别:new调用构造函数,如果想回收申请的存储区的时候,还得回收存储区内部的每个对象,就得调用每个对象的析构函数,这就是delete,可以自动地调用每个对象的析构函数。但是free就不行了。- 关于
delete和delete[]:如果new的是一个数组,那么释放的时候就需要使用delete[],表示delete的是一段连续的存储空间;如果new的是一个单一的对象,new的时候就不需要加[]。
原地构造
原地构造的语法:
new(对象地址)类构造函数
原地构造可以结合 malloc 一起使用。
A *Adata1 = (A *)malloc(sizeof(A) * n);
for (int i = 0; i < n; i++) {new(Adata1 + i) A(); //原地构造,A()表示调用默认构造,这个位置表示的是调用哪个类的哪个构造函数
}
这个过程就是说先用 malloc 开辟一块连续的存储区,这片存储区没有被初始化,用原地构造依次地对每个位置进行初始化,完成构造行为。
原地构造在实现深拷贝的时候使用较多。
3. 析构函数
局部对象的析构函数在函数执行结束后执行
#include<iostream>
using namespace std;class A {
public :~A() {cout << "destructor" << endl;}
};int main() {A a; //调用了默认构造函数cout << "end of main" << endl;return 0;
}
运行结果:在 main 函数执行结束后,才会执行析构函数

析构函数的调用顺序
#include<iostream>
using namespace std;class A {
public :~A() {cout << this << " : destructor" << endl;}
};int main() {A a; //调用了默认构造函数A b;cout << "&a = " << &a << endl;cout << "&b = " << &b << endl;cout << "end of main" << endl;return 0;
}
运行结果:

为什么对象的构造顺序和析构顺序是相反的?
这是正常的语言特性。
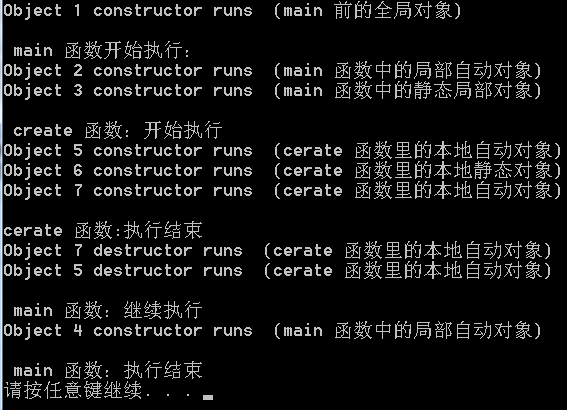
析构顺序和声明的对象是否在栈上是没有关系的,即便将两个对象声明为全局的,析构顺序依然是反的。
从语言设计来说,b对象有可能依赖于a对象的信息进行构造,所以在析构的时候,b对象也有可能依赖于a对象的信息才能完成正确的析构,所以在析构b对象之前不能先析构a对象。这就解释了构造顺序和析构顺序永远是反的。