当下无监督作为一种热门的机器学习技术,网上有不少关于无监督与有监督差异讨论的文章。DataVisor作为率先将无监督技术运用在反欺诈行业的娇娇领先者,我们在本文中,将深入浅出的讲解无监督机器学习技术与有监督技术在不同方面的区别,通过对比这两种技术,让大家对无监督反欺诈技术有更好的了解。
对比一 : 有标签 vs 无标签
有监督机器学习又被称为“有老师的学习”,所谓的老师就是标签。有监督的过程为先通过已知的训练样本(如已知输入和对应的输出)来训练,从而得到一个最优模型,再将这个模型应用在新的数据上,映射为输出结果。再经过这样的过程后,模型就有了预知能力。
而无监督机器学习被称为“没有老师的学习”,无监督相比于有监督,没有训练的过程,而是直接拿数据进行建模分析,意味着这些都是要通过机器学习自行学习探索。这听起来似乎有点不可思议,但是在我们自身认识世界的过程中也会用到无监督学习。比如我们去参观一个画展,我们对艺术一无所知,但是欣赏完多幅作品之后,我们也能把它们分成不同的派别。比如哪些更朦胧一点,哪些更写实一些。即使我们不知道什么叫做朦胧派和写实派,但是至少我们能把他们分为两个类。
对比二 : 分类 vs 聚类
有监督机器学习的核心是分类,无监督机器学习的核心是聚类(将数据集合分成由类似的对象组成的多个类)。有监督的工作是选择分类器和确定权值,无监督的工作是密度估计(寻找描述数据统计值),这意味着无监督算法只要知道如何计算相似度就可以开始工作。
对比三 : 同维 vs 降维
有监督的输入如果是n维,特征即被认定为n维,也即y=f(xi)或p(y|xi), i =n,通常不具有降维的能力。而无监督经常要参与深度学习,做特征提取,或者干脆采用层聚类或者项聚类,以减少数据特征的维度。
对比四 :分类同时定性 vs 先聚类后定性
有监督的输出结果,也就是分好类的结果会被直接贴上标签,是好还是坏。也即分类分好了,标签也同时贴好了。类似于中药铺的药匣,药剂师采购回来一批药材,需要做的只是把对应的每一颗药材放进贴着标签的药匣中。无监督的结果只是一群一群的聚类,就像被混在一起的多种中药,一个外行要处理这堆药材,能做的只有把看上去一样的药材挑出来聚成很多个小堆。如果要进一步识别这些小堆,就需要一个老中医(类比老师)的指导了。因此,无监督属于先聚类后定性,有点类似于批处理。
对比五 :独立 vs 非独立
李航在其著作《统计学习方法》(清华大学出版社)中阐述了一个观点:对于不同的场景,正负样本的分布可能会存在偏移(可能是大的偏移,也可能偏移比较小)。好比我们手动对数据做标注作为训练样本,并把样本画在特征空间中,发现线性非常好,然而在分类面,总有一些混淆的数据样本。对这种现象的一个解释是,不管训练样本(有监督),还是待分类的数据(无监督),并不是所有数据都是相互独立分布的。或者说,数据和数据的分布之间存在联系。作为训练样本,大的偏移很可能会给分类器带来很大的噪声,而对于无监督,情况就会好很多。可见,独立分布数据更适合有监督,非独立数据更适合无监督。
对比六 : 不透明 vs 可解释性
由于有监督算法最后输出的一个结果,或者说标签。yes or no,一定是会有一个倾向。但是,如果你想探究为什么这样,有监督会告诉你:因为我们给每个字段乘以了一个参数列[w1, w2, w3…wn]。你继续追问:为什么是这个参数列?为什么第一个字段乘以了0.01而不是0.02?有监督会告诉你:这是我自己学习计算的!然后,就拒绝再回答你的任何问题。是的,有监督算法的分类原因是不具有可解释性的,或者说,是不透明的,因为这些规则都是通过人为建模得出,及其并不能自行产生规则。所以,对于像反洗钱这种需要明确规则的场景,就很难应用。而无监督的聚类方式通常是有很好的解释性的,你问无监督,为什么把他们分成一类?无监督会告诉你,他们有多少特征有多少的一致性,所以才被聚成一组。你恍然大悟,原来如此!于是,进一步可以讲这个特征组总结成规则。如此这般分析,聚类原因便昭然若揭了。
对比七 :DataVisor无监督独有的拓展性
试想这样一个n维模型,产出结果已经非常好,这时又增加了一维数据,变成了n+1维。那么,如果这是一个非常强的特征,足以将原来的分类或者聚类打散,一切可能需要从头再来,尤其是有监督,权重值几乎会全部改变。而DataVisor开发的无监督算法,具有极强的扩展性,无论多加的这一维数据的权重有多高,都不影响原来的结果输出,原来的成果仍然可以保留,只需要对多增加的这一维数据做一次处理即可。
如何选择有监督和无监督
了解以上对比后,我们在做数据分析时,就可以高效地做选择了。
首先,我们查看现有的数据情况。假如在标签和训练数据都没有的情况下,毫无疑问无监督是最佳选项。但其实对数据了解得越充分,模型的建立就会越准确,学习需要的时间就会越短。我们主要应该了解数据的以下特性: 特征值是离散型变量还是连续型变量;特征值中是否存在缺失的值;何种原因造成缺失值;数据中是否存在异常值;某个特征发生的频率如何。
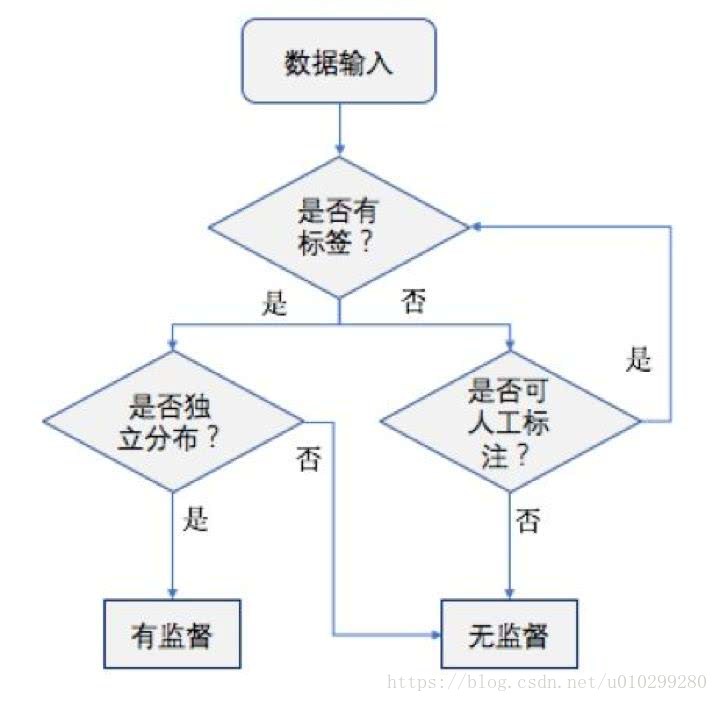
其次,数据条件是否可改善?在实际应用中,有些时候即使我们没有现成的训练样本,我们也能够凭借自己的双眼,从待分类的数据中人工标注一些样本,这样就可以把条件改善,从而用于有监督学习。当然不得不说,有些数据的表达会非常隐蔽,也就是我们手头的信息不是抽象的形式,而是具体的一大堆数字,这样我们很难人工对它们进行分类。举个例子,在bag - of - words 模型中,我们采用k-means算法进行聚类,从而对数据投影。在这种情况下,我们之所以采用k-means,就是因为我们只有一大堆数据,而且是很高维的,若想通过人工把他们分成50类是十分困难的。想象一下,一个熊孩子把50个1000块的拼图混在了一起,你还能够再把这50000个凌乱的小方块区分开吗?所以说遇到这种情况也只能选用无监督学习了。
最后,看样本是否独立分布。对于有训练样本的情况,看起来采用有监督总是比采用无监督好。但有监督学习就像是探索悬崖时的一个安全绳,有着一定的指导作用。就像是即使班级里的第一名,也非常需要标准答案来获得肯定,对吧?做完题对一下答案,总觉得会更安心一点。但对于非独立分布的数据,由于其数据可能存在内在的未知联系,因而存在某些偏移量,这个时候假如追求单一的“标准答案”反而会错失其数据背后隐藏关联。就像是做数学题,往往还有标准答案以外的其他解法。而在反欺诈的场景中,这些隐藏关联往往包含着一个未知地欺诈团伙活动。所以在反欺诈领域中无监督机器学习能实现更准确和广泛的欺诈检测。