在线上项目中,需要统计产品中用户行为和使用情况,从而可以从用户和产品的角度去了解用户群体,从而升级和迭代产品,使其更加贴近用户。用户行为数据可以通过前端数据监控的方式获得,除此之外,前端还需要实现性能监控和异常监控。性能监控包括首屏加载时间、白屏时间、http请求时间和http响应时间。异常监控包括前端脚本执行报错等。
实现前端监控有三个步骤:前端埋点和上报、数据处理和数据分析。本文针对整个前端监控,设计适用的方案。本文的主要内容分为:
- 为什么需要前端监控
- 常用前端埋点方案总结
- 前端埋点方案选型和前端上报方案设计
- 前端监控结果可视化展示系统的设计
一、为什么需要前端监控
前端监控的目的是:
获取用户行为以及跟踪产品在用户端的使用情况,并以监控数据为基础,指明产品优化的方向。
前端监控可以分为三类:数据监控、性能监控和异常监控。下面我们来一一的了解。
(1)数据监控
数据监控,顾名思义就是监听用户的行为。常见的数据监控包括:
- PV/UV:PV(page view),即页面浏览量或点击量。UV:指访问某个站点或点击某条新闻的不同IP地址的人数
- 用户在每一个页面的停留时间
- 用户通过什么入口来访问该网页
- 用户在相应的页面中触发的行为
统计这些数据是有意义的,比如我们知道了用户来源的渠道,可以促进产品的推广,知道用户在每一个页面停留的时间,可以针对停留较长的页面,增加广告推送等等。
(2)性能监控
性能监控指的是监听前端的性能,主要包括监听网页或者说产品在用户端的体验。常见的性能监控数据包括:
- 不同用户,不同机型和不同系统下的首屏加载时间
- 白屏时间
- http等请求的响应时间
- 静态资源整体下载时间
- 页面渲染时间
- 页面交互动画完成时间
这些性能监控的结果,可以展示前端性能的好坏,根据性能监测的结果可以进一步的去优化前端性能,比如兼容低版本浏览器的动画效果,加快首屏加载等等。
(3)异常监控
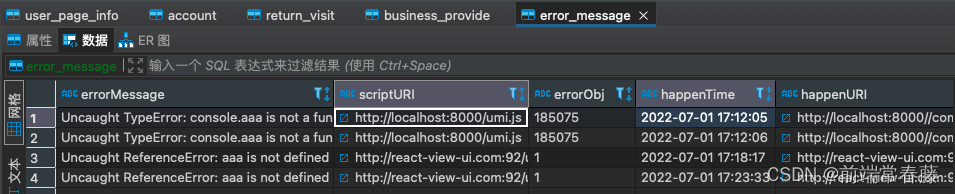
此外,产品的前端代码在执行过程中也会发生异常,因此需要引入异常监控。及时的上报异常情况,可以避免线上故障的发上。虽然大部分异常可以通过try catch的方式捕获,但是比如内存泄漏以及其他偶现的异常难以捕获。常见的需要监控的异常包括:
- Javascript的异常监控
- 样式丢失的异常监控
二、常用前端埋点方案总结
在上一节中介绍了前端监控的作用,那么如何实现前端监控呢,实现前端监控的步骤为:前端埋点和上报、数据处理和数据分析。首要的步骤就是前端埋点和上报,也就是数据的收集阶段。数据收集的丰富性和准确性会影响对产品线上效果的判别结果。
目前常见的前端埋点方法分为三种:代码埋点、可视化埋点和无痕埋点。下面一一介绍每一种埋点的方法。
(1) 代码埋点
代码埋点,就是以嵌入代码的形式进行埋点,比如需要监控用户的点击事件,会选择在用户点击时,插入一段代码,保存这个监听行为或者直接将监听行为以某一种数据格式直接传递给server端。此外比如需要统计产品的PV和UV的时候,需要在网页的初始化时,发送用户的访问信息等。
优点:
可以在任意时刻,精确的发送或保存所需要的数据信息。
缺点:
工作量较大,每一个组件的埋点都需要添加相应的代码
(2)可视化埋点
通过可视化交互的手段,代替代码埋点。将业务代码和埋点代码分离,提供一个可视化交互的页面,输入为业务代码,通过这个可视化系统,可以在业务代码中自定义的增加埋点事件等等,最后输出的代码耦合了业务代码和埋点代码。
可视化埋点听起来比较高大上,实际上跟代码埋点还是区别不大。也就是用一个系统来实现手动插入代码埋点的过程。
缺点:
可视化埋点可以埋点的控件有限,不能手动定制。
(3)无埋点
无埋点并不是说不需要埋点,而是全部埋点,前端的任意一个事件都被绑定一个标识,所有的事件都别记录下来。通过定期上传记录文件,配合文件解析,解析出来我们想要的数据,并生成可视化报告供专业人员分析因此实现“无埋点”统计。
从语言层面实现无埋点也很简单,比如从页面的js代码中,找出dom上被绑定的事件,然后进行全埋点。
优点:
由于采集的是全量数据,所以产品迭代过程中是不需要关注埋点逻辑的,也不会出现漏埋、误埋等现象
缺点:
无埋点采集全量数据,给数据传输和服务器增加压力
无法灵活的定制各个事件所需要上传的数据
三、前端埋点方案选型和前端上报方案设计
第一章中介绍了前端所需要监听的信息,在第二章中介绍了前端埋点的常见方式,本文来根据需求,来定制我们的埋点和上报方案。
(1)监控数据
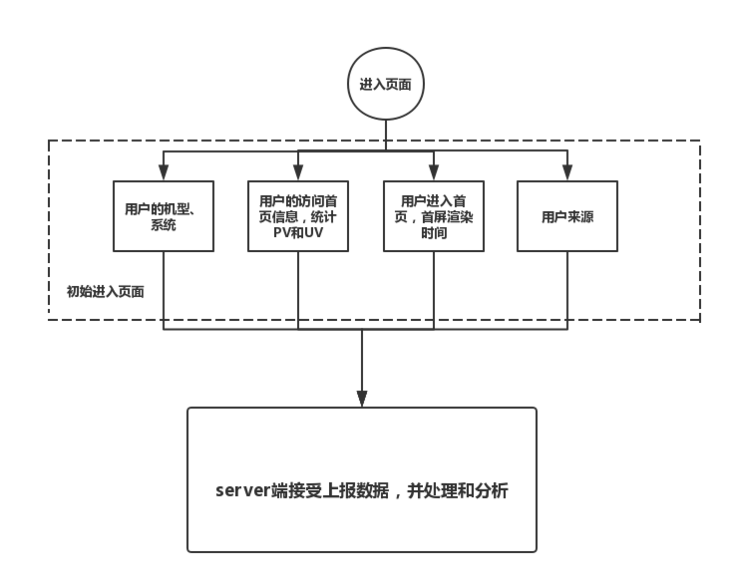
首先我们需要明确一个产品或者网页,普遍需要监控和上报的数据。监控的分为三个阶段:用户进入网页首页、用户在网页内部交互和交互中报错。每一个阶段需要监控和上报的数据如下图所示:
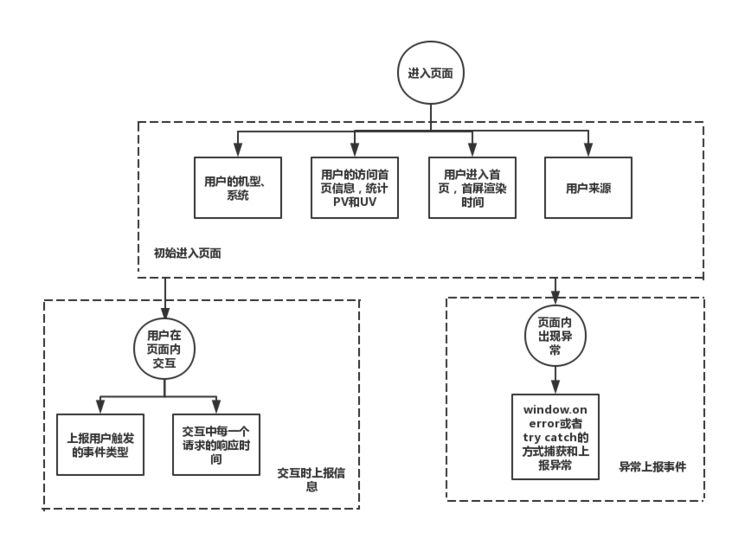
(2)埋点方案
在实际项目中考虑到上报数据的灵活定制,以及减少数据传输和服务器的压力,在所需埋点处不多的情况下,常用的方式是代码埋点。
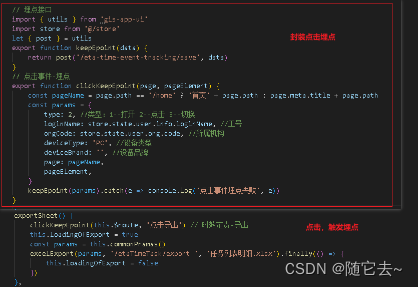
以用户进入首页为例,我们在首页渲染完成后会发送事件类型和类型相关的数据给server端,告知首页的监控信息。
(3)上报周期和上报数据类型
如果埋点的事件不是很多,上报可以时时进行,比如监控用户的交互事件,可以在用户触发事件后,立刻上报用户所触发的事件类型。如果埋点的事件较多,或者说网页内部交互频繁,可以通过本地存储的方式先缓存上报信息,然后定期上报。
接着来确定需要埋点上报的数据,上报的信息包括用户个人信息以及用户行为,主要数据可以分为:
- who: appid(系统或者应用的id),userAgent(用户的系统、网络等信息)
- when: timestamp(上报的时间戳)
- from where:
currentUrl(用户当前url),fromUrl(从哪一个页面跳转到当前页面),type(上报的事件类型),element(触发上报事件的元素) - what: 上报的自定义扩展数据data:{},扩展数据中可以按需求定制,比如包含uid等信息
上报数据的对象为:
{ ----------------上报接口本身提供--------------------currentUrl, fromUrl,timestamp,userAgent:{os,netWord,}----------------业务代码配置和自定义上报数据------------type,appid,element,data:{uid,uname}
}
(4)埋点和上报举例
我们以上报首屏加载事件为例,DOM提供了document的DOMContentLoaded事件来监听dom挂载,提供了window的load事件来监听页面所有资源加载渲染完毕。
<script type="text/javascript">var start=Date.now();document.addEventListener('DOMContentLoaded', function() {fetch('some api',{type:'dom complete',data:{domCompletedTime:Date.now()-start}})});window.addEventListener('load', function() {fetch('some api',{type:'load complete',data:{LoadCompletedTime:Date.now()-start}})});
</script>
(5)前端埋点系统的前后端通信加密
在上报数据的前后端通信中,需要和server端协商加密机制,利用 OpenSSL库来实现的加密,OpenSSL已经是一个广泛被采用的加密算法。前端可以采用node的crypto模块。
首先来看hash算法,crypto.createHash() 来创建一个Hash实例,可利用的hash算法如下:
- md5
- sha1
- sha256
- sha512
- ripemd160
以sha256算法加密为例:
const str="123445";//需要加密的字段
const hash=crypto.createHash('sha256');//指定加密算法
hash.update(str); //通过算法加密相应的字段
const result=hash.digest('hex');//转化成十六进制
四、前端监控结果可视化展示系统的设计
当后端得到前端上报的信息之后,经过数据分析和处理,需要前端可视化的展示数据分析后的结果。
可以在开源中后台系统ant-design-pro的基础上进行二次开发,首先要明确展示信息。展示的信息包括单个用户和整体应用。
对于单个用户来说需要展示的监控信息为:
- 单个用户,在交互过程中触发各个埋点事件的次数
- 单个用户,在某个时间周期内,访问本网页的入口来源
- 单个用户,在每一个子页面的停留时间
对于全体用户需要展示的信息为:
- 某一个时间段内网页的PV和UV
- 全体用户访问网页的设备和操作系统分析
- 某一个时间段内访问本网页的入口来源分析
- 全体用户在访问本网页时,在交互过程中触发各个埋点事件的总次数
- 全体用户在访问本网页时,网页上报异常的集合
删选功能集合:
- 时间筛选:提供今日(00点到当前时间)、本周、本月和全年
- 用户删选:提供根据用户id删选出用户行为的统计信息
- 设备删选:删选不同系统的整体展示信息