TLD之检测篇(二)
扫描方式前面已经说过,具体参数【5.3】:scales step =1.2, horizontal step =10 percent of width, vertical step =10 percent of height, minimal bounding box size = 20 pixels. This setting produces around 50k bounding boxes for a QVGA image (240×320), the exact number depends on the aspect ratio of the initial bounding box.
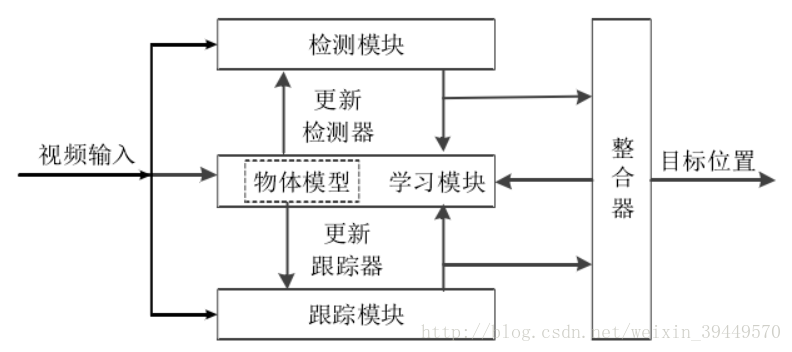
TLD分类器的三道关卡

如上图所示,TLD的检测算法共有三关:
第一关:方差
使用简单的阈值判断,阈值设定为初始选择目标方差的50%(存储在TLD::var),见【5.3.1】50 percent of variance of the patch that was selected for tracking。
第二关:随机森林分类器

TLD特征
首先介绍一下TLD所使用的特征,2bit BP,很简单,就是任意两个点的大小关系,取值只有0和1。结合后面的分类器,我更倾向于将特征定义为0/1组成的串/向量。具体来 说,首先随机产生13对坐标,然后比较对应坐标像素值的大小,得到13个0/1,最后依次组成13位二进制数,也就可以看出一个整数。为了去噪,预先对图像进行了高斯滤波。不过图TLD特征中,只有10位。
TLD所使用的随机森林相当简单,一共有10棵树,每一棵树的分类特征就是上述的13位二进制串,与CART,ID3等决策树不同,它没有特征选择,它只是对特征分布进行了直方图统计,所以,每一个树可以看成一个贝叶斯分类器,而且直方图的区间数多到2^13。每一棵树分类的方法特么简单,正样本的概率为特征对应的区间正负样本数之比。最后对所有树的分类结果求和即为随机森林的最终分类结果,即正样本的概率。原文【5.3.2】说结果的平均值超过0.5就当做正样本,不过,实际代码中是超过0.6才算正样本,而结果超过0.5的负样本才作为随机森林重新训练的负样本,即hard negative。
下面直接看源码实现
FerNNClassifier::prepare实现确定特征的比对位置,它在TLD::init函数中被调用,主要是这几个变量features[s][i]、thrN、 posteriors、pCounter、nCounter,命名非常直白,含义就不多说了。
void FerNNClassifier::prepare(const vector<Size>& scales){acum = 0;// 1. Initialize test locations for features// 随机产生需要坐标对(x1f,y1f,x2f,y2f,注意范围[0,1)),// 即确定由每一个特征是由哪些点对进行而得到,这些位置一旦确定就不会改变,// 由于我们要进行多尺度检测,所以同一个点在不同尺度scales,实际对应的坐标要乘以对应尺度的width和height。int totalFeatures = nstructs*structSize;//nstructs 10 structSize 13features = vector<vector<Feature> >(scales.size(),vector<Feature> (totalFeatures));RNG& rng = theRNG();float x1f,x2f,y1f,y2f;int x1, x2, y1, y2;for (int i=0;i<totalFeatures;i++){x1f = (float)rng; //产生[0,1)直接的浮点数y1f = (float)rng;x2f = (float)rng;y2f = (float)rng;for (int s=0;s<scales.size();s++){x1 = x1f * scales[s].width;y1 = y1f * scales[s].height;x2 = x2f * scales[s].width;y2 = y2f * scales[s].height;features[s][i] = Feature(x1, y1, x2, y2);}}// 2. Thresholds,负样本的阈值thrN = 0.5*nstructs;// 3. Initialize Posteriors,为统计直方图分配空间for (int i = 0; i<nstructs; i++) {posteriors.push_back(vector<float>(pow(2.0,structSize), 0));pCounter.push_back(vector<int>(pow(2.0,structSize), 0));nCounter.push_back(vector<int>(pow(2.0,structSize), 0));}
}确定了由哪些点对得到特征后,就可以获取给定图像块(patch)的特征了,scale_idx是图像块的尺度索引,fern[t]就是所提取的第t个特征,前面说过,特征是一个13位二进制数,也就是一个整数。
void FerNNClassifier::getFeatures(const cv::Mat&image,constint& scale_idx, vector<int>& fern){int leaf;for (int t=0;t<nstructs;t++){leaf=0;for (int f=0; f<structSize; f++){//依次得到每一位leaf = (leaf << 1) + features[scale_idx][t*nstructs+f](image);}fern[t]=leaf;}
}能够提取特征了,那么接下来就可以训练随机森林分类器,这部分稍微分的有点细,首先介绍训练函数FerNNClassifier::trainF(ferns,resample),ferns是训练集,即正/负样本的特征,不过呢,类别标号ferns[i].second==1即为正样本,resample是bootstrap的次数,其实函数实现时只有一轮,bootstrap是用容易分错的正样本和负样本更新分类器,measure_forest就是该分类器的分类函数,update是更新函数。
void FerNNClassifier::trainF(const vector<std::pair<vector<int>,int> >&ferns,intresample){thrP = thr_fern*nstructs; //0.6*10 for (int i = 0; i <ferns.size(); i++){ if(ferns[i].second==1){//正样本 if(measure_forest(ferns[i].first)<=thrP) update(ferns[i].first,1,1); }else{//负样本 if (measure_forest(ferns[i].first) >= thrN) update(ferns[i].first,0,1); }}
}FerNNClassifier::measure_forest就是前面提到的,将10棵树的概率求和
float FerNNClassifier::measure_forest(vector<int>fern) {float votes = 0;for (int i = 0; i < nstructs; i++) {votes += posteriors[i][fern[i]];}return votes;
}update更新正负样本的直方图分布,注意:posteriors只算了正样本的概率
void FerNNClassifier::update(const vector<int>& fern,intC, int N) {int idx;for (int i = 0; i < nstructs; i++) {//10idx = fern[i];//13位的特征//C=1,正样本,C=0,负样本(C==1) ? pCounter[i][idx] +=N : nCounter[i][idx] +=N;if (pCounter[i][idx]==0) {//既然是正概率,如果正样本的数目为0,正样本的概率自然也为0posteriors[i][idx] = 0;} else {posteriors[i][idx] = ((float)(pCounter[i][idx]))/(pCounter[i][idx] + nCounter[i][idx]);}}
}第三关:最近邻分类器
最近邻分类器顾名思义咯,与随机森林一样,其中也涉及到特征、训练函数、分类函数。
特征其实就是将图像块大小归一化(都变成patch_size×patch_size),零均值化【5.1】
void TLD::getPattern(const Mat& img, Mat& pattern,Scalar&mean,Scalar&stdev){resize(img,pattern,Size(patch_size,patch_size));meanStdDev(pattern,mean,stdev);pattern.convertTo(pattern,CV_32F);pattern = pattern-mean.val[0];
}训练函数trainNN,我觉得最近邻分类器其实没有所谓的训练,因为只需要将容易分错的正/负样本加入正负样本集就可以了。其中,pEx是正样本集,nEx是负样本集。
void FerNNClassifier::trainNN(const vector<cv::Mat>& nn_examples){float conf,dummy;vector<int> y(nn_examples.size(),0);y[0]=1;//只有第一个是正样本,并不是原始的目标区域,而是best_boxvector<int> isin;for (int i=0;i<nn_examples.size();i++){// For each exampleNNConf(nn_examples[i],isin,conf,dummy);// Measure Relative similarityif (y[i]==1 && conf<=thr_nn){if (isin[1]<0){ //注意:如果pEx为空,NNConf直接返回 thr_nn=0,isin都为-1, pEx = vector<Mat>(1,nn_examples[i]); continue; } pEx.push_back(nn_examples[i]);//之前存在正样本,追加} if(y[i]==0 && conf>0.5) nEx.push_back(nn_examples[i]); } acum++;printf("%d. Trained NN examples: %d positive %d negative\n",acum,(int)pEx.size(),(int)nEx.size());
}分类函数NNConf,计算的就是待分类样本example和NN分类器中所有正负样本的距离,距离是酱紫计算的(见OpenCV refermanual):

好吧,这个我也是第一次见,不过这个和相关系数特别像:


区别是没有减去均值,还记得我们前面提到图像块都进行了零均值化,因此距离就是计算相关系数……
不过,还要进行一些处理才方便作为距离测度, 相关系数的取值范围是[-1,1],加上1变成[0,2],再将范围缩小为[0,1]

相似性包含两种,Relative similarity和Conservative similarity,具体见【5.2】,不过这个版本采用了另一种计算方式,大家自己领会一下吧,我也说不上哪个好。
void FerNNClassifier::NNConf(const Mat& example, vector<int>& isin,float&rsconf,float&csconf){isin=vector<int>(3,-1);if (pEx.empty()){ //if isempty(tld.pex) % IF positive examples in the model are not defined THEN everything is negativersconf = 0; // conf1 = zeros(1,size(x,2));csconf=0;return;}if (nEx.empty()){ //if isempty(tld.nex) % IF negative examples in the model are not defined THEN everything is positiversconf = 1; // conf1 = ones(1,size(x,2));csconf=1;return;}Mat ncc(1,1,CV_32F);float nccP,csmaxP,maxP=0;bool anyP=false;int maxPidx,validatedPart = ceil(pEx.size()*valid);//正样本的前 50%,用于计算Conservative similarit【5.2 5】float nccN, maxN=0;bool anyN=false;for (int i=0;i<pEx.size();i++){matchTemplate(pEx[i],example,ncc,CV_TM_CCORR_NORMED);// measure NCC to positive examples//相关系数的取值范围是[-1,1],加上1变成[0,2],再将范围缩小为[0,1]nccP=(((float*)ncc.data)[0]+1)*0.5;if (nccP>ncc_thesame)//0.95anyP=true;if(nccP > maxP){maxP=nccP;//Relative similaritymaxPidx = i;if(i<validatedPart)csmaxP=maxP;//Conservative similari}}for (int i=0;i<nEx.size();i++){matchTemplate(nEx[i],example,ncc,CV_TM_CCORR_NORMED);//measure NCC to negative examplesnccN=(((float*)ncc.data)[0]+1)*0.5;if (nccN>ncc_thesame)anyN=true;if(nccN > maxN)maxN=nccN;}//set isinif (anyP) isin[0]=1; //if he query patch is highly correlated with any positive patch in the model then it is considered to be one of themisin[1]=maxPidx; //get the index of the maximall correlated positive patchif (anyN) isin[2]=1; //if the query patch is highly correlated with any negative patch in the model then it is considered to be one of them//Measure Relative Similarityfloat dN=1-maxN;float dP=1-maxP;rsconf = (float)dN/(dN+dP); //与原文【5.2】有出入,不过也是可以理解的//Measure Conservative SimilaritydP = 1 - csmaxP;csconf =(float)dN / (dN + dP);
}TLD::detect函数
有了前面的铺垫,这段程序应该比较好懂了吧。
void TLD::detect(const cv::Mat&frame){//cleaningdbb.clear();dconf.clear();dt.bb.clear();//检测的结果,一个目标一个bounding boxdouble t = (double)getTickCount();Mat img(frame.rows,frame.cols,CV_8U);integral(frame,iisum,iisqsum);//GaussianBlur(frame,img,Size(9,9),1.5);//int numtrees = classifier.getNumStructs();// nstructs: 10float fern_th = classifier.getFernTh();//thr_fern:0.6vector <int> ferns(10);float conf;int a=0;Mat patch;// 1. 方差->结果存在tmp ->随机森林-> dt.bbfor (int i=0;i<grid.size();i++){//FIXME: BottleNeckif (getVar(grid[i],iisum,iisqsum)>=var){//第一关:方差a++;patch = img(grid[i]);classifier.getFeatures(patch,grid[i].sidx,ferns);//sidx:scale indexconf = classifier.measure_forest(ferns);//第二关:随机森林tmp.conf[i]=conf; //只要能通过第一关就会保存到tmptmp.patt[i]=ferns;if (conf>numtrees*fern_th){dt.bb.push_back(i); //第二关}}elsetmp.conf[i]=0.0;//第一关都没过}int detections = dt.bb.size();printf("%d Bounding boxes passed the variance filter\n",a);printf("%d Initial detection from Fern Classifier\n",detections);if (detections>100){//第二关附加赛:100名以后的回家去nth_element(dt.bb.begin(),dt.bb.begin()+100,dt.bb.end(),CComparator(tmp.conf));dt.bb.resize(100);detections=100;}if (detections==0){detected=false;return;//啥都没看到……}printf("Fern detector made %d detections ",detections);t=(double)getTickCount()-t;printf("in %gms\n", t*1000/getTickFrequency());// Initialize detection structuredt.patt = vector<vector<int> >(detections,vector<int>(10,0)); // Corresponding codes of the Ensemble Classifierdt.conf1 = vector<float>(detections); // Relative Similarity (for final nearest neighbour classifier)dt.conf2 =vector<float>(detections); // Conservative Similarity (for integration with tracker)dt.isin = vector<vector<int> >(detections,vector<int>(3,-1)); // Detected (isin=1) or rejected (isin=0) by nearest neighbour classifierdt.patch = vector<Mat>(detections,Mat(patch_size,patch_size,CV_32F));// Corresponding patches,patch_size: 15int idx;Scalar mean, stdev;float nn_th = classifier.getNNTh();//thr_nn:0.65//3. 第三关:最近邻分类器,用Relative Similarity分类,但是却用 Conservative Similarity作为分数->dconffor (int i=0;i<detections;i++){ // for every remaining detectionidx=dt.bb[i]; // Get the detected bounding box indexpatch = frame(grid[idx]);getPattern(patch,dt.patch[i],mean,stdev); // Get pattern within bounding boxclassifier.NNConf(dt.patch[i],dt.isin[i],dt.conf1[i],dt.conf2[i]); // Evaluate nearest neighbour classifierdt.patt[i]=tmp.patt[idx];//fernsif (dt.conf1[i]>nn_th){ // idx = dt.conf1 > tld.model.thr_nn; % get all indexes that made it through the nearest neighbourdbb.push_back(grid[idx]); // BB = dt.bb(:,idx); % bounding boxesdconf.push_back(dt.conf2[i]); // Conf = dt.conf2(:,idx); % conservative confidences}} // endif (dbb.size()>0){printf("Found %d NN matches\n",(int)dbb.size());detected=true;}else{printf("No NN matches found.\n");detected=false;}
}