-
简介
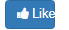
本文介绍三种高可用使用,及验证clickhouse的高可用性,三种方案分别如下:
不管是多分片还是多副本都是以集群方式部署,那么对外暴露多台Clickhouse服务,通常会通过LB方式使每台服务器能够均匀的接受到客户端的请求,另外一点就是在其中一台服务发生故障,仍然能通过故障转移方式正常对外提供服务。
- nginx代理
客户端连接clickhouse的时候通过nginx做负载均衡,因为本身clickhouse支持http协议,端口号为http端口,所以此种方案直接使用nginx的http代理即可。 - clickhouse驱动
Clickhouse-jdbc是使用负载均衡客户端ru.yandex.clickhouse.BalancedClickhouseDataSource来保证的,本质上是通过后台启动一个线程定时去探测clickhouse服务端,生成可用的地址列表。然后获取连接的时候从可用地址列表中随机选择一个节点来建立连接。 - 通过chproxy
chproxy即专为clickhouse使用的代理,功能更为强大。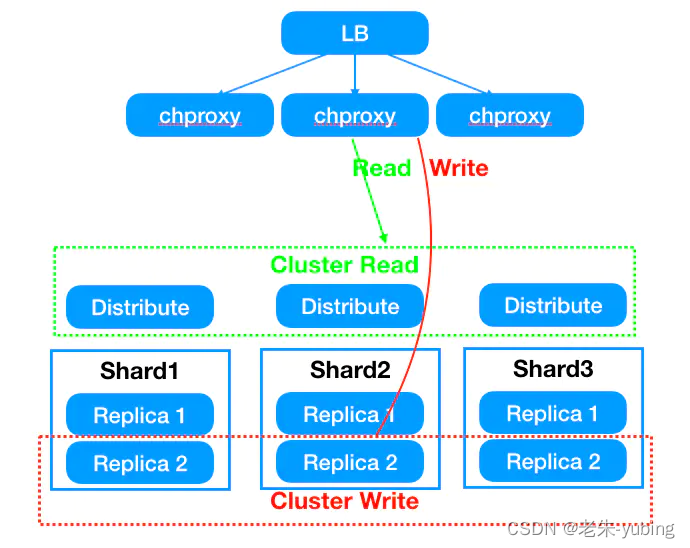
测试服务器地址
| ip | 服务 |
|---|---|
| 10.0.10.2:8123 | clickhouse(与10.0.10.3互为为主备) |
| 10.0.10.3:8123 | clickhouse (与10.0.10.2互为为主备) |
| 10.0.10.5:8123 | chproxy |
| 10.0.10.5:18123 | nginx |
测试点:
- 两台clickhouse服务运行正常,查询分布到2台机器
- 任意一台宕机,程序执行正常
- 当宕机机器恢复正常,数据能从恢复
前置条件
创建本地表
CREATE TABLE repl_abc on cluster cluster1
(
`id` String,
`price` Float64,
`create_time` DateTime
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/repl_abc','{replica}')
PARTITION BY toYYYYMM(create_time)
ORDER BY id;
创建分布式表
CREATE TABLE repl_abc_all on cluster cluster1
(
`id` String,
`price` Float64,
`create_time` DateTime
)
ENGINE = Distributed('cluster1','default','repl_abc', rand());
插入测试数据
insert into repl_abc_all values('01X001',123,'2021-05-01 09:09:00'),('02X002',123,'2021-06-01 09:09:00'),('03W001',321,'2021-05-01 09:09:00'),('04W002',321,'2021-06-01 09:09:00'),('05K001',123,'2021-05-01 09:09:00'),('06K002',123,'2021-06-01 09:09:00'),('07M001',321,'2021-05-01 09:09:00'),('08M002',321,'2021-06-01 09:09:00'),('09S001',123,'2021-05-01 09:09:00'),('10S002',123,'2021-06-01 09:09:00'),('11G001',321,'2021-05-01 09:09:00'),('12G002',321,'2021-06-01 09:09:00');
1.使用nginx代理
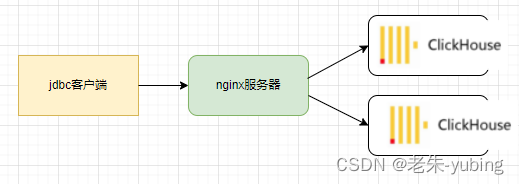
在nginx中增加配置
upstream clickhouse {
server 10.0.10.2:8123 max_fails=3 fail_timeout=10s;
server 10.0.10.3:8123 max_fails=3 fail_timeout=10s;
}
server {
listen 18123;
location / {
proxy_pass http://clickhouse;
}
}
使用systemctl stop clickhouse 模拟一台clickhouse 宕机,返回数据正常。
上述java测试代码 url 更改为
String url = "jdbc:clickhouse://10.0.10.5:8123/default";
在任意一台clickhouse模拟宕机,测试是否查询正常。
#systemctl stop clickhouse
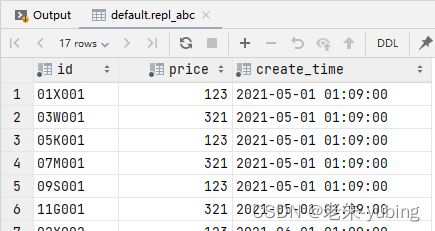
模拟数据写入和恢复
执行
insert into repl_abc_all values('001',123,now());
成功,并且可以查询到数据。
重新启动宕机的clickhouse,从宕机的clickhouse再次查询,刚才插入的数据。数据返回正常,说明数据恢复成功。
select * from repl_abc where id='001';
2. 使用官方的客户端做高可用
基本逻辑如下:
- 1.通过配置的url串,来切分构造url列表;
- 2.通过一个定时线程任务,来不断的去ping url列表,来更新可用的url列表;
- 3.在可用列表中随机返回一个可用url;
示例代码:
package com.example.clickhousedemo;import ru.yandex.clickhouse.BalancedClickhouseDataSource;
import ru.yandex.clickhouse.settings.ClickHouseProperties;import java.sql.*;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;public class Clickhouse_JDBC_test {public static void main(String[] args) throws Exception {exeSql("select count(1) from repl_abc_all");}public static void exeSql(String sql) throws SQLException {String url = "jdbc:clickhouse://10.0.10.2:8123,10.0.10.3:8123/default";ClickHouseProperties clickHouseProperties = new ClickHouseProperties();clickHouseProperties.setUser("default");clickHouseProperties.setPassword("");BalancedClickhouseDataSource balanced = new BalancedClickhouseDataSource(url, clickHouseProperties);//对每个host进行ping操作, 排除不可用的连接balanced.actualize();Connection connection = balanced.getConnection();Statement statement = null;ResultSet results = null;try {statement = connection.createStatement();long begin = System.currentTimeMillis();results = statement.executeQuery(sql);long end = System.currentTimeMillis();System.out.println("执行("+sql+")耗时:"+(end-begin)+"ms");ResultSetMetaData rsmd = results.getMetaData();List<Map> list = new ArrayList();while(results.next()){Map map = new HashMap();for(int i = 1;i<=rsmd.getColumnCount();i++){map.put(rsmd.getColumnName(i),results.getString(rsmd.getColumnName(i)));}list.add(map);}for(Map map : list){System.err.println(map);}} catch (Exception e) {e.printStackTrace();}finally {//关闭连接try {if(results!=null){results.close();}if(statement!=null){statement.close();}if(connection!=null){connection.close();}} catch (SQLException e) {e.printStackTrace();}}}
}
3. 使用chproxy做高可用
chproxy介绍 https://www.chproxy.org/cn
chproxy 安装
从https://github.com/ContentSquare/chproxy/releases 下载二进制包
下载地址: wget -c https://github.com/Vertamedia/chproxy/releases/download/v1.14.0/chproxy-linux-amd64-v1.14.0.tar.gz
编辑配置文件 /data/chproxy/config.yml
log_debug: false # debug日志
hack_me_please: true# cache设置,可设置长期缓存或者短期缓存,按组区分
caches: # 缓存设置
- name: "longterm"
dir: "/data/chproxy/longterm/cachedir"
max_size: 100Gb
expire: 1h
grace_time: 20s- name: "shortterm"
dir: "/data/chproxy/shortterm/cachedir"
max_size: 100Mb
expire: 10s# 网络白名单组,按组区分
network_groups: # 白名单组,可设置多个白名单组
- name: "cluster_internal"
networks: ["10.0.10.0/8"]- name: "office_addrs"
networks: ["172.17.0.0/16"]# 参数设置,按组区分
param_groups: # 参数组,可设置多个参数
- name: "cron-job"
params:
- key: "max_memory_usage"
value: "40000000000"- key: "max_bytes_before_external_group_by"
value: "20000000000"- name: "web"
params:
- key: "max_memory_usage"
value: "5000000000"- key: "max_columns_to_read"
value: "30"- key: "max_execution_time"
value: "30"# chproxy server相关设置,一般分为http、https、metrics
server:
http:
listen_addr: ":8123" # chproxy 服务监听端口
allowed_networks: ["office_addrs", "cluster_internal"] # 允许访问chproxy服务白名单
read_timeout: 5m
write_timeout: 10m
idle_timeout: 20mmetrics:
allowed_networks: ["office_addrs", "cluster_internal"] # 暴露给prometheus使用的白名单# 用户设置,按组区分
users:
- name: "default" # chproxy 用户名
password: "" # chproxy 密码
to_cluster: "cluster1" # 用户可访问的cluster名称
to_user: "default" # chproxy用户对应的ck用户
deny_http: false # 是否允许http请求
allow_cors: true
requests_per_minute: 20 # 限制该用户每分钟请求次数
# cache: "longterm" # 使用缓存,若使用缓存,查询优先走缓存,而不是按照规则轮询
params: "web" # 应用“web”指定的参数集
max_queue_size: 100 # 最大队列数
max_queue_time: 35s # 队列最大等待时间- name: "default1" # chproxy 用户
to_cluster: "cluster2" # 不同的chproxy用户,可对应不同的cluster集群
to_user: "default"
allowed_networks: ["office_addrs", "cluster_internal", "172.16.104.12"]
max_concurrent_queries: 4
max_execution_time: 1m
deny_https: false# 逻辑集群设置,按组区分
clusters:
- name: "cluster1" # chproxy 集合名称
scheme: "http" # 请求类型,http/https
nodes: ["node02.tusvn.nw:8123","node03.tusvn.nw:8123"] # 集群可访问节点,http使用端口默认为8123,https使用端口默认为8443,查看ck服务的config.xml配置文件查询
heartbeat: # 集群内部心跳检测定义
interval: 1m
timeout: 10s
request: "/?query=SELECT%201%2B1"
response: "2\n"kill_query_user: # 达到上限自动执行kill用户
name: "default"
password: ""users:
- name: "default" # 集群对应chproxy用户信息
password: ""
max_concurrent_queries: 512
max_execution_time: 1m- name: "cluster2" # chproxy 集群2名称,可从逻辑上定义多个集群
scheme: "http"
replicas: # 集群可访问节点
- name: "replica1"
nodes: ["10.0.10.2:8123"]
- name: "replica2"
nodes: ["10.0.10.3:8123"]users:
- name: "default"
max_concurrent_queries: 512
max_execution_time: 1m
chproxy安装好的地址 10.0.10.5:8123
程序目录 /data/chproxy
启动chproxy
#systemctl start chproxy
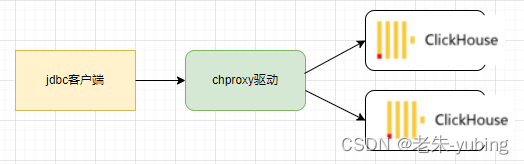
启动chproxy 通过客户端,执行数据库增删改查,验证正常。
关闭一台clickhouse,故障切换正常。
结论:
•BalancedClickhouseDataSource:使用简单;但是内部随机方式,可能会导致负载不均匀,虽然有定时检测机制,但是经测试,节点挂掉,请求直接报错;
•Nginx: 支持多种请求策略、自动故障转移,扩容新增节点只需要修改其配置即可
chproxy 拥有更多更灵活的配置权限,完善的健康检查,更好的性能。
推荐使用chproxy实现高可用。