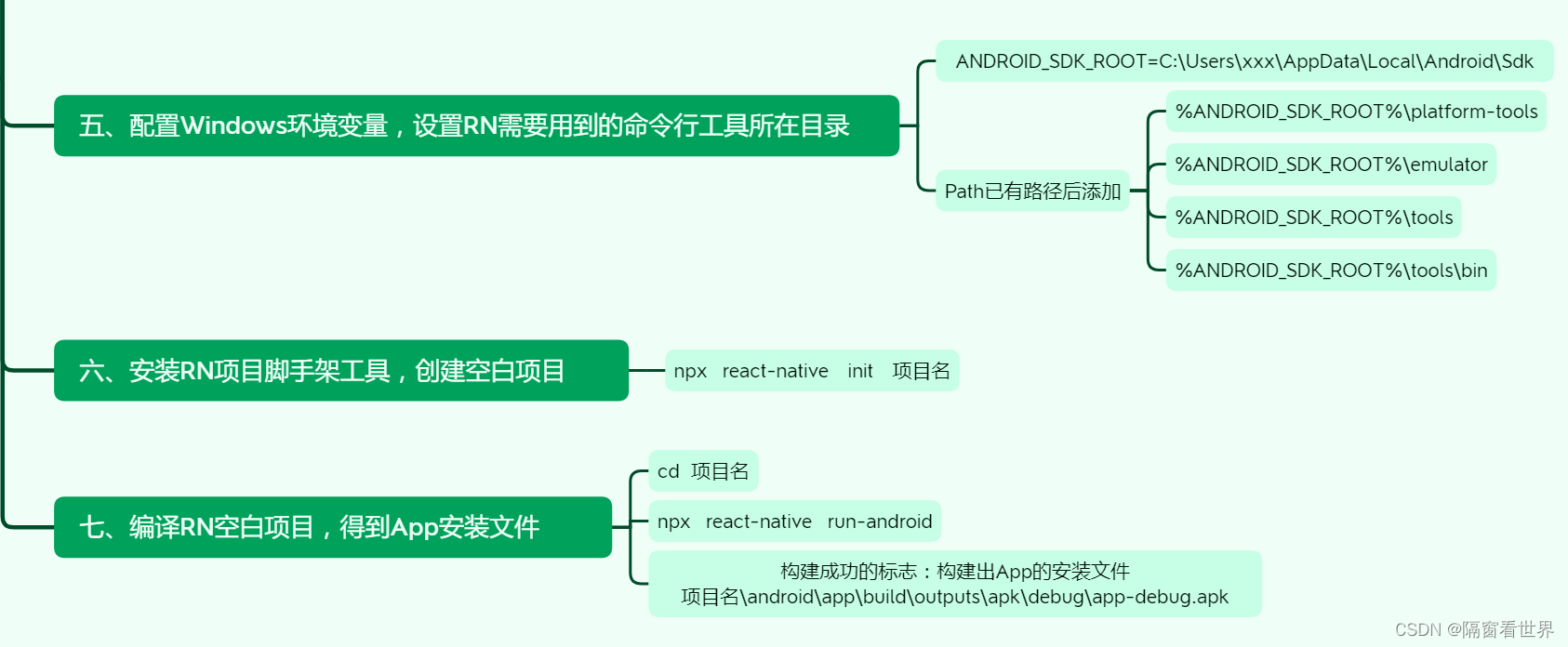
1、NER任务简介与业务场景
任务简介: 任务是信息抽取领域内的一个子任务,其任务目标是给定一段非结构文本后,从句子中寻找、识别和分类相关实体,例如人名、地名和机构名称。
业务场景: 命名实体识别技术可用于特定域的信息抽取,例如在滴滴打车场景中,可将司机与乘客的对话语音转化为文本,然后应用NER技术提取出发地,目的地,乘客信息,敏感词等。
2、NER发展路线

图1:NER发展路线图
3、研究现状
3.1、基于规则
基于规则的 NER 系统依赖于人工制定的规则。可以基于特定领域的地名词典和句法词汇模式来设计规则。比较知名的系统包括:LaSIE-II, NetOwl, Facile和 SAR。当词汇库详尽无遗时,基于规则的系统是一种好的选择。但是在一些特定领域,由于其特定的规则和不完整的词汇库,经常会从此类系统中观察到高精度和低召回率,并且这些系统无法转移到其他领域。
3.2、 基于机器学习
3.2.1、无监督
无监督学习的典型方法是聚类。基于聚类的 NER 系统抽取相关实体是通过上下文相似度的聚类实现的。Collins 等人仅仅使用少量的种子标注数据和 7 个特征,包括拼写(比如大小写),实体上下文,实体本身等,进行实体识别。Nadeau 等人提出一种地名词典构建和命名实体歧义解析的无监督系统。该系统基于简单而高效的启发式方法,结合了实体提取和歧义消除。
3.2.2、有监督
通过监督学习,NER 可以被转换为多分类或序列标注任务。给定带标注的数据样本,经过精心设计的特征可以用来表示每个训练示例。然后利用机器学习算法学习模型,从未知的数据中识别相似的模式。许多机器学习算法已在有监督的 NER 中应用,包括包括隐马尔可夫模型(Hidden Markov Model,HMM),决策树,最大熵模型,支持向量机(support vector machine, SVM)和条件随机场(Conditional Random Fields, CRF)。
3.3、基于深度学习
③基于词序列的模型: 英文以及大多数其他语种的语言天然按空格划分单词,早期的中文NER模型也遵循英文NER模型先分词后预测。然而在分词阶段不可避免分词误差,从而将误差传递到后续的模块中,影响模型的识别能力。
④基于字序列的模型: 为了规避基于词序列的模型带来的分词误差,自2003年后的中文NER模型大都在字序列的层面做进一步的特征抽取和序列标注。
⑤融合外部信息的模型: 单纯的基于字序列的模型只使用字符的语义信息,在信息量上存在明显不足,因此后续研究考虑将各式各样的外部信息融入字符序列中,例如偏旁部首信息,拼音信息,词典信息等。词典信息是应用最广泛的外部信息。
⑥LatticeLSTM: 2018年,Zhang and Yang提出了LatticeLSTM模型。该模型利用一个句子中所有被单个字符匹配到的词语,把这些词语编码为一个有向无环图 (directed acyclic graph, DAG)。优点: 该模型利用一个句子中所有被单个字符匹配到的词语,把这些词语编码为一个有向无环图(directed acyclic graph, DAG)。得益于丰富词汇信息,LatticeLSTM 模型已在各种数据集上取得了不错的结果。缺点: 这个有向无环图结构有时无法选择正确的路径,这可能导致晶格模型退化为部分基于单词的模型。其模型架构图如图2所示:

图2:LatticeLSTM模型架构图
⑦LR-CNN: 2019年,Gui 等人提出了一种基于 CNN 的 NER 模型(Cnn-based chinese ner with lexicon rethinking, LR-CNN), 该模型对匹配的词以不同的窗口大小进行编码(如图 3 所示)。该模型主要通过 CNN 并行处理整个句子以及所有潜在的单词,并且还应用了一种反思机制来处理词典中潜在单词之间的冲突。这种反思机制可以利用高级语义来细化嵌入单词的权重,并解决潜在单词之间的冲突。

图3:LRCNN模型架构图
⑧LGN: 2019年,Gui等人提出了一个基于词典的图形神经网络(A Lexicon-Based Graph Neural Network for Chinese NER, LGN),把中文 NER 看着一个节点分类任务(如图4所示)。通过细致的连接实现了字符和单词之间更好的通过细致的连接实现了字符和单词之间更好的交互效果。词汇知识将相关字符连接起来,以捕获本地特征。同时,设计了一个全局中继节点来捕获远程依赖和高级特征。LGN 遵循邻域聚集方案,其中通过递归聚集其输入边和全局中继节点来计算节点表示。由于聚合的多次迭代,该模型可以使用全局上下文信息来重复比较歧义词,以获得更好的预测。

图4:LGN模型架构图
⑨CGN: 2019年,Sui 等人针对词汇匹配问题,提出了一种基于字符的协同图形网络,包括编码层、图形层、融合层和解码层。该模型构建三个词典和字符的图,使用GAT抽取每个图中蕴含的信息并融合到一起作为字符的融合特征。该模型的架构如如图5所示。

图5: CGN模型架构图
⑩TENER: 2019年,Yan 等人在中文 NER 任务上提出了一种改进的 Transformer 编码器 TENER。Yan 等人通过使用方向相对位置编码,减少参数的数量,并提高注意分布,来提高基于 transformer 的模型在NER 任务中的性能。经过实验验证,模型性能有了很大的提高,甚至比基于 BiLSTM 的模型性能更好。其模型架构图如图6所示。

图6:TENER模型架构图
11 PLT: Lattice结构将词典词信息加入字符级的中文NER能够有效利用丰富的词边界信息。但是,由于DAG有向无环图的结构和单向的顺序性质,使得基于RNNs的这种方法不能进行批量计算和有效的语义交互。2020年,Xue等人在论文中提出的PLT,以transformer encoder为基础,能够并行地批量处理对所有字符和匹配的词典词信息的建模。除此之外,它还添加了位置关系表示;引进了一种多孔机制增强局部性的建模和维持捕捉长期依赖的能力。其模型架构图如图7所示。

图7: PLT模型架构图
12 SoftLexicon: 2020年,Ma 等人提出了一个简单的方法来实现Lattice-LSTM 的思想,即把每个字符的所有匹配词合并到一个基于字符的 NER 模型中。该模型不仅在字符表示中编码词典信息,同时还结合了新的编码方案。新的编码方案能够尽可能多地保留词典匹配结果。因此该模型能够实现快速的推理速度。与Lattice-LSTM 相比,该模型不需要复杂的模型结构,更容易实现,并且可以通过调整字符表示层快速适应任何合适的神经 NER 模型。其模型架构图如图8所示。

图8:SoftLexicon模型架构图
13 FLAT 2020年,Li 等人利用平面Lattice结构,以便 Transformer可以通过位置编码来捕获词信息,由此提出了Chinese NER Using Flat-Lattice Transformer(FLAT) 模型。FLAT 采用全连接的自我关注来模拟序列中的长距离依赖关系。为了保持位置信息,Transformer为序列中的每个标记引入了位置表示。Transformer的自我关注机制使角色能够直接与任何潜在的词互动,包括自我匹配的词。其模型架构如图9所示。

图9: FLAT模型架构图
14 DCSAN 2021年,Zhao 等人提出了一种动态的跨自晶格注意网络方法。该方法的灵感来源于计算机视觉中的VQA 任务。如图 7 所示,他们把字符和单词序列视为为两种不同的模态。为了对词字晶格结构上的信息交互进行建模,首先设计了一个跨晶格注意力模块,该模块旨在捕获两个输入特征空间之间细粒度的相关性。然后,进一步构造一个动态的自晶格注意模块,该模块能够动态融合单词特征并且在不管两个任意字符之间的距离如何而建立他们之间的直接联系。给定词和字向量表示和对齐的晶格构,模型首先利用跨晶格注意力模块以生成拥有词信息的字符特征。然后采用动态的自晶格注意力模块结合字符和单词特征,最终获得自我注意的字符特征。以这种方式,我们的网络可以充分的捕获词字晶格结构上的信息交互,从而为中文 NER 预测提供了丰富的表示形式。其模型架构如图10所示。

图10: DCSAN模型架构图
15 MECT: 2021年,Wu 等人为了利于汉字的结构信息,提出了提出了一种新颖的基于多元数据嵌入的 Cross-Transformer 模型。如图 11 所示,Wu 等人在 FLAT 模型的基础上引入 radical-stream 模块,该模块可以融合中文结构信息,例如偏旁部首。该方法利用的中文结构信息对于同音字干扰中文分词也是一种有效的解决方法。

图11: MECT模型架构图
4、主流模型效果对比
4.1、 数据集介绍
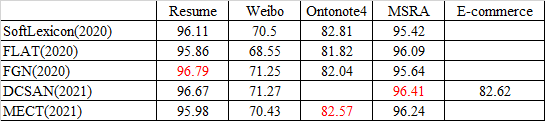
现有中文NER的数据集主要有Resume、Weibo、Ontonote4.0、MSRA、E-commerce。各个数据集情况如表1所示:
表1:中文NER常用数据集概况

4.2、评价指标
中文NER目前作为典型的序列标注任务,其评价指标采用实体的标准F1值。其计算公式如式1所示:
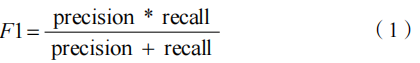
4.3、最新模型结果对比
5、结论与展望
目前传统的中文NER任务已经做的比较完善了,如果期望在NER领域做出更好的效果,需要制作新的数据集或者迁移到其他语种以及具体应用场景(如特定域的信息抽取)中。另一个研究点是轻量级NER模型的鲁棒性研究,现有模型愈发臃肿,大都牺牲模型速度换取模型性能,因此怎么在减轻模型体积的前提下增加模型的鲁棒性是一个非常值得研究的点。
6、 参考文献
[1] Nadeau D, Sekine S. A survey of named entity recognization and classification[J]. Lingvisticae Investigationes. 2007, 30 (1): 3-26.
[2] Collins M, Singer Y. Unsupervised models for named entity classification[C]//1999 Joint SIGDAT Conference on Empirical Methods in Natural Language Processing and Very Large Corpora. 1999.
[3] Nadeau D, Turney P D, Matwin S. Unsupervised named-entity recognition: Generating gazetteers and resolving ambiguity[C]. Conference of the Canadian society for computational studies of intelligence, 2006: 266-277.
[4] Eddy S R. Hidden markov models[J]. Current opinion in structural biology. 1996, 6 (3): 361-365.
[5] Quinlan J R. Induction of decision trees[J]. Machine learning. 1986, 1 (1): 81–106.
[6] Kapur J N. Maximum-entropy models in science and engineering[M]. John Wiley & Sons, 1989.
[7] Suthaharan S. Support vector machine[M]//Suthaharan S. Machine learning models and algorithms for big data classification. Springer, 2016: 2016: 207-235.
[8] Lafferty J, McCallum A, Pereira F C. Conditional random fields: Probabilistic models for segmenting and labeling sequence data[C]//In Proceedings of the Eighteenth International Conference on Machine Learning. 2001: 282-289.
[9] Collobert R, Weston J, Bottou L, et al. Natural language processing (almost) from scratch[J]. Journal of machine learning research. 2011, 12 (ARTICLE): 2493-2537.
[10] Yadav V, Bethard S. A survey on recent advances in named entity recognition from deep learning models[J]. arXiv preprint arXiv:1910.11470. 2019.
[11] Ma X, Hovy E. End-to-end sequence labeling via bi-directional lstm-cnnscrf[J]. arXiv preprint arXiv:1603. 01354. 2016.
[12] Peters M E, Neumann M, Iyyer M, et al. Deep contextualized word representations[J]. arXiv preprint arXiv:1802. 05365. 2018.
[13] Yang J, Teng Z, Zhang M, et al. Combining discrete and neural features for sequence labeling[C]//International Conference on Intelligent Text Processing and Computational Linguistics. 2016: 140-154.
[14] Gui T, Ma R, Zhang Q, et al. Cnn-based chinese ner with lexicon rethinking[C]//Proceedings of the 28th International Joint Conference on Artificial Intelligence, 2019: 4982-4988.
[15] 赵山,罗睿,蔡志平.中文命名实体识别综述[J].计算机科学与探索,2022,16(02):296-304.

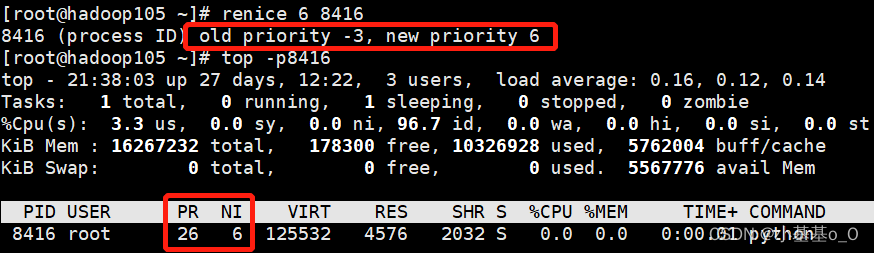
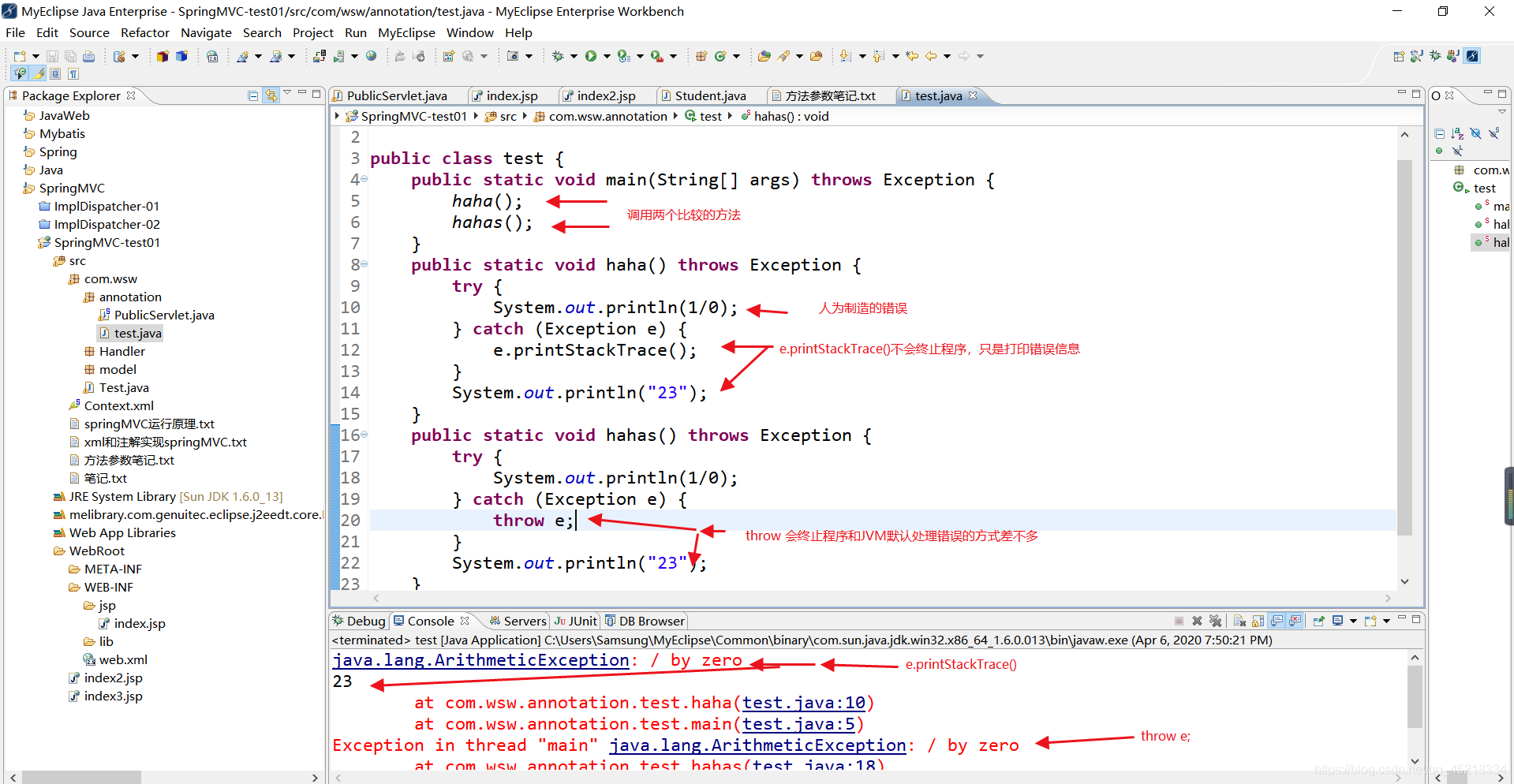
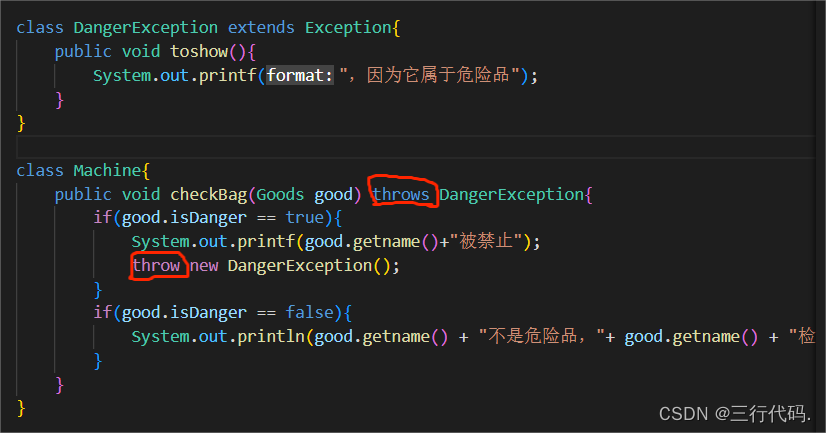
![得到c++程序Process ID [getpid()], 调高CPU优先级 [renice]](https://img-blog.csdnimg.cn/9ed2665d7a894787b490e6bd77f3fa4b.png)