目录
学习要求
一、数据科学的学科地位
二、统计学
1.统计学与数据科学
2.数据科学中常用的统计学知识
3.统计学与机器学习的区别与联系
4.数据科学视角下的统计学
三、机器学习
1.机器学习与数据科学
2.数据科学中常用的机器学习的知识
(1)基于实例学习
(2)概念学习
(3)决策树学习
(4)人工神经网络学习
(5)贝叶斯学习
(6)遗传算法
(7)分析学习
(8)增强学习
3.机器学习在数据科学中的应用
四。数据可视化
总结
学习要求
掌握:数据科学的学科地位
理解:统计学、机器学习、数据可视化对数据科学的主要影响
了解:数据科学的理论基础
一、数据科学的学科地位
从学科定位看,数据科学处于数学与统计知识、黑客精神与技能和领域实务知识三大领域重叠之处。
- 数据科学与(传统)数学和统计学有区别
- “黑客精神与技能”——大胆创新、喜欢挑战、追求完美和不断改进
- “领域和务实知识”——不仅掌握数学与统计知识以及具备黑客精神与技能,而且还需要精通某一个特定领域的实务知识与经验
- 数据科学:大数据背后的科学
- 新兴科学:是一门将“现实世 界”映射到“数据世 界”之后,在“数据 层次”上研究“现实 世界”的问题,并 根据“数据世界”的 分析结果,对“现 实世界”进行预测 、洞见、解释或 决策的新兴科学
- 交叉性学科:是一门以“数据”,尤其是“大数据”为 研究对象,并以 数据统计、机器 学习、数据可视 化等为理论基础 ,主要研究数据 加工与准备、数 据分析、数据管 理、数据计算、 数据产品开发等 活动的交叉性学科
- 独立学科:是一门以实现“从 数据到信息”、“从 数据到知识”和( 或)“从数据到智 慧”的转化为主要 研究目的,以“数 据驱动”、“数据业 务化”、“数据洞见 ”、“数据产品研发 ”和(或)“数据生 态系统的建设”为 主要研究任务的 独立学科
- 知识体系:是一门以“数据时 代”,尤其是“大数 据时代”面临的新 挑战、新机会、 新思维和新方法 为核心内容的,包括新的理论、 方法、模型、技 术、平台、工具 、应用和最佳实 践在内的一整套 知识体系。
二、统计学
1.统计学与数据科学
统计学是数据科学的主要基础理论之一。
2.数据科学中常用的统计学知识
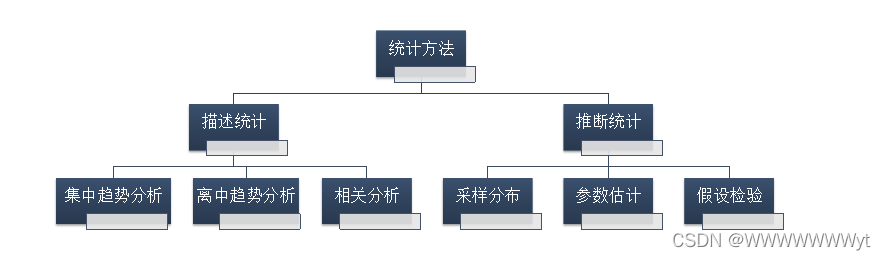
- 从行为目的与思维方式看
描述统计:集中趋势分析、离中趋势分析
推断统计:采样分布、参数估计、假设检验
- 从方法论角度
基本分析法:回归分析、分类分析、聚类分析、关联规则分析、时间序列分析
元分析法:加权平均法、优化方法
3.统计学与机器学习的区别与联系
通常认为统计学更关注的是“可解释性”,侧重“模型”;机器学习更关注“预测能力”,侧重“算法”,但统计学与机器学习并不是完全对立,反而相互融洽的趋势愈加显著
- 从理论方法角度
统计学的方法可以应用于机器学习,反之亦然。
- 从统计学家(或机器学习)的角度
很多统计学家也是计算机科学家,反之亦然
- 主要区别
1.统计学需要事先对处理对象(数据)的概率分布做出假定,而机器学习则不需要
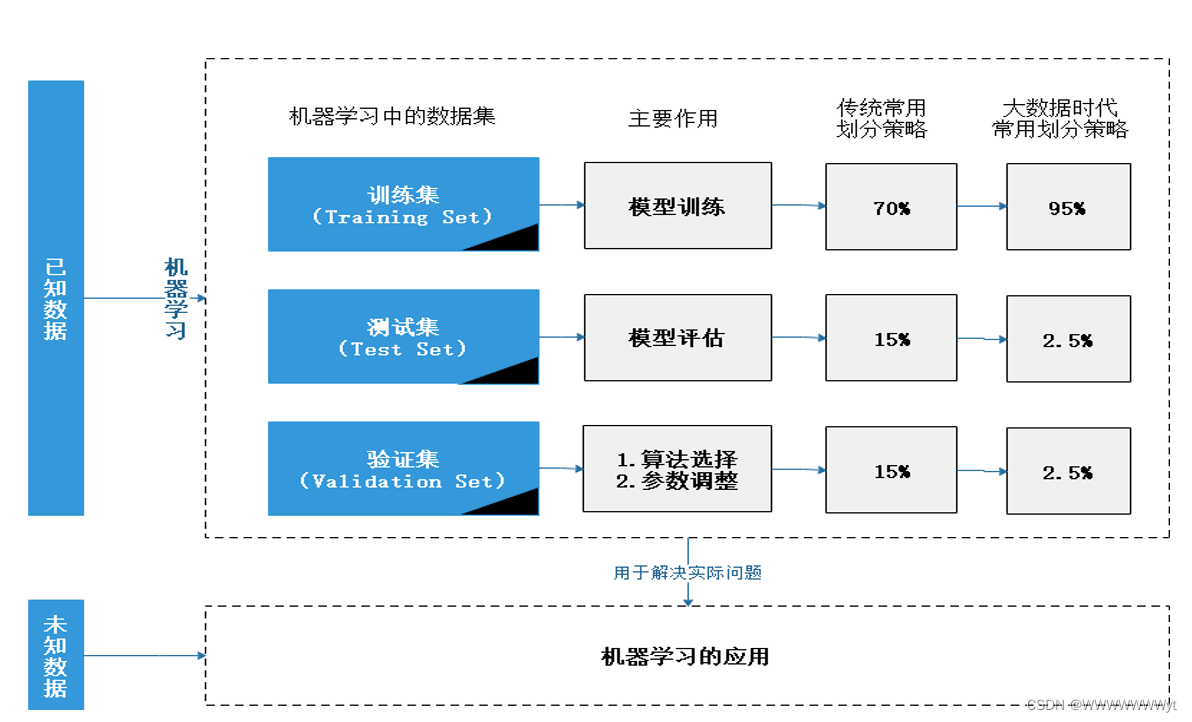
2.统计学通过各种统计指标(如置信区间)以评价统计模型的拟合优度,而机器学习通过交叉 验证验证或划分训练集和测试集的方法评价算法准确度。
4.数据科学视角下的统计学
- 不是随机样本,而是全体数据
- 不是精确性,而是混杂性
- 不是因果关系,而是相关关系
三、机器学习
1.机器学习与数据科学
机器学习思路:以现有的部分数据(训练集)为学习素材(输入),通过特定的学习方法(机器学习算法),让机器学习到(输出)能够处理更多或未来数据的新能力(目标函数)。
2.数据科学中常用的机器学习的知识
(1)基于实例学习
事先将训练样本存储下来,然后每当遇到一个新增查询实例时,学习系统分析新增实例与以前存储的实例之间的关系,并据此把一个目标函数赋给一个新增实例。
方法:K临近法、局部加权回归法、基于案例的推理
(2)概念学习
从有关某个布尔函数的输入输出训练严格不能中推算出该布尔函数。
方法:Find-S算法、候选消除算法
(3)决策树学习
一种逼近离散值目标函数的过程。
决策树代表一种分类的过程
- 根节点:分类的开始
- 叶节点:一个实例的结束
- 中间节点:相应实例的某一属性
- 节点之间的边:某一个属性的属性值
- 从根节点到叶节点的每条路径:一个具体的实例,同一个路径上的所有所有属性之间是“逻辑与”的关系
方法:ID3算法
(4)人工神经网络学习
由人工神经元组成人工神经网络,神经元之间的连接方式对于选择具体学习算法具有重要影响。根据连接方式的不同,通常把人工神经网络分为无反馈的向前神经网络和相互连接型网络(反馈网络)。
方法:深度学习
(5)贝叶斯学习
以贝叶斯法则为基础,并通过概率手段进行学习的方法。
方法:朴素贝叶斯分类器
(6)遗传算法
主要研究“从候选假设空间中搜索出最佳假设”
基本原则(借鉴生物):适者生存、两性繁衍及突变
基本算子(与原则对应):选择、交叉和突变
方法:GA算法
(7)分析学习
使用先验知识来分析或解释每个训练样本,以推理出样本的哪些特征与目标函数相关或不相关,因此这些假设能使机器学习系统比单独依靠数据进行泛化有更高的精度。
(8)增强学习
研究如何协助自治Agent(具有与环境交互能力的自治主体如机器人)的学习活动,进而达到选择最优动作的目的。
常见机器学习算法:有监督学习、无监督学习、半监督学习
3.机器学习在数据科学中的应用
1.机器学习的应用(IBM Watson)
该框架的阶段:
- 命中列表的规范化
- 问题分类
- 迁移学习
- 答案合并
- 最优答案选择
- 证据扩散
- 多项答案
2.机器学习与其他技术的集成应用
- 统计分析
- 信息检索
- 自然语言处理
- 知识表达与推理
- 人机接口
四.数据可视化
重要地位:
1.视觉是人类获得信息的主要途径
- 视觉感知是人类大脑的最主要功能之一
- 眼睛是感知信息能力最强的人体器官之一
2.相对于统计分析,数据可视化的优势在于:
- 可视化处理可以洞察分析无法发现的结构和细节
- 可视化处理结果的解读对用户知识水平的要求较低
3.可视化可以帮助人们提高理解与处理数据的效率
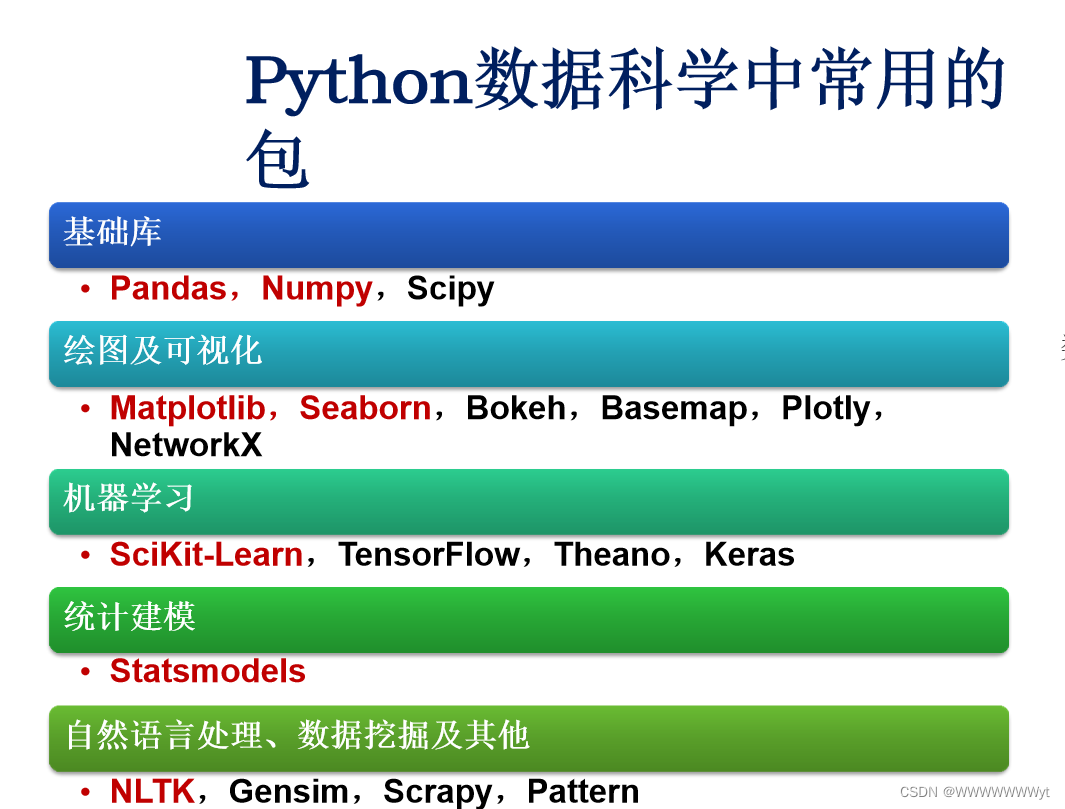
五.python常用库
总结
通过本章的学习,我对现在所学的专业有了更深刻的了解,对之后的学习之路有了大概的方向,同时也对之后要学习的课程产生了好奇。