基于R语言的主成分回归(PCR)与Lasso回归在水稻基因组预测中的对比
0 引言
全基因组选择是 21 世纪动植物育种的一种重要的选择策略,其核心就是全基因组预测,即基于分布在整个基因组上的多样性分子标记来对育种值进行预测,为个体的选择提供依据。
全基因组选择( genomic selection,GS) 是利用分布在整个基因组上的分子标记来估算育种值的一种高效、经济的方法.它实质上是估计所有基因或染色体片段的联合效应,并结合这些效应来预测基因组 估计的育种值( genomic estimated breeding value,GEBV)。
许多统计方法都可用于全基因组选择,包括贝叶斯方法( 贝叶斯 B) ,最佳线性无偏预测( BLUP) , 以及正则化线性模型( 岭回归、Lasso 回归和弹性网络) 等。但是对于预测农作物的性状而言没有一种方法是完美的,它们各有各的特点,而预测的效果取决于模型的性质与性状的特点和遗传结构。
本文将对基于R语言编写的主成分回归分析方法与Lasso回归方法进行对比,并对来自于RIL.G.Rdata和RIL.T.Rdata的数据预测结果进行对比,比较哪种预测效果更好。
1 材料与方法
1.1 实验数据
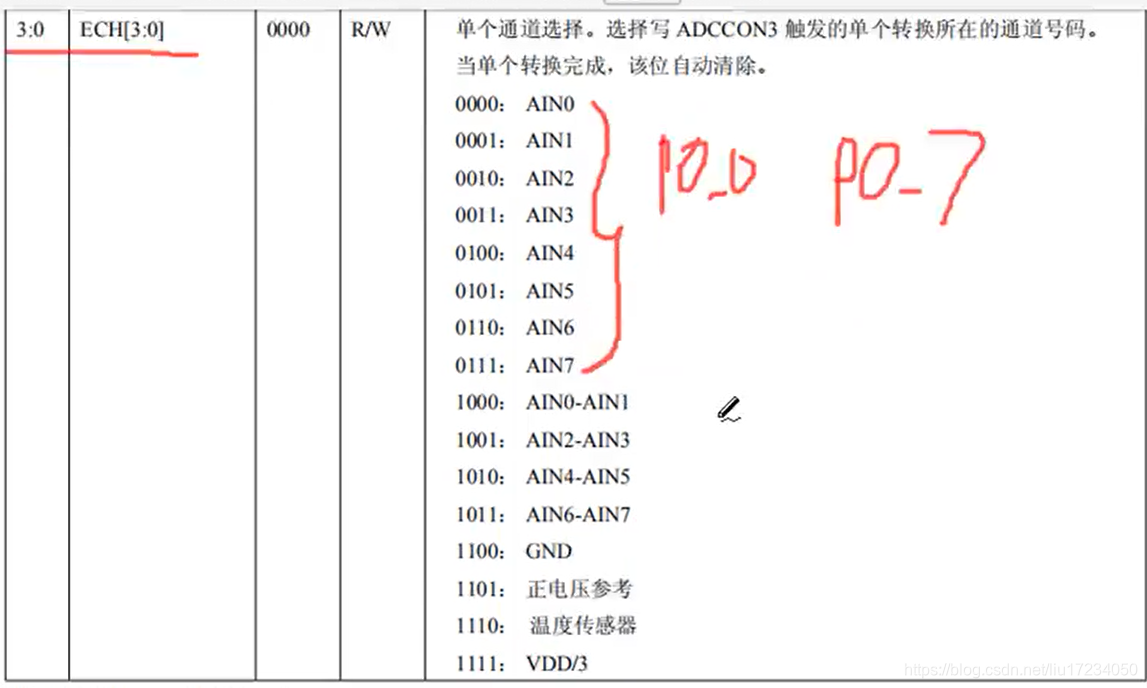
数据来源是Gains in QTL detection using an ultra-high density SNP map based on population sequencing relative to traditional RFLP/SSR markers.. 实验人员实验人员将珍汕 97 A 和明恢 63 两个水稻品种作为亲本,杂交产生 210 个重组自交系( recombinant inbred lines,RIL) ,从这些重组自交系中收集 4 个产量相关性状的表型数据,它们分别是水稻产量( yd) ,千粒重( kgw) ,分蘖数( tp) 和单株谷粒数 ( gn) 。将各个重复的性状的平均表型值作为响应变量。基因组数据由水稻基因组的约270 000 个 SNP 推断的 1 619 个组( bin) 表示。组内的所有 SNP 都具有完全相同的分离模式( 完全的连锁不平衡( LD) ) ,因 此来自一组的一个SNP 足以代表整个组。210 个RIL 的基因型编码为: 1 代表珍汕97 A 基因型,0代表明 恢 63 基因型。
1.2 统计模型
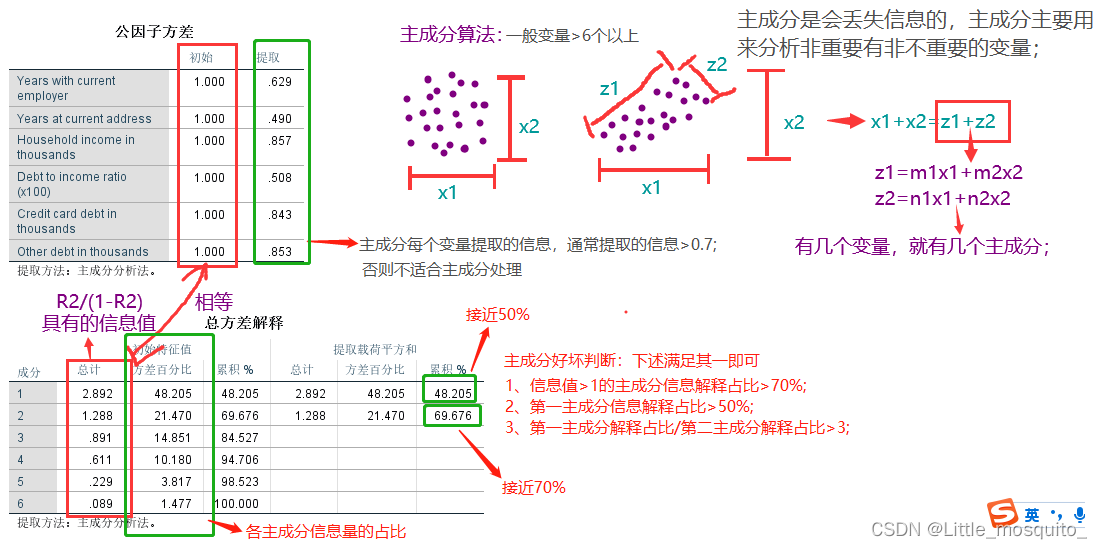
1.2.1 主成分回归
主成分回归分析(PCR),以主成分为自变量进行的回归分析。是分析多元共线性问题的一种方法。用主成分得到的回归关系不像用原自变量建立的回归关系那样容易解释。
用主成分分析法对回归模型中的多重共线性进行消除后,将主成分变量作为自变量进行回归分析,然后根据得分系数矩阵将原变量代回得到的新的模型。主成分回归结合了主成分提取和多元回归分析的思想,适用于变量比较多的情况,样本数比变量的维度少的情况。
1.2.2 Lasso 回归
Lasso( least absolute shrinkage and selection operator) 是统计学家 Robert Tibshirani 在 1996 年提出的一种变量选择方法,它是 OLS 的约束版本,是一种基于线性回归模型的降维方法,对高维小样本数据的 稀疏模型十分有用,在基因表达谱分析中被广泛应用。

奇妙地是,适当选择调节参数λ,可以使得部分回归系数变成零, 达到了即减小回归系数的绝对值又挑选重要变量子集的效果。
2 模型代码详解
因对不同的表型的思路与方法类似,以下仅以RIL.G.Rdata中的数据中水稻产量( yd) 为例进行解释
2.0 实验准备
2.0.1 软件和数据准备
下载好R语言以及rstudio,并将需要的数据"RIL.G.Rdata"、“RIL.T.Rdata”、"RIL.Phe.Rdata"保存到工作目录
2.0.2 准备需要用到的R包
# 安装包
install.packages("glmnet")
install.packages('foreach')
install.packages('Matrix')
install.packages('pls')
加载R包,以便后续使用:
# 加载包
library(pls)
library(Matrix)
library(glmnet)
library(foreach)
2.1 主成分回归
2.1.1 导入数据
load("RIL.G.Rdata")
# 210*1619的矩阵,每一行代表一株水稻,每一列代表一个遗传标记
load("RIL.T.Rdata")
# 210*5467的矩阵,每一列代表一个基因的表达量
load("RIL.Phe.Rdata")
#210*4的矩阵,每一列代表一个表型
2.1.2 数据初步处理
Gen_YD<-data.frame(G)
Phe<-data.frame(RIL.Phe)
Gen_YD$YD<-Phe$yd #将产量(yd)合并到Gen_YD
sum(is.na(Gen_YD))#检查Gen_YD的na值
2.1.3 建造训练集和测试集
x_YD<-model.matrix(YD~.,Gen_YD)
y_YD<-Gen_YD$YD
set.seed(1)#编号为1的随机数,使模拟结果可以重复
train_YD<-sample(1:nrow(x_YD),nrow(x_YD)*7/10)# train:test=7:3
x_YD.train<-x_YD[train_YD,]
x_YD.test<-x_YD[-train_YD,]
y_YD.train<-y_YD[train_YD]
y_YD.test<-y_YD[-train_YD]
traindata_YD<-Gen_YD[train_YD,]
testdata_YD<-Gen_YD[-train_YD,]
2.1.4 拟合模型
G_YD.model <- pcr(YD~., data=Gen_YD, scale=TRUE, validation="CV")
summary(G_YD.model)
参数解释:
- scale = TRUE 每个预测变量都被标准为均值为0,标准差为1,这避免了模型中预测变量使用不同度量单位而产生的影响。
- validation = “CV”: 使用K折交叉验证评估模型表现,默认K为10。也可以使用LOOCV参数。
2.1.5 选择主成分
可视化方式展示RMSE,从而更直观决定选择主成分数量
layout(matrix(c(2,3,1,1),2,2, byrow = TRUE))#2,3 两个图在第一行,1图在第二行占两列(共2行2列)
validationplot(G_YD.model, val.type="R2")
validationplot(G_YD.model, val.type="MSEP")
validationplot(G_YD.model)
运行结果图:

由summary(G_YD.model)中的结果以及上图可知,在加入51个主成分时,模型的拟合效果较好,且保留的原始信息达到了85%左右,故选取51个主成分。
2.1.5 使用最终模型进行预测
此次使用51个主成分模型测试新的观测数据,使用PCR模型在测试集上预测:
YD.trainmodel <- pcr(YD~., data=traindata_YD, scale=TRUE, validation="CV")
pcr_pred.YD <- predict(YD.trainmodel, testdata_YD, ncomp=51)
2.1.6 报导MSE说明预测效果
# 计算MSE
YD.pr.MSE<-mean((pcr_pred.YD - y_YD.test)^2)
YD.pr.MSE
#YD.pr.MSE=17.27612
2.2 LASSO回归
2.2.1—2.2.3于2.1中2.1.1—2.1.3相同,故省略
2.2.4 观察调节参数λ变化时系数估计的变化情况
用R的glmnet包计算lasso。 用glmnet()函数, 指定参数alpha=1时执行的是lasso。 用参数lambda=指定一个调节参数网格, lasso将输出这些调节参数对应的结果。 对回归结果使用plot()函数可以画出调节参数变化时系数估计的变化情况。
使用gmlnet包的glmnet()函数计算Lasso回归, 指定一个调节参数网格grid
# 为了绘图, 先选择的λ一个网格
#100个数,都是10的多少次方,幂为10到-2中间100个数
grid <- 10^seq(10,-2,length=100)
#使用gmlnet包的glmnet()函数计算Lasso回归,
#指定一个调节参数网格
LASSO.model_YD<- glmnet(x_YD.train, y_YD.train, alpha=1, lambda=grid)
plot(LASSO.model_YD)
得到G_YD数据的LASSO轨迹图:

对lasso结果使用plot()函数可以绘制延调节参数网格变化的各回归系数估计,横坐标不是调节参数而是调节参数对应的系数绝对值和, 可以看出随着系数绝对值和增大,实际是调节参数变小, 更多地自变量进入模型。
2.2.5 用交叉验证估计调节参数
按照前面划分的训练集与测试集, 仅使用训练集数据做交叉验证估计最优调节参数:
#使用训练集数据做交叉验证估计最优调节参数λ
CV.LASSO.model_YD<-cv.glmnet(x_YD.train,y_YD.train,alpha=1)
plot(CV.LASSO.model_YD)
CV.LASSO.model_YD$lambda.min
# LASSO.model_YD$lambda.min=0.4222839

2.2.6 预测并求得YD预测结果的MSE
y_YD.test.pred<-predict(LASSO.model_YD,newx = x_YD.test,s=CV.LASSO.model_YD$lambda.min)
MSE_YD_LASSO.min<-mean((y_YD.test-y_YD.test.pred)^2)
MSE_YD_LASSO.min
# MSE_YD_LASSO.min=15.49929
3 结果与分析
3.1.1 PCR预测的MSE:
| 表型 | 来自G中数据 | 来自T中数据 |
|---|---|---|
| YD | 17.27612 | 6.961144 |
| KGW | 1.44509 | 2.102107 |
| TP | 1.004282 | 0.6619375 |
| GN | 331.4245 | 118.1309 |
3.1.2 LASSO回归预测的MSE
| 表型 | 来自G中数据 | 来自T中数据 |
|---|---|---|
| YD | 15.49929 | 6.250179 |
| KGW | 1.786023 | 2.191938 |
| TP | 1.230221 | 0.7583952 |
| GN | 305.9624 | 166.5751 |
3.2 结果讨论
3.2.1 比较不同方法的回归模型
从表中数据的MSE值比较来看,PCR与LASSO有如下结论:
- 1、对于G中数据,PCR对于YD和GN的拟合效果不如LASSO模型的拟合效果,而KGW和TP的拟合效果优于LASSO模型
- 2、对于T中数据,除YD外,其余各表型均是PCR的拟合效果更好
- 3、综上所述,PCR与LASSO对各组数据拟合的拟合效果各有优劣
3.2.2 比较G与T数据中哪一个预测效果更好
从表中数据的MSE值比较来看,G与T数据的预测结果有如下结论:
-
1、PCR预测结果中,除KGW外,其余各表型均是来自T中的数据具有更好的预测效果
-
2、LASSO回归预测结果中, 除KGW外,其余各表型均是来自T中的数据具有更好的预测效果
-
3、综上所述,除开KGW表型外,不管哪种方法,均是T中数据的预测结果更好,故可以认为,若对所有表型同时预测,T中数据较好
4 收获
在此次实验中,除了了解了多元线性回归和LASSO回归的操作方法外,也在过程中去了解了岭回归和回归变量的选择。
有时数据集可能包含过多特征,甚至是冗余特征,可以用降维技术进压缩特征,但通常会降低模型性能。
最常用的特征降维方法是主成分分析(PCA),是利用协方差矩阵的特征值分解
原理,实现多个特征向少量综合特征(称为主成分)的转化,每个主成分都是
多个原始特征的线性组合,且各个主成分之间互不相关,第一主成分是解释数
据变异(方差)最大的,然后是次大的,依此类推。
此外还了解到,通常情况下,划分训练集和验证集与交叉验证方法经常联合运用。 取一个固定的较小规模的测试集, 此测试集不用来作子集选择, 对训练集用交叉验证方法选择最优子集, 然后再测试集上验证。
5 附录
5.1 各组数据PCR的RMSE直观图
-
G_YD:

-
G_KGW:

-
G_TP:

-
G_GN:

-
T_YD:

-
T_KGW:

-
T_TP:

-
T_GN:

5.2 各组数据LASSO轨迹图
-
G_YD:

-
G_KGW:

-
G_TP:

-
G_GN:

-
T_YD:

-
T_KGW:

-
T_TP:

-
T_GN:

5.3 各组数据的λ
-
G_YD:

-
G_KGW:

-
G_TP:

-
G_GN:

-
T_YD:

-
T_KGW:

-
T_TP:

-
T_GN:

5.4 完整代码
load("RIL.G.Rdata")
# 210*1619的矩阵,每一行代表一株水稻,每一列代表一个遗传标记
load("RIL.T.Rdata")
# 210*5467的矩阵,每一列代表一个基因的表达量
load("RIL.Phe.Rdata")
#210*4的矩阵,每一列代表一个表型
library(Matrix)
library(glmnet)
library(foreach)
library(pls)
#1.利用G预测Phe中的四个表型
#数据处理
Gen_YD<-data.frame(G)
Gen_KGW<-data.frame(G)
Gen_TP<-data.frame(G)
Gen_GN<-data.frame(G)
Phe<-data.frame(RIL.Phe)
Gen_YD$YD<-Phe$yd #将产量(yd)合并到Gen_YD
Gen_KGW$KGW<-Phe$kgw #千粒重(kgw)合并到基因标记中Gen_KGW
Gen_TP$TP<-Phe$tp #分蘖数(tp)合并到Gen_TP
Gen_GN$GN<-Phe$gn # 单株谷粒数(gn)合并到Gen_GN中
sum(is.na(c(Gen_YD,Gen_KGW,Gen_GN,Gen_TP)))##1、产量YD
###建造训练集和测试集
x_YD<-model.matrix(YD~.,Gen_YD)
y_YD<-Gen_YD$YD
set.seed(1)#编号为1的随机数,使模拟结果可以重复
train_YD<-sample(1:nrow(x_YD),nrow(x_YD)*7/10)
x_YD.train<-x_YD[train_YD,]
x_YD.test<-x_YD[-train_YD,]
y_YD.train<-y_YD[train_YD]
y_YD.test<-y_YD[-train_YD]
traindata_YD<-Gen_YD[train_YD,]
testdata_YD<-Gen_YD[-train_YD,]##主成分回归
G_YD.model <- pcr(YD~., data=Gen_YD, scale=TRUE, validation="CV")
summary(G_YD.model)
#可视化方式展示RMSE,从而更直观决定选择主成分数量
layout(matrix(c(2,3,1,1),2,2, byrow = TRUE))
validationplot(G_YD.model, val.type="R2")
validationplot(G_YD.model, val.type="MSEP")
validationplot(G_YD.model)
#训练模型并预测
YD.trainmodel <- pcr(YD~., data=traindata_YD, scale=TRUE, validation="CV")
pcr_pred.YD <- predict(YD.trainmodel, testdata_YD, ncomp=51)
# 计算MSE
YD.pr.MSE<-mean((pcr_pred.YD - y_YD.test)^2)
YD.pr.MSE
#YD.pr.MSE=17.27612#LASSO回归
# 为了绘图, 先选择的λ一个网格
#100个数,都是10的多少次方,幂为10到-2中间100个数
grid <- 10^seq(10,-2,length=100)
#使用gmlnet包的glmnet()函数计算Lasso回归,
#指定一个调节参数网格
LASSO.model_YD<- glmnet(x_YD.train, y_YD.train, alpha=1, lambda=grid)
plot(LASSO.model_YD)
#使用训练集数据做交叉验证估计最优调节参数λ
CV.LASSO.model_YD<-cv.glmnet(x_YD.train,y_YD.train,alpha=1)
plot(CV.LASSO.model_YD)
CV.LASSO.model_YD$lambda.min
# LASSO.model_YD$lambda.min= 0.4222839
#预测并求得YD预测结果的MSE
y_YD.test.pred<-predict(LASSO.model_YD,newx = x_YD.test,s=CV.LASSO.model_YD$lambda.min)
MSE_YD_LASSO.min<-mean((y_YD.test-y_YD.test.pred)^2)
MSE_YD_LASSO.min
# MSE_YD_LASSO.min=15.49929##2、千粒重KGW
###建造训练集和测试集
x_KGW<-model.matrix(KGW~.,Gen_KGW)
y_KGW<-Gen_KGW$KGW
set.seed(2)#编号为2的随机数,使模拟结果可以重复
train_KGW<-sample(1:nrow(x_KGW),nrow(x_KGW)*7/10)
x_KGW.train<-x_KGW[train_KGW,]
x_KGW.test<-x_KGW[-train_KGW,]
y_KGW.train<-y_KGW[train_KGW]
y_KGW.test<-y_KGW[-train_KGW]
traindata_KGW<-Gen_KGW[train_KGW,]
testdata_KGW<-Gen_KGW[-train_KGW,]##主成分回归
G_KGW.model <- pcr(KGW~., data=Gen_KGW, scale=TRUE, validation="CV")
summary(G_KGW.model)
#可视化方式展示RMSE,从而更直观决定选择主成分数量
layout(matrix(c(2,3,1,1),2,2, byrow = TRUE))
validationplot(G_KGW.model, val.type="R2")
validationplot(G_KGW.model, val.type="MSEP")
validationplot(G_KGW.model)
#训练模型并预测
KGW.trainmodel <- pcr(KGW~., data=traindata_KGW, scale=TRUE, validation="CV")
pcr_pred.KGW <- predict(KGW.trainmodel, testdata_KGW, ncomp=114)
# 计算MSE
KGW.pr.MSE<-mean((pcr_pred.KGW - y_KGW.test)^2)
KGW.pr.MSE
#KGW.pr.MSE=1.44509#LASSO
# 为了绘图, 先选择的λ一个网格
#100个数,都是10的多少次方,幂为10到-2中间100个数
grid <- 10^seq(10,-2,length=100)
#使用gmlnet包的glmnet()函数计算Lasso回归,
#指定一个调节参数网格(沿用前面的网格)
LASSO.model_KGW<- glmnet(x_KGW.train, y_KGW.train, alpha=1, lambda=grid)
plot(LASSO.model_KGW)
#使用训练集数据做交叉验证估计最优调节参数λ
CV.LASSO.model_KGW<-cv.glmnet(x_KGW.train,y_KGW.train,alpha=1)
plot(CV.LASSO.model_KGW)
CV.LASSO.model_KGW$lambda.min
#预测并求得KGW预测结果的MSE
# LASSO.model_KGW$lambda.min=0.03154449
y_KGW.test.pred<-predict(LASSO.model_KGW,newx = x_KGW.test,s=CV.LASSO.model_KGW$lambda.min)
MSE_KGW_LASSO.min<-mean((y_KGW.test-y_KGW.test.pred)^2)
MSE_KGW_LASSO.min
# MSE_KGW_LASSO.min=1.786023##3、分蘖数TP
###建造训练集和测试集
x_TP<-model.matrix(TP~.,Gen_TP)
y_TP<-Gen_TP$TP
set.seed(3)#编号为3的随机数,使模拟结果可以重复
train_TP<-sample(1:nrow(x_TP),nrow(x_TP)*7/10)
x_TP.train<-x_TP[train_TP,]
x_TP.test<-x_TP[-train_TP,]
y_TP.train<-y_TP[train_TP]
y_TP.test<-y_TP[-train_TP]
traindata_TP<-Gen_TP[train_TP,]
testdata_TP<-Gen_TP[-train_TP,]##主成分回归
G_TP.model <- pcr(TP~., data=Gen_TP, scale=TRUE, validation="CV")
summary(G_TP.model)
#可视化方式展示RMSE,从而更直观决定选择主成分数量
layout(matrix(c(2,3,1,1),2,2, byrow = TRUE))
validationplot(G_TP.model, val.type="R2")
validationplot(G_TP.model, val.type="MSEP")
validationplot(G_TP.model)
#训练模型并预测
TP.trainmodel <- pcr(TP~., data=traindata_TP, scale=TRUE, validation="CV")
pcr_pred.TP <- predict(TP.trainmodel, testdata_TP, ncomp=44)
# 计算MSE
TP.pr.MSE<-mean((pcr_pred.TP - y_TP.test)^2)
TP.pr.MSE
#TP.pr.MSE=1.004282#LASSO
# 为了绘图, 先选择的λ一个网格
#100个数,都是10的多少次方,幂为10到-2中间100个数
grid <- 10^seq(10,-2,length=100)
#使用gmlnet包的glmnet()函数计算Lasso回归,
#指定一个调节参数网格(沿用前面的网格)
LASSO.model_TP<- glmnet(x_TP.train, y_TP.train, alpha=1, lambda=grid)
plot(LASSO.model_TP)
#使用训练集数据做交叉验证估计最优调节参数λ
CV.LASSO.model_TP<-cv.glmnet(x_TP.train,y_TP.train,alpha=1)
plot(CV.LASSO.model_TP)
CV.LASSO.model_TP$lambda.min
# LASSO.model_TP$lambda.min= 0.02266522
#预测并求得TP预测结果的MSE
y_TP.test.pred<-predict(LASSO.model_TP,newx = x_TP.test,s=CV.LASSO.model_TP$lambda.min)
MSE_TP_LASSO.min<-mean((y_TP.test-y_TP.test.pred)^2)
MSE_TP_LASSO.min
#MSE_TP_LASSO.min= 1.230221##4、单株谷粒数GN
###建造训练集和测试集
x_GN<-model.matrix(GN~.,Gen_GN)
y_GN<-Gen_GN$GN
set.seed(4)#编号为4的随机数,使模拟结果可以重复
train_GN<-sample(1:nrow(x_GN),nrow(x_GN)*7/10)
x_GN.train<-x_GN[train_GN,]
x_GN.test<-x_GN[-train_GN,]
y_GN.train<-y_GN[train_GN]
y_GN.test<-y_GN[-train_GN]
traindata_GN<-Gen_GN[train_GN,]
testdata_GN<-Gen_GN[-train_GN,]##主成分回归
G_GN.model <- pcr(GN~., data=Gen_GN, scale=TRUE, validation="CV")
summary(G_GN.model)
#可视化方式展示RMSE,从而更直观决定选择主成分数量
layout(matrix(c(2,3,1,1),2,2, byrow = TRUE))
validationplot(G_GN.model, val.type="R2")
validationplot(G_GN.model, val.type="MSEP")
validationplot(G_GN.model)
#训练模型并预测
GN.trainmodel <- pcr(GN~., data=traindata_GN, scale=TRUE, validation="CV")
pcr_pred.GN <- predict(GN.trainmodel, testdata_GN, ncomp=77)
# 计算MSE
GN.pr.MSE<-mean((pcr_pred.GN - y_GN.test)^2)
GN.pr.MSE
#GN.pr.MSE=331.4245
# 为了绘图, 先选择的λ一个网格
#100个数,都是10的多少次方,幂为10到-2中间100个数
grid <- 10^seq(10,-2,length=100)
#使用gmlnet包的glmnet()函数计算Lasso回归,
#指定一个调节参数网格(沿用前面的网格)
LASSO.model_GN<- glmnet(x_GN.train, y_GN.train, alpha=1, lambda=grid)
plot(LASSO.model_GN)
#使用训练集数据做交叉验证估计最优调节参数λ
CV.LASSO.model_GN<-cv.glmnet(x_GN.train,y_GN.train,alpha=1)
plot(CV.LASSO.model_GN)
CV.LASSO.model_GN$lambda.min
# LASSO.model_GN$lambda.min= 1.230093
#预测并求得GN预测结果的MSE
y_GN.test.pred<-predict(LASSO.model_GN,newx = x_GN.test,s=CV.LASSO.model_GN$lambda.min)
MSE_GN_LASSO.min<-mean((y_GN.test-y_GN.test.pred)^2)
MSE_GN_LASSO.min
#MSE_GN_LASSO.min= 305.9624#2.利用T预测Phe中的四个表型
#数据处理
Gen_YD<-data.frame(RIL.T)
Gen_KGW<-data.frame(RIL.T)
Gen_TP<-data.frame(RIL.T)
Gen_GN<-data.frame(RIL.T)
Phe<-data.frame(RIL.Phe)
Gen_YD$YD<-Phe$yd #将产量(yd)合并到Gen_YD
Gen_KGW$KGW<-Phe$kgw #千粒重(kgw)合并到基因标记中Gen_KGW
Gen_TP$TP<-Phe$tp #分蘖数(tp)合并到Gen_TP
Gen_GN$GN<-Phe$gn # 单株谷粒数(gn)合并到Gen_GN中
sum(is.na(c(Gen_YD,Gen_KGW,Gen_GN,Gen_TP)))#LASSO回归
##1、产量YD
###建造训练集和测试集
x_YD<-model.matrix(YD~.,Gen_YD)
y_YD<-Gen_YD$YD
set.seed(5)#编号为5的随机数,使模拟结果可以重复
train_YD<-sample(1:nrow(x_YD),nrow(x_YD)*7/10)
x_YD.train<-x_YD[train_YD,]
x_YD.test<-x_YD[-train_YD,]
y_YD.train<-y_YD[train_YD]
y_YD.test<-y_YD[-train_YD]
traindata_YD<-Gen_YD[train_YD,]
testdata_YD<-Gen_YD[-train_YD,]##主成分回归
G_YD.model <- pcr(YD~., data=Gen_YD, scale=TRUE, validation="CV")
summary(G_YD.model)
#可视化方式展示RMSE,从而更直观决定选择主成分数量
layout(matrix(c(2,3,1,1),2,2, byrow = TRUE))
validationplot(G_YD.model, val.type="R2")
validationplot(G_YD.model, val.type="MSEP")
validationplot(G_YD.model)
#训练模型并预测
YD.trainmodel <- pcr(YD~., data=traindata_YD, scale=TRUE, validation="CV")
pcr_pred.YD <- predict(YD.trainmodel, testdata_YD, ncomp=51)
# 计算MSE
YD.pr.MSE<-mean((pcr_pred.YD - y_YD.test)^2)
YD.pr.MSE
#YD.pr.MSE=6.961144#LASSO回归
# 为了绘图, 先选择的λ一个网格
#100个数,都是10的多少次方,幂为10到-2中间100个数
grid <- 10^seq(10,-2,length=100)
#使用gmlnet包的glmnet()函数计算Lasso回归,
#指定一个调节参数网格
LASSO.model_YD<- glmnet(x_YD.train, y_YD.train, alpha=1, lambda=grid)
plot(LASSO.model_YD)
#使用训练集数据做交叉验证估计最优调节参数λ
CV.LASSO.model_YD<-cv.glmnet(x_YD.train,y_YD.train,alpha=1)
plot(CV.LASSO.model_YD)
CV.LASSO.model_YD$lambda.min
# LASSO.model_YD$lambda.min= 0.4514454
#预测并求得YD预测结果的MSE
y_YD.test.pred<-predict(LASSO.model_YD,newx = x_YD.test,s=CV.LASSO.model_YD$lambda.min)
MSE_YD_LASSO.min<-mean((y_YD.test-y_YD.test.pred)^2)
MSE_YD_LASSO.min
# MSE_YD_LASSO.min=6.250179##2、千粒重KGW
###建造训练集和测试集
x_KGW<-model.matrix(KGW~.,Gen_KGW)
y_KGW<-Gen_KGW$KGW
set.seed(6)#编号为6的随机数,使模拟结果可以重复
train_KGW<-sample(1:nrow(x_KGW),nrow(x_KGW)*7/10)
x_KGW.train<-x_KGW[train_KGW,]
x_KGW.test<-x_KGW[-train_KGW,]
y_KGW.train<-y_KGW[train_KGW]
y_KGW.test<-y_KGW[-train_KGW]
traindata_KGW<-Gen_KGW[train_KGW,]
testdata_KGW<-Gen_KGW[-train_KGW,]##主成分回归
G_KGW.model <- pcr(KGW~., data=Gen_KGW, scale=TRUE, validation="CV")
summary(G_KGW.model)
#可视化方式展示RMSE,从而更直观决定选择主成分数量
layout(matrix(c(2,3,1,1),2,2, byrow = TRUE))
validationplot(G_KGW.model, val.type="R2")
validationplot(G_KGW.model, val.type="MSEP")
validationplot(G_KGW.model)
#训练模型并预测
KGW.trainmodel <- pcr(KGW~., data=traindata_KGW, scale=TRUE, validation="CV")
pcr_pred.KGW <- predict(KGW.trainmodel, testdata_KGW, ncomp=125)
# 计算MSE
KGW.pr.MSE<-mean((pcr_pred.KGW - y_KGW.test)^2)
KGW.pr.MSE
#KGW.pr.MSE=2.102107#LASSO
# 为了绘图, 先选择的λ一个网格
#100个数,都是10的多少次方,幂为10到-2中间100个数
grid <- 10^seq(10,-2,length=100)
#使用gmlnet包的glmnet()函数计算Lasso回归,
#指定一个调节参数网格(沿用前面的网格)
LASSO.model_KGW<- glmnet(x_KGW.train, y_KGW.train, alpha=1, lambda=grid)
plot(LASSO.model_KGW)
#使用训练集数据做交叉验证估计最优调节参数λ
CV.LASSO.model_KGW<-cv.glmnet(x_KGW.train,y_KGW.train,alpha=1)
plot(CV.LASSO.model_KGW)
CV.LASSO.model_KGW$lambda.min
#预测并求得KGW预测结果的MSE
# LASSO.model_KGW$lambda.min= 0.1434862
y_KGW.test.pred<-predict(LASSO.model_KGW,newx = x_KGW.test,s=CV.LASSO.model_KGW$lambda.min)
MSE_KGW_LASSO.min<-mean((y_KGW.test-y_KGW.test.pred)^2)
MSE_KGW_LASSO.min
# MSE_KGW_LASSO.min=2.191938##3、分蘖数TP
###建造训练集和测试集
x_TP<-model.matrix(TP~.,Gen_TP)
y_TP<-Gen_TP$TP
set.seed(7)#编号为7的随机数,使模拟结果可以重复
train_TP<-sample(1:nrow(x_TP),nrow(x_TP)*7/10)
x_TP.train<-x_TP[train_TP,]
x_TP.test<-x_TP[-train_TP,]
y_TP.train<-y_TP[train_TP]
y_TP.test<-y_TP[-train_TP]
traindata_TP<-Gen_TP[train_TP,]
testdata_TP<-Gen_TP[-train_TP,]##主成分回归
G_TP.model <- pcr(TP~., data=Gen_TP, scale=TRUE, validation="CV")
summary(G_TP.model)
#可视化方式展示RMSE,从而更直观决定选择主成分数量
layout(matrix(c(2,3,1,1),2,2, byrow = TRUE))
validationplot(G_TP.model, val.type="R2")
validationplot(G_TP.model, val.type="MSEP")
validationplot(G_TP.model)
#训练模型并预测
TP.trainmodel <- pcr(TP~., data=traindata_TP, scale=TRUE, validation="CV")
pcr_pred.TP <- predict(TP.trainmodel, testdata_TP, ncomp=114)
# 计算MSE
TP.pr.MSE<-mean((pcr_pred.TP - y_TP.test)^2)
TP.pr.MSE
#TP.pr.MSE=0.6619375#LASSO
# 为了绘图, 先选择的λ一个网格
#100个数,都是10的多少次方,幂为10到-2中间100个数
grid <- 10^seq(10,-2,length=100)
#使用gmlnet包的glmnet()函数计算Lasso回归,
#指定一个调节参数网格(沿用前面的网格)
LASSO.model_TP<- glmnet(x_TP.train, y_TP.train, alpha=1, lambda=grid)
plot(LASSO.model_TP)
#使用训练集数据做交叉验证估计最优调节参数λ
CV.LASSO.model_TP<-cv.glmnet(x_TP.train,y_TP.train,alpha=1)
plot(CV.LASSO.model_TP)
CV.LASSO.model_TP$lambda.min
# LASSO.model_TP$lambda.min= 0.05295078
#预测并求得TP预测结果的MSE
y_TP.test.pred<-predict(LASSO.model_TP,newx = x_TP.test,s=CV.LASSO.model_TP$lambda.min)
MSE_TP_LASSO.min<-mean((y_TP.test-y_TP.test.pred)^2)
MSE_TP_LASSO.min
#MSE_TP_LASSO.min= 0.7583952##4、单株谷粒数GN
###建造训练集和测试集
x_GN<-model.matrix(GN~.,Gen_GN)
y_GN<-Gen_GN$GN
set.seed(8)#编号为8的随机数,使模拟结果可以重复
train_GN<-sample(1:nrow(x_GN),nrow(x_GN)*7/10)
x_GN.train<-x_GN[train_GN,]
x_GN.test<-x_GN[-train_GN,]
y_GN.train<-y_GN[train_GN]
y_GN.test<-y_GN[-train_GN]
traindata_GN<-Gen_GN[train_GN,]
testdata_GN<-Gen_GN[-train_GN,]##主成分回归
G_GN.model <- pcr(GN~., data=Gen_GN, scale=TRUE, validation="CV")
summary(G_GN.model)
#可视化方式展示RMSE,从而更直观决定选择主成分数量
layout(matrix(c(2,3,1,1),2,2, byrow = TRUE))
validationplot(G_GN.model, val.type="R2")
validationplot(G_GN.model, val.type="MSEP")
validationplot(G_GN.model)
#训练模型并预测
GN.trainmodel <- pcr(GN~., data=traindata_GN, scale=TRUE, validation="CV")
pcr_pred.GN <- predict(GN.trainmodel, testdata_GN, ncomp=130)
# 计算MSE
GN.pr.MSE<-mean((pcr_pred.GN - y_GN.test)^2)
GN.pr.MSE
#GN.pr.MSE=118.1309#LASSO
# 为了绘图, 先选择的λ一个网格
#100个数,都是10的多少次方,幂为10到-2中间100个数
grid <- 10^seq(10,-2,length=100)
#使用gmlnet包的glmnet()函数计算Lasso回归,
#指定一个调节参数网格(沿用前面的网格)
LASSO.model_GN<- glmnet(x_GN.train, y_GN.train, alpha=1, lambda=grid)
plot(LASSO.model_GN)
#使用训练集数据做交叉验证估计最优调节参数λ
CV.LASSO.model_GN<-cv.glmnet(x_GN.train,y_GN.train,alpha=1)
plot(CV.LASSO.model_GN)
CV.LASSO.model_GN$lambda.min
# LASSO.model_GN$lambda.min=0.2338641
#预测并求得GN预测结果的MSE
y_GN.test.pred<-predict(LASSO.model_GN,newx = x_GN.test,s=CV.LASSO.model_GN$lambda.min)
MSE_GN_LASSO.min<-mean((y_GN.test-y_GN.test.pred)^2)
MSE_GN_LASSO.min
#MSE_GN_LASSO.min= 166.5751