CHOLAN: A Modular Approach for Neural Entity Linking on Wikipedia and Wikidata
论文链接:https://arxiv.org/abs/2101.09969 (EACL 2021)
代码实现:https://github.com/ManojPrabhakar/CHOLAN
ABSTRACT
本文作者提出了实现在知识库上进行端到端实体链接的模块化方法——CHOLAN,该模型包含由两个 transformer-base model 构成的 pipeline。第一个 transformer 用于提取句子中的 mention,第二个 transformer 获取 mention context 和 entity description 并以此将 mention 分类到预定的候选实体集中。作者在实验中将实体链接到 Wikipedia、Wikidata 两个知识库中,并在 CoNLL-AIDA, MSNBC, AQUAINT, ACE2004, T-REx 数据集上取得了优于 SOTA 的表现。
1 简介
实体链接包含三个步骤:
- mention detection:从句子中检测出实体提及
- candidate generation:生成候选实体集合
- entity disambiguation:通过语义消歧,从实体集合中选出最优实体
实体链接的方法主要分为以下三类:
- 将 mention detection 和 entity diambiguation 作为独立的子任务,会导致将前一阶段的错误传播到后一阶段
- 将 MD 和 ED 联合建模,强调两个子任务相互依赖
- 将三个步骤联合建模,并认为这三个任务相互依存
作者认为 candidate generation 是影响 EL 模型性能的瓶颈,对此作者进行了探究。CHOLAN 在 以下数据集上取得了 SOTA 的成绩 T- REx for Wikidata; AIDA-B, MSBC, AQUAINT, and ACE2004 for Wikipedia。
2 相关工作
mention detection
mention detection 可以视为命名实体识别的任务,解决方案涉及以下几种: CRFs、特征字典构建、基于特征推理的神经网络、上下文编码
candidate generate
有四类主流方法:1. 预定义的候选实体集合;2. 字典查询(字典通过统计知识库关联别名构建);3. 经验概率实体图, p ( m ∣ e ) p(m|e) p(m∣e);;4. 通过使用Wikidata 的实体标签、关联别名等数据扩展构建局部知识图
End2End EL
2016 年:图模型。 J-nerd: joint named entity recogni- tion and disambiguation with rich linguistic features.
2018 年:使用 Bi-LSTM 模型进行 MD,通过计算 mention detection embedding 和 candidate description 的相似度进行消歧,其中使用了预定义的 candidate 集合。 End-to-end neural entity linking.
2019 年:使用 BERT 模型对三个子任务联合建模。Investigating entity knowl- edge in bert with simple neural end-to-end en- tity linking
2020 年:使用 transformer 模型实现了三个子任务;基于启发式模型进行消歧;对于MD、ED 训练神经网络,并使用别名生成实体。
3 方法
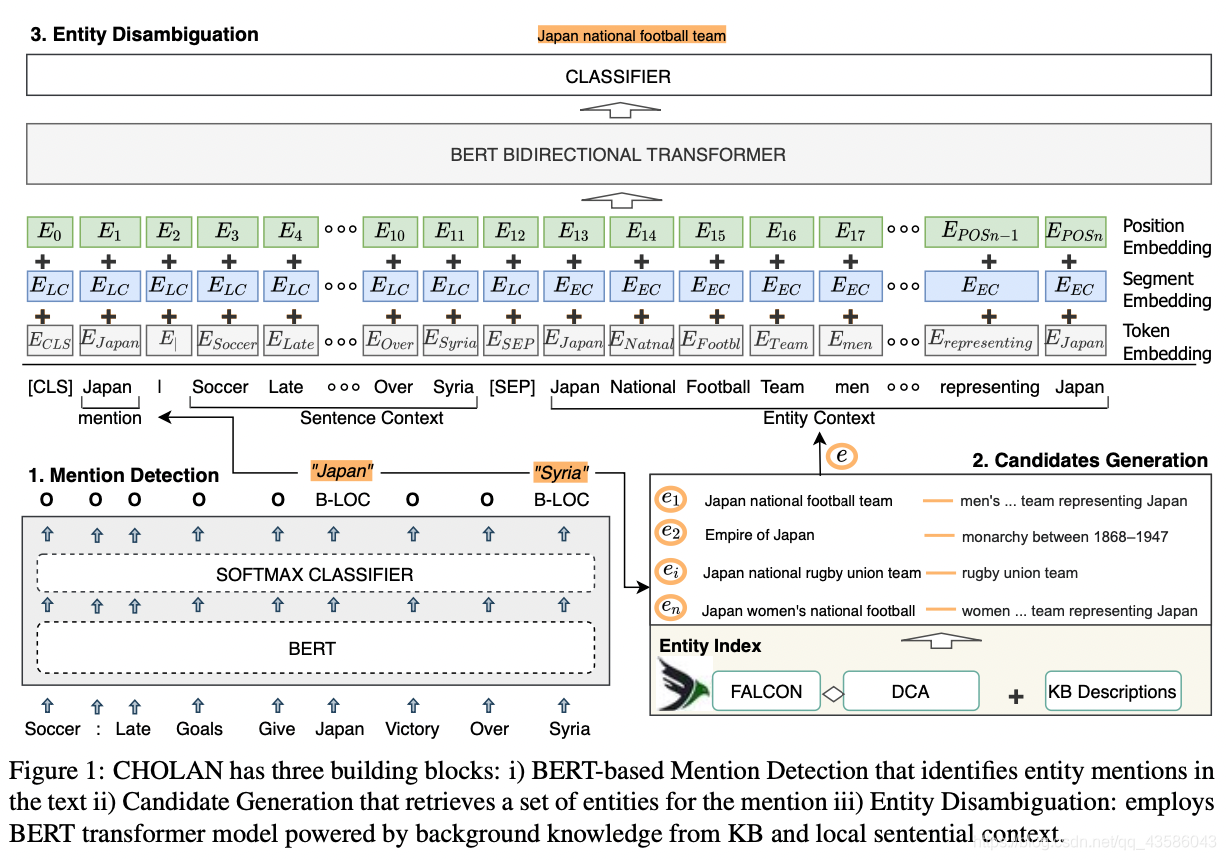
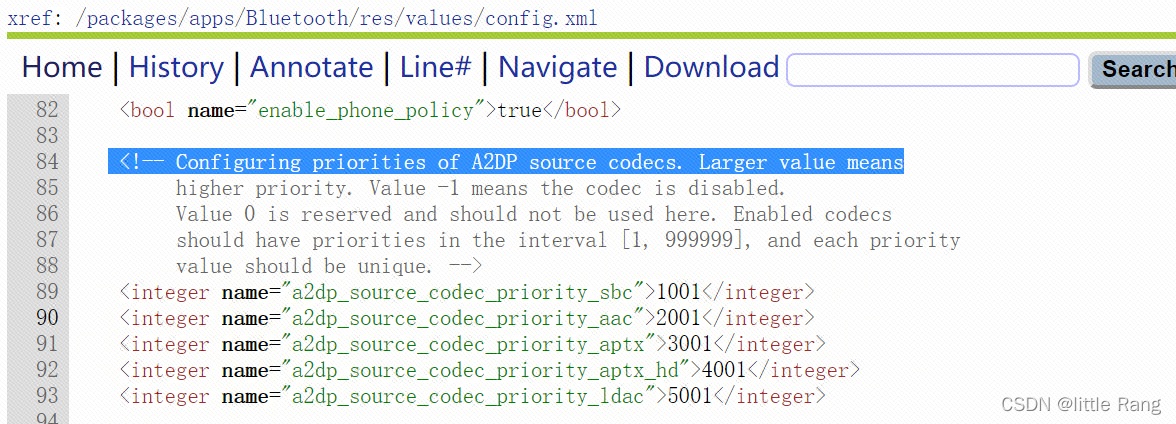
3.1 Mention detection
使用了 Bert 预训练模型,将 [CLS] 和 [SEP] 添加到句子的首尾输入到 Bert 模型中。再使用逻辑回归将每个 token 分类到 BIO 标签上。作者使用了最新的 B E R T B A S E BERT_{BASE} BERTBASE 预训练参数,在非结构化的专门数据集上进行微调,如上图左下角所示。
3.2 Candidate generation
使用了 两个候选实体集,用来检验candidate generation 对entity linking 的影响:
- DCA 候选实体集 :由 2019 年论文Learning dynamic con- text augmentation for global entity linking 提出,根据概率实体图创建,每个 mention 有 30 个候选实体
- Falcon 候选实体集:由 2019 年论文 Old is gold: Linguistic driven approach for entity and relation linking of short text. 提出,从 Wikidata 中创建本地索引 KG,并通过别名进行扩展,本地索引 KG 通过 BM25 进行检索。作者使用 Wikipedia 对 Falcon进行了扩展,同时将 Wikipedia 中相关实体的第一段,作为 entity description 添加到 candidate 中。
3.3 Entity disambiguation
作者提出了 WikiBERT 模型,WikiBERT 衍生于 Bert 模型,并在实体链接数据集 (CoNLL-AIDA and T-REx) 上进行微调。作者声称:“WikiBERT 的创新之处在于 将局部的句子上下文和全局的 entity 上下文引入到了 transformer 中” (个人认为 BLINK, 2020 就已经提出了该方法)作者将 mention context 和 entity description 拼接到一起,以 SEP 分隔,输入到 BERT 中,将实体消歧视为句子分类问题。
句子中的 mention、context、entity 都是以下三种 embedding 的加和。
- token embedding:将 mention 以
|分隔,放在 S1 头部;entity name 直接放在 entity description 的首部。 - segment embedding:每个序列都加上 mention context 和 entity description 的embedding
- position embedding:表示输入位置 i i i 的 embedding
模型的训练采用了 Pre-training of deep contextualized embeddings of words and entities for named entity disambiguation 2019 年提出的负采样的方法。
4 实验
对于Wikidata知识库,作者选择了 T-REx 数据集。对于 Wikipedia 知识库,作者选择了 CoNLL-AIDA 数据集进行训练,使用了 AIDA-B MSNBC AQUAINT ACE2004 数据集进行测试。
作者在 Wikidata 和 Wikipedia 两个知识库上对 baseline 进行了对比,CHOLAN 超过了以往的 SOTA 模型,同时作者分别在这两个KG上对 Candidate generation 和 entity dismbiguation 进行了消融实验。结果证明,选择更优的 candidate set 以及在消歧阶段引入 entity description 和 mention context 能显著提高模型性能。
改进空间:对于候选实体生成,可以使用 Zero- shot entity linking with dense entity retrieval. 2019 提出的 bi-encoder 的方法。