Chatbot GPT模型训练过程详解
在人工智能领域,聊天机器人是一种模拟人类对话行为的计算机程序。近年来,随着深度学习和自然语言处理技术的飞速发展,聊天机器人越来越流行。本文将详细阐述GPT(Generative Pre-trained Transformer)模型在聊天机器人的训练过程。
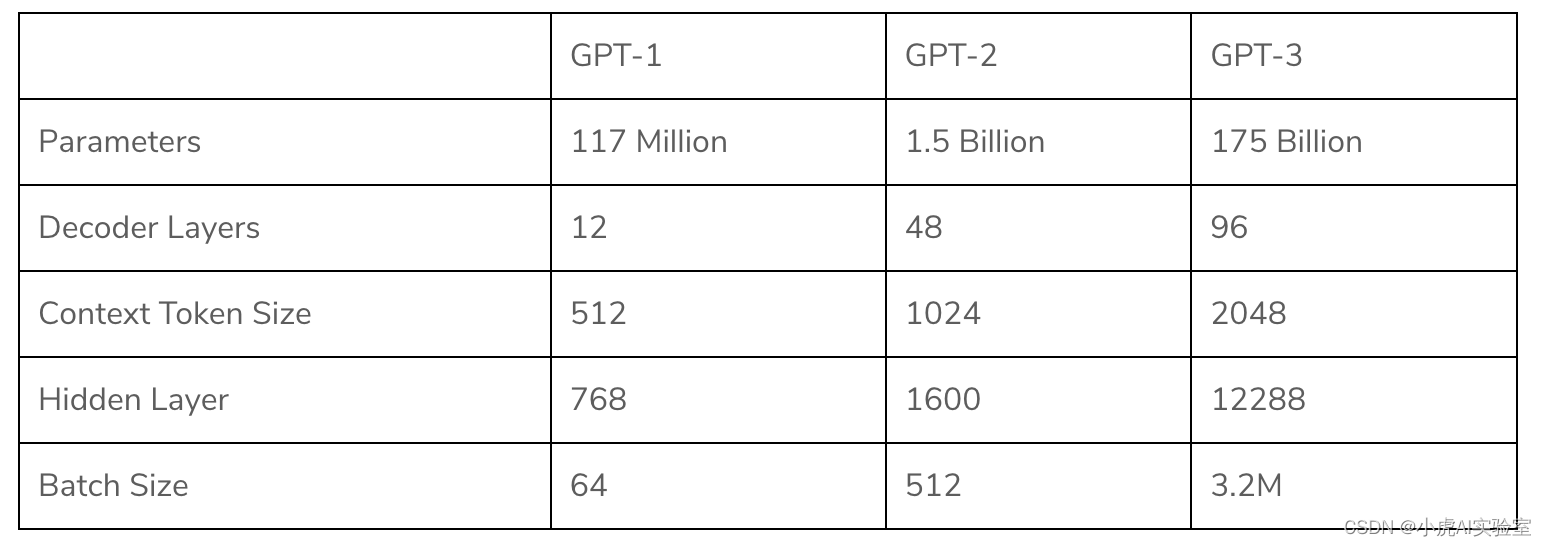
1. GPT模型的基础:Transformer
GPT模型的基础是Transformer模型,它是一种基于自注意力(Self-Attention)机制的深度学习模型。与传统的循环神经网络(RNN)和卷积神经网络(CNN)相比,Transformer模型在处理长距离依赖关系和并行计算方面具有显著优势。
Transformer模型的核心组件是自注意力机制,它允许模型对输入序列中的每个单词分配不同的权重,从而捕捉到丰富的上下文信息。此外,Transformer模型还引入了位置编码(Positional Encoding)来表示单词在输入序列中的位置信息。
2. 预训练GPT模型
GPT模型的训练分为两个阶段:预训练和微调。在预训练阶段,模型在大量无标签文本数据上进行无监督学习,目的是学习到通用的语言表示。这一阶段的训练过程可以分为以下步骤:
2.1 数据准备
首先,我们需要收集大量无标签的文本数据,例如维基百科、书籍、新闻文章等。这些文本数据被称为语料库。为了便于模型处理,我们需要对原始文本进行预处理,包括分词、去除停用词、词干提取等。
2.2 语言模型训练
在预处理后的文本数据上,我们使用单向语言模型进行训练。单向语言模型的目标是根据给定的上下文预测下一个单词。在训练过程中,模型通过最大化似然估计来学习词汇表中每个单词的条件概率分布。
2.3 参数更新
为了训练GPT模型,我们需要定义损失函数和优化器。损失函数通常采用交叉熵损失(Cross-Entropy Loss),用于衡量模型预测的概率分布与实际概率分布之间的差异。优化器的作用是根据损失函数的梯度更新模型参数,常见的优化器有随机梯度下降(SGD)、Adam等。
在训练过程中,我们将输入序列喂给模型,并计算损失函数。然后,我们使用优化器更新模型参数以最小化损失。这个过程需要在大量文本数据上进行多次迭代,以使模型充分学习到语言知识。
3. 微调GPT模型
在预训练阶段完成后,我们需要在特定任务上对GPT模型进行微调。这一阶段的训练过程可以分为以下步骤:
3.1 任务数据准备
首先,我们需要收集与聊天机器人相关的对话数据。这些数据可以是人与人之间的对话,也可以是人与机器人之间的对话。我们需要将对话数据整理成输入输出对的形式,其中输入是上下文文本,输出是回复文本。
3.2 微调语言模型
在收集到任务数据后,我们需要对GPT模型进行微调。这个过程与预训练阶段类似,不过我们需要将无监督学习转换为监督学习。具体来说,我们需要根据任务数据调整模型预测下一个单词的条件概率分布。在微调过程中,我们通常使用较小的学习率,并在较短的时间内进行训练。
3.3 参数更新
在微调阶段,我们同样需要定义损失函数和优化器。损失函数仍然采用交叉熵损失,优化器可以继续使用预训练阶段的优化器。我们需要在任务数据上进行多次迭代,以使模型学习到与聊天机器人相关的语言知识。
4. 聊天机器人的部署和测试