说到查询,日常中常用的baidu,cnbing ,google等之类的网站。关系型数据库中的全文索引应该也是从这些搜索引擎里摸索出来的。
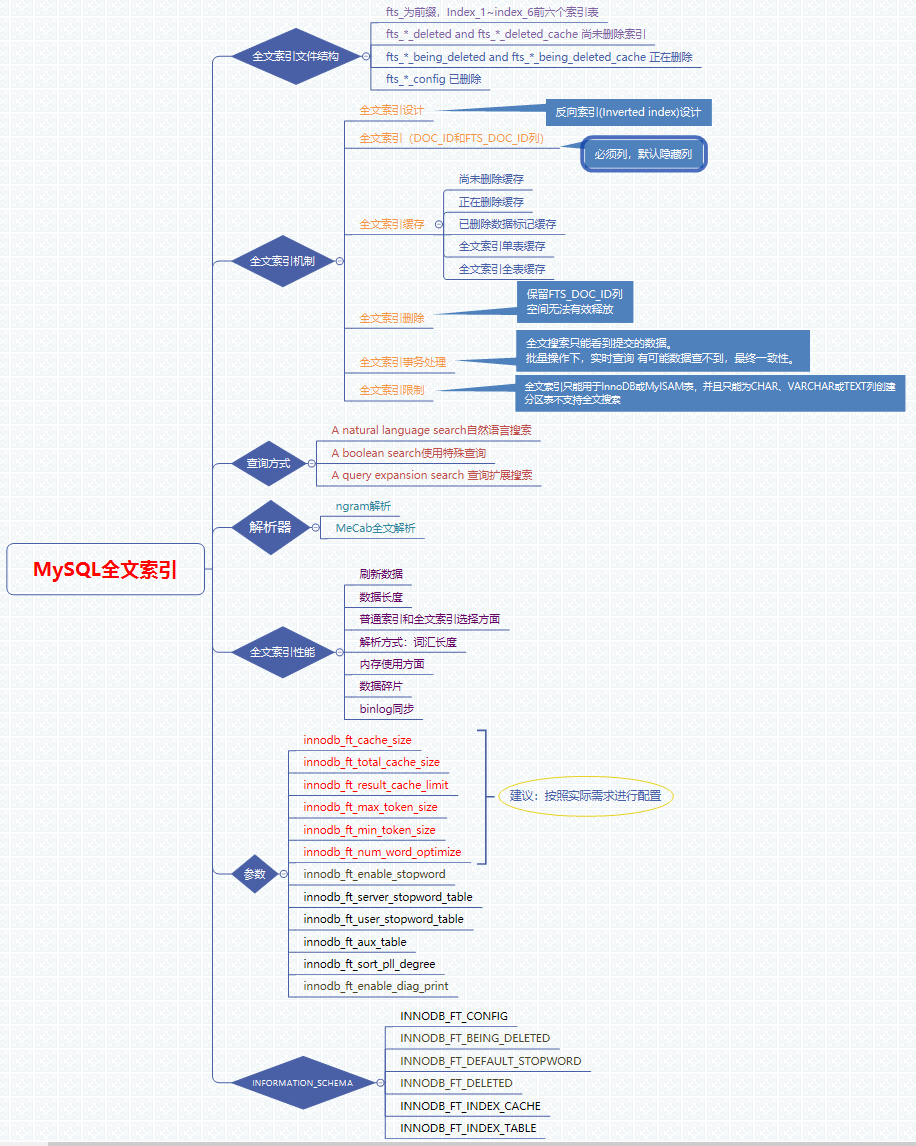
全文索引介绍:
在数据库中常用的查询方式一般是 等价,范围方式。当然也有LIKE %的模糊查询,虽然用不到索引,在文本内容比较少时是比较合适,但是对于大量的文本数据检索,全文索引在大量的数据面前,能比 LIKE % 快很多,速度不是一个数量级。所以总结下来,索引全文索引就是为这种场景设计的。
MySQL中的全文索引表跟普通的表生成的文件不一样,在底层文件会生成fts开头的索引文件,只要在实际生成文件包含这些,就说明表上创建了全文索引。
mysql> CREATE TABLE my_stopwords(value VARCHAR(30)) ENGINE = INNODB;mysql> CREATE FULLTEXT INDEX idx ON table_name(`columns`);mysql> SELECT * FROM INFORMATION_SCHEMA.TABLESPACES_EXTENSIONS WHERE TABLESPACE_NAME LIKE 'db7/fts%';+---------------------------------------------------+------------------+
| TABLESPACE_NAME | ENGINE_ATTRIBUTE |
+---------------------------------------------------+------------------+
| db7/fts_00000000000005c4_00000000000002fa_index_1 | NULL |
| db7/fts_00000000000005c4_00000000000002fa_index_2 | NULL |
| db7/fts_00000000000005c4_00000000000002fa_index_3 | NULL |
| db7/fts_00000000000005c4_00000000000002fa_index_4 | NULL |
| db7/fts_00000000000005c4_00000000000002fa_index_5 | NULL |
| db7/fts_00000000000005c4_00000000000002fa_index_6 | NULL |
| db7/fts_00000000000005c4_being_deleted | NULL |
| db7/fts_00000000000005c4_being_deleted_cache | NULL |
| db7/fts_00000000000005c4_config | NULL |
| db7/fts_00000000000005c4_deleted | NULL |
| db7/fts_00000000000005c4_deleted_cache | NULL |
+---------------------------------------------------+------------------+全文索引机制:
全文索引采用了反向索引(Inverted index)设计。反向索引存储单词列表,对于每个单词,存储该单词出现的文档列表。为了支持邻近搜索,每个单词的位置信息也以字节偏移量的形式存储。
这里提到了反向索引:
反向索引:根据关键词反向得到该关键词的其它所有信息,比如该关键词所在的文件,在文件里出现的次数和行数等,这些信息就是用户查找该关键词时所要用的信息.
举个例子:
#用不同的数字索引不同的句子(比如以下三句在文本中是按照0,1,2的顺序排列的)0 : "I love you"
1 : "I love you too "
2 : "I dislike you"
#如果要用单词作为索引,而句子的位置作为被索引的元素,那么索引就发生了倒置:"I" : {0,1,2}
"love" : {0, 1}
"you" : {0,1,2}
"dislike" : {2}
#如果要检索 "I dislike you" 这句话,那么就可以这么计算 : {0,1,2} 交集 {0,1,2}交集 {2} 这样就比较好理解了。
2. InnoDB全文索引DOC_ID和FTS_DOC_ID列
InnoDB使用一个称为DOC_ID的唯一文档标识符来将全文索引中的单词映射到该单词出现的文档记录中。映射需要索引表上的FTS_DOC_ID列。如果没有定义FTS_DOC_ID列,InnoDB会在创建全文索引时自动添加一个隐藏的FTS_DOC_ID列。
mysql> CREATE TABLE opening_lines (id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,opening_line TEXT(500),author VARCHAR(200),title VARCHAR(200)) ENGINE=InnoDB;
Query OK, 0 rows affected (0.03 sec)
mysql> CREATE FULLTEXT INDEX idx ON opening_lines(opening_line);
Query OK, 0 rows affected, 1 warning (0.26 sec)
Records: 0 Duplicates: 0 Warnings: 1mysql> show warnings;
+---------+------+--------------------------------------------------+
| Level | Code | Message |
+---------+------+--------------------------------------------------+
| Warning | 124 | InnoDB rebuilding table to add column FTS_DOC_ID |
+---------+------+--------------------------------------------------+
1 row in set (0.00 sec)InnoDB创建一个隐藏的FTS_DOC_ID列,并在FTS_DOC_ID列上创建一个唯一索引(FTS_DOC_ID_INDEX)。如果你想创建自己的FTS_DOC_ID列,列必须定义为BIGINT UNSIGNED NOT NULL,并命名为FTS_DOC_ID(全大写),并且以避免空值或重复值, 不能重用FTS_DOC_ID值。
mysql> CREATE TABLE `opening_lines` (`FTS_DOC_ID` bigint unsigned NOT NULL AUTO_INCREMENT,`opening_line` text COLLATE utf8mb4_bin,`author` varchar(200) COLLATE utf8mb4_bin DEFAULT NULL,`title` varchar(200) COLLATE utf8mb4_bin DEFAULT NULL,PRIMARY KEY (`FTS_DOC_ID`)
) ENGINE=InnoDB;mysql> CREATE UNIQUE INDEX FTS_DOC_ID_INDEX on opening_lines(FTS_DOC_ID);除此之外FTS_DOC_ID_INDEX不能定义为降序索引,因为InnoDB SQL解析器不使用降序索引。
为了避免重新构建表,在删除全文索引时保留FTS_DOC_ID列
插入文档时,将对其进行标记,并将单个单词和相关数据插入全文索引。这个过程,即使对于小文档,也可能导致大量的小插入到辅助索引表中,使对这些表的并发访问成为争用点。为了避免这个问题,InnoDB使用全文索引缓存来临时缓存最近插入的索引表。这个内存缓存结构保存插入,直到缓存满了,然后批量刷新到磁盘(到辅助索引表)
mysql> SELECT * FROMINFORMATION_SCHEMA.INNODB_FT_INDEX_CACHE;物理文件对应缓存:
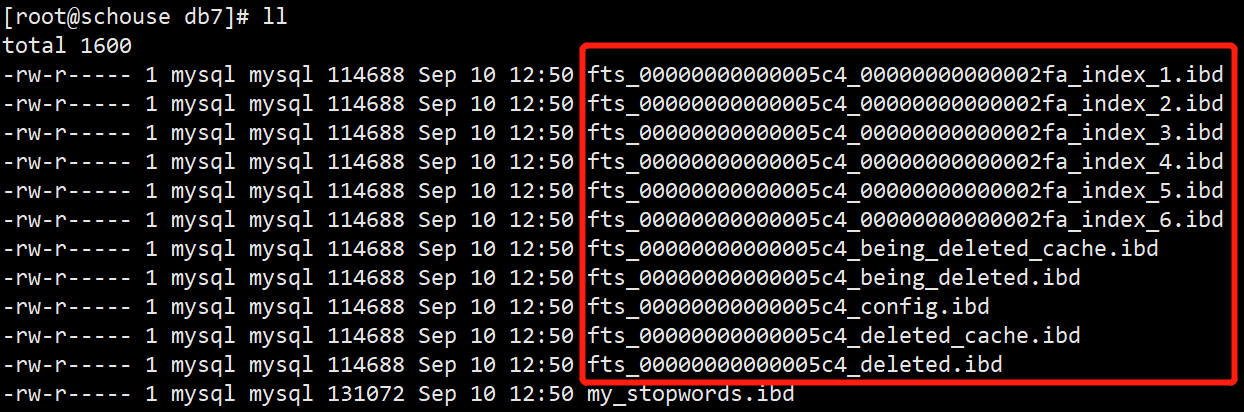
- 辅助索引表名以fts_为前缀,以index_#为后缀。Index_1~index_6前六个索引表组成了反向索引。当传入文档被标记化时,单个单词(也称为“标记”)将与位置信息和相关的DOC_ID一起插入索引表中。根据单词第一个字符的字符集排序权重,在六个索引表中对单词进行完全排序和分区。
反向索引被划分为的6个辅助索引表,以支持并行索引创建。通过innodb_ft_sort_pll_degree两个线程标记、排序并将单词和相关数据插入索引表。
mysql> show variables like 'innodb_ft_sort_pll_degree';
+---------------------------+-------+
| Variable_name | Value |
+---------------------------+-------+
| innodb_ft_sort_pll_degree | 2 |
+---------------------------+-------+
1 row in set (0.00 sec)-
fts_deleted and ftsdeleted_cache
包含已删除但其数据尚未从全文索引中删除的文档的文档id (DOC_ID)。ftsdeleted_cache是fts_deleted表的内存版本。 -
fts_being_deleted and ftsbeing_deleted_cache
包含被删除文档的文档id (DOC_ID),这些文档的数据目前正在从全文索引中删除。ftsbeing_deleted_cache表是fts_being_deleted表的内存版本。 -
fts_*_config
存储关于全文索引的内部状态的信息。最重要的是,它存储FTS_SYNCED_DOC_ID,用于标识已解析并刷新到磁盘的文档。在崩溃恢复的情况下,FTS_SYNCED_DOC_ID值用于标识尚未刷新到磁盘的文档,以便可以重新解析文档并将其添加回全文索引缓存
#系统内存表支持查询:
SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_CONFIG;缓存和批刷新行为避免了对辅助索引表的频繁更新,这可能会在繁忙的插入和更新期间导致并发访问问题。批处理技术还避免了对同一个单词的多次插入,并尽量减少重复条目。不是单独刷新每个单词,而是将相同单词的插入合并并作为单个条目刷新到磁盘,从而在保持辅助索引表尽可能小的同时提高插入效率。
innodb_ft_cache_size:变量用于配置全文索引缓存的大小(以每个表为基础),这将影响全文索引缓存刷新的频率。
innodb_ft_total_cache_size:变量为给定实例中的所有表定义一个全局全文索引缓存大小限制。
全文索引缓存存储与辅助索引表相同的信息。但是,全文索引缓存只缓存最近插入行的标记化数据。在查询时,已经刷新到磁盘(到辅助索引表)的数据不会返回到全文索引缓存中。直接查询辅助索引表中的数据,并在返回之前将辅助索引表的结果与来自全文索引缓存的结果合并。
删除具有全文索引列的记录可能导致辅助索引表中的大量小删除,使对这些表的并发访问成为争用点。为了避免这个问题,每当从索引表中删除一条记录时,已删除文档的DOC_ID将记录在一个特殊的FTS_DELETED表中,而已索引的记录将保留在全文索引中。在返回查询结果之前,使用FTS_DELETED表中的信息过滤掉已删除的doc_id。这种设计的好处是删除既快又便宜。缺点是删除记录后索引的大小不会立即减少。
要删除已删除记录的全文索引项,在索引表上使用innodb_optimize_fulltext_only= on命令执行OPTIMIZE TABLE命令重建全文索引
InnoDB全文索引由于其缓存和批处理行为而具有特殊的事务处理特征。具体来说,全文索引上的更新和插入是在事务提交时处理的,这意味着全文搜索只能看到提交的数据。全文搜索只在插入的行提交后返回结果。批量操作下,查询实时查询 有可能数据查不到,最终一致性。
- 全文索引只能用于InnoDB或MyISAM表,并且只能为CHAR、VARCHAR或TEXT列创建。
- MySQL提供了一个内置的全文ngram解析器,支持中文,日文和韩文(CJK),以及一个可安装的MeCab日文全文解析器插件。 “ngram全文解析器”和“MeCab全文解析器插件”
- FULLTEXT索引定义可以在创建表时在CREATE TABLE语句中给出,也可以稍后使用ALTER TABLE或CREATE index添加。
- 对于大型数据集,将数据加载到一个没有FULLTEXT索引的表中,然后在此之后创建索引,比将数据加载到一个已有FULLTEXT索引的表中要快得多。
- 分区表不支持全文搜索
全文索引三种类型查询方式
自然语言搜索将搜索字符串解释为自然人类语言中的短语(自由文本中的短语)。除了双引号(")字符外,没有特殊操作符。stopword列表应用。
a.所为stopword a is in or when 等等
中文的话前面这句话,“在”、“里面”、“也”、“的”、“它”、“为”这些词都是停止词。这些词因为使用频率过高,几乎每个语句基本都会有,所以搜索引擎开将这一类词语全部忽略掉。
mysql> SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_DEFAULT_STOPWORD;
+-------+
| value |
+-------+
| a |
| about |
| an |
| are |
。。。。。
| who |
| will |
| the |
| www |
+-------+
36 rows in set (0.00 sec)也可以自定义stopword,自主性比较高
mysql> CREATE TABLE my_stopwords(value VARCHAR(30)) ENGINE = INNODB;
mysql> INSERT INTO my_stopwords(value) VALUES ('Ishmael');
mysql> CREATE FULLTEXT INDEX idx ON my_stopwords(`value`);
mysql> SET GLOBAL innodb_ft_server_stopword_table = 'db7/my_stopwords';b.自然语言搜索,使用IN NATURAL LANGUAGE MODE修饰符时,MATCH()函数会针对文本集合执行字符串的自然语言搜索。
mysql> CREATE TABLE articles (id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,title VARCHAR(200),body TEXT,FULLTEXT (title,body)) ENGINE=InnoDB;
Query OK, 0 rows affected (0.08 sec)mysql> INSERT INTO articles (title,body) VALUES('MySQL Tutorial','DBMS stands for DataBase ...'),('How To Use MySQL Well','After you went through a ...'),('Optimizing MySQL','In this tutorial, we show ...'),('1001 MySQL Tricks','1. Never run mysqld as root. 2. ...'),('MySQL vs. YourSQL','In the following database comparison ...'),('MySQL Security','When configured properly, MySQL ...');mysql> SELECT * FROM articlesWHERE MATCH (title,body)AGAINST ('database' IN NATURAL LANGUAGE MODE);2. A boolean search
使用特殊查询语言的规则解释搜索字符串。字符串包含要搜索的单词。它还可以包含一些操作符,这些操作符指定了一些要求,例如某个单词必须在匹配的行中出现或不出现,或者该单词的权重应该高于或低于通常值。
mysql> SELECT * FROM articles WHERE MATCH (title,body)AGAINST ('+MySQL -YourSQL' IN BOOLEAN MODE);条件:
- stands for AND
- stands for NOT
除此之外 > < ( ) ~ * 等条件符号
查询扩展搜索是对自然语言搜索的修改。搜索字符串用于执行自然语言搜索。然后将搜索返回的最相关行的单词添加到搜索字符串中,并再次执行搜索。查询返回第二次搜索的行.
mysql>DROP TABLE IF EXISTS articles01;
mysql>CREATE TABLE articles01 (id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,title VARCHAR(200),FULLTEXT (title)) ENGINE=InnoDB;
mysql>INSERT INTO articles01 (title) VALUES('MySQL Tutorial'),('Optimizing Tutorial'),('analyze db');可以分为两个阶段:
一阶段:第一条sql语句直返回MySQL包含的数据,
mysql> SELECT * FROM articlesWHERE MATCH (title,body)AGAINST ('database' IN NATURAL LANGUAGE MODE);
+----+----------------+
| id | title |
+----+----------------+
| 1 | MySQL Tutorial |
+----+----------------+二阶段:QUERY EXPANSION是上述结果当中词汇,再次进行对应的查询。
WHERE MATCH (title,body)AGAINST ('database' WITH QUERY EXPANSION);
+----+---------------------+
| id | title |
+----+---------------------+
| 1 | MySQL Tutorial |
| 2 | Optimizing Tutorial |
+----+---------------------+就是使用结果集再次进行匹配。
解析器
全文解析提供两种解析方式:
- ngram解析器:
内置的MySQL全文解析器使用单词之间的空格作为分隔符,以确定单词的开始和结束位置,这在处理不使用单词分隔符的表意语言时是一个限制。为了解决这个问题,MySQL提供了一个支持中文、日文和韩文(CJK)的ngram全文解析器。5.7.6版本开始支持中文全文索引。
ngram是给定文本序列中的n个字符的连续序列。ngram解析器将文本序列标记为n个字符的连续序列。
比如:abcd字段
n=1: 'a', 'b', 'c', 'd'
n=2: 'ab', 'bc', 'cd'
n=3: 'abc', 'bcd'
n=4: 'abcd'
[mysqld]
ngram_token_size=2 (1~10)定义了拆分的单词。
比如 ‘abcd’ 采用n=2的方式 ‘ab’, ‘bc’, ‘cd’
‘a bc’ 就是 ‘bc’
“生日快乐” 中文就会拆分成 “生日”“快乐” 2个分词
对于中文来说确实挺麻烦的事情,直接1 就可以
- MeCab全文解析器
MeCab全文文本解析器插件是一个日文全文文本解析器插件,它将文本序列标记为有意义的单词。
除了将文本标记为有意义的单词外,MeCab索引通常比ngram索引更小,而且MeCab全文搜索通常更快。
缺点是与ngram全文解析器相比,MeCab全文解析器对文档进行标记需要更长的时间。
配置方式如下:
[mysqld]
loose-mecab-rc-file=MYSQL_HOME/lib/mecab/etc/mecabrc
innodb_ft_min_token_size=15. 参数
使用该功能就需要合理配置参数:

6. 总结
mysql的全文索引只有一种方法判断相关性,就是词频,索引并不会记录匹配的词在字符串中的位置。并且,全文索引和数据量有较大的关系,全文索引只会全部在内存中时,性能才会很好,因此当全文索引过大,不能全部读入进内存,性能就会比较差。
可以通过一下点,思考下全文索引的问题:
1、修改一段文本中的100个单词时,需要索引100次。
2、全文索引的长度对性能的影响也是巨大的
3、全文索引会产生更多的碎片,需要频繁的优化(optimize table)操作
4、内存和数据容量也是常可观,所以需要规划和参数控制这部分
5、因为mysql复制机制是基于逻辑复制,产生的binlog毕竟很大,那就会出现主从延迟等问题。
6、词分割(token_size)也是一个问题,单个汉字也能表达出不同的意思。
7、查询上:如果sql中包含match against,而索引列上又正好有全文索引,那么mysql就一定会使用全文索引,如果此时还有其他索引,mysql也不会去对比那个索引性能更高。
当然不管那个数据库都有局限性,合理使用采用DBA之道。