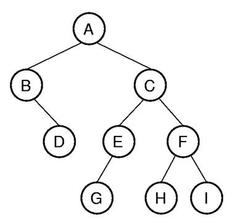
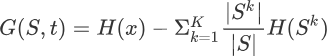简介
在信息论中,熵(entropy)是接收的每条消息中包含的信息的平均量,又被称为信息熵、信源熵、平均自信息量。
熵最好理解为不确定性的量度而不是确定性的量度,因为越随机的信源的熵越大。
比较不可能发生的事情,当它发生了,会提供更多的信息。
熵的单位通常为比特,但也用Sh、nat、Hart计量,取决于定义用到对数的底。
熵的概念最早起源于物理学,用于度量一个热力学系统的无序程度。在信息论里面,熵是对不确定性的测量。但是在信息世界,熵越高,则能传输越多的信息,熵越低,则意味着传输的信息越少。
英语文本数据流的熵比较低,因为英语很容易读懂,也就是说很容易被预测。即便我们不知道下一段英语文字是什么内容,但是我们能很容易地预测,比如,字母e总是比字母z多,或者qu字母组合的可能性总是超过q与任何其它字母的组合。如果未经压缩,一段英文文本的每个字母需要8个比特来编码,但是实际上英文文本的熵大概只有4.7比特。
消息的熵乘以消息的长度决定了消息可以携带多少信息。
熵的计算
如果有一枚理想的硬币,其出现正面和反面的机会相等,则抛硬币事件的熵等于其能够达到的最大值。我们无法知道下一个硬币抛掷的结果是什么,因此每一次抛硬币都是不可预测的。
因此,使用一枚正常硬币进行若干次抛掷,这个事件的熵是一比特,因为结果不外乎两个——正面或者反面,可以表示为0, 1编码,而且两个结果彼此之间相互独立。若进行n次独立实验,则熵为n,因为可以用长度为n的比特流表示。
但是如果一枚硬币的两面完全相同,那个这个系列抛硬币事件的熵等于零,因为结果能被准确预测。现实世界里,我们收集到的数据的熵介于上面两种情况之间。
定义
依据Boltzmann’s H-theorem,香农把随机变量X的熵值 Η(希腊字母Eta)定义如下,其值域为{x1, …, xn}:
H ( X ) = ∑ i P ( x i ) I ( x i ) = − ∑ i P ( x i ) log b P ( x i ) \mathrm{H} (X)=\sum _{{i}}{{\mathrm {P}}(x_{i})\,{\mathrm {I}}(x_{i})}=-\sum _{{i}}{{\mathrm {P}}(x_{i})\log _{b}{\mathrm {P}}(x_{i})} H(X)=i∑P(xi)I(xi)=−i∑P(xi)logbP(xi)
其中,P为X的概率质量函数(probability mass function),E为期望函数,而I(X)是X的信息量(又称为自信息)。I(X)本身是个随机变数。
当取自有限的样本时,熵的公式可以表示为:
H ( X ) = ∑ i P ( x i ) I ( x i ) = − ∑ i P ( x i ) log b P ( x i ) \mathrm{H} (X)=\sum _{{i}}{{\mathrm {P}}(x_{i})\,{\mathrm {I}}(x_{i})}=-\sum _{{i}}{{\mathrm {P}}(x_{i})\log _{b}{\mathrm {P}}(x_{i})} H(X)=i∑P(xi)I(xi)=−i∑P(xi)logbP(xi)
在这里b是对数所使用的底,通常是2,自然常数e,或是10。当b = 2,熵的单位是bit;当b = e,熵的单位是nat;而当b = 10,熵的单位是Hart。
pi = 0时,对于一些i值,对应的被加数0 logb 0的值将会是0,这与极限一致。
lim p → 0 + p log p = 0 \lim_{p\to0+}p\log p = 0 p→0+limplogp=0
还可以定义事件 X 与 Y 分别取 xi 和 yj 时的条件熵为
H ( X ∣ Y ) = − ∑ i , j p ( x i , y j ) log p ( x i , y j ) p ( y j ) {\displaystyle \mathrm {H} (X|Y)=-\sum _{i,j}p(x_{i},y_{j})\log {\frac {p(x_{i},y_{j})}{p(y_{j})}}} H(X∣Y)=−i,j∑p(xi,yj)logp(yj)p(xi,yj)
其中p(xi, yj)为 X = xi 且 Y = yj 时的概率。这个量应当理解为你知道Y的值前提下随机变量 X 的随机性的量。
熵为什么用 log 来计算?
H ( X ) = ∑ i P ( x i ) I ( x i ) = − ∑ i P ( x i ) log b P ( x i ) \mathrm{H} (X)=\sum _{{i}}{{\mathrm {P}}(x_{i})\,{\mathrm {I}}(x_{i})}=-\sum _{{i}}{{\mathrm {P}}(x_{i})\log _{b}{\mathrm {P}}(x_{i})} H(X)=i∑P(xi)I(xi)=−i∑P(xi)logbP(xi)
信息熵=事件发生概率*事件携带的信息量
信息的量化应该遵循:
- 信息是非负的
- 如果一件事物发生的概率是1(没有选择的自由度),信息量为0。(越确定的事件越不混乱)
- 如果两件事物的发生是独立的(联合概率),它们一起发生时我们获得的信息是两者单独发生的信息之和。
- 信息的度量应该是概率的函数,函数最好是单调连续的。
香农发现 lnx, x∈[0,1] 符合以上要求

事件携带的信息量 I(xi)
I ( x i ) = − l o g b P ( x i ) {\mathrm {I}}(x_{i})=-log _{b}{\mathrm {P}}(x_{i}) I(xi)=−logbP(xi)
再结合“一件事物发生概率为0时,信息量也为0”,我们可以获得(变量X的)信息熵的完整定义形式:
H ( X ) = ∑ i P ( x i ) I ( x i ) = − ∑ i P ( x i ) log b P ( x i ) \mathrm{H} (X)=\sum _{{i}}{{\mathrm {P}}(x_{i})\,{\mathrm {I}}(x_{i})}=-\sum _{{i}}{{\mathrm {P}}(x_{i})\log _{b}{\mathrm {P}}(x_{i})} H(X)=i∑P(xi)I(xi)=−i∑P(xi)logbP(xi)
参考文献:
[1]https://zh.wikipedia.org/wiki/%E7%86%B5_(%E4%BF%A1%E6%81%AF%E8%AE%BA)
[2]信息为什么还有单位,熵为什么用 log 来计算? - 勃起床的回答 - 知乎
https://www.zhihu.com/question/310100965/answer/1219472348
[3]https://www.cnblogs.com/fm-yangon/p/14073664.html