导读
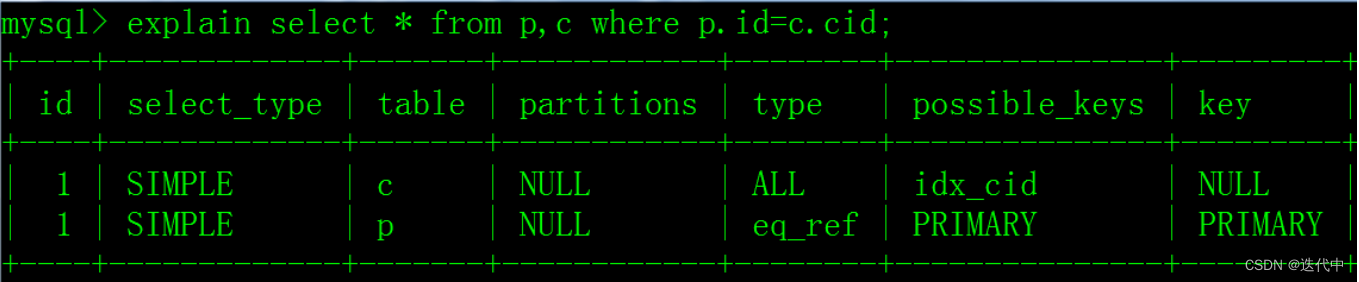
数据开发过程中,开发完成的 SQL 发布到生产环境,经常会发生 SQL 执行慢甚至根本无法执行,如何避免这种情况呢?这一篇我们分析一下 SQL Server 的执行计划是如何生成及如何阅读评估执行计划。
基本概念
在此之前,我们先了解以下几个概念,方便我们理解。
本文中的 SQL 语句案例以及执行计划均使用 SQL Server 2017 版本自带的 AdventureWorksDW 样例数据库。
索引
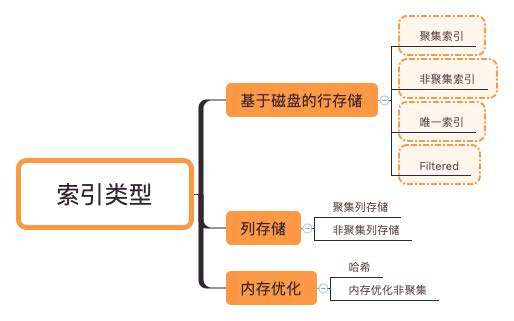
索引本质上就是一种帮助数据库高效获取数据的数据结构,比如 B 树树索引使用二分查找法查找,检索一条记录的复杂度是 O(LogN)。但是这也不意味着索引越多越好,维护索引同样会影响写入性能,需要根据实际情况平衡数据写入的读写性能。索引是基于数据库表创建的,包含一个表中的某些列的值以及记录对应的地址,并且把这些值存储在一个数据结构中。常见的就是使用哈希表,B+ 树,SQL Server 中使用的就是 B+ 树。SQL Server 提供了如下集中索引类型。
执行计划
执行计划也称为“查询计划”或者”执行计划“,是 SQL 语句的执行方式,由查询优化器根据数据库中表和索引的定义以及数据库统计信息,为 SQL 语句选择的最高效的数据访问方式,然后交给执行器去执行。
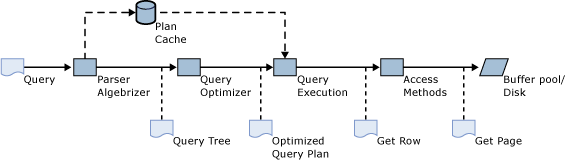
执行计划缓存
SQL Server 提供了一个用于存储执行计划和数据缓冲区的内存池,内存池中中用于存储执行计划的部分称为计划缓存。SQL Server 中执行任何 TSQL 语句时,数据库引擎首先查看计划缓存,确认是否存在同一个 TSQL 语句的现有执行计划。SQL Server 会重用找到的任何现有计划,节省重新编译 TSQL 语句的开销。如果没有执行计划,则为查询生成新的执行计划。
既然是缓存,执行计划何时会从缓存中删除呢?当存在内存不足, SQL Server 使用基于开销的方法确定从计划缓存中删除哪些执行计划。如果内存不足,SQL Server 会重复检查执行计划,直至删除了足够多的执行计划。
重新编译执行计划
执行计划会在某些情况下导致无效, SQL Server 检测到使执行计划无效的更改后,将执行计划标记为无效。此后,SQL Server 必须要下一个连接重新编译新的计划。
导致计划无效的情况有:
1),查询引用的表或者视图进行了更改;
2),存储过程的修改;
3),执行计划使用的索引有更改或删除;
4),执行计划使用的统计信息有更新,统计信息可以通过 update statistics 显式生成或者自动生成;
5),执行了 sp_recompile;
6),存储过程使用了 with recompile 选项;
执行计划重用不一定是一件好事,而编译/重编译也不一定是一件坏事。需要根据实际场景来判断是应该重用执行计划还是重编译执行计划。
如何显示执行计划
SSMS 提供了三种用于显示执行计划
1),估计执行计划,是编译的计划,由查询优化器根据估计生成。预估执行计划不等于实际执行计划,但是绝大多数情况下实际的执行计划跟预估执行计划都是一致的。统计信息变更或者执行计划重编译等情况下,可能会造成不同。
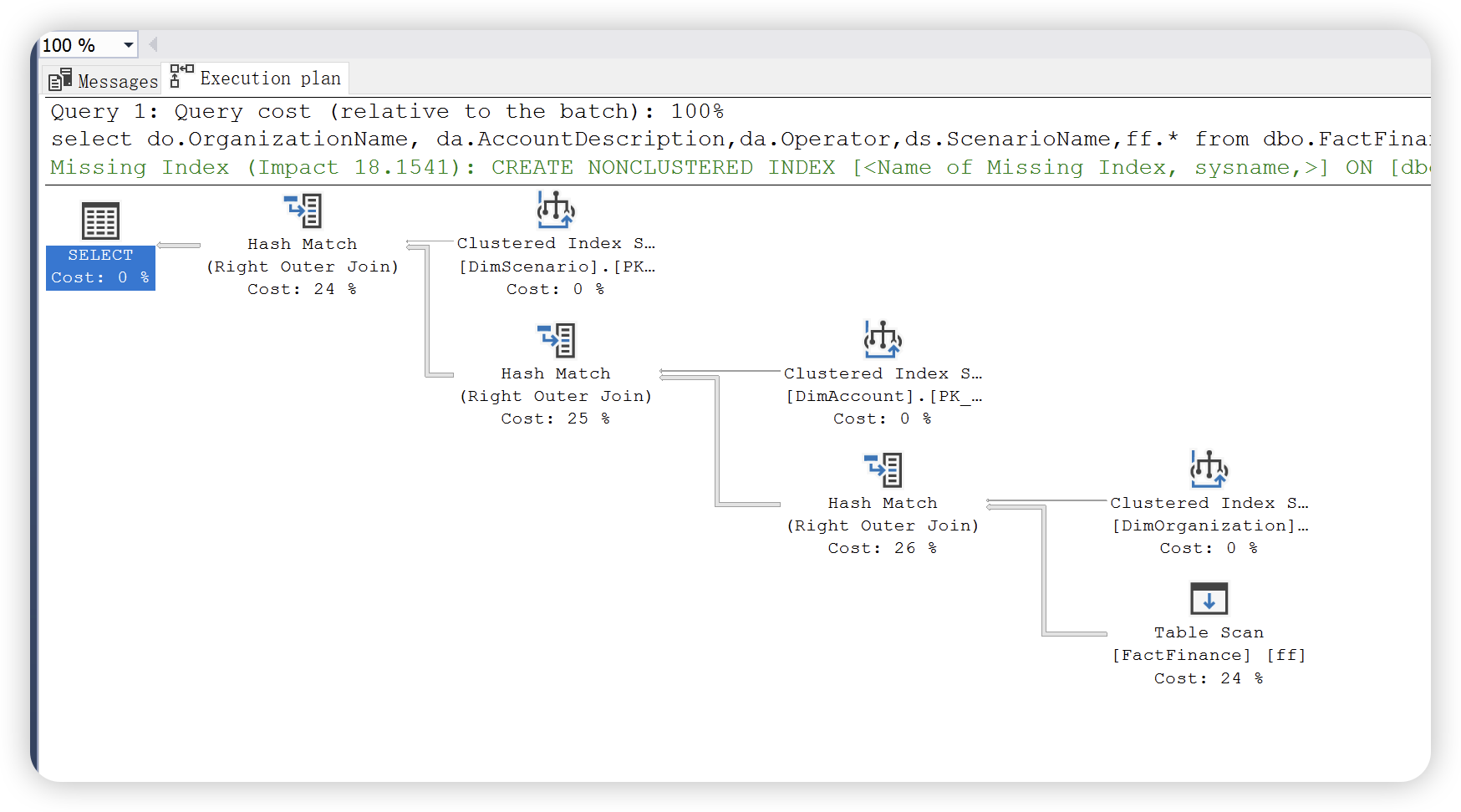
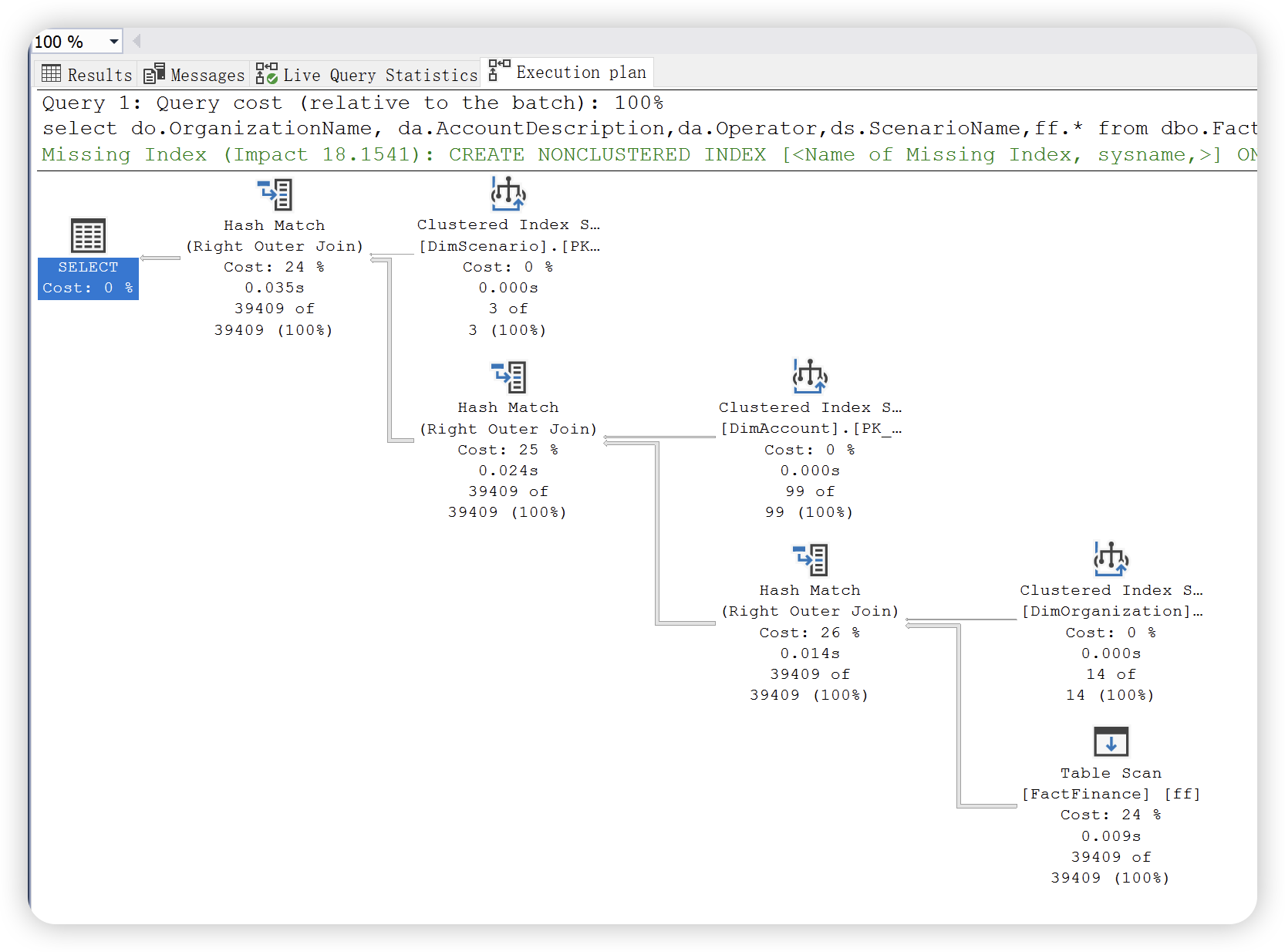
2),实际执行计划,是编译计划及其执行上下文,在执行 SQL 语句后出现,包括实际运行时信息。
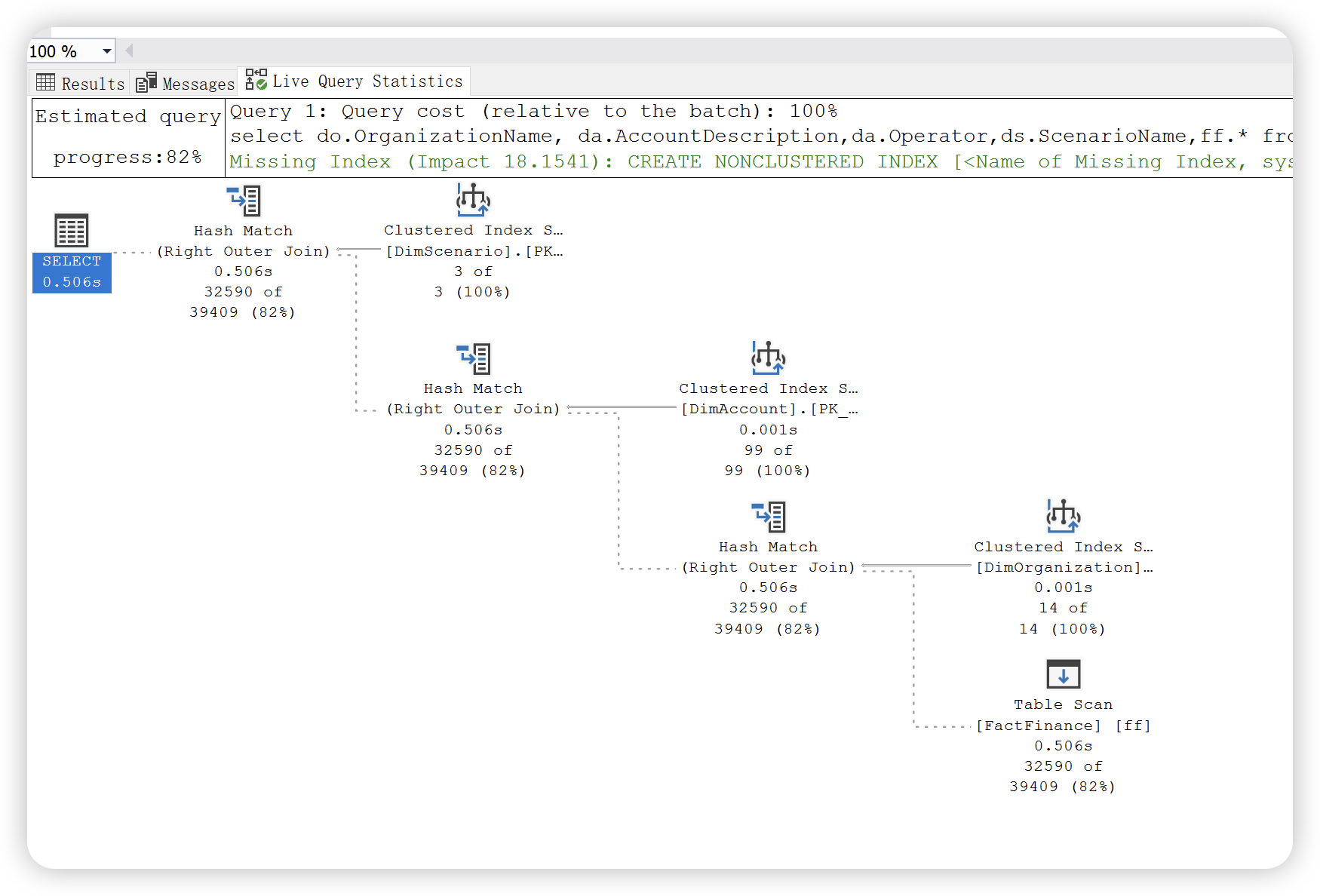
3),实时查询统计信息,与实际执行计划相同,包括编译的计划和执行上下文。可用于正在进行的查询执行,每个一秒更新一次。开销有可能比较大,不建议生产环境使用。下图中
基本法则
前置条件介绍完,现在正式进入主题。首先是执行计划的阅读方式,我们需要遵循一个基本法则: 自上向下,从右向左。同一行的执行计划步骤,右边的先执行。同一列的执行步骤,上边的先执行。
基本图形
在阅读执行计划之前我们有必要了解以下 SQL Server 图形执行计划中提供的基本图标的意义。
1),并行执行,如果给定的图形执行计划图标包含一个带有两个从右到左箭头的黄色圆圈,则表示运算符并行执行。
2),连线
运算符之间的连线表示运算符之间传递的方向和数据量。箭头的粗细表示传递的数据量多少。如下图中粗细箭头表示的数据量及其他详细信息如下所示,执行计划从右向左的箭头中的数据量同样可以反应数据查询扫描的行数与最后实际 SELECT 查询的行数差异。
细箭头
粗箭头
3),运算符详细信息
SQL Server 执行计划支持图形方式,文本和 XML 格式查看。本篇文章主要以图形化方式解析执行计划,查询计划由逻辑运算符组成的树表示,查询计划创建后,查询优化器会为每个逻辑运算符选择最有效的物理运算法,最后查询优化器使用基于开销的方法将逻辑运算法转化为物理运算符。SQL Server 使用到的逻辑运算符和物理运算符参考如下链接: SQL Server 图形执行计划图标。
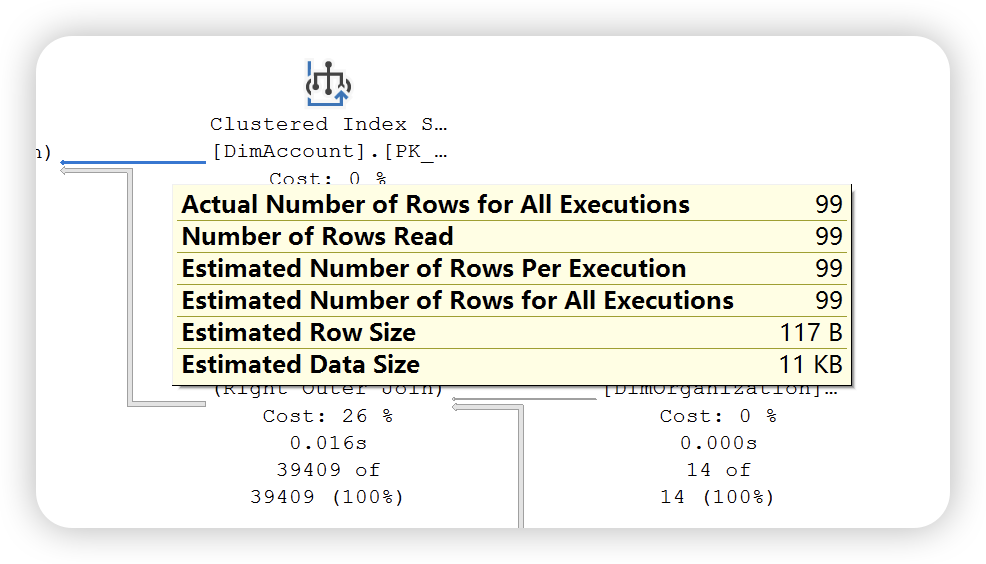
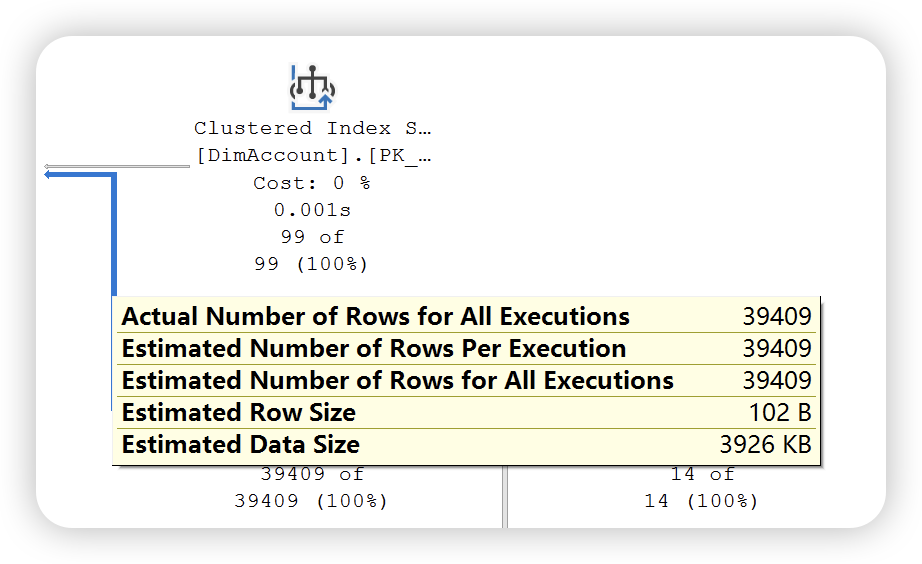
本篇内容主要介绍图形执行计划的阅读方法,根据上文介绍,SQL Server 提供了两种执行计划 —— 估计执行计划和实际执行计划。两种执行执行计划提供的运算符统计信息不同。如下图所示:
估计执行计划
实际执行计划
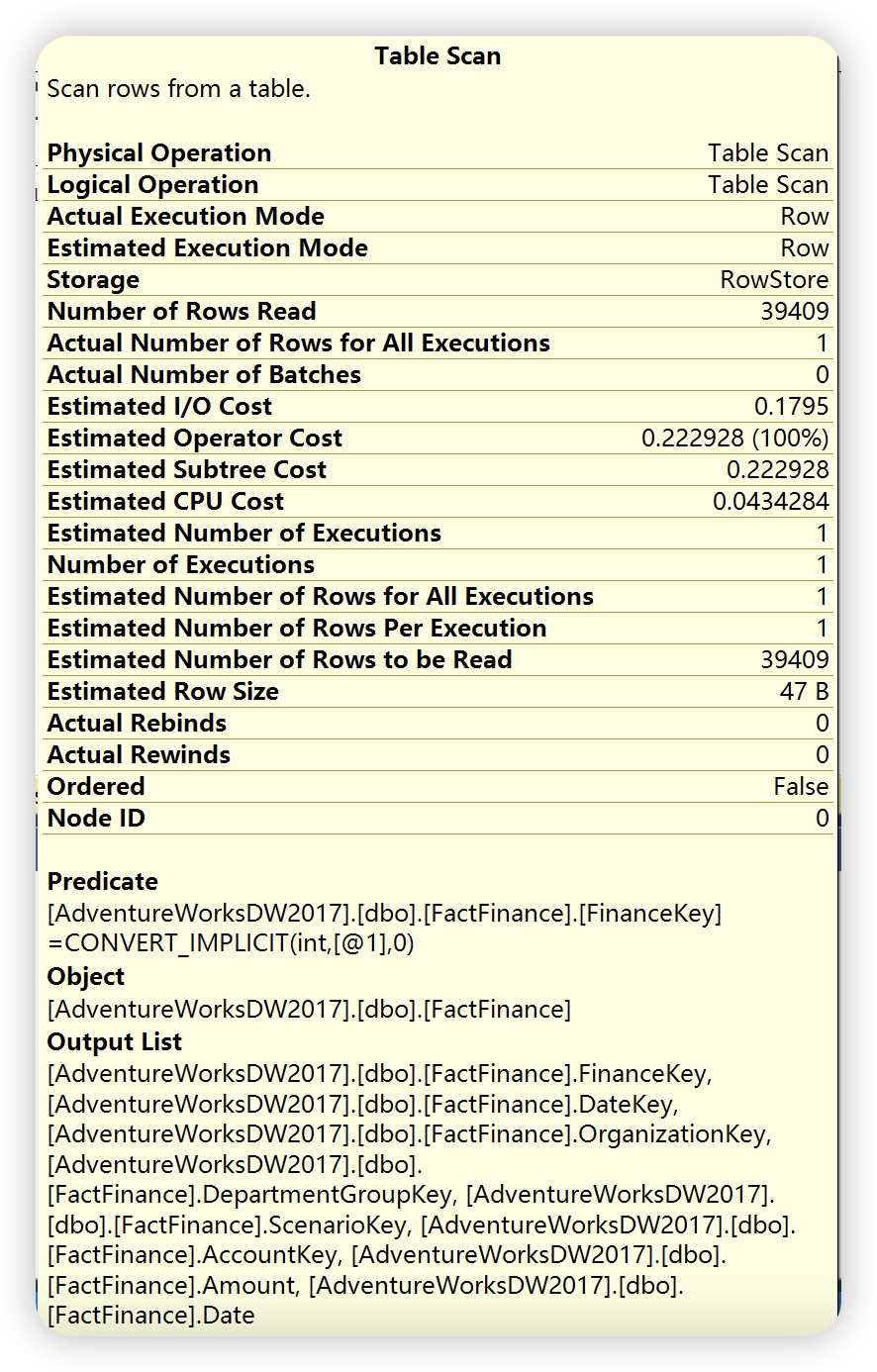
通过以上两幅执行计划统计信息图可以发现,实际执行计划除了提供估计执行计划统计信息之外,还提供了实际执行统计信息。这些数字不代表此运算符消耗的实际资源量,它代表 SQL Server 执行期间分配的估计成本。虽然不代表实际的资源量,但是这些信息有助于了解执行查询时内部发生的实际情况。大多数情况下,实际值和预估计是相同的,如果出现不一致的情况,可能的原因就是数据库表或者索引的统计信息已经过时,需要进行更新。
在上图中比较的执行计划统计信息图中还有使用的索引,检索列的列表,以及用于过滤该运算符中数据的条件信息。除了,还可以通过右键运算符 ——> 属性查看更详细的统计信息。
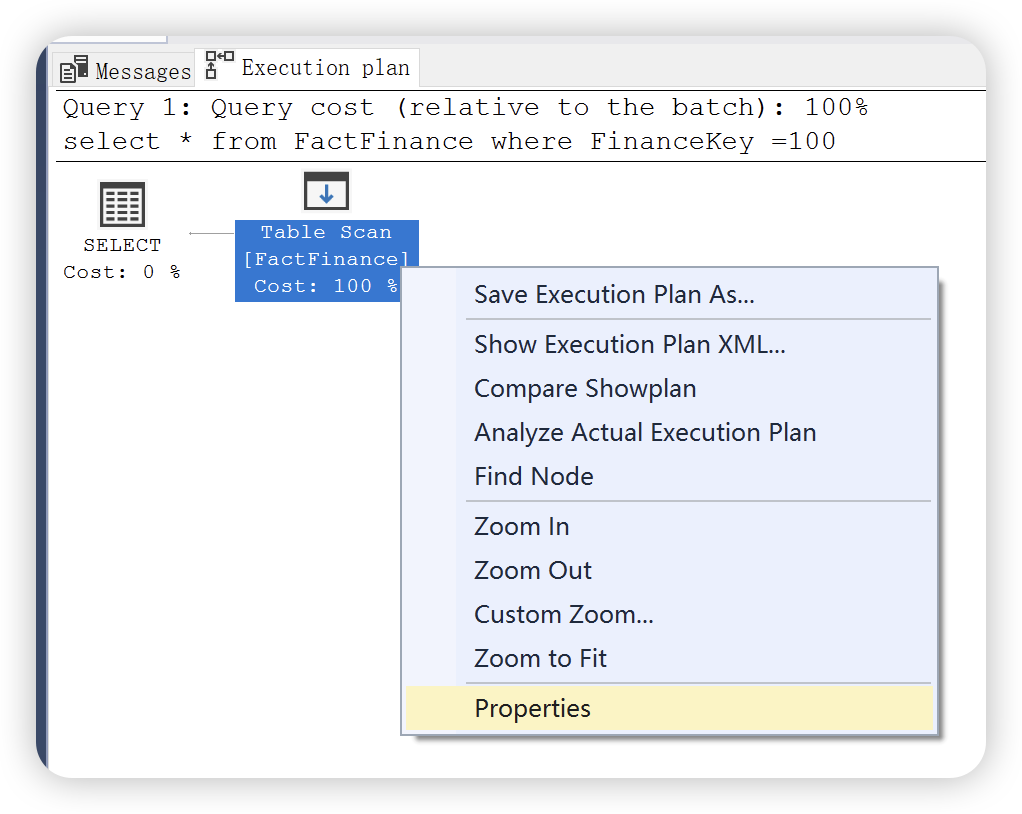
也可以选中运算符后,单击 F4,同样会显示运算符的属性窗口。
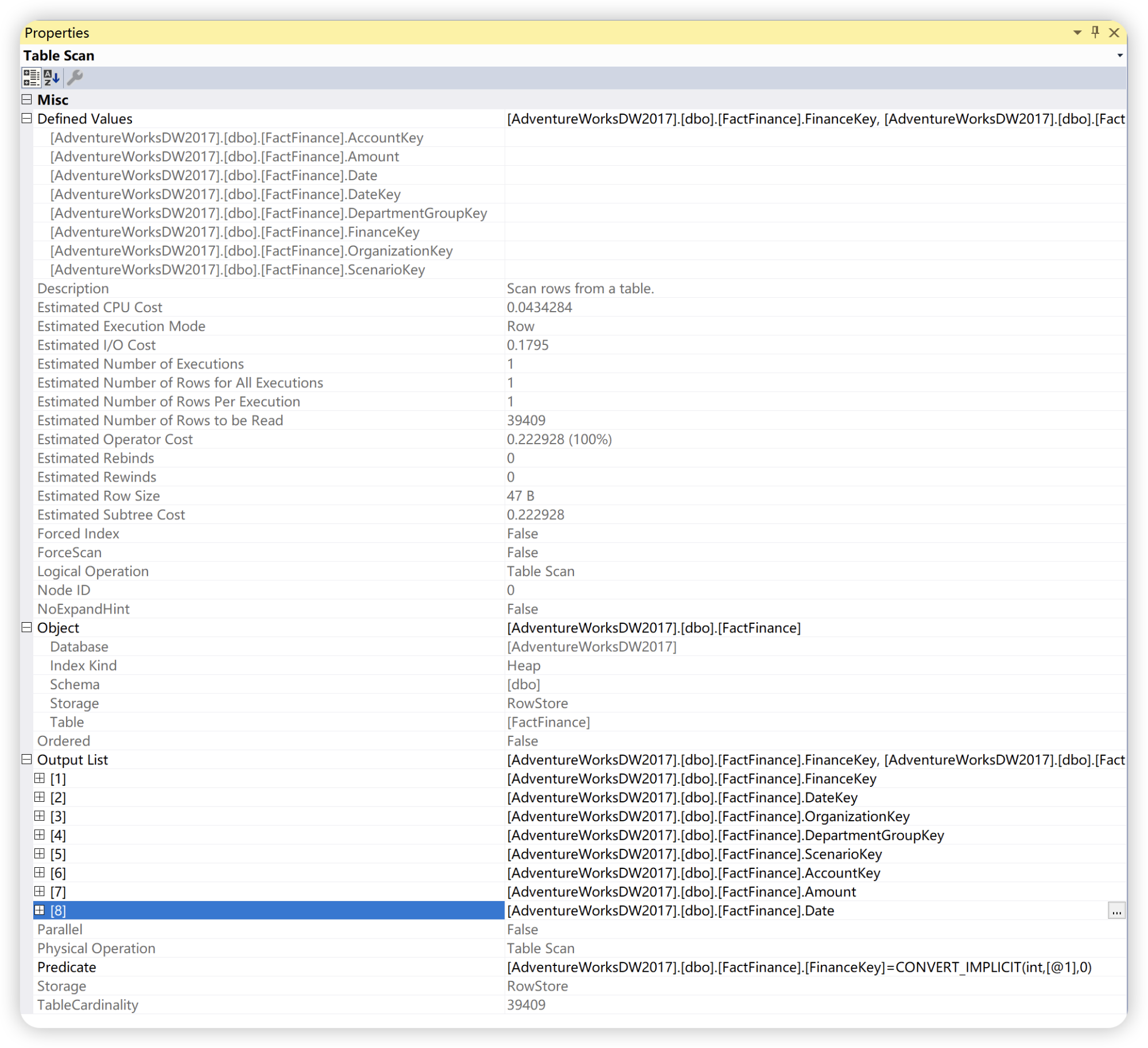
谓词
微软官方给的解释是:取值为 TRUE、FALSE 或 UNKNOWN 的表达式。 谓词用于 WHERE 子句和 HAVING 子句的搜索条件中,还用于 FROM子句的联接条件以及需要布尔值的其他构造中。
谓词常用语过滤数据。一般来说尽早地过滤数据,可以减少中间结果集的大小,减少后续计算需要处理的数据量。所以谓词下推是一个重要优化点,谓词下推主要作用就是尽可能下亚谓词,提前过滤部分数据。SQL Server 2017 版本中的查询优化器,会自动将谓词下推,将基于表或基于视图饿条件查询,经过查询优化后,将 where 条件下推到基本表进行过滤再进行关联,提高查询性能。
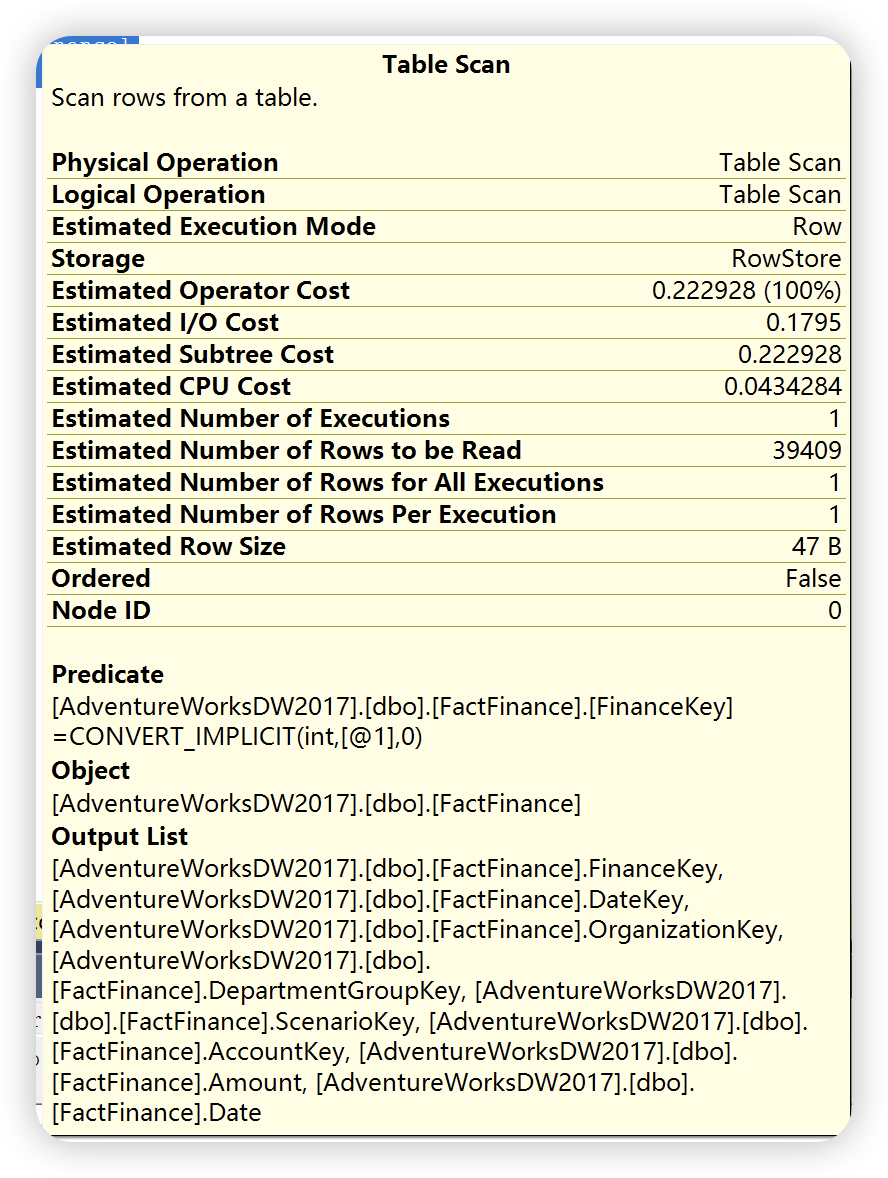
表扫描 Table Scan
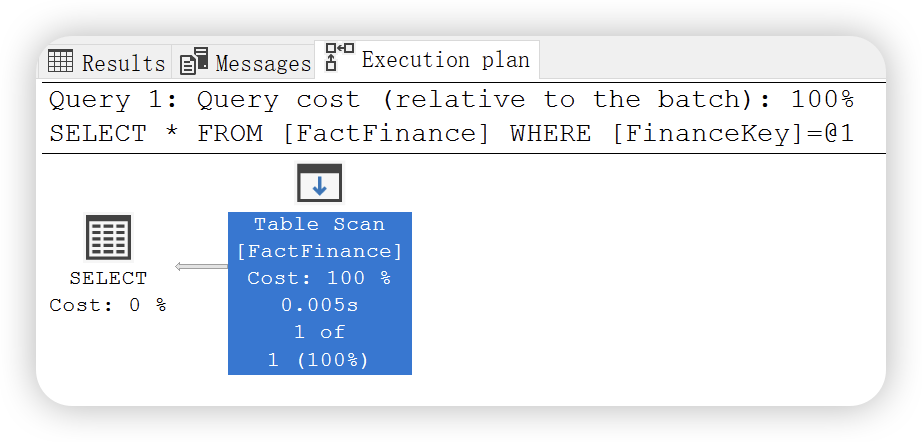
首先我们查询一张没有任何索引的事实表,如果表上面没有创建任何索引,表肯定是堆表。
堆是不含有聚集索引的表,可以在存储为堆的表上创建一个或者多个非聚集索引。数据存储在堆中并且无需指定顺序,因为是无序的,所以在向堆表中插入数据时是无法预测数据顺序的。如果要确保堆返回的数据行的顺序,需要指定 Order By 子句。或者通过创建聚集索引指定存储数据的永久逻辑顺序。如果某个表是堆并且不具有任何非聚集索引,则必须读取整个表(表扫描)以便找到任何行。堆表实际是一种数据结构,用于以逻辑结构存储表数据,后期文章会详细讲解堆表的数据结构。
select *
from FactFinance
where FinanceKey = 100;
执行计划如下:
聚集索引扫描
如果一个表含有聚集索引,称为聚集表,聚集表是 B 树结构,表数据按照聚集索引列排序,因为表数据只能有一种物理顺序,所以一个表只能有一个聚集索引。数据量大时,可以大幅减少读取次数。
select *
from dimcustomer
where firstname = 'Clarence'
如果选择一个存在聚集索引的表查询,执行计划是如何查找记录的的呢?此时会按照聚集索引扫描查找数据,根据执行计划的索引缺失提示,是因为 where 子句中数据过滤语句的字段不是聚集索引列,所以执行计划没有落到任何索引上,所以聚集索引扫描与表扫描相同。当表增加了聚集索引后,堆表就变成了聚集表,聚集表的数据存储在聚集索引的叶级节点。聚集索引何时才能够生效呢?
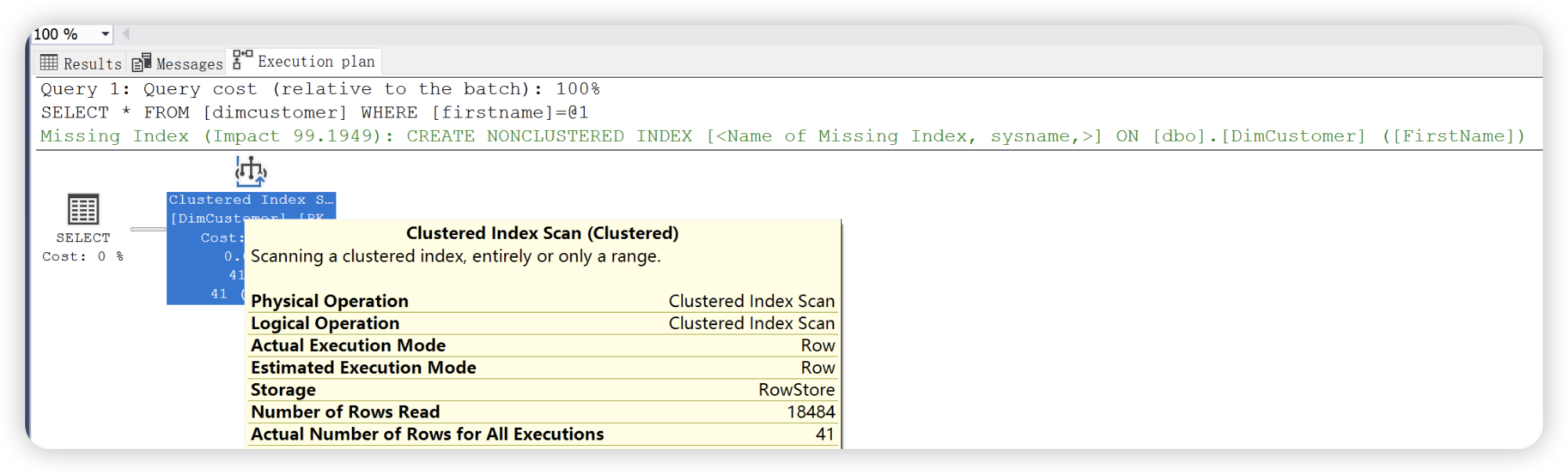
聚集索引查找
如果按照聚集索引列字段查找,执行计划则会按照聚集索引查找。
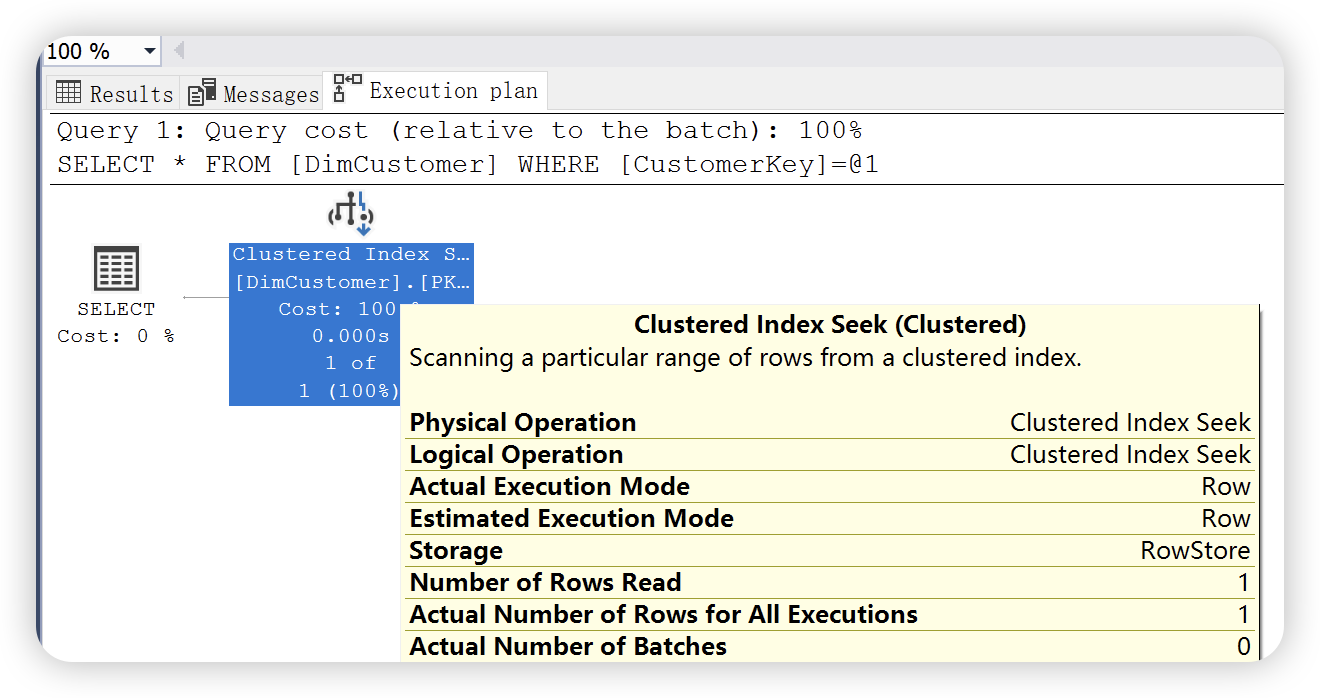
select *
from DimCustomer
where CustomerKey = 11018
聚集索引查找和聚集索引扫描两个运算符图标是不相同的,两种图形分别形象的代表了两种数据查找方法的不同。聚集索引查找是最快的数据查找方法。开发中,能使用聚集索引查找,则使用聚集索引查找。
索引扫描
根据以上几种数据扫描方式,假如我们创建的不是聚集索引,而是非聚集索引,执行计划会发生什么变化呢?
创建非聚集索引
create nonclustered index ix_firstname on dimcustomer(firstname);
在表上为 firstname 创建索引后,此时按照如下语句查询全表,执行计划会按照哪种数据扫描方式查询数据呢?
select *
from dimcustomer
执行计划如下,依然使用的是聚集索引扫描 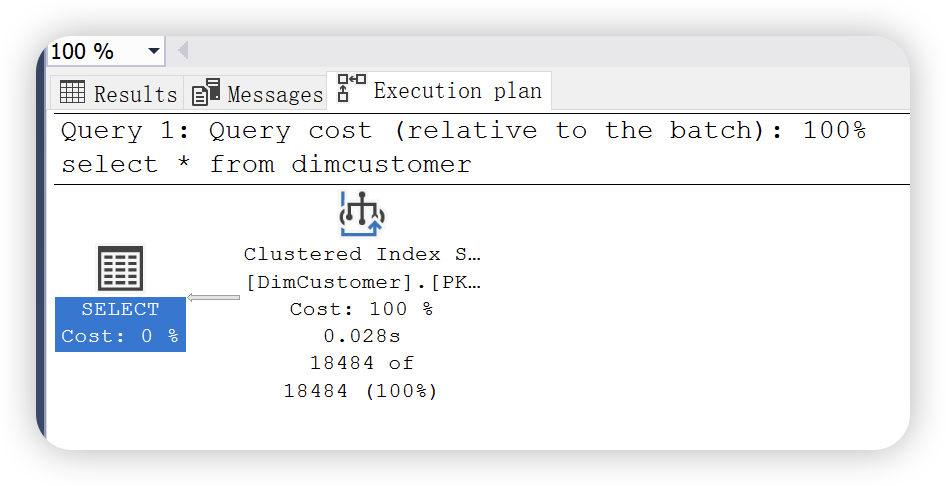
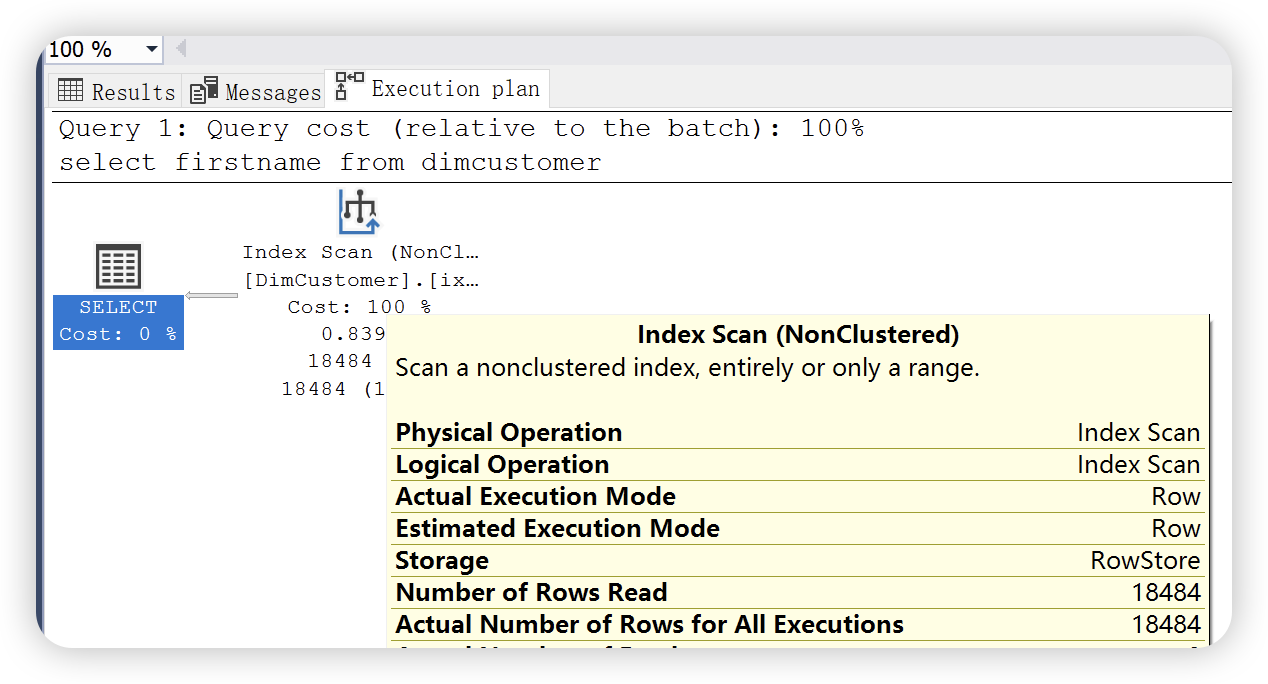
修改查询语句,只查询一列 firstname
select firstname
from dimcustomer
执行计划会不会走索引扫描呢?非聚集索引能够覆盖所需要的数据,所以执行了非聚集索引扫描。
索引查找
再次修改上面的查询语句,增加查询条件,根据 firstname 查找某个人
select firstname
from dimcustomer
where firstname = 'Clarence'
因为 firstname 是非聚集索引列,此时 firstname 作为查询条件,执行计划就会按照索引查找读取数据记录。执行计划如下图:
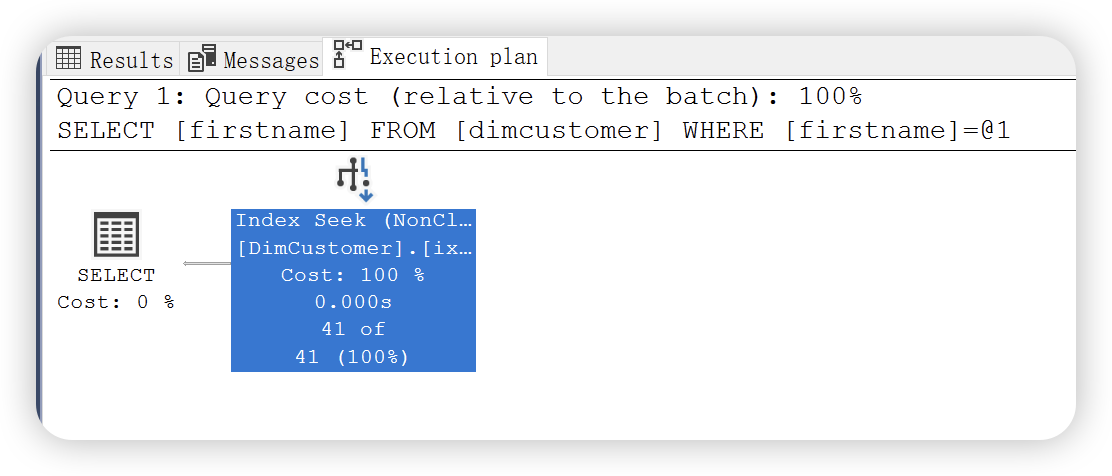
键值查找运算符
我们在聚集索引表上创建了一个含有 firstname 的非聚集索引,如果需求变化了,不仅仅需要读取 firstname,需要读取所有字段,执行计划又会发生什么呢?
select *
from dimcustomer
where firstname = 'Clarence'
此时出现了连三个运算符,分别是上面的索引查找,Key Lookup(键值查找运算符) 和 Nested Loops ( 嵌套循环运算符 )。
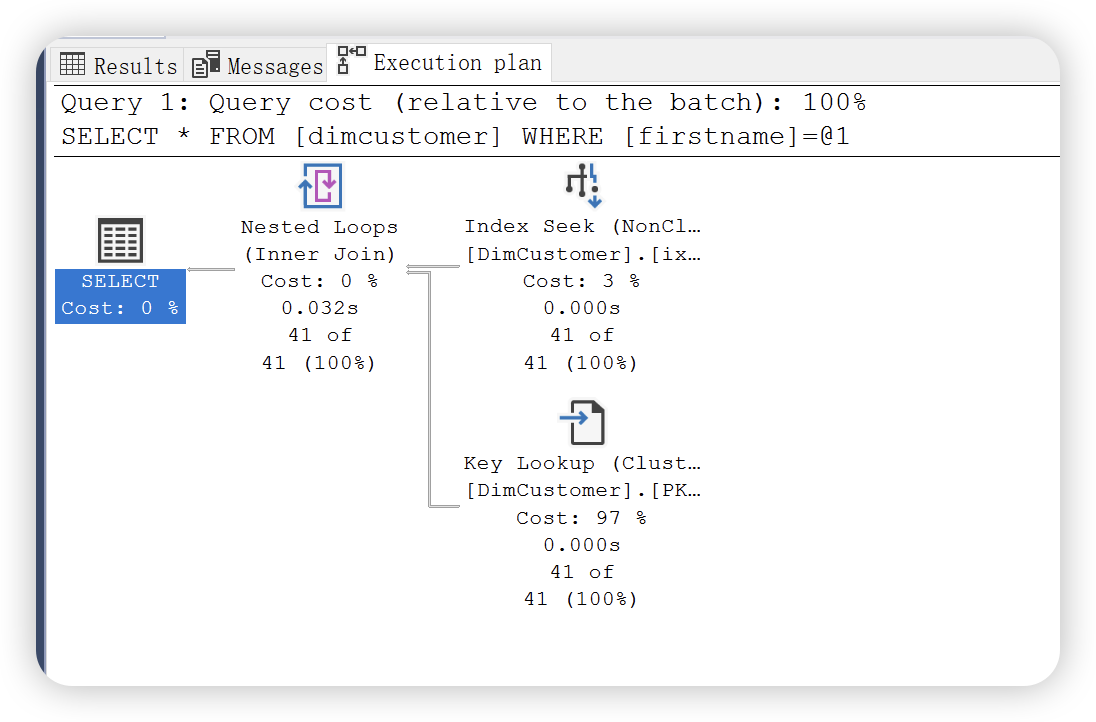
SQL Server 为何会使用这种查找方式呢?根据执行计划基本原则,从上向下,从右向左。SQL Server 首先对非聚集索引执行了查找,但是非聚集索引上无法获取除 firstname 外的其余列。因此,SQL Server 使用非聚集索引上的数据指针来获取其余数据,因为该表存在聚集索引,所以该表是聚集表。所以通过键值查找在聚集索引上的非聚集索引不包含的列。
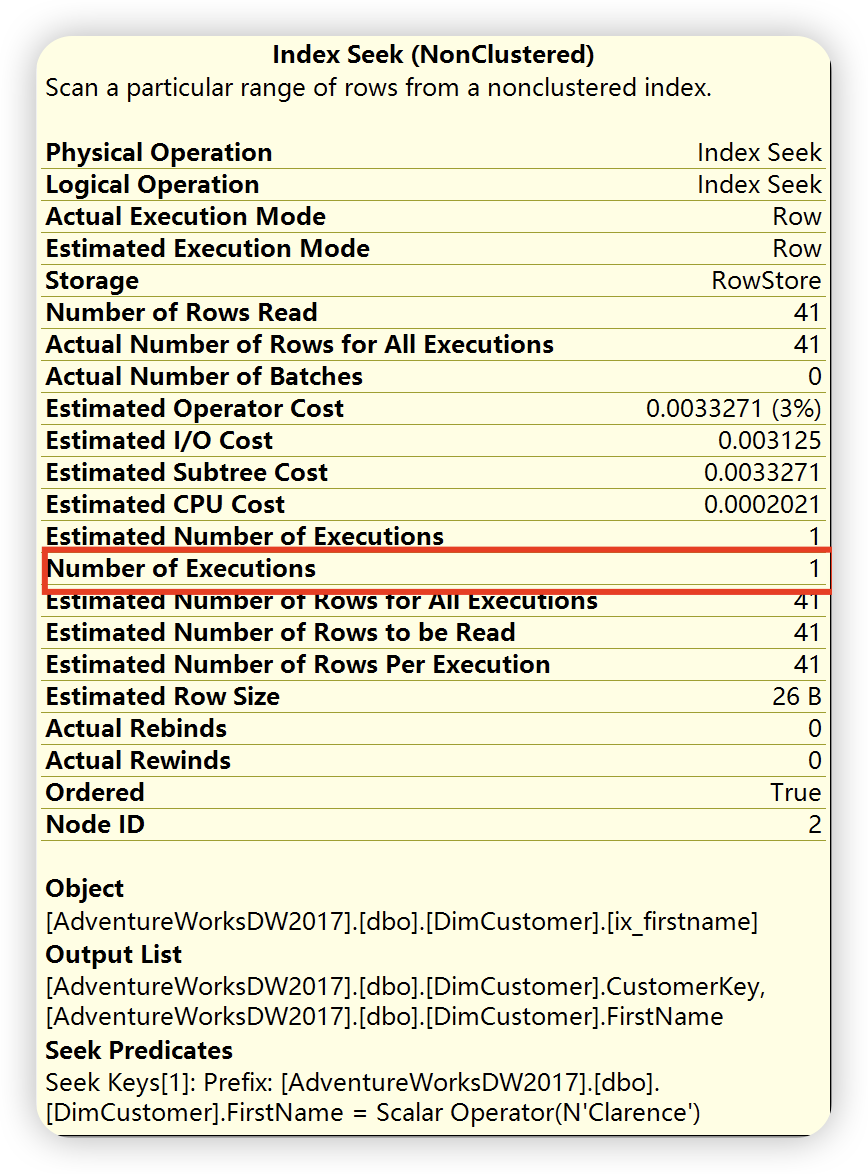
1),索引查找输出列
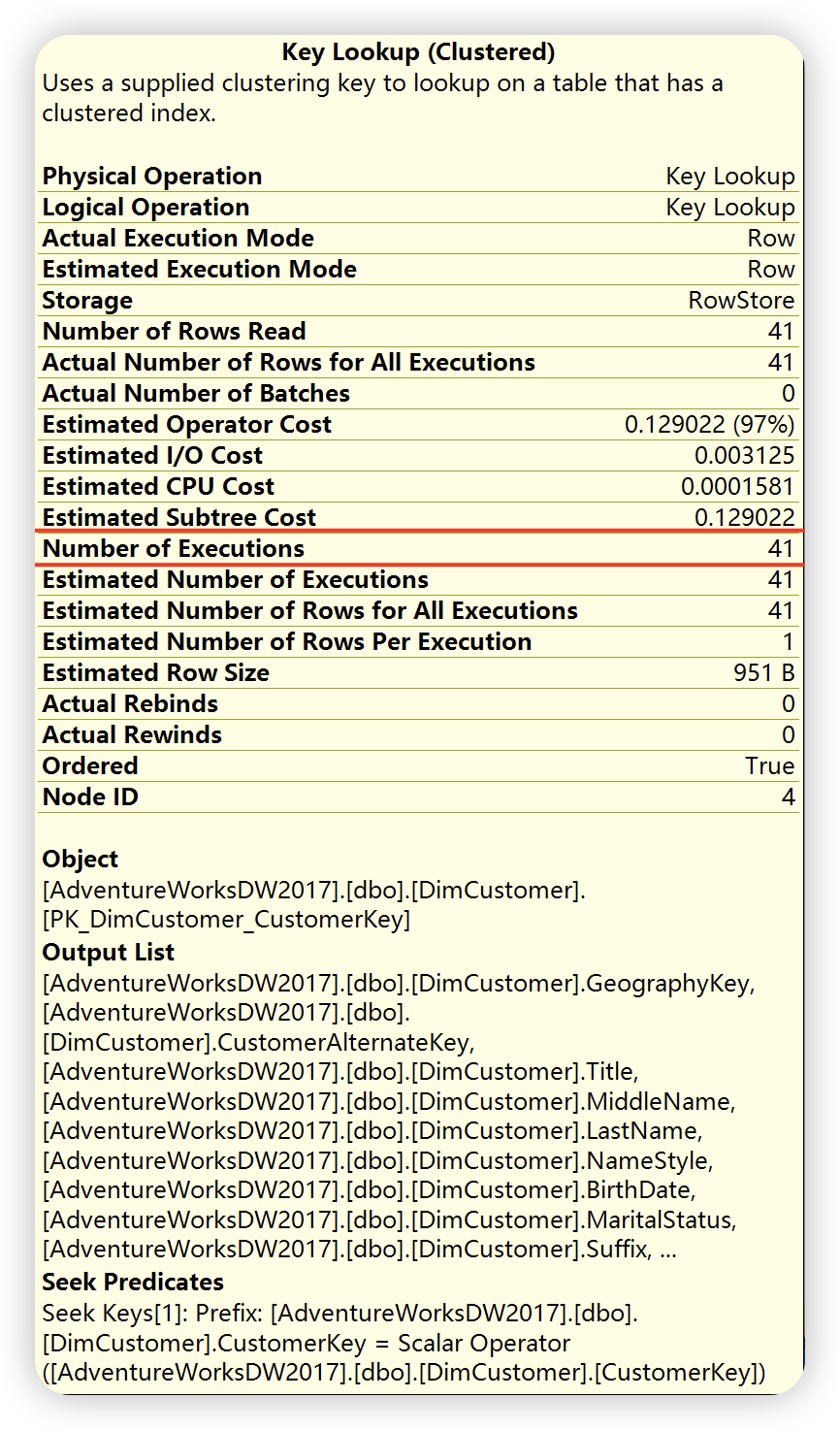
2),键值查找输出列
嵌套循环
嵌套循环( Nested Loop ),根据如下详细信息描述,位于上面的外部输入,也就是第1)部索引查找,和位于下面的内部输入( 第2步的内部输入,也就是键值查找 ),外部输入仅仅执行一次,根据外部输入满足关联条件的每一行,对内部输入进行查找,对内部输入进行查找,这里执行41此。()
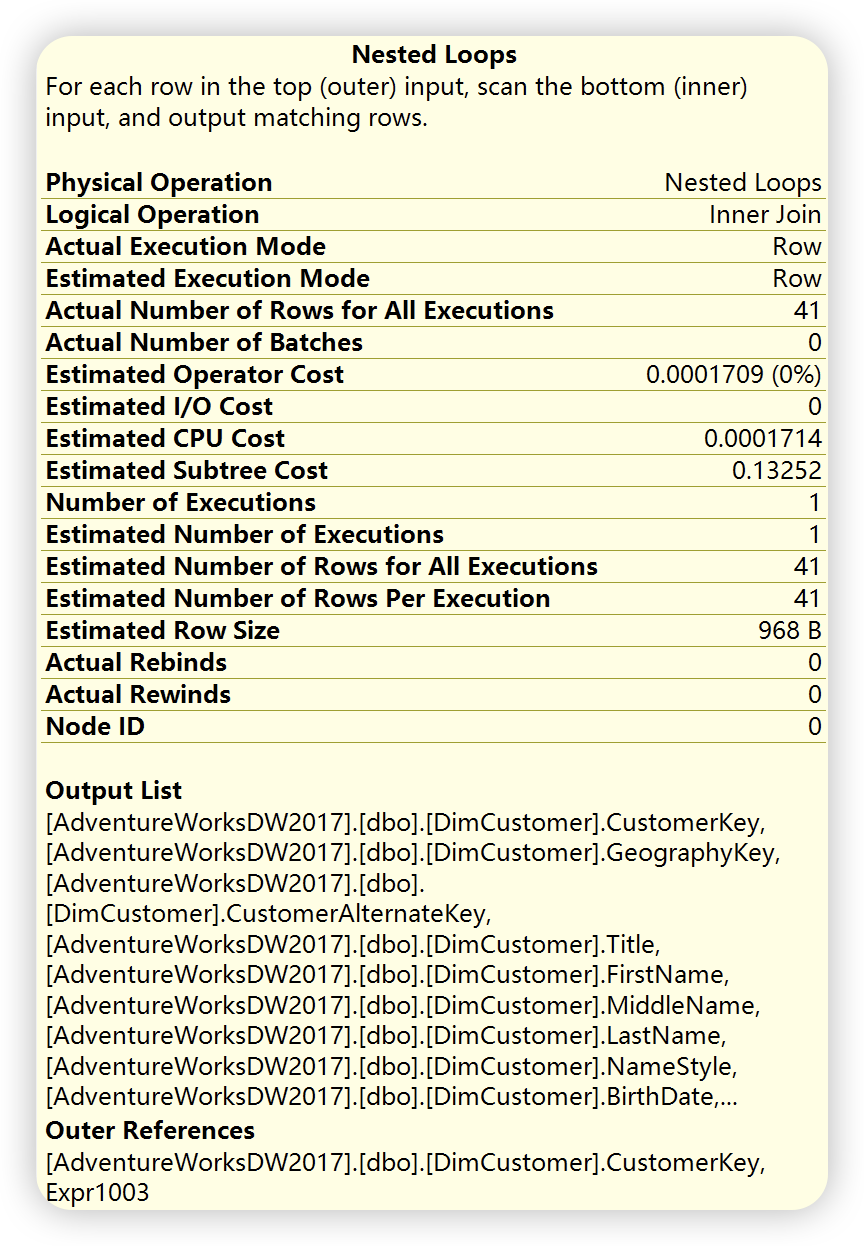
根据以上分析,外部输入数据量较小,内部输入数据量相对较大,而且内部输入上已经创建了聚集索引,查询优化器选择了嵌套循环连接。嵌套循环连接也称为”嵌套迭代“,类似于下面的伪代码。嵌套循环比较适用于小数据量或者小事务中使用。
for(row r1 in outer table)
for(row r2 in inner table)
if( r1, r2 符合匹配条件 )
output(r1, r2);
合并连接
尝试如下 SQL,以 CustomerKey 内连接事实表和维度表,该关联字段在维度表上建有聚集索引,
select *
from FactInternetSales fis
inner join dimcustomer dc
on dc.CustomerKey = fis.CustomerKey
执行计划如下:
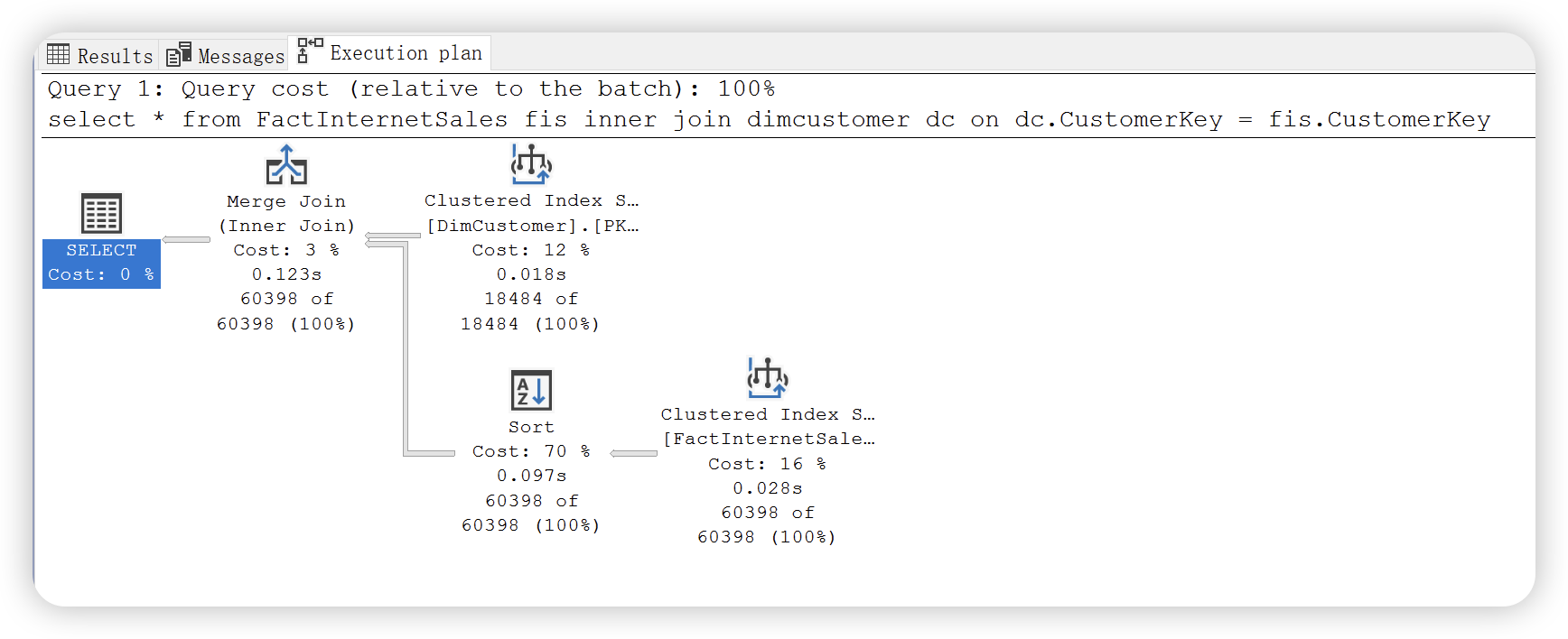
合并连接是从每个输入仅仅执行一次访问,因此比嵌套循环连接要快一些,只有当两个输入都是大数据量的情况下,此时合并链接的性能与哈希连接性能相近;但是如果两个输入数据量差异较大,哈希连接会由于合并链接。合并连接要求输入都是有序的,并且关联条件为等号,此时由于维度表 CutomerKey 的聚集索引为有序的,通过该字段与事实表关联后,SQL Server 为另一个输入增加了 Sort 操作符对另一个输入进行排序,最后选择合并排序。
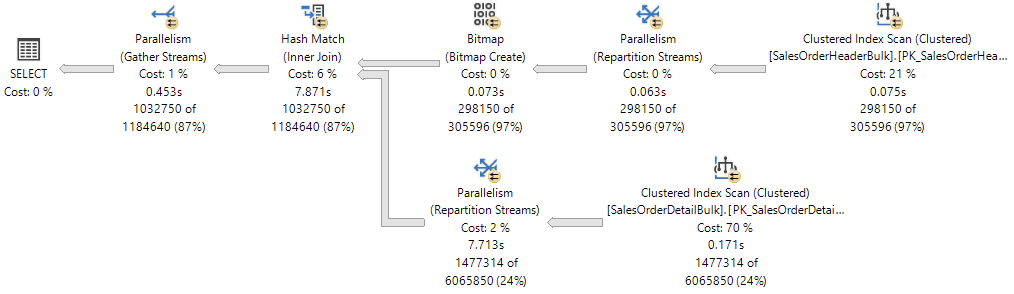
哈希连接
我们执行如下 SQL 查询事实表与维度表。
select do.OrganizationName,ff.*
from dbo.FactFinance ff
left join DimOrganization do
on do.OrganizationKey = ff.OrganizationKey
where ff.Date > '2010-10-10';
执行计划如下:
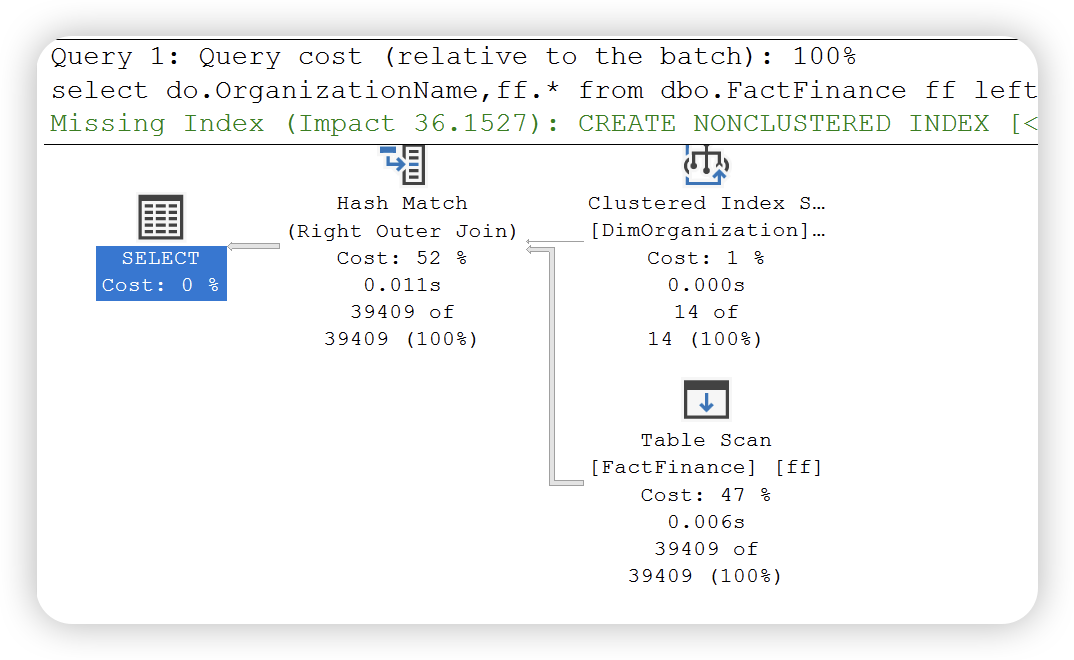
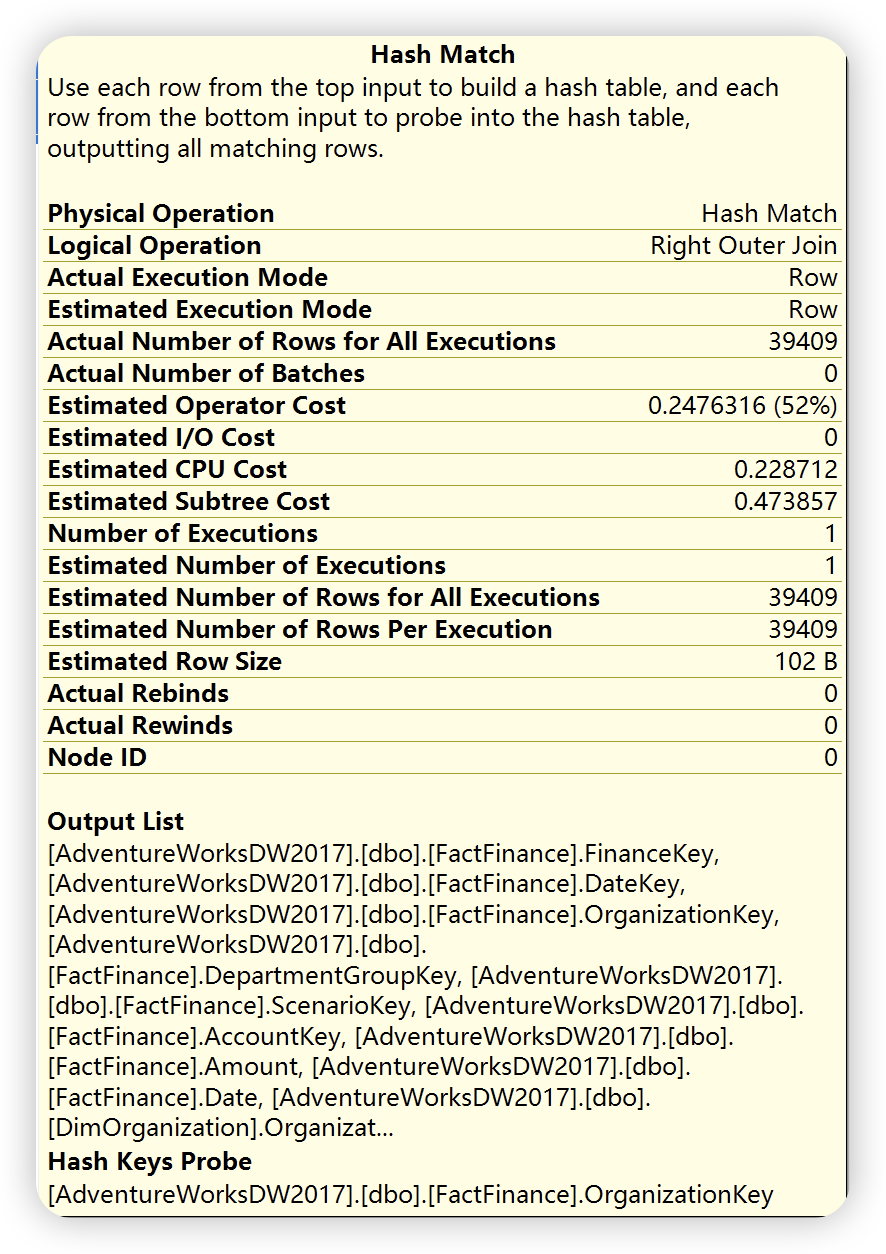
根据如下运算符详细信息可以得知,查询优化器会根据两个输入中较小的哪个作为生成输入,另一个作为探测输入。哈希链接用于多种匹配操作,( 如下图 logical operation ),左外链接,右外链接,完全外部🔗,左半链接,右半链接,交集,联合和差异等。此外,哈希连接又分为三种类型:内存中的哈希连接,Grace 哈希连接和递归哈希链接。SQL Server 会根据实际情况选择最有的一种,有兴趣的可以试一下。
往期文章

数据仓库系列
数据仓库之维度表
Hive 系列
Hive 必知必会(一)介绍
Hive 必知必会(二)基本操作
Hive 必知必会(三)基本操作(续)
Kettle 系列
Kettle 学习之路(一)基本概念
Kettle 学习之路(二)安装配置
Kettle 学习之路(三)文本文件输入
Kettle 学习之路(四)变量与参数
Kettle 学习之路(五)XML 文件输入
Kettle 学习之路(六)JSON 输入
Kettle 学习之路(七)Excel 输入
Kettle 学习之路(八)行列转换
Kettle 学习之路(九)同步 SQL Server 数据到 Hive
本文由 mdnice 多平台发布