在学习、使用和研究spark的过程中,逐渐会发现:单纯看官方文档对spark参数调优只能解决一小部分的问题,要想进一步的学习spark,进一步调优甚至在spark源码的基础上二次开发,我觉得收益最高的应该是学习执行计划了。
因此在研究spark源码之前,学习执行计划 可以对整个spark执行过程、架构设计都有一个初步的认识。
然而国内网站各大博客,都没有找到一个相关入门教程,笔者打算利用空余时间,在学习的同时做一个笔记,分享一下。
-------
基础篇:
Spark常用算子:https://blog.csdn.net/zyzzxycj/article/details/82706233
内存模型:https://blog.csdn.net/zyzzxycj/article/details/82740733
RDD&Partition:https://blog.csdn.net/zyzzxycj/article/details/82754411
DAG:https://blog.csdn.net/zyzzxycj/article/details/82734453
hive文件存储类型:https://blog.csdn.net/zyzzxycj/article/details/79267635
-------
Spark执行流程与原理:
https://blog.csdn.net/zyzzxycj/article/details/83788647
-------
1、先从最简单的例子开始 select *
场景:select * from test1(普通表 TextFile、一个partition)
== Physical Plan ==
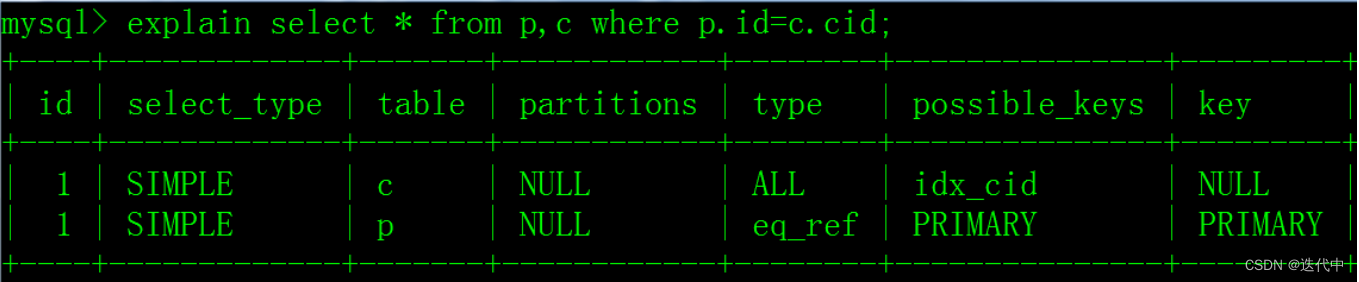
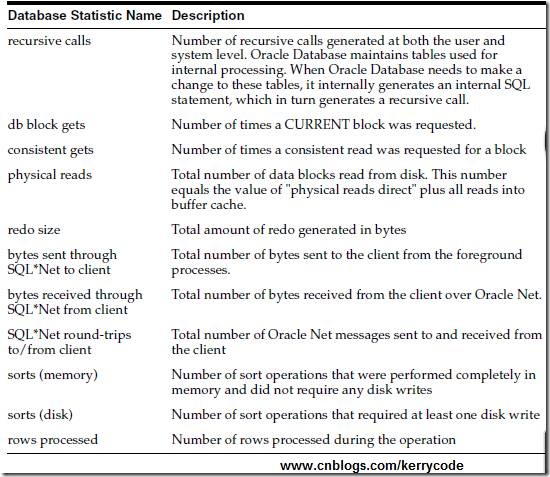
HiveTableScan [instance_id#2, order_id#3, pt#4], HiveTableRelation `heguozi`.`test1`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [instance_id#2, order_id#3], [pt#4]解释:HiveTableScan:扫描hive表,[]内为表中的三个字段(包括了表字段+分区字段)
HiveTableRelation:后面跟了库名.表名,HiveLazySimpleSerDe:TextFile默认的序列化器,[]内为表中两个字段,[]内为分区字段
2、count
场景:select count(*) from test1(普通表 TextFile、多个partition)
== Physical Plan ==
*(2) HashAggregate(keys=[], functions=[count(1)])
+- Exchange SinglePartition+- *(1) HashAggregate(keys=[], functions=[partial_count(1)])+- HiveTableScan HiveTableRelation `heguozi`.`test1`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [instance_id#8, order_id#9], [pt#10]解释:执行计划自下而上读,这个时候出现了两个stage,执行计划中 *(1)和*(2)为WholeStageCodegenId 这个会在之后的文章中做介绍。
count操作会触发HashAggregate算子,无论有多少个partition,均会产生shuffle。
总dag-graph:

stage1:

stage2:

PS:WholeStageCodegen 是spark2.X的新优化器,参考:https://blog.csdn.net/zyzzxycj/article/details/82745336
3、简单where查询
场景:select * from test1 where order_id='1'

解释:where作为过滤条件,spark只用了filter一个算子,窄依赖,会在一个stage中完成。
dag-graph:

4、group by & join
场景:
SELECT self_entity_id entity_id
FROM DW_DTL.DTL_T_CM_OD_TP_JOIN a
JOIN(SELECT entity_id,code,nameFROM ods_shop_org.shopWHERE code IN('C8007797')) b ON(a.self_entity_id = b.entity_id)
WHERE curr_date BETWEEN '2018-07-22' AND '2018-08-22'
GROUP BY a.self_entity_id执行计划:
| == Physical Plan ==
*(5) HashAggregate(keys=[self_entity_id#41021], functions=[])
+- *(5) HashAggregate(keys=[self_entity_id#41021], functions=[])+- *(5) Project [self_entity_id#41021]+- *(5) SortMergeJoin [self_entity_id#41021], [entity_id#41158], Inner:- *(2) Sort [self_entity_id#41021 ASC NULLS FIRST], false, 0: +- Exchange hashpartitioning(self_entity_id#41021, 200): +- *(1) Project [self_entity_id#41021]: +- *(1) Filter (((isnotnull(curr_date#41044) && (curr_date#41044 >= 2018-07-22)) && (curr_date#41044 <= 2018-08-22)) && isnotnull(self_entity_id#41021)): +- *(1) FileScan parquet dw_dtl.dtl_t_cm_od_tp_join[self_entity_id#41021,curr_date#41044,pt#41120] Batched: true, Format: Parquet, Location: CatalogFileIndex[hdfs://cluster-cdh/user/hive/warehouse/dw_dtl.db/dtl_t_cm_od_tp_join], PartitionCount: 1355, PartitionFilters: [], PushedFilters: [IsNotNull(curr_date), GreaterThanOrEqual(curr_date,2018-07-22), LessThanOrEqual(curr_date,2018-0..., ReadSchema: struct<self_entity_id:string,curr_date:string>+- *(4) Sort [entity_id#41158 ASC NULLS FIRST], false, 0+- Exchange hashpartitioning(entity_id#41158, 200)+- *(3) Project [entity_id#41158]+- *(3) Filter (code#41133 IN (C8007797) && isnotnull(entity_id#41158))+- HiveTableScan [code#41133, entity_id#41158], HiveTableRelation `ods_shop_org`.`shop`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [id#41121, country_code#41122, shop_kind#41123, profession#41124L, shop_type#41125, brand_id#41126, brand_entity_id#41127, plate_id#41128, plate_entity_id#41129, name#41130, english_name#41131, spell#41132, code#41133, customer_kind#41134, join_mode#41135, phone1#41136, phone2#41137, memo#41138, introduce#41139, status#41140, expire#41141, zip_code#41142, linkman#41143, business_time#41144, ... 28 more fields], [pt#41173] |dag-graph:

解释:
stage1扫描了以parquet方式存储的表,并进行了filter过滤,得到a表;与此同时,stage3扫描了text格式的hive表并进行filter过滤,得到了b表;project算子表明了其join条件为self_entity_id与entity_id;然后进入stage5,sortMergeJoin、aggregateByKey得到最终结果。
其中,Exchange hashpartitioning(column_name,num)为stages之间的shuffle,下图为该算子的定义:

column_name为expressions 即partition的keys,num为numPartitions 即hash取模后下游接收buckets个数:
(对key哈希取模partition = key.hashCode () % numPartitions)。
Project(column_name1,column_name2,....):为字段和#XXXX的映射,
实际上WholeStageCodegen-*(1)&*(2)为第一个stage,*(3)&*(4)为第二个stage,*(5)为第三个stage。
5、一个稍微复杂的例子
场景:
SELECT bb.customer_register_id,bb.time,cc.mobile from(SELECT a.user_id,b.customerregister_id,c.mobileFROM (SELECT split(split(split(split(recored,' HTTP')[0],'seat_code=')[1],'&')[0],'_')[1] AS user_idFROM dw_ubt.meal_2dfire_comWHERE recored LIKE '%async_modify%'AND recored LIKE '%presell%'AND pt>='20180905'AND pt<='20180911'GROUP BY split(split(split(split(recored,' HTTP')[0],'seat_code=')[1],'&')[0],'_')[1]) aLEFT JOIN (SELECT customerregister_idFROM ods_order_org.waitingorderdetailWHERE pay_status=2AND status=4AND kind=7AND pt>'20180501'GROUP BY customerregister_id) bON a.user_id=b.customerregister_idLEFT JOIN ods_member_org.customer_register cON a.user_id=c.idWHERE b.customerregister_id is null) aaRIGHT JOIN (SELECT customer_register_id,from_unixtime(int(create_time/1000),'YYYY-MM-DD HH:MM:SS') AS timeFROM ods_presell_market_org.coupon_customerWHERE activity_type=1AND channel != 4AND status=1AND from_unixtime(int(expire_time/1000),'yyyyMMdd') > from_unixtime(unix_timestamp(),'yyyyMMdd')AND is_valid =1AND create_time <=1536681600000) bbON aa.user_id=bb.customer_register_id
LEFT JOIN ods_member_org.customer_register ccON bb.customer_register_id=cc.id
WHERE aa.user_id is null执行计划:
| == Physical Plan ==
*(13) Project [customer_register_id#10228, time#10151, mobile#10244]
+- SortMergeJoin [customer_register_id#10228], [id#10243], LeftOuter:- *(11) Project [customer_register_id#10228, time#10151]: +- *(11) Filter isnull(user_id#10150): +- SortMergeJoin [user_id#10150], [customer_register_id#10228], RightOuter: :- *(8) Project [user_id#10150]: : +- SortMergeJoin [user_id#10150], [id#10203], LeftOuter: : :- *(6) Project [user_id#10150]: : : +- *(6) Filter isnull(customerregister_id#10193): : : +- SortMergeJoin [user_id#10150], [customerregister_id#10193], LeftOuter: : : :- *(3) Sort [user_id#10150 ASC NULLS FIRST], false, 0: : : : +- Exchange hashpartitioning(user_id#10150, 200): : : : +- *(2) HashAggregate(keys=[split(split(split(split(recored#10154, HTTP)[0], seat_code=)[1], &)[0], _)[1]#10267], functions=[]): : : : +- Exchange hashpartitioning(split(split(split(split(recored#10154, HTTP)[0], seat_code=)[1], &)[0], _)[1]#10267, 200): : : : +- *(1) HashAggregate(keys=[split(split(split(split(recored#10154, HTTP)[0], seat_code=)[1], &)[0], _)[1] AS split(split(split(split(recored#10154, HTTP)[0], seat_code=)[1], &)[0], _)[1]#10267], functions=[]): : : : +- *(1) Filter ((isnotnull(recored#10154) && recored#10154 LIKE %async_modify%) && Contains(recored#10154, presell)): : : : +- HiveTableScan [recored#10154], HiveTableRelation `dw_ubt`.`meal_2dfire_com`, org.apache.hadoop.hive.ql.io.orc.OrcSerde, [recored#10154], [pt#10155], [isnotnull(pt#10155), (pt#10155 >= 20180905), (pt#10155 <= 20180911)]: : : +- *(5) Sort [customerregister_id#10193 ASC NULLS FIRST], false, 0: : : +- *(5) HashAggregate(keys=[customerregister_id#10193], functions=[]): : : +- Exchange hashpartitioning(customerregister_id#10193, 200): : : +- *(4) HashAggregate(keys=[customerregister_id#10193], functions=[]): : : +- *(4) Project [customerregister_id#10193]: : : +- *(4) Filter (((((isnotnull(kind#10159) && isnotnull(status#10184)) && isnotnull(pay_status#10181)) && (pay_status#10181 = 2)) && (status#10184 = 4)) && (kind#10159 = 7)): : : +- *(4) FileScan parquet ods_order_org.waitingorderdetail[kind#10159,pay_status#10181,status#10184,customerregister_id#10193,pt#10202] Batched: true, Format: Parquet, Location: PrunedInMemoryFileIndex[hdfs://cluster-cdh/user/hive/warehouse/ods_order_org.db/waitingorderdetai..., PartitionCount: 4, PartitionFilters: [isnotnull(pt#10202), (pt#10202 > 20180501)], PushedFilters: [IsNotNull(kind), IsNotNull(status), IsNotNull(pay_status), EqualTo(pay_status,2), EqualTo(status..., ReadSchema: struct<kind:int,pay_status:int,status:int,customerregister_id:string>: : +- *(7) Sort [id#10203 ASC NULLS FIRST], false, 0: : +- Exchange hashpartitioning(id#10203, 200): : +- HiveTableScan [id#10203], HiveTableRelation `ods_member_org`.`customer_register`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [id#10203, mobile#10204, name#10205, spell#10206, sex#10207, birthday#10208, pwd#10209, sale_address_id#10210, is_verified#10211, is_valid#10212, create_time#10213L, op_time#10214L, last_ver#10215L, attachment_id#10216, server#10217, path#10218, contry_id#10219, contry_code#10220, extend_fields#10221, country_code#10222, spark#10223, level#10224, expire_time#10225], [pt#10226]: +- *(10) Sort [customer_register_id#10228 ASC NULLS FIRST], false, 0: +- Exchange hashpartitioning(customer_register_id#10228, 200): +- *(9) Project [customer_register_id#10228, from_unixtime(cast(cast((cast(create_time#10240L as double) / 1000.0) as int) as bigint), YYYY-MM-DD HH:MM:SS, Some(Asia/Harbin)) AS time#10151]: +- *(9) Filter ((((((((((isnotnull(status#10236) && isnotnull(create_time#10240L)) && isnotnull(channel#10234)) && isnotnull(activity_type#10233)) && isnotnull(is_valid#10238)) && (cast(activity_type#10233 as int) = 1)) && NOT (cast(channel#10234 as int) = 4)) && (cast(status#10236 as int) = 1)) && (from_unixtime(cast(cast((cast(expire_time#10235L as double) / 1000.0) as int) as bigint), yyyyMMdd, Some(Asia/Harbin)) > 20180918)) && (cast(is_valid#10238 as int) = 1)) && (create_time#10240L <= 1536681600000)): +- HiveTableScan [activity_type#10233, channel#10234, create_time#10240L, customer_register_id#10228, expire_time#10235L, is_valid#10238, status#10236], HiveTableRelation `ods_presell_market_org`.`coupon_customer`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [id#10227L, customer_register_id#10228, coupon_kind_id#10229L, coupon_type#10230, price#10231, activity_id#10232L, activity_type#10233, channel#10234, expire_time#10235L, status#10236, snapshot_id#10237, is_valid#10238, last_ver#10239, create_time#10240L, op_time#10241L], [pt#10242]+- *(12) Sort [id#10243 ASC NULLS FIRST], false, 0+- Exchange hashpartitioning(id#10243, 200)+- HiveTableScan [id#10243, mobile#10244], HiveTableRelation `ods_member_org`.`customer_register`, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [id#10243, mobile#10244, name#10245, spell#10246, sex#10247, birthday#10248, pwd#10249, sale_address_id#10250, is_verified#10251, is_valid#10252, create_time#10253L, op_time#10254L, last_ver#10255L, attachment_id#10256, server#10257, path#10258, contry_id#10259, contry_code#10260, extend_fields#10261, country_code#10262, spark#10263, level#10264, expire_time#10265], [pt#10266] |dag-graph:

执行计划缩略图:

6、较为复杂的例子
create table active_shop_week ASSELECT 2 AS dim_time,t1.curr_week AS curr_date,total_active_shop,(SELECT curr_week,count(distinct entity_id) AS total_active_shopFROM totGROUP BY curr_week) t1
LEFT JOIN (SELECT a.curr_week,count(distinct a.entity_id) AS catering_active_shopFROM tot aJOIN catering bON a.entity_id = b.entity_idGROUP BY a.curr_week) t2ON t1.curr_week = t2.curr_week
LEFT JOIN (SELECT a.curr_week,count(distinct a.entity_id) AS retail_active_shopFROM tot aJOIN retail bON a.entity_id = b.entity_idGROUP BY a.curr_week) t3 ON t1.curr_week = t3.curr_week
LEFT JOIN (SELECT curr_week,count(distinct entity_id) AS total_online_orderFROM online_orderGROUP BY curr_week) o1ON t1.curr_week = o1.curr_week
LEFT JOIN (SELECT curr_week,count(distinct entity_id) AS total_online_payFROM online_payGROUP BY curr_week) o2ON t1.curr_week = o2.curr_week
LEFT JOIN (SELECT a.curr_week,count(distinct a.entity_id) AS catering_order_activeFROM order_active aJOIN catering bON a.entity_id = b.entity_idGROUP BY a.curr_week) d1ON t1.curr_week = d1.curr_week
LEFT JOIN (SELECT curr_week,count(distinct entity_id) AS retail_order_activeFROM (SELECT curr_date,entity_id,concat(year(date_sub(next_day(curr_date,'MON'),7)),'-',weekofyear(date_sub(next_day(curr_date,'MON'),7))) AS curr_weekFROM olap_analysis.tmp_retail_active_shopUNIONallSELECT curr_date,a.entity_id,concat(year(date_sub(next_day(curr_date,'MON'),7)),'-',weekofyear(date_sub(next_day(curr_date,'MON'),7))) AS curr_weekFROM order_active aJOIN retail bON a.entity_id = b.entity_id)uGROUP BY curr_week ) d2ON t1.curr_week = d2.curr_week
LEFT JOIN (SELECT curr_week,count(distinct entity_id) AS catering_online_orderFROM online_orderGROUP BY curr_week) w1ON t1.curr_week = w1.curr_week
LEFT JOIN (SELECT curr_week,sum(if(order_from = 40,1,0)) AS catering_weixin_order,sum(if(order_from = 41,1,0)) AS catering_zhifubao_orderFROM (SELECT entity_id,order_from,concat(year(date_sub(next_day(curr_date,'MON'),7)),'-',weekofyear(date_sub(next_day(curr_date,'MON'),7))) AS curr_weekFROM (SELECT from_unixtime(int(op_time/1000),'yyyy-MM-dd') AS curr_date, entity_id, order_fromFROM dw_order_org.waitingorderdetail_cleanWHERE pt = '20180925'AND from_unixtime(int(op_time/1000), 'yyyy-MM-dd')BETWEEN '2018-08-01'AND '2018-09-25') xGROUP BY concat(year(date_sub(next_day(curr_date,'MON'),7)),'-',weekofyear(date_sub(next_day(curr_date,'MON'),7))), entity_id, order_from) ttGROUP BY curr_week) w2ON t1.curr_week = w2.curr_weekLEFT JOIN (SELECT curr_week,count(distinct a.entity_id) AS catering_online_payFROM online_pay aJOIN catering bON a.entity_id = b.entity_idGROUP BY curr_week) op1ON t1.curr_week = op1.curr_week
LEFT JOIN (SELECT curr_week,count(distinct a.entity_id) AS retail_online_payFROM online_pay aJOIN retail bON a.entity_id = b.entity_idGROUP BY curr_week) op2ON t1.curr_week = op2.curr_week
LEFT JOIN (SELECT curr_week,sum(if(pay_client_type = 1,1,0)) AS catering_weixin_pay,sum(if(pay_client_type = 2,1,0)) AS catering_zhifubao_payFROM (SELECT a.entity_id,a.curr_week,a.pay_client_typeFROM paymentflow aJOIN catering bON a.entity_id = b.entity_idGROUP BY a.entity_id,a.curr_week,a.pay_client_type) rGROUP BY curr_week ) p1ON w1.curr_week = p1.curr_week
LEFT JOIN (SELECT curr_week,sum(if(pay_client_type = 1,1,0)) AS retail_weixin_pay,sum(if(pay_client_type = 2,1,0)) AS retail_zhifubao_payFROM (SELECT a.entity_id,a.curr_week,a.pay_client_typeFROM paymentflow aJOIN retail bON a.entity_id = b.entity_idGROUP BY a.entity_id,a.curr_week,a.pay_client_type) rGROUP BY curr_week ) p2ON w1.curr_week = p2.curr_week