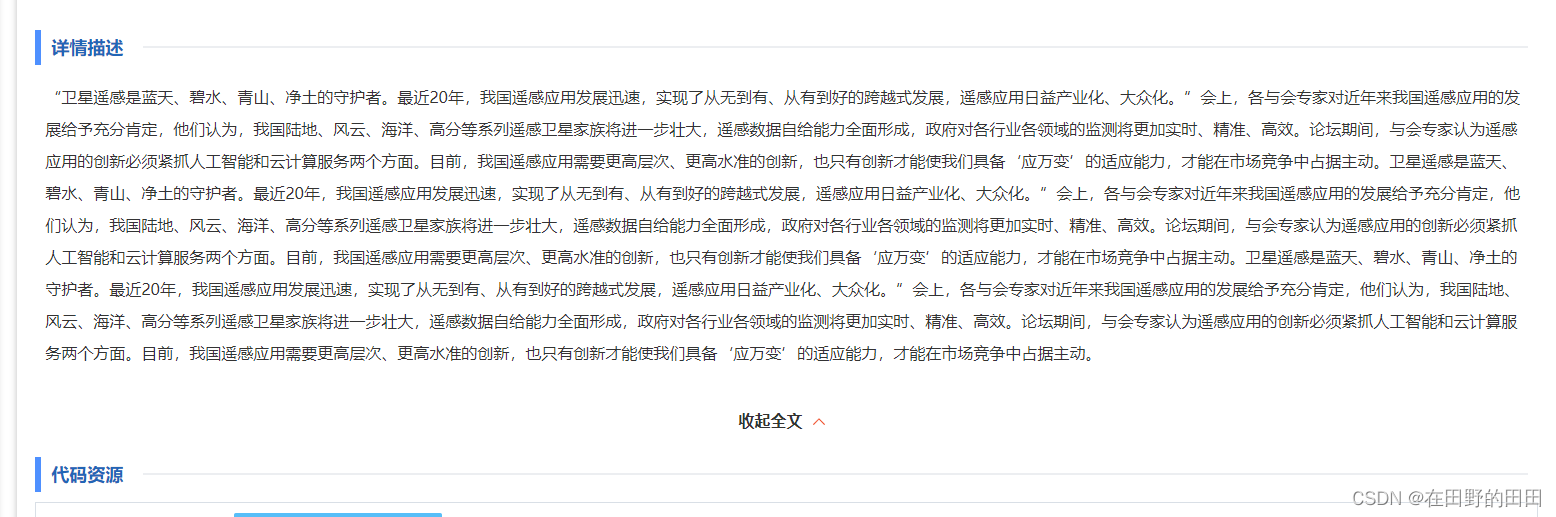
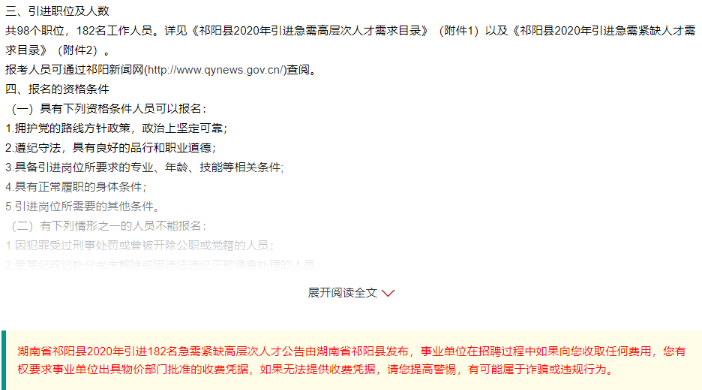
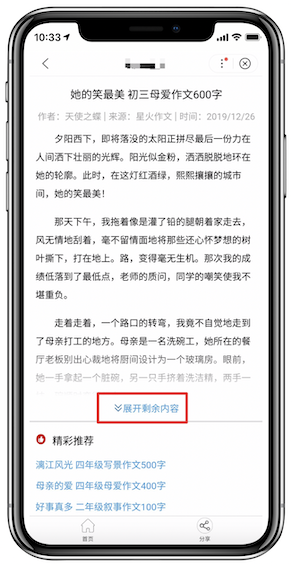
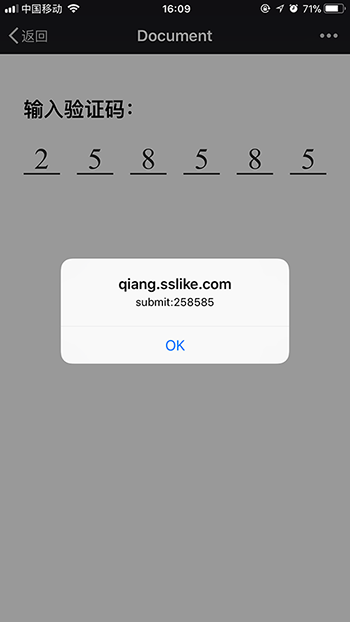
获取新浪微博“展开全文”的完整文本

在个人主页的响应中,这篇微博的表示形式是这样的:
<div class=\"WB_text W_f14\" node-type=\"feed_list_content\" nick-name=\"Vista看天下\">\n 【一堂课让柳传志大呼过瘾,千字长文力挺湖畔大学】11月20日晚,柳传志发布千字长文《为湖畔大学正名》,力挺湖畔大学。他提到,在湖畔大学上课,是找到了“知音”,参加各种论坛、座谈、讲课30余年,印象最深的就是在湖畔大学上课。柳传志发自内心地认为,湖畔大学是在培养扶植真正代表中国的企业家, ...<a target=\"_blank\" href=\"//weibo.com/1323527941/Fw5poB1mb\" class=\"WB_text_opt\" suda-uatrack=\"key=original_blog_unfold&value=click_unfold:4176472908823355:1323527941\" action-type=\"fl_unfold\" action-data=\"mid=4176472908823355&is_settop&is_sethot&is_setfanstop&is_setyoudao\">展开全文<i class=\"W_ficon ficon_arrow_down\">c</i></a> </div>
在点击“展开全文”的时候,可以看到控制台新增了这样一条请求:
请求的格式为:"https://weibo.com/p/aj/mblog/getlongtext?ajwvr=6&"+ action-data +"&__rnd=1511181643288"
rnd代表当前时间的毫秒数,可以不做修改。

在浏览器中复制请求网址,得到如下的页面:

因此利用模拟浏览器访问目标网址的方式,来获取到这段文字。在这里利用JSONObject解析json,利用jsoup解析html。
Document doc = (Document) Jsoup.parse(s);
Elements select = doc.getElementsByClass("WB_text W_f14");//微博个人主页的每一条博文所在的class//遍历每一个元素
for (Element element : select) {if (element.text().contains("展开全文")) {
//获取这个元素所在div中的action-data属性,来拼接需要访问的URL
String attr = element.select(".WB_text_opt").attr("action-data");String longTextUrl = "https://weibo.com/p/aj/mblog/getlongtext?ajwvr=6&"+attr+"&__rnd=1511181740414";
//创建连接
HttpURLConnection conn = DownLoadPage.connectUrl(longTextUrl);// 打开连接conn.connect();StringBuffer sb = new StringBuffer();// 打开这个网站的输入流InputStream inputStream = conn.getInputStream();BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream));String temp = null;while ((temp = bufferedReader.readLine()) != null) {sb.append(temp);}
//解码,否则会出现乱码的情况
String decodeUnicode = DownLoadPage.decodeUnicode(sb.toString());//System.out.println(decodeUnicode);JSONObject json = JSONObject.fromObject(decodeUnicode);String ss = json.getString("data");String sss = JSONObject.fromObject(ss).getString("html");Document docc = (Document) Jsoup.parse(sss);System.out.println(docc.text());}else{System.out.println(element.text());}
}




![[HTML+CSS+Vue.js] 超长文本等内容默认折叠显示,点击展开全文,再点击收起(仿知乎效果)](https://img-blog.csdnimg.cn/20181116052303524.gif)