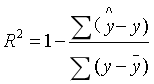一、方差分析的基本概念
方差分析是在20世纪20年代发展起来的一种统计方法,它是由英国统计学家费希尔在进行实验设计时为解释实验数据而首先引入的。
从形式上看,方差分析是比较多个总体的均值是否相等;但是其本质上是研究变量之间的相互关系。方差分析主要用于研究一个数值因变量与一个或多个分类自变量的关系。
根据方差分析的计算方法给方差分析下一个定义:
方差分析(analysis of variance ,ANOVA)就是通过检验各总体的均值是否相等来判断分类型自变量对数值型因变量是否有显著影响。
二、利用实例讲解方差分析的应用
假设某私立学校具有小学、初中、高中三个水平的学生,每个水平阶段的学生每个学期都会进行一次期末考试。另外假设小学共抽取10个班级,初中抽取9个班级,高中抽取8个班级。
每个班级期末考试的平均分分别用Ai(i=1,2,...,10)、Bj(j=1,2,...,9)和Ck(k=1,2,...,8)表示,为了比较各个水平阶段的班级平均分是否有显著性差异,就可以使用方差分析。
这里的阶段就是因素,也称之为因子,因子的三个取值:小学、初中、高中,称为水平或处理。
|
| 阶段 | ||
|
| 小学 | 初中 | 高中 |
| 1 | 90 | 87 | 80 |
| 2 | 90 | 88 | 79 |
| 3 | 89 | 90 | 80 |
| 4 | 88 | 78 | 89 |
| 5 | 89 | 89 | 87 |
| 6 | 91 | 90 | 86 |
| 7 | 96 | 80 | 89 |
| 8 | 88 | 81 | 83 |
| 9 | 80 | 82 |
|
| 10 | 90 |
|
|
为了更为直观地观察各水平平均值,绘制箱线图如下:

由于以上数据只涉及到一个分类自变量,即阶段,因此属于单因素方差分析。
从箱线图可以看出,各水平学生的平均分存在一定的差异,但是这种差异显著不显著,还需要进一步分析。
同时,各个水平的方差看起来也不尽相同。
二、方差分析的基本思想
由以上分析可以看出,虽然各个水平的学生平均分存在差异,但是其方差也有差别,方差分析的基本思想就是弄清楚影响因变量取值的误差来源,以判断是否是分类自变量对因变量产生影响。
在上述数据中,各组数据的误差主要来源于以下几个部分。
首先,即使是同一组的数据,其取值也具有差别,这是因为班级是随机抽取的,因此他们之间的差异可以看作是随机因素的影响造成的,或者说是由抽样的随机性造成的,这种来自水平内部的误差称之为组内误差,显然,组内误差只含有随机误差。
其次,各组的取值不同。来自不同水平之间的误差称为组间误差,这种差异可能来自于随机误差,也可能来自于因子本身的系统性误差造成的系统误差。因此,组内误差包含有可能包含两个方面,即随机误差和系统误差。
最后,总误差为组内误差与组间误差之和。
这样,就把造成因变量的差异的误差分解成组内误差和组间误差。
即
总误差=组内误差+组间误差
如果组内误差与组间误差相差太大,说明组间误差存在很大成分的系统误差,这时候就可以认为各水平均值显著不等。
将组间误差与总误差的比值定义为关系强度R2,即
R2=
将各平方和除以对应的自由度,则得到相应的均方,也称为方差。
SST的自由度为n-1
SSA的自由度为k-1
SSE的自由度为n-k

三、方差分析的基本假设
(1)各总体的方差必须相等
(2)各总体必须服从正态分布
(3)各观测值相互独立
四、方差分析的类型
根据影响因变量的因素个数,可以把方差分析分为单因素方差分析和双因素方差分析。
如果是双因素方差分析,根据两个因素的交互作为是否对因变量产生影响可分为无交互作用的双因素方差分析和有交互作用的双因素方差分析。
五、方差分析的R语言实现
(一)方差分析基本假设的检验
将数据在R语言中以列表形式存储,
> ave_score
$primary
[1] 90 90 89 88 89 91 96 88 80 90
$junior
[1] 87 88 90 78 89 90 80 81 82
$senior
[1] 80 79 80 89 87 86 89 83
1、方差齐性检验
(1)Bartlett检验(Bartlett检验也可以接受一个数据框为输入,结构与下面的Levene检验相同。此方法比较适合用于总体服从正态分布的检验)
> bartlett.test(ave_score)
Bartlett test of homogeneity of variances
data: ave_score
Bartlett's K-squared = 0.28233, df = 2, p-value = 0.8683
P值为0.8683,由于p大于常用的a=0.05,因此,无法拒绝原假设,即认为方差相等。
(2)Levene检验 (Levene检验函数接受的数据结构为数据框结构,并且一列是各水平的取值score,另一列是所属的水平level,用score~level表示score为因变量,level为自变量。此方法适用于总体非正态的检验)
> scores<-data.frame(score=c(ave_score$primary,ave_score$junior,ave_score$senior),level=rep(c("primary","junior","senior"),c(10,9,8)))
> scores
score level
1 90 primary
2 90 primary
3 89 primary
4 88 primary
5 89 primary
6 91 primary
7 96 primary
8 88 primary
9 80 primary
10 90 primary
11 87 junior
12 88 junior
13 90 junior
14 78 junior
15 89 junior
16 90 junior
17 80 junior
18 81 junior
19 82 junior
20 80 senior
21 79 senior
22 80 senior
23 89 senior
24 87 senior
25 86 senior
26 89 senior
27 83 senior
> leveneTest(score~level,data = scores)
Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 2 1.0461 0.3668
24
P值大于0.05,可认为等方差
(3)Fligner-Killeen检验
> fligner.test(ave_score)(fliger.test函数可以接受列表输入)
Fligner-Killeen test of homogeneity of variances
data: ave_score
Fligner-Killeen:med chi-squared = 2.0447, df = 2, p-value = 0.3597
结论同上
2、正态性检验
shapiro检验(输入数据为一个向量,检验该向量的数据是否服从正态分布)
> sapply(ave_score,shapiro.test)(
primary junior
statistic 0.8332102 0.8725879
p.value 0.03657401 0.1310428
method "Shapiro-Wilk normality test" "Shapiro-Wilk normality test"
data.name "X[[i]]" "X[[i]]"
senior
statistic 0.8764152
p.value 0.1739798
method "Shapiro-Wilk normality test"
data.name "X[[i]]"
primary 水平的检验拒绝原假设,即非正态。这个数据只是为了说明方差分析的原理,并没有进行严格的验证,但是不影响后续工作的推进。
3、独立性检验
可以通过控制抽样过程来控制独立性,无具体的检验方法。
(二)方差分析
1、单因素方差分析
方差分析所需的数据结构一般是一个数据框,就像上面的那样。
进行方差分析可以使用lm()函数,也可以使用aov()函数,再利用summary()函数或者anova()函数输出最终结果。
对于上述的单因素方差分析,分别用这两者方法分析如下:
(1)用lm()函数
> score_lm<-lm(score~level,data = scores)
> summary(score_lm)
Call:
lm(formula = score ~ level, data = scores)
Residuals:
Min 1Q Median 3Q Max
-9.100 -3.500 0.900 2.938 6.900
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 85.000 1.424 59.706 <2e-16 ***
levelprimaty 4.100 1.962 2.089 0.0475 *
levelsenior -0.875 2.075 -0.422 0.6770
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 4.271 on 24 degrees of freedom
Multiple R-squared: 0.2309, Adjusted R-squared: 0.1668
F-statistic: 3.602 on 2 and 24 DF, p-value: 0.04285
> anova(score_lm)
Analysis of Variance Table
Response: score
Df Sum Sq Mean Sq F value Pr(>F)
level 2 131.41 65.705 3.6021 0.04285 *
Residuals 24 437.78 18.241
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Summary()函数会输出残差和模型,anova()只会输出结果。
(2)利用aov()函数
> score_aov<-aov(score~level,data = scores)
> summary(score_aov)
Df Sum Sq Mean Sq F value Pr(>F)
level 2 131.4 65.71 3.602 0.0429 *
Residuals 24 437.8 18.24
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
> anova(score_aov)
Analysis of Variance Table
Response: score
Df Sum Sq Mean Sq F value Pr(>F)
level 2 131.41 65.705 3.6021 0.04285 *
Residuals 24 437.78 18.241
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
从上述结果可以看出,anova()输出的是标准的方差分析表,而利用lm()函数计算的方差分析会输出回归模型,以及残差——更多的是回归的信息。
2、无交互作用的双因素方差分析
有的时候,因变量可能受到来自一个以上的因素的影响,最典型的就是双因素方差分析。假如因素A与因素B没有联合效应,则称为无交互作用的双因素方差分析。
考虑以下的例子,假如某经销商想知道一款饮料的销售额与销售地点和饮料包装风格的关系,探究这两个因素是否都在影响销售额或者只有一个因素影响销售额。
数据如下:
| 地区 | |||||||
| A | B | C | D | E | 合计 | ||
| 包装 | 甲 | 30 | 33 | 29 | 41 | 37 | 170 |
| 乙 | 32 | 38 | 39 | 32 | 40 | 181 | |
| 丙 | 29 | 33 | 35 | 39 | 40 | 176 | |
| 丁 | 40 | 41 | 45 | 39 | 40 | 205 | |
| 合计 | 131 | 145 | 148 | 151 | 157 | 732 | |
无交互作用的双因素方差分析与单因素方差分析类似,只是在写公式的时候变成【销售额~地区+包装】就行。
如果为了省事,可以使用gl()函数生成因子,但是为了与原数据对应,减小阅读压力,建议自己写因子水平。
gl(n, k, length = n*k, labels = seq_len(n), ordered = FALSE)n:一个整数,表示水平的个数
an integer giving the number of levels.
k:表示每个水平重复几遍an integer giving the number of replications.
length:如果前面两个都给出了,就不用给这项参数了,否则需要给出所有数据的个数an integer giving the length of the result.
labels:结果的标签向量an optional vector of labels for the resulting factor levels.
ordered:是否排序a logical indicating whether the result should be ordered or not.
这里,我选择自己手动生成水平数据。
> dat<-read.table("clipboard",header = TRUE,stringsAsFactors = FALSE)
> dat
包装 A B C D E
1 甲 30 33 29 41 37
2 乙 32 38 39 32 40
3 丙 29 33 35 39 40
4 丁 40 41 45 39 40
> sales<-c(dat$A,dat$B,dat$C,dat$D,dat$E)
> areas<-rep(c("A","B","C","D","E"),each=4)
> style<-rep(c('甲','乙','丙','丁'),5)
> sales
[1] 30 32 29 40 33 38 33 41 29 39 35 45 41 32 39 39 37 40 40 40
> areas
[1] "A" "A" "A" "A" "B" "B" "B" "B" "C" "C" "C" "C" "D" "D" "D" "D" "E" "E" "E" "E"
> style
[1] "甲" "乙" "丙" "丁" "甲" "乙" "丙" "丁" "甲" "乙" "丙" "丁" "甲" "乙" "丙" "丁"
[17] "甲" "乙" "丙" "丁"
> drink_sale<-data.frame(sales,areas,style)
> drink_sale
sales areas style
1 30 A 甲
2 32 A 乙
3 29 A 丙
4 40 A 丁
5 33 B 甲
6 38 B 乙
7 33 B 丙
8 41 B 丁
9 29 C 甲
10 39 C 乙
11 35 C 丙
12 45 C 丁
13 41 D 甲
14 32 D 乙
15 39 D 丙
16 39 D 丁
17 37 E 甲
18 40 E 乙
19 40 E 丙
20 40 E 丁
分析之前需要对地区和包装风格做方差齐性检验。
> bartlett.test(sales~areas,data = drink_sale)
Bartlett test of homogeneity of variances
data: sales by areas
Bartlett's K-squared = 4.833, df = 4, p-value = 0.3049
> bartlett.test(sales~style,data = drink_sale)
Bartlett test of homogeneity of variances
data: sales by style
Bartlett's K-squared = 2.017, df = 3, p-value = 0.5689
检验结果都无法拒绝原假设,即可以认为方差是相等的。
接下来进行方差分析
> drink_aov<-aov(sales~areas+style,data = drink_sale)
> anova(drink_aov)
Analysis of Variance Table
Response: sales
Df Sum Sq Mean Sq F value Pr(>F)
areas 4 93.8 23.450 1.6572 0.22397
style 3 141.2 47.067 3.3263 0.05655 .
Residuals 12 169.8 14.150
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
两个p值都是大于0.05,因此可以认为销售地区与包装风格对销售额没有显著影响。
3、有交互作用的双因素方差分析
因素之间的交互作用在现实中很常见,比如胖胖的人喜欢蓝色的衣服,南方的人更喜欢喝雪花啤酒等,前者是体重和颜色的交互作用,后者是地区和啤酒品牌的交互作用。
因此,如果两个因素联合在一起对因变量有显著的影响,则称这样的方差分析为有交互作用的方差分析。
下面的数据展示的是各个路段在高峰期与非高峰期的车流量(数据来自《数据分析:R语言实战》)。对其进行双因素方差分析的过程如下。
| 路段1 | 路段2 | 路段3 | |
| 高峰期 | 25 24 27 25 25 | 19 20 23 22 21 | 29 28 31 28 30 |
| 非高峰期 | 20 17 22 21 17 | 18 17 13 16 12 | 22 18 24 21 22 |
> cars<-read.table("clipboard",header = TRUE,stringsAsFactors = TRUE)
> summary(cars)
车流量 路段 时期
Min. :12.00 路段1:10 非高峰期:15
1st Qu.:18.25 路段2:10 高峰期 :15
Median :22.00 路段3:10
Mean :21.90
3rd Qu.:25.00
Max. :31.00
方差齐性检验
> bartlett.test(车流量~路段,data=cars)
Bartlett test of homogeneity of variances
data: 车流量 by 路段
Bartlett's K-squared = 0.57757, df = 2, p-value = 0.7492
> bartlett.test(车流量~时期,data=cars)
Bartlett test of homogeneity of variances
data: 车流量 by 时期
Bartlett's K-squared = 0.053302, df = 1, p-value = 0.8174
上述检验显示满足方差齐性条件
接下来进行方差分析
> cars_aov<-aov(车流量~路段*时期,data=cars)
> anova(cars_aov)
Analysis of Variance Table
Response: 车流量
Df Sum Sq Mean Sq F value Pr(>F)
路段 2 261.600 130.800 35.3514 7.018e-08 ***
时期 1 313.633 313.633 84.7658 2.407e-09 ***
路段:时期 2 6.667 3.333 0.9009 0.4195
Residuals 24 88.800 3.700
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
路段和时期的p值都显著小于0.05,但是二者的联合效应的p值为0.4195,大于0.05,因此可以认为二者无显著的交互作用。
交互效应图可以更加直观地看出两个因素是否具有交互效应,可以用interaction.plot()绘制
interaction.plot(x.factor, trace.factor, response, fun = mean,type = c("l", "p", "b", "o", "c"), legend = TRUE,trace.label = deparse(substitute(trace.factor)),fixed = FALSE,xlab = deparse(substitute(x.factor)),ylab = ylabel,ylim = range(cells, na.rm = TRUE),lty = nc:1, col = 1, pch = c(1:9, 0, letters),xpd = NULL, leg.bg = par("bg"), leg.bty = "n",xtick = FALSE, xaxt = par("xaxt"), axes = TRUE,...) x.factor | a factor whose levels will form the x axis. |
trace.factor | another factor whose levels will form the traces. |
response | a numeric variable giving the response |
> names(cars)<-c("flow","path","time")
> attach(cars)
> interaction.plot(path,time,flow,legend = F)
> interaction.plot(time,path,flow,legend = F)
两个图中的曲线均没有相交,可以初步认为没有交互作用。