先看下本文中的知识点:
- python selenium库安装
- chrome webdirver的下载安装
- selenium+chrome使用代理
- 进阶学习
搭建开发环境:
- selenium库
- chrome webdirver
- 谷歌浏览器 >=7.9
PS:安装了的同学可以跳过了接着下一步,没安装的同学跟着我的步骤走一遍
安装selenium库
pip install selenium
安装chrome webdirver
这里要注意要配置系统环境,把chrome webdirver解压后放到python路径的Scripts目录下,跟pip在一个目录下。
这里可以教大家一个查看python安装路径的命令
# windows系统,打开cmd
where python
# linux系统
whereis python
谷歌浏览器
注意谷歌浏览器的版本要>=7.9,因为之前下载的chrome webdirver是7.9版本的。浏览器就自己安装吧。
代码样例
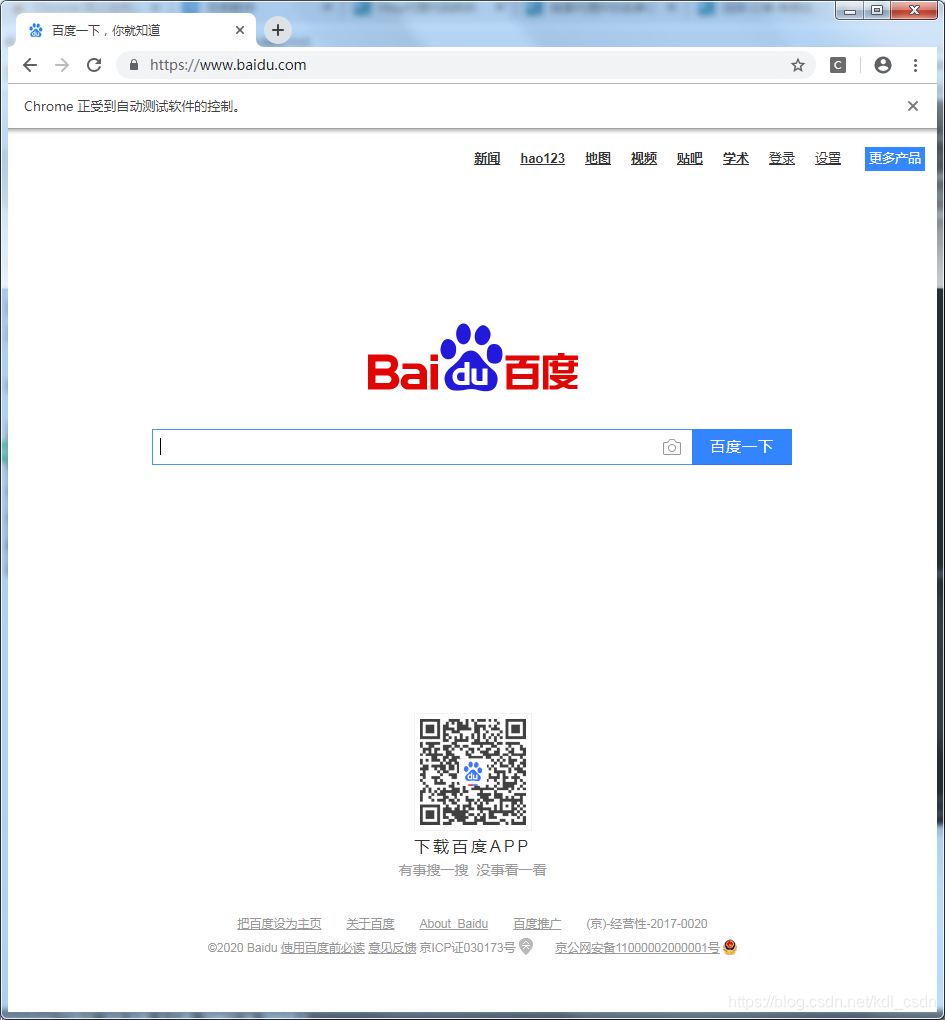
好的,现在咋们的环境都配置好了,写几行代码试下,以请求百度为例
from selenium import webdriver
# 用webdriver的chrome浏览器打开
chrome = webdriver.Chrome()
chrome.get('https://www.baidu.com')
print(chrome.page_source)
chrome.quit() #退出
运行下,先会打开chrome浏览器,然后访问百度,在打印page信息,最后关闭浏览器
使用代理
使用代理IP去访问就得加一个参数了,代码如下
from selenium import webdriverchrome_options = webdriver.ChromeOptions()
# 代理IP,由快代理提供
proxy = '60.17.254.157:21222'
# 设置代理
chrome_options.add_argument('--proxy-server=%s' % proxy)
# 注意options的参数用之前定义的chrome_options
chrome = webdriver.Chrome(options=chrome_options)
# 百度查IP
chrome.get('https://www.baidu.com/s?ie=UTF-8&wd=ip')
print(chrome.page_source)
chrome.quit() #退出
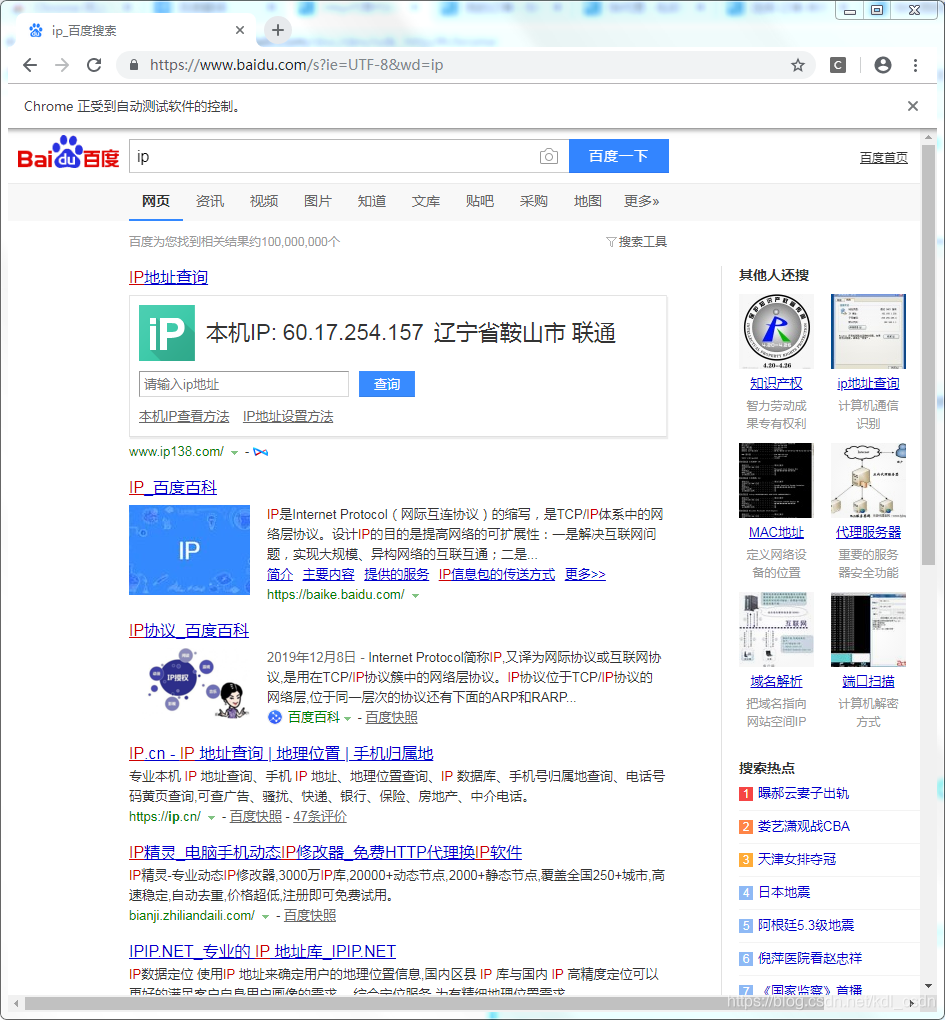
运行下,结果如图
扩展
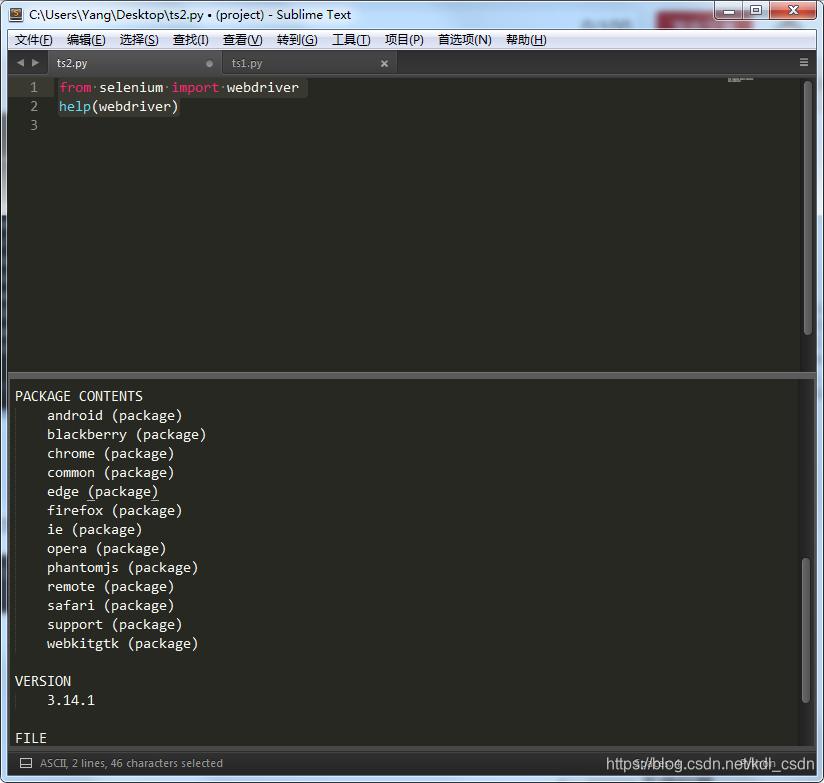
不想用谷歌浏览器啊,想用火狐怎么办。没问题啊,webdriver也支持火狐。看下webdriver的帮助文档
from selenium import webdriver
help(webdriver)
看下图,不止支持火狐firefox,谷歌chrome,ie,opera等等都支持的。
进阶学习
- selenium中文文档
- 代理IP使用