文章目录
- 中文笔记地址
- 视频地址
- 第1章 引言
- 1.1 欢迎
- 1.2 机器学习是什么
- 1.3 监督学习
- 1.4 无监督学习
- 第2章
- 2.1 模型展示
- 单变量线性回归
- 2.2 代价函数
- 2.3-2.4 代价函数理解
- 2.5-2.6 梯度下降算法,梯度下降算法理解
- 第3章
- 第4章
- 4.2 多元(多变量)梯度下降算法
- 4.3 梯度下降实用技巧1-特征缩放
- 4.4 梯度下降算法实用技巧2 -学习率的选择
- 4.5 特征与多项式回归
- 4.6 正规方程
- 4.7 正规方程(在矩阵不可逆的时候解法)
- 第5章
- 5.6 向量化概念
- 第6章
- 6.1 分类问题
- 6.2 假设陈述
- 6.3 决策界限
- 6.4代价函数
- 6.5 简化代价函数与梯度下降
- 6.6 高级优化
- 6.7 多元分类:一对多
- 第7章
- 7. 1过拟合问题
- 7.2 代价函数
- 7.3 线性回归的正则化
- 7.4 正则化的逻辑回归模型
- 第8章
- 8.1 非线性建设
- 8.3 模型展示I
- 8.4 模型展示II
- 8.5 例子与直观理解神经网络 I
- 8.6 例子与直观理解神经网络 II
- 8.7 神经网络解决多元分类
- 第9章
- 9.1 代价函数
- 9.2 反向传播算法
- 9.3 理解反向传播算法
- 9.4 使用技巧:展开参数
- 9.5 梯度检测
- 9.6 随机初始化
- 9.7 总结
- 9.8 自动驾驶
- 第10章
- 10.1 决定下一步做什么
- 10.2 评估假设
- 10.3 模型选择和训练,验证,测试集
- 10.4 诊断偏差与方差
- 10.5 正则化和偏差、方差
- 10.6 学习曲线
- 10.7 决定接下来做什么
- 11.1 确定执行的优先级
- 11.2 误差分析
- 11.3 不对称性分类的误差评估
- 11.4 查准率和召回率的权衡
- 11.5 机器学习数据
- 12.1 优化目标(支持向量机)
- 12.2 直观上对于大间隔的理解
- 12.3 大间隔分类器的数学原理
- 12.4 核函数1
- 12.5 核函数2
- 12.6 使用SVM
中文笔记地址
https://github.com/fengdu78/Coursera-ML-AndrewNg-Notes
视频地址
https://www.bilibili.com/video/BV164411b7dx?p=4
https://study.163.com/course/courseLearn.htm?courseId=1210076550#/learn/video?lessonId=1280912351&courseId=1210076550
第1章 引言
1.1 欢迎
1.2 机器学习是什么
定义机器学习为:在进行特定编程的情况下,给予计算机 学习能力的领域。目前存在几种不同类型的学习算法,主要的两种类型被我们称之为监督学习和无监督学习。监督学习这个想法是指,我们将教计算机如何去完成任务, 而在无监督学习中,我们打算让它自己进行学习
1.3 监督学习
**监督学习指的就是我们给学习算法一个数据集(训练集)。这个数据集由“正确答案”组成。
回归与分类问题定义
回归 这个词的意思是,我们在试着推测出这一系列连续值属性
回归问题 ,指我们试着推测出一个连续值的结果,比如房子的价格(1-1000元),尽管价格最小单位是分,但我们还是把它作为连续值
分类指的是,我们试着推测出离散的输出值,如是否是肿瘤(是为1,不是为0)
支持向量机,里面有一个巧妙的数学技巧,能让计算机处理无限多个特征
假设你经营着一家公司,你想开发学习算法来处理这两个问题:
(1)你有一大批同样的货物,想象一下,你有上千件一模一样的货物等待出售,这时你想预测接下来的三个月能卖多少件?
(2)你有许多客户,这时你想写一个软件来检验每一个用户的账户。对于每一个账户,你要判断它们是否曾经被盗过?
那这两个问题,它们属于分类问题、还是回归问题
问题一是一个回归问题,因为你知道,如果我有数千件货物,我会把它看成一个实数(有理数+无理数),一个连续的值。因此卖出的物品数,也是一个连续的值。
问题二是一个分类问题,因为我会把预测的值,用 0 来表示账户未被盗,用 1 表示账户曾经被盗过。所以我们根据账号是否被盗过,把它们定为0 或 1,然后用算法推测一个账号是 0 还是 1,因为只有少数的离散值,所以我把它归为分类问题。
1.4 无监督学习
无监督学习中,数据集没有任何的标签或者是有相同的标签。所以我们已知数据集,却不知如何处理,也未告知每个数据点是什么
无监督学习就是运行一个聚类算法(无监督学习算法),把不同的个体,归入不同类或者归为不同的类型的人
无监督学习的第2种算法,叫“鸡尾酒会算法”,能两种混合在一起的声音区分开来(如两种混在一起的人声,人声和背景音混在一起)
问题Q&A汇总


无监督学习和有监督学习的区别:(1)数据集,有监督学习的数据集是提前打好标签的,而无监督学习的数据集是没有任何标签或标签都是相同的
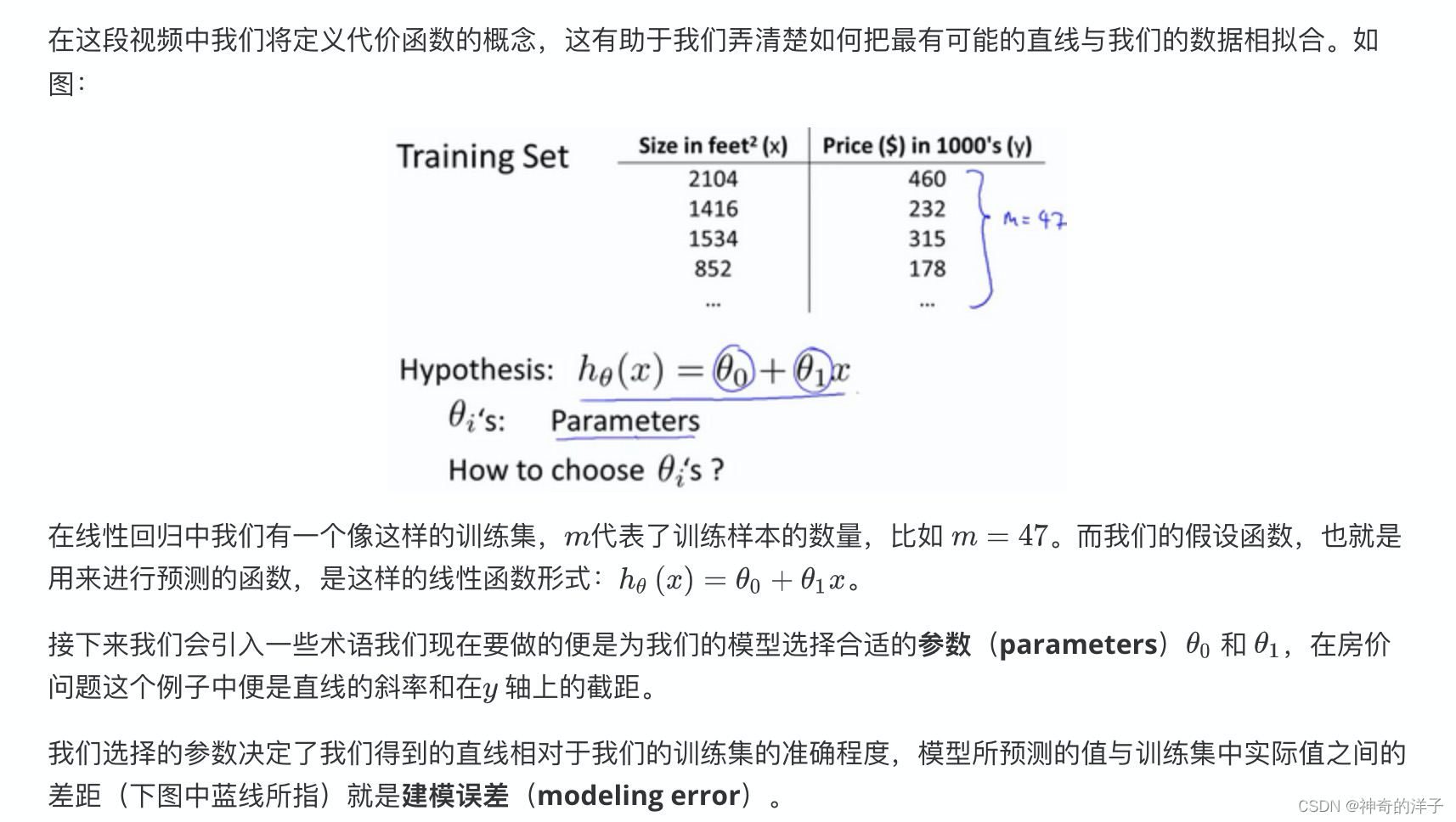
第2章
2.1 模型展示
单变量线性回归
一元线性回归模型(单变量线性回归模型)
一种可能的表达方式为: 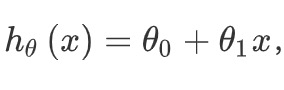
因为只含有一个特征/输入变量,因此这样的问题叫作单变量线性回归问题。h表示为假设函数

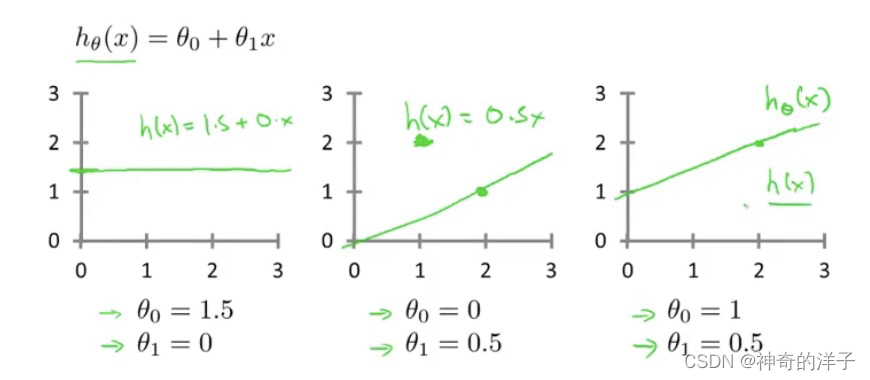
我们可以通过模型参数,a和b (对应文中的0和1两个参数),来定义不同的假设函数
2.2 代价函数
代价函数也被称作平方误差函数,有时也被称为平方误差代价函数。我们之所以要求出误差的平方和,是因为误差平方代价函数,对于大多数问题,特别是回归问题,都是一个合理的选择
整体的目标函数是使得误差平方代价函数值最小

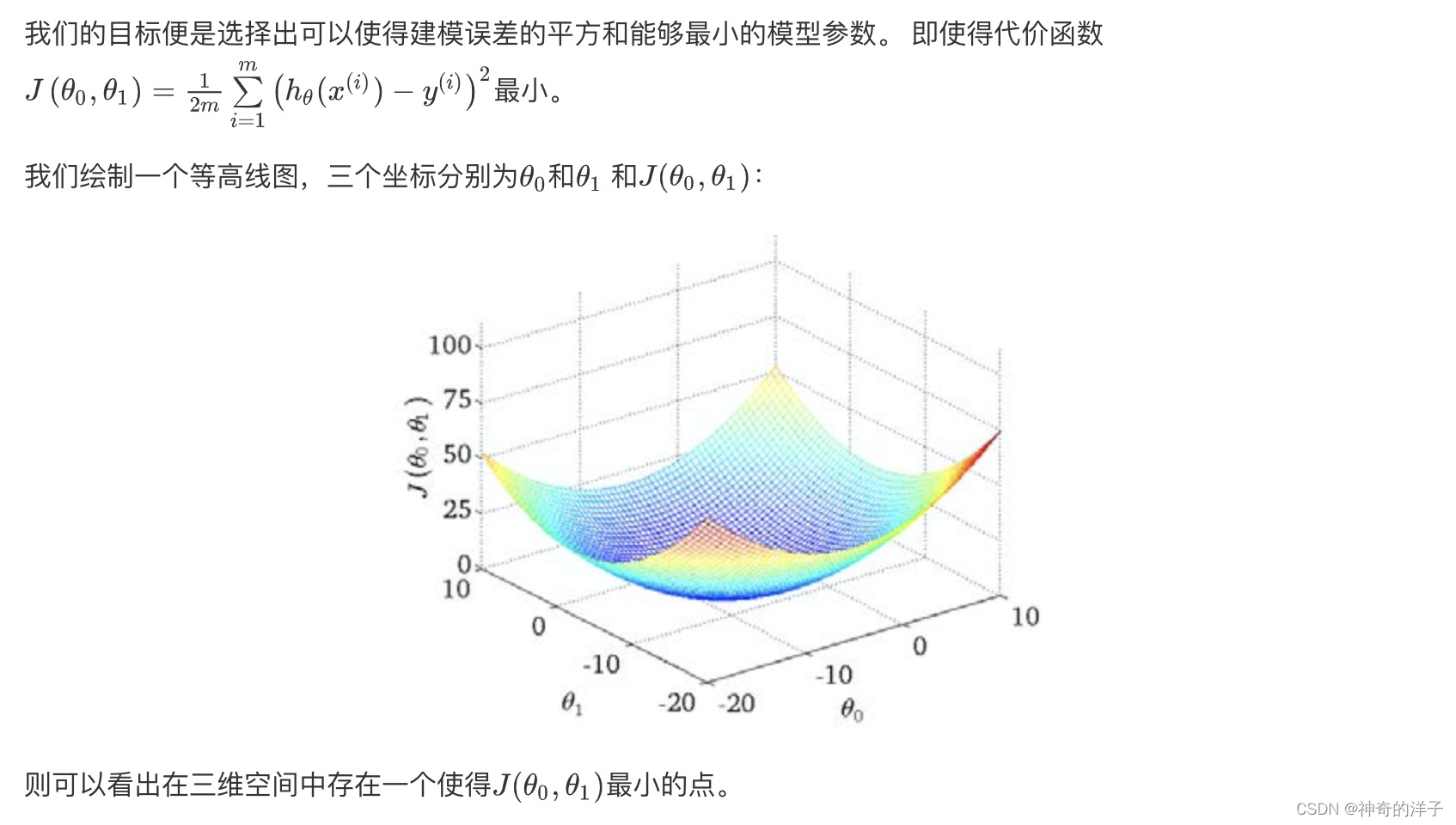
这个最小的点,对应的参数(0,1),形成最终的目标函数
看到第2张图,是等高线,所有圆圈上(参数x0,和参数x1),对应的j(x0,x1)的值都是相同的,类似于等高线
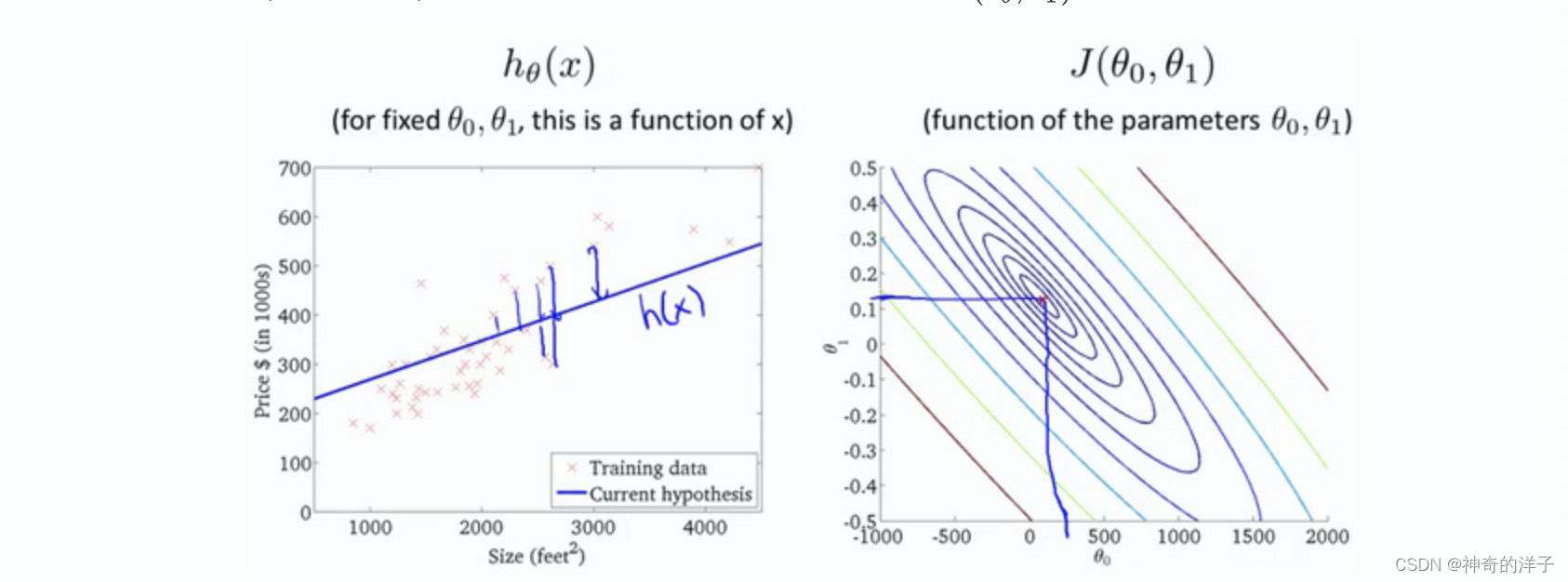
2.3-2.4 代价函数理解

提供假设函数,该假设函数有两个参数,我们通过误差平方和来定义代价函数,当选定特定的参数0和参数1,使代价函数值最小,这个就是我们的目标函数
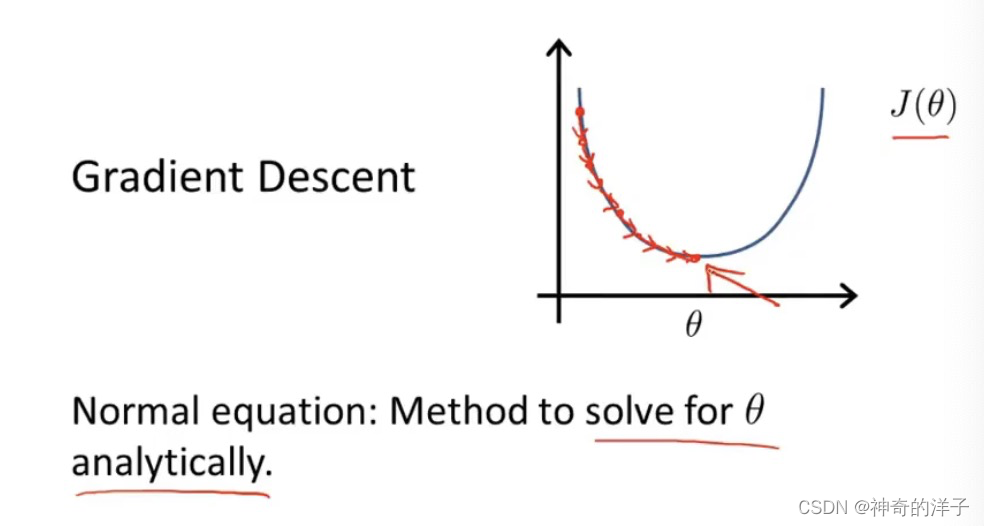
2.5-2.6 梯度下降算法,梯度下降算法理解
梯度下降算法,可以用于求函数的最小值,可用梯度下降算法来求出代价函数J(x0,x1)的最小值
梯度下降算法公式

公式当中的:= 为赋值,而=为条件判断语句(视频中是这样定义的)

另外更新x0,x1 参数需要同步更新,右边先更新x0 ,再更新x1 不是典型的梯度下降算法,结果可能不正确
梯度下降会自动采用更小的幅度,没有必要再降低学习率a
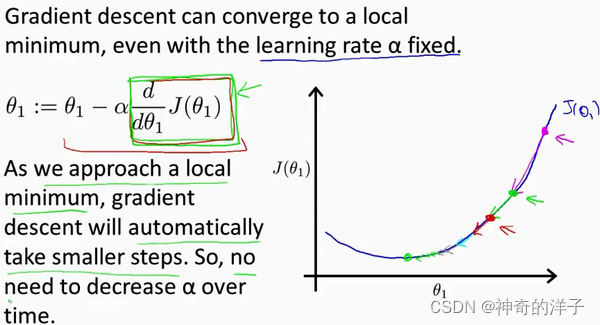
梯度下降可以收敛到一个局部最小值,即使学习率a是固定的。当接近一个局部最小值时,梯度下降会自动采取更小的步骤,所以不需要随时间减小学习率a
但就目前而言,应用刚刚学到的算法,你应该已经掌握了批量梯度算法,并且能把它应用到线性回归中了,这就是用于线性回归的梯度下降法。
如果你之前学过线性代数,有些同学之前可能已经学过高等线性代数,你应该知道有一种计算代价函数最小值的数值解法,不需要梯度下降这种迭代算法。在后面的课程中,我们也会谈到这个方法,它可以在不需要多步梯度下降的情况下,也能解出代价函数的最小值,这是另一种称为正规方程(normal equations)的方法。实际上在数据量较大的情况下,梯度下降法比正规方程要更适用一些。
现在我们已经掌握了梯度下降,我们可以在不同的环境中使用梯度下降法,我们还将在不同的机器学习问题中大量地使用它。所以,祝贺大家成功学会你的第一个机器学习算法。
在下一段视频中,告诉你泛化(通用)的梯度下降算法,这将使梯度下降更加强大。
第3章
矩阵和向量相关概念
第4章
4.2 多元(多变量)梯度下降算法

下面是单变量梯度下降和多变量梯度下降的对比
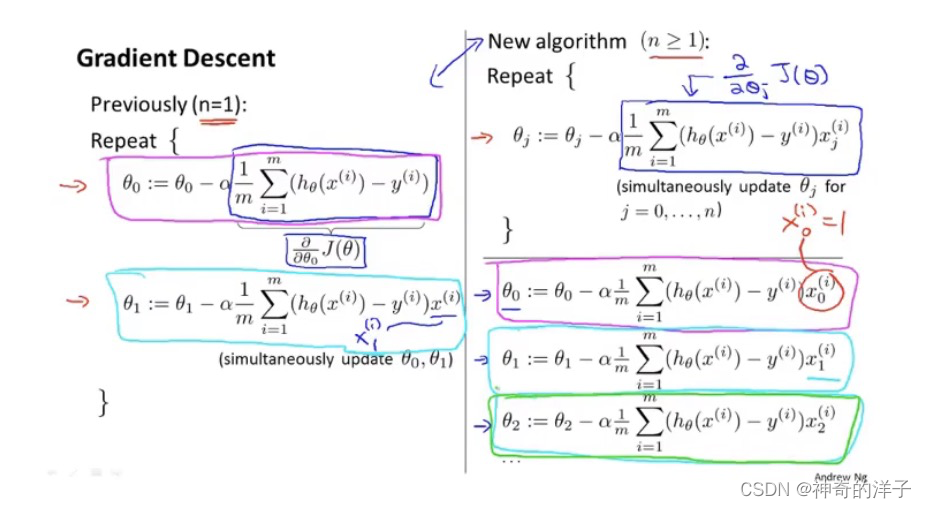
4.3 梯度下降实用技巧1-特征缩放
特征缩放,先看左边的图,如果有两个特征,一个特征是房子大小0-2000,而另一个特征是卧室的数量(1-5),那么画出来的代价函数的图像,就是椭圆状,这种图像经过梯度下降算法,很难收敛,因为(x0,x1)会来回震荡
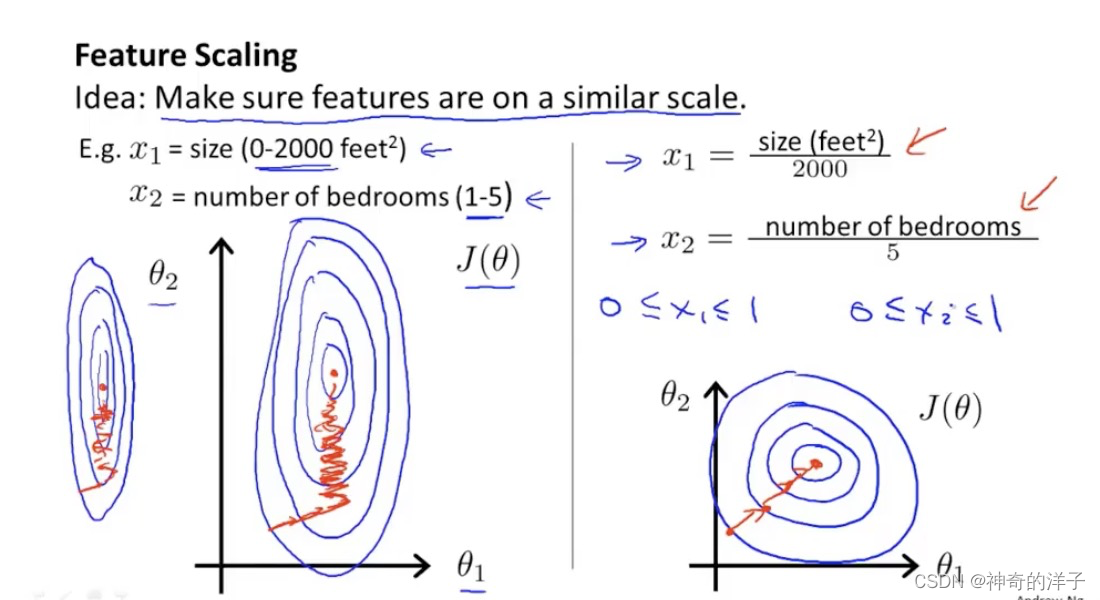
我们经过特征缩放,即x1=size/2000,x2=卧室数量/5,这样的操作后,x1与x2 都处于 0到1的范围

尽量使得每一个特征处于-1<= xi <=1 这个范围内,误差大一点也没关系,但是太大或者大小就要注意了
使用特征缩放时,有时候会进行均值归一化的操作

特征值x1= x1 -u1 / s1
这里的u1 就是训练数据集当中 x1 的平均值,而 s1 就是 x1的范围,即x1最大值-x1 最小值。 s1 也可以取x1的标准差,不过一般用x1最大值-x1 最小值就行
4.4 梯度下降算法实用技巧2 -学习率的选择

在梯度下降算法运行过程中,该图的横轴是迭代次数,而 竖轴是代价函数的最小值,通常情况下,迭代次数越多,代价函数的最小值会依次减小。有一个自动收敛测试,当J(x)小于 10-3 次方时,就认为已经收敛
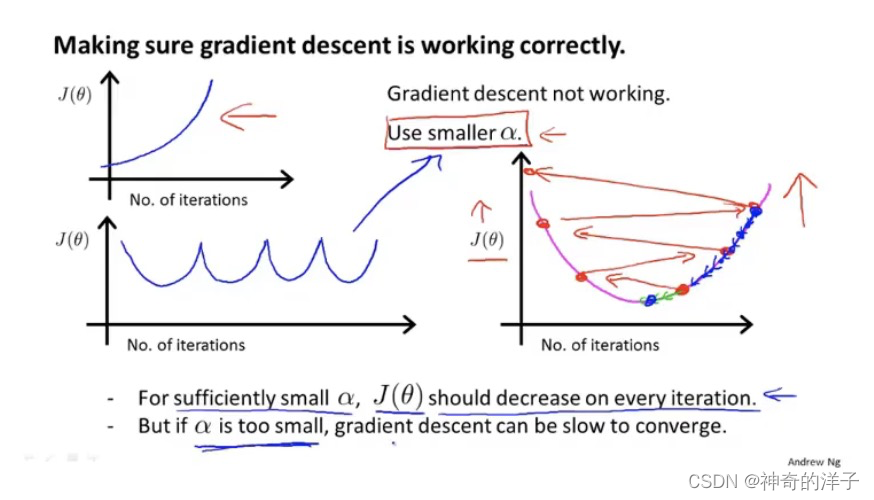
像图中的三幅图,都要降低学习率a。但是如果学习率a太小的话,收敛就会很慢,那么如何选择合适的学习率呢

先找一个最小的学习率,再找一个太大的学习率,然后取一个最大可能值或比最大值小一些的值,作为学习率
4.5 特征与多项式回归
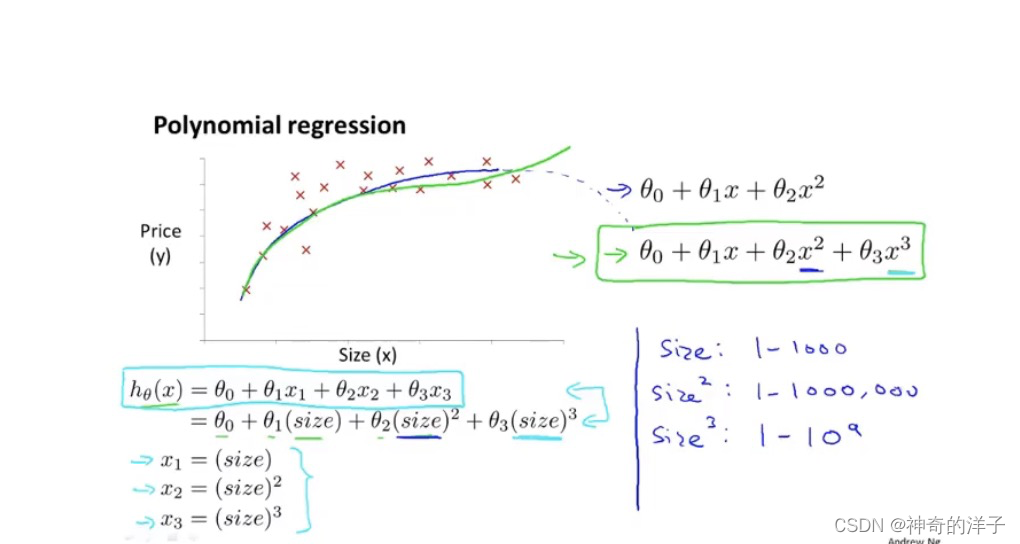
我们房子的特征,除了宽和高两个特征,还能把两者结合起来,如房子面积作为一个特征,这样有可能更能准确用来预测房子的价格

线性回归模型,假设函数除了选择直线外如 omg 0 + omg 1 x,还能选择二次多项式,或者三次多项式,这样可能拟合得更好,如果使用了梯度下降,需要特征缩放,不然size ,size 平方,size 三次方,差别太大
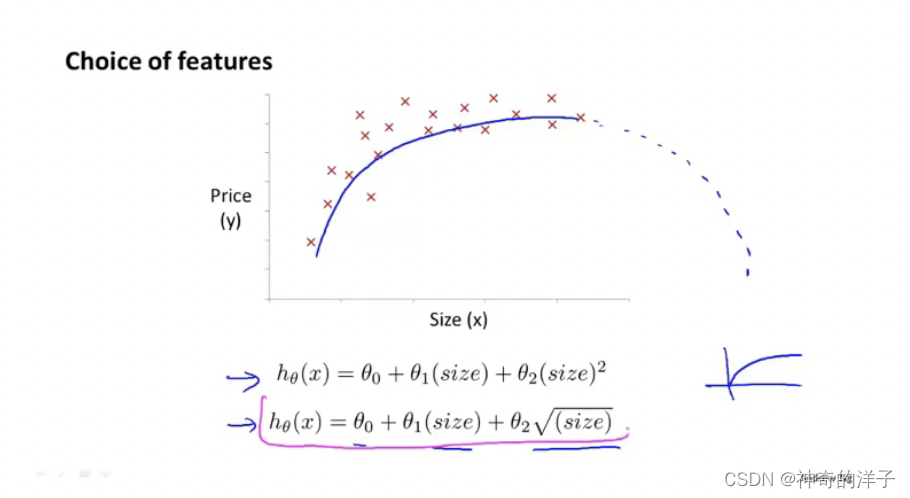
当然多项式,也可以选择平方根函数,这样或许拟合得更好。后续会介绍算法去自动选择合适的多项式
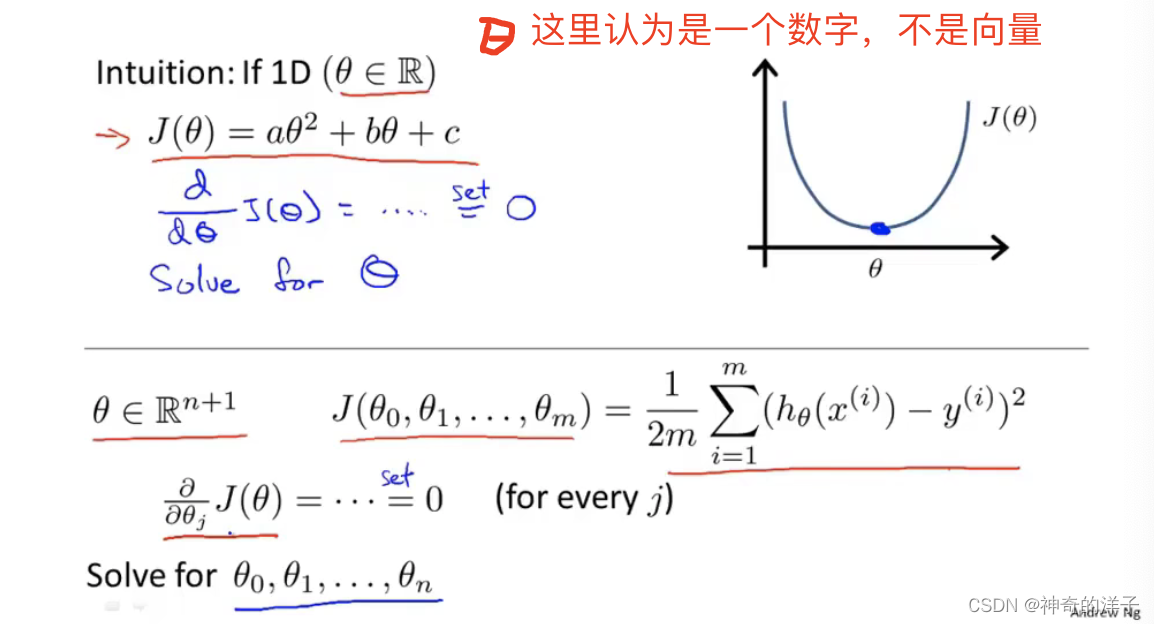
4.6 正规方程
在讲正规方程以前,我们知道使用梯度下降,是通过迭代的方法,使得代价函数不断下降
通过求导,或者求所有变量的偏微分,可以获取函数的最小值,但这样实现起来过于复杂,这里我需要知道实现原理即可
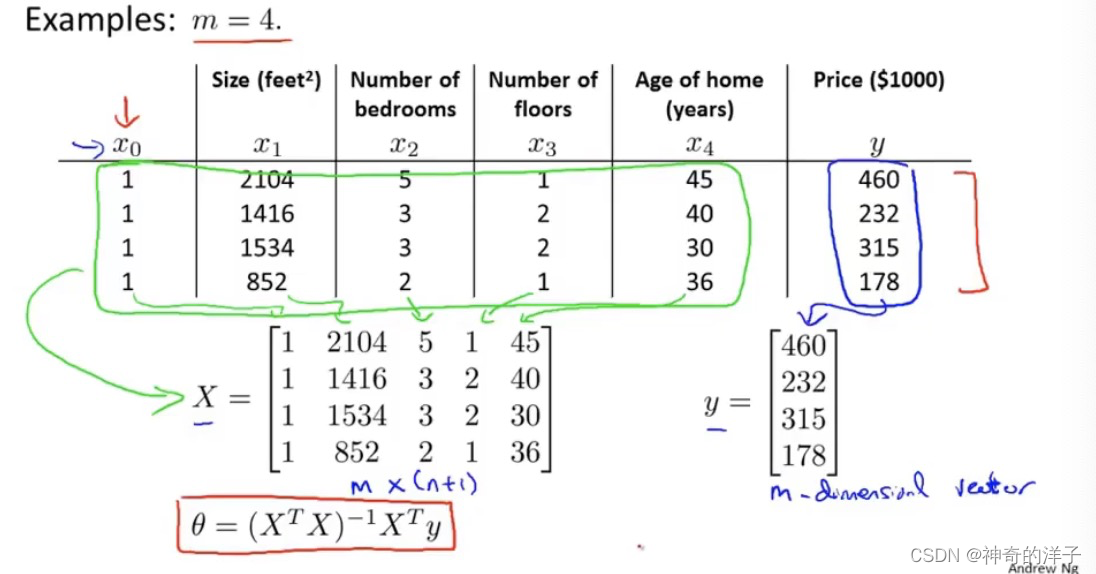
对于下面这个例子,有4个特征,我们构造x0的一列,然后表示出矩阵X和向量y,通过下面这个式子就能直接求出oumiga的最小值
构造正规方程的步骤如下
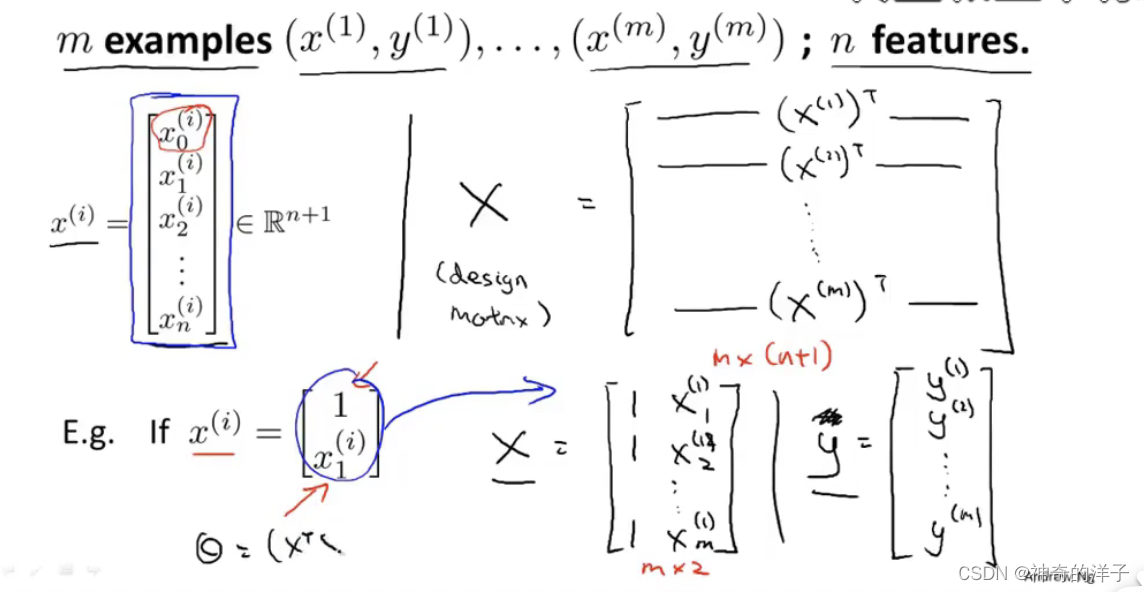
注意:使用正规方程,不用进行特征缩放
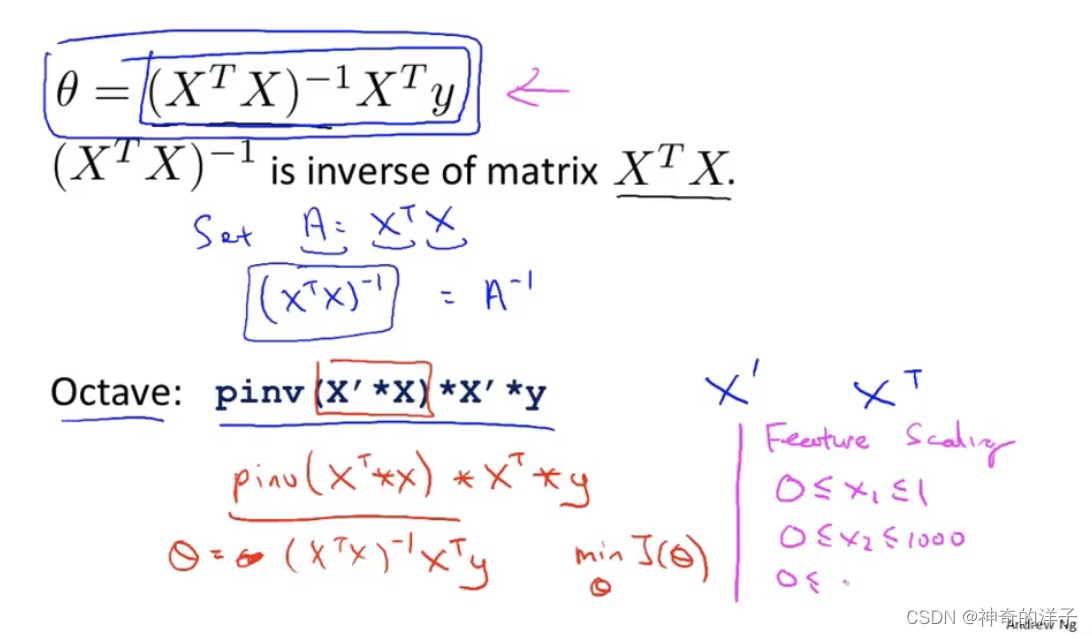
对比梯度下降和正规方程,一般特征数量 n>10000 对于线性回归模型就可以使用梯度下降

4.7 正规方程(在矩阵不可逆的时候解法)
XT.X不可逆的情况下,仍然可以使用Octave 里面的伪逆函数pinv 获取正确的结果

其余解决办法有两个,(1)一些已经线性相关的特征,如x1=(3.28)平方* x2,这时候可以去掉x2这个特征
(2)如果特征太多(比如=样本m太少,而特征n太多),可以删除一些特征,或者使用正则化方法

第5章
5.6 向量化概念
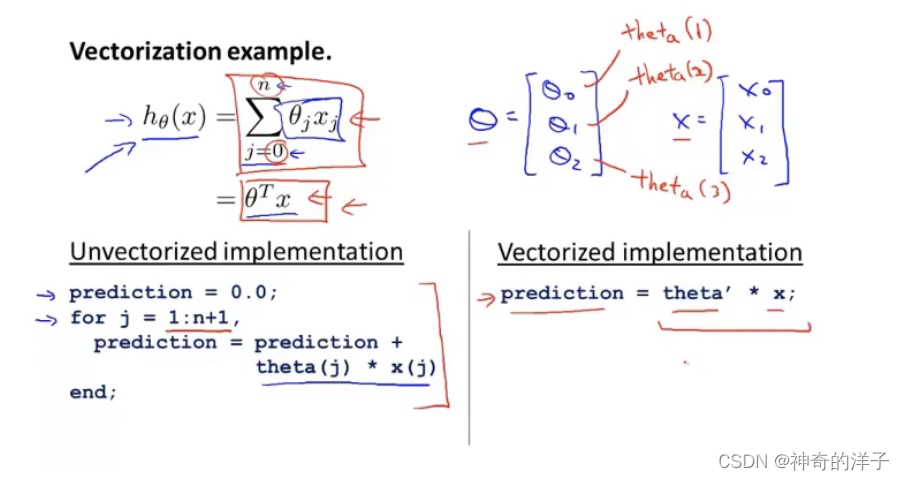
用C++ 实现向量化的计算

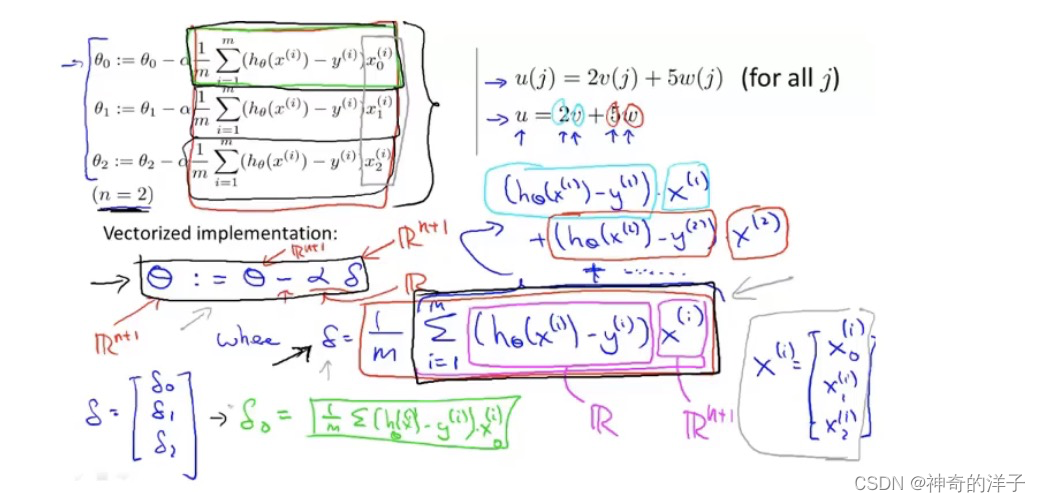
梯度下降的公式,未用向量化实现

梯度下降算法用向量化实现后的公式
第6章
6.1 分类问题

如果将线性回归用于分类问题上,看到图像1 拟合得很好,当假设函数h(x)>= 0.5 时,预测 y=1 ,就是肿瘤为恶性,当h(x)< 0.5 时,预测 y=0 ,肿瘤为良性。但如果增加一个点x ,假设函数就会变成图像2,这时当h(x)< 0.5时,预测就不准了,此时当h(x)< 0.5 ,有两个恶性肿瘤样本也被认为是良性肿瘤了
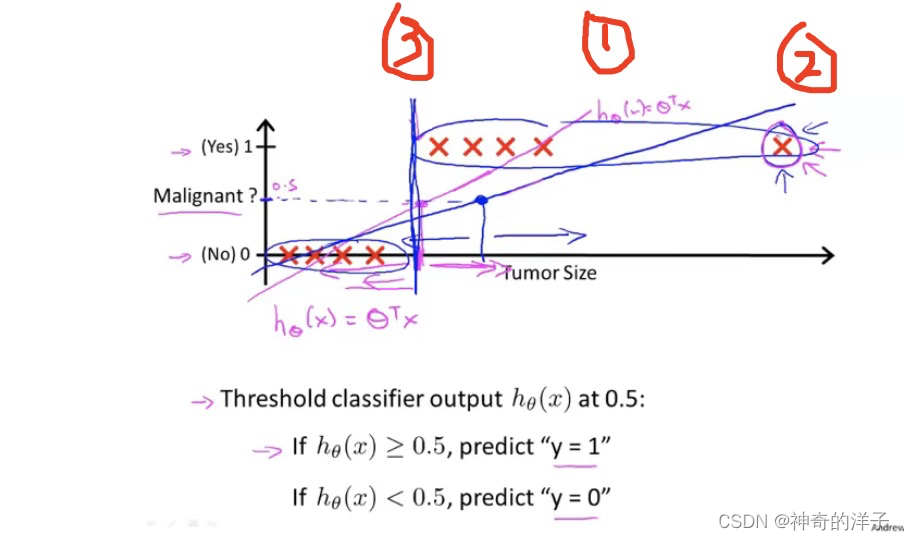
使用逻辑回归算法,可以使得假设函数的值在0-1之间

6.2 假设陈述
逻辑回归模型
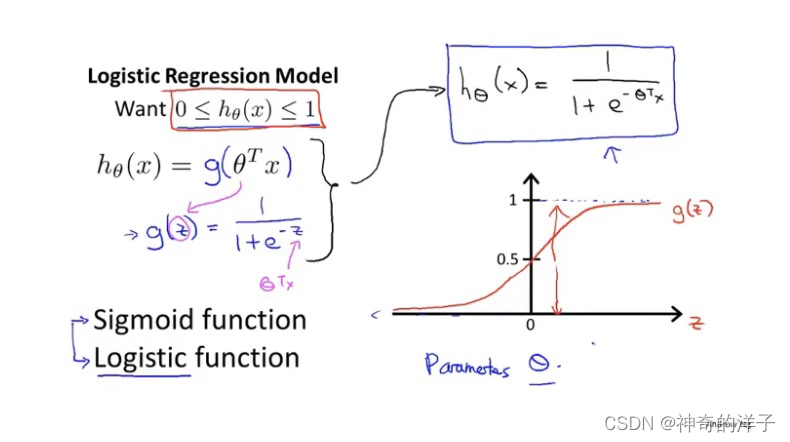
看一个具体的逻辑回归问题

P(y=0| x;oumiga) 这个公式可以理解成条件概率
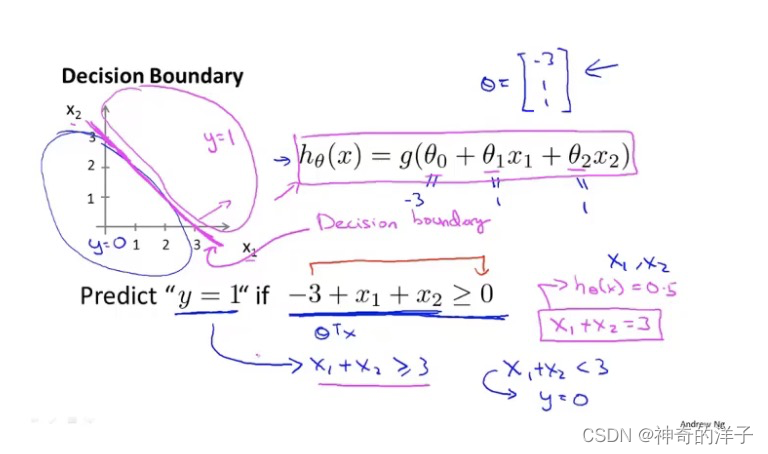
6.3 决策界限
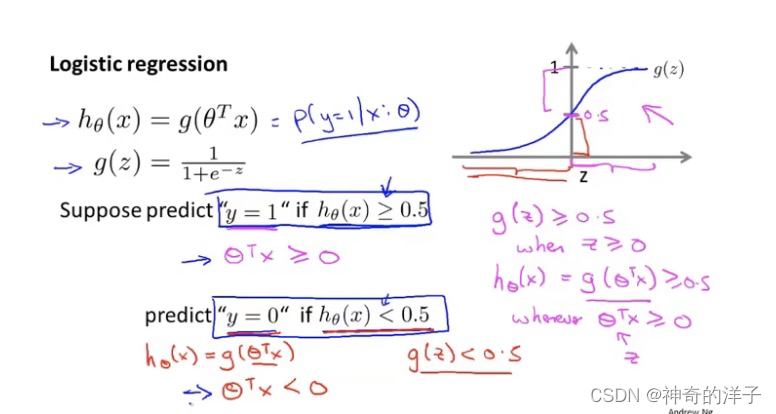
g(z)> =0.5 当 z >=0 时

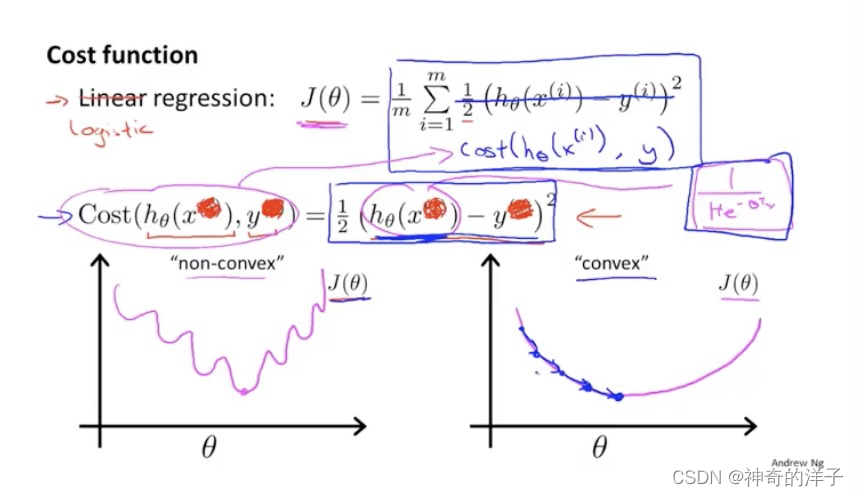
6.4代价函数
逻辑回归的代价函数选择
如果直接使用线性回归的,误差平方作为代价函数,会出现代价函数不是凸函数的情况,会得到局部最优解,影响梯度下降算法寻找全局最小值
下面是逻辑回归的代价函数
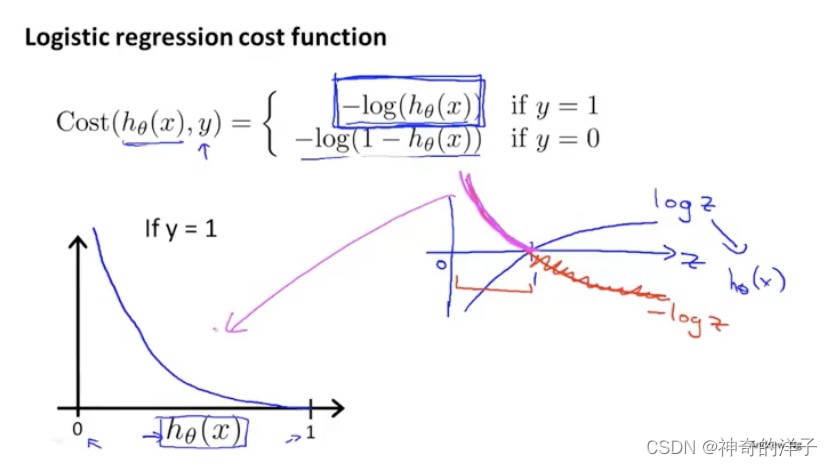
先看下if y=1 的函数图像,如果 y=1 时,h(x)接近为0,这时候认定他是一个恶性肿瘤,这时候代价会很大(因为之前预测是h(x)<0.5 是良性)

下面是y=0的代价函数,当h(x)=1 时,若还是预测y=0 ,代价会非常高
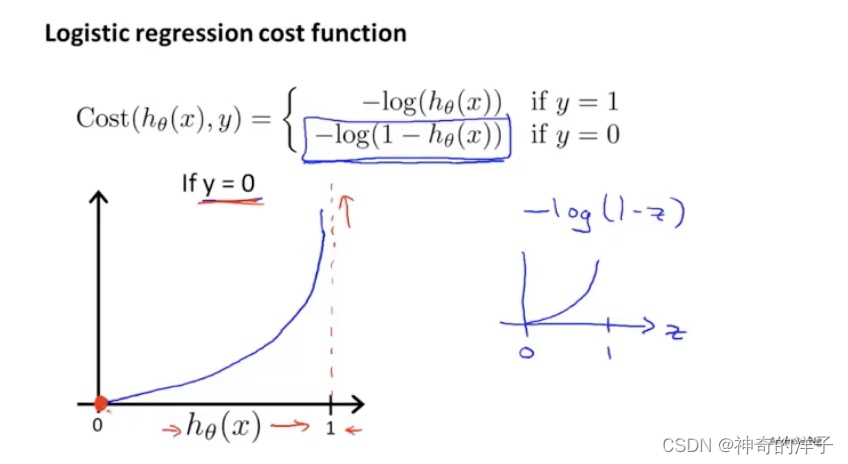
6.5 简化代价函数与梯度下降
可以将逻辑回归的代价函数进行简化

注意,假设函数的输出值,表示的P(y=1 |x;oumiga即为恶性肿瘤的概率,逻辑回归的代价函数,是根据统计学当中的最大似然估计得出的



下面的图1,少了1/m,网上说也可以归到学习率里面去
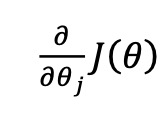
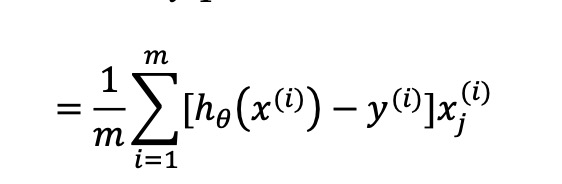
图1

利用梯度下降算法找到代价函数的最小值,表面上看上去与线性回归的梯度下降算法一样,但是这里 的h𝜃(𝑥) = 𝑔(𝜃𝑇𝑋)与线性回归中不同,所以实际上是不一样的。另外,在运行梯度下降算法 之前,进行特征缩放依旧是非常必要的
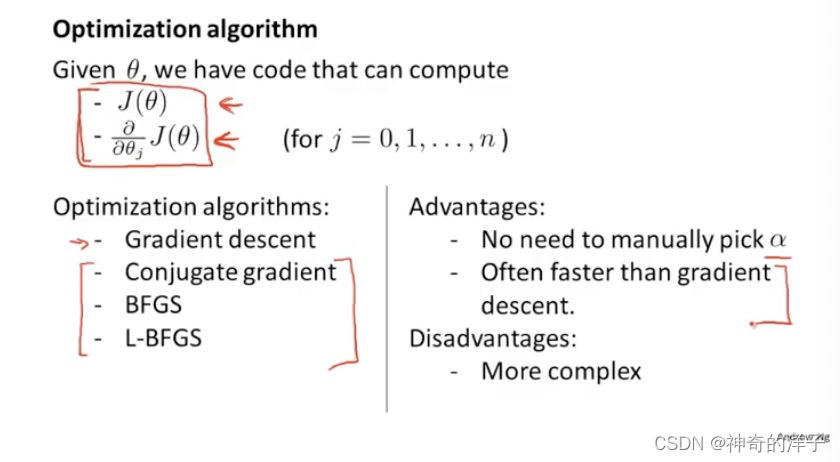
6.6 高级优化
梯度下降的原理

(1)共轭梯度法,(2) BFGS(变尺度法) 和 (3)L-BFGS(限制变尺度 101
就是其中一些更高级的优化算法,它们需要有一种方法来计算 𝐽(𝜃),以及需要一种方法 计算导数项,然后使用比梯度下降更复杂的算法来最小化代价函数
右边这个使用octave 的costFunction函数,会有两个返回值,一个是jval,另外一个是gradient

6.7 多元分类:一对多

前面是谈到了二分类问题,下面是处理多个分类的问题
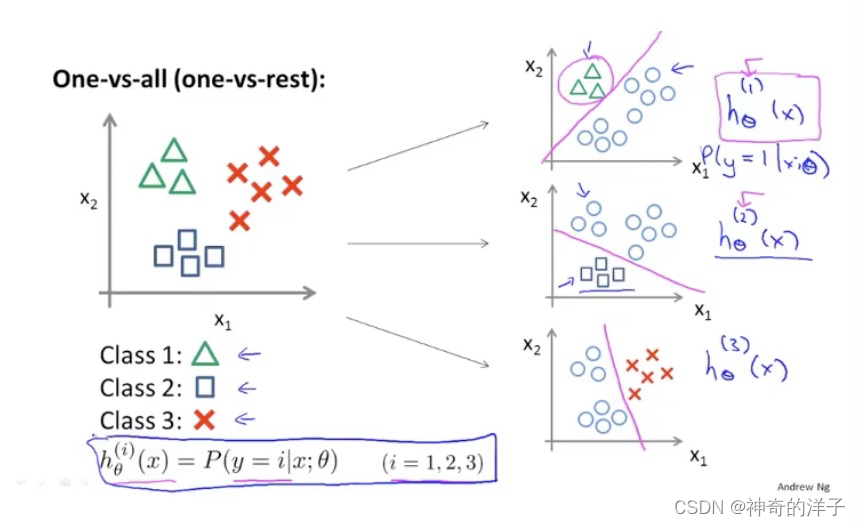
现在要做的就是训练这个逻辑回归分类器:h(𝑖)(𝑥), 𝜃
其中 𝑖 对应每一个可能的 𝑦 = 𝑖 。训练好了以后, 三个分类器𝜃 就已经全部确定了
最后,为了做出预测,我们给出输入一个新的 𝑥 值,用 这个做预测。我们要做的就是在我们三个分类器里面输入 𝑥,然后我们选择一个让 h(𝑖)(𝑥)
最大的𝑖,即max h(𝑖)(𝑥)。 如i=1,输入x的样本,h1(x) 为0.3 ,h2(x)为0.4 ,h3(x)为0.2,那么预测该样本x,对应为y=1

第7章
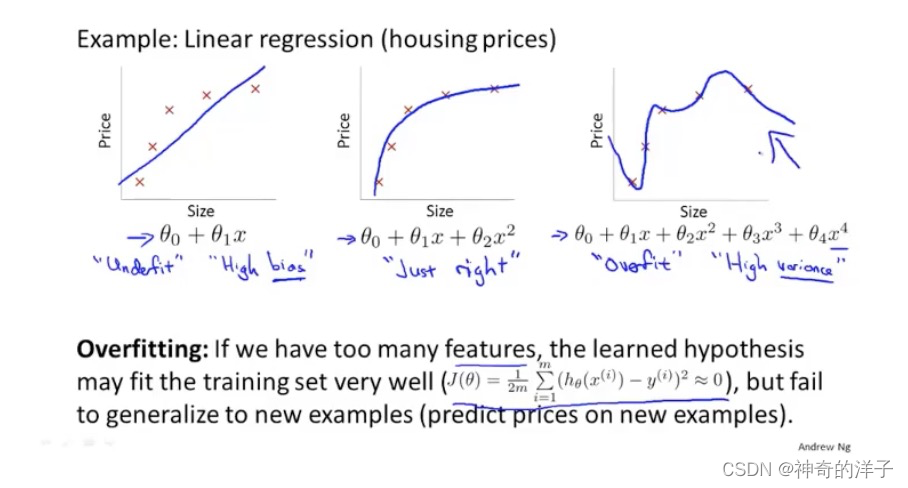
7. 1过拟合问题
下面三张图,分别是欠拟合,拟合刚好,和过拟合。
第一个模型是一个线性模型,欠拟合,不能很好地适应我们的训练集;第三个模型是一 个四次方的模型,过于强调拟合原始数据,而丢失了算法的本质:预测新数据。我们可以看 出,若给出一个新的值使之预测,它将表现的很差,是过拟合,虽然能非常好地适应我们的 训练集但在新输入变量进行预测时可能会效果不好;而中间的模型似乎最合适。
除了线性回归,在逻辑回归当中,也会出现过过拟合的情况
如下面的图1是欠拟合,图3是过拟合
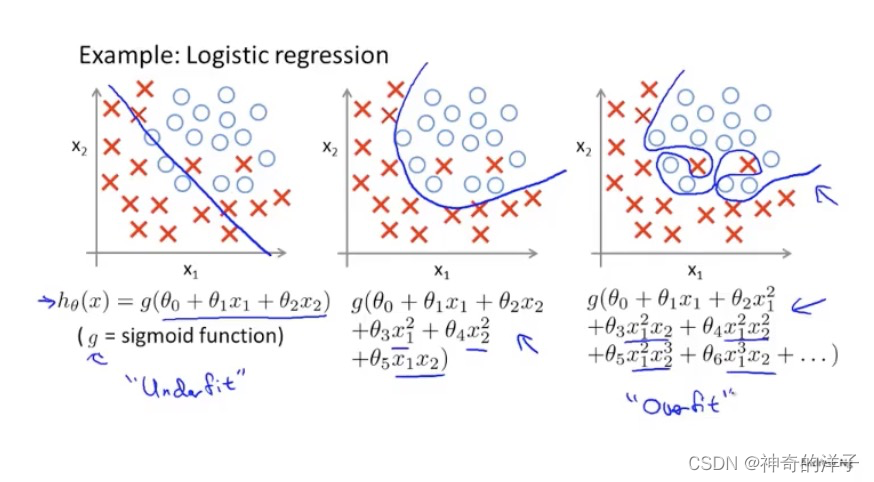
就以多项式理解,𝑥 的次数越高,拟合的越好,但相应的预测的能力就可能变差。并且特征太多,样本太少就有可能出现过拟合的情况,我们也不能随便去掉一些特征。

如果我们发现了过拟合问题,应该如何处理?
1.丢弃一些不能帮助我们正确预测的特征。可以是手工选择保留哪些特征,或者使用一 些模型选择的算法来帮忙(例如 PCA)
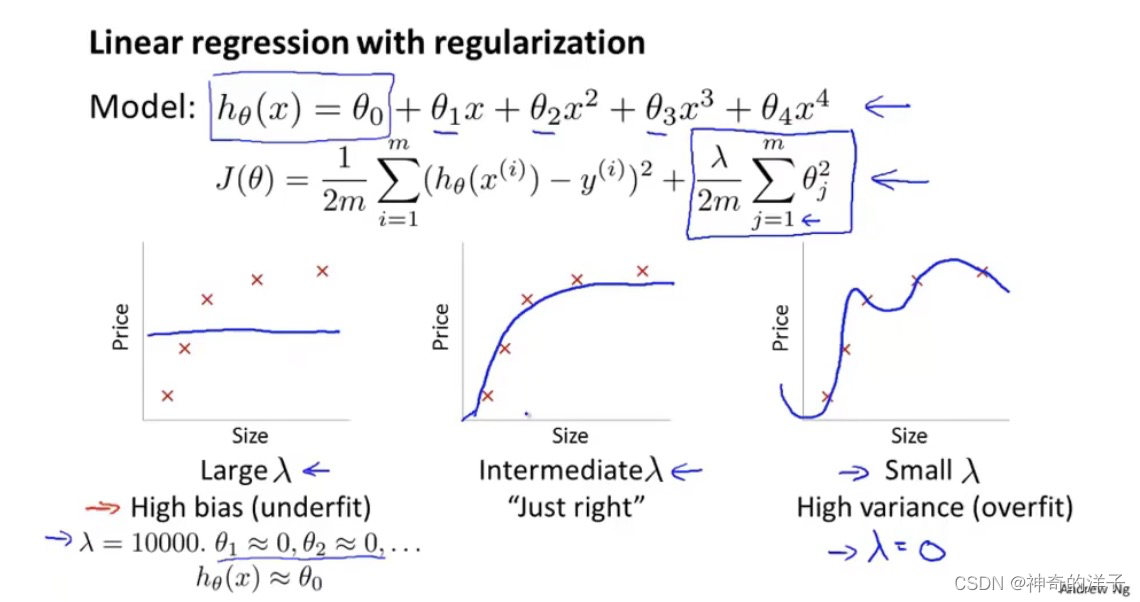
2.正则化。 保留所有的特征,但是减少参数的大小(magnitude)。

7.2 代价函数

这里可以加入正则惩罚项,在减少参数𝜃 的值
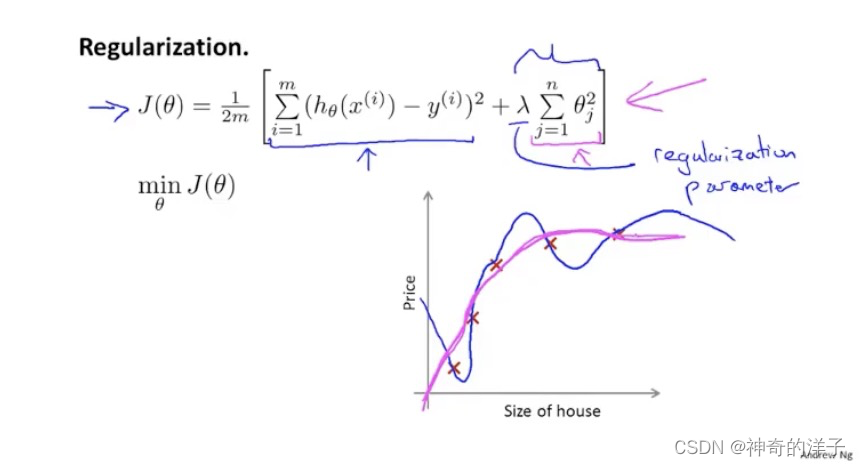
如果选择的正则化参数 λ 过大,则会把所有的参数都最小化了,导致模型变成 h𝜃(𝑥) = 𝜃0,也就是上图中红色直线所示的情况,造成欠拟合。

7.3 线性回归的正则化
线性回归有两种办法来获取代价函数最小值,一种是梯度下降算法,另一种是正规方程,下面将正则化,融入到以下两种算法
梯度下降算法,加入正则化的式子后,需要对𝜃0 单独处理一下

正规方程加入正则化后

正则化后的正规方程 ,不会出现矩阵不可逆的情况

7.4 正则化的逻辑回归模型
在逻辑回归当中,有两个方式来减小代价函数,一种是使用梯度下降,另外一种是更高级的算法(1)共轭梯度法,(2) BFGS(变尺度法) 和 (3)L-BFGS(限制变尺度 101
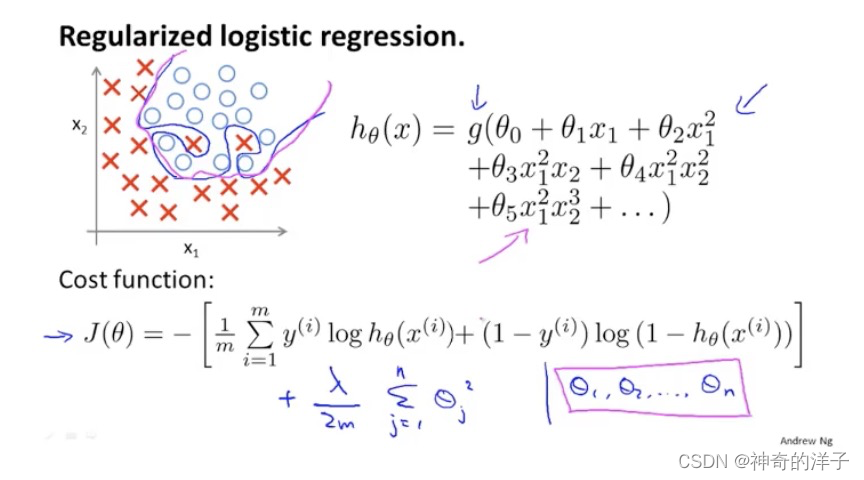
在逻辑回归当中,使用梯度下降算法,加入正则化后的表达式如下:

结合Octave ,可以使用更高级的算法或者梯度下降算法,减少代价函数值,下面是加入正则化项的方法

第8章
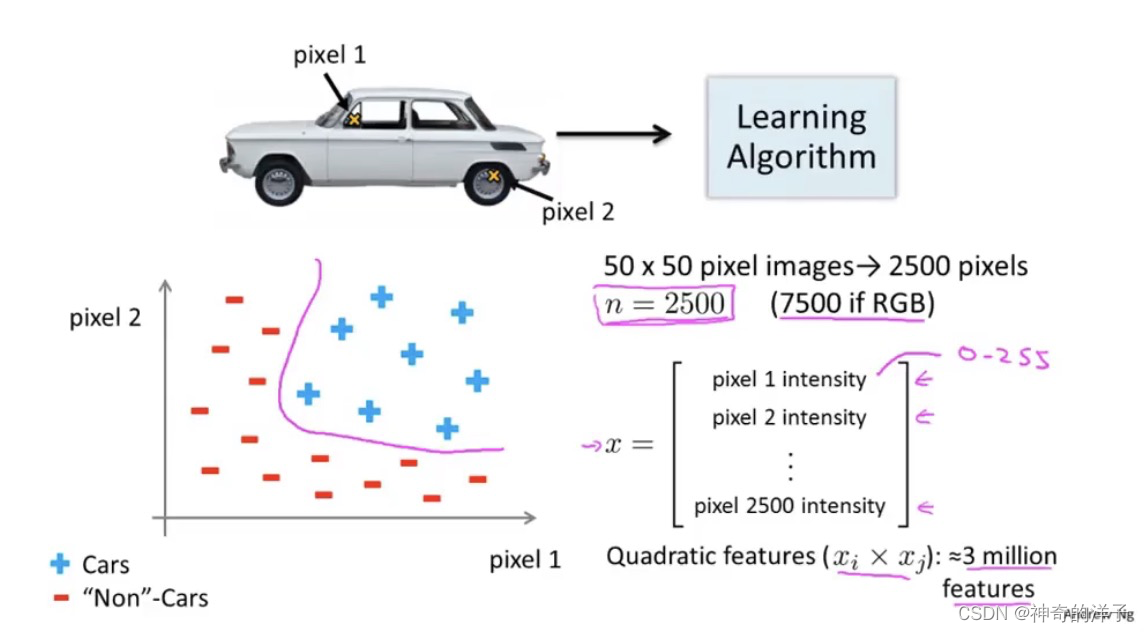
8.1 非线性建设
两个特征乘积=2500*2500/2约等于300w
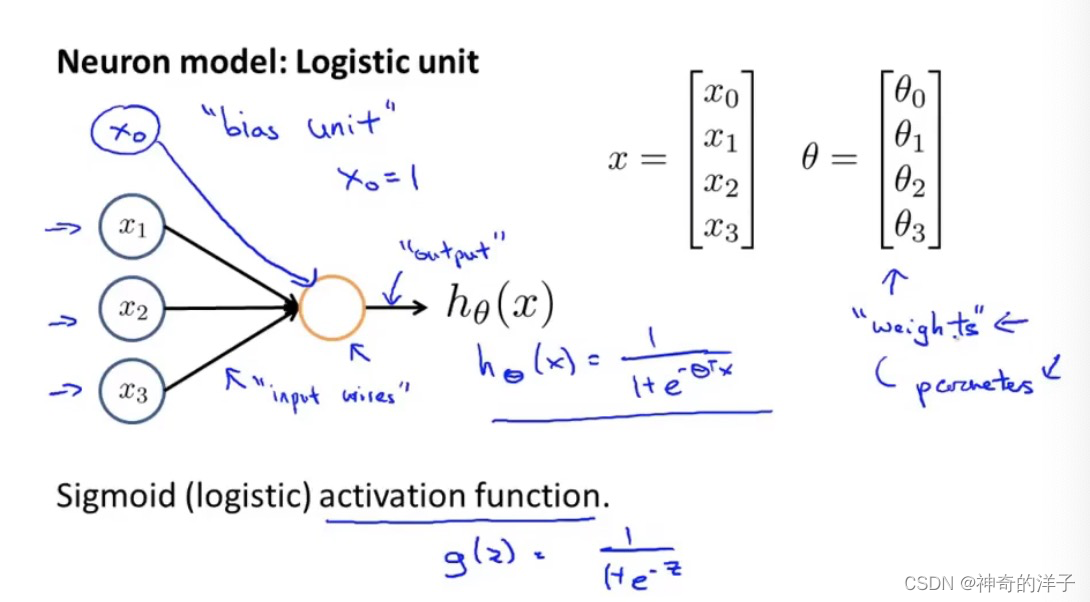
8.3 模型展示I
一个带有激活函数的人工神经元,𝜃 为模型的参数,在神经网络里面表示模型的权重
常用激活函数
https://blog.csdn.net/tyhj_sf/article/details/79932893
x0=1 可以自己根据需要添加
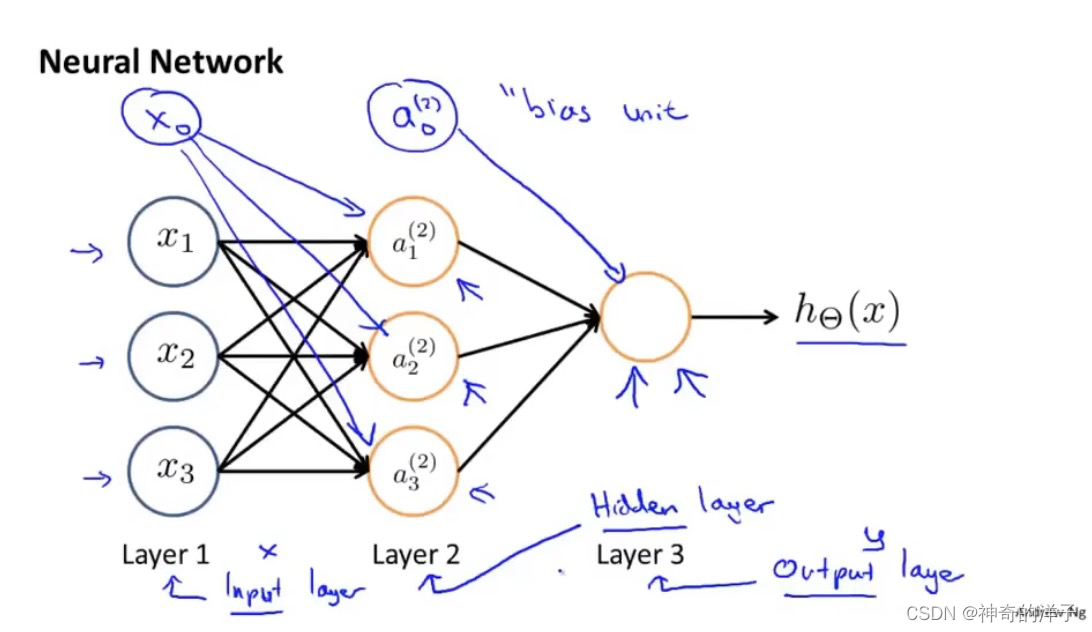
输入层,隐藏层,输出层
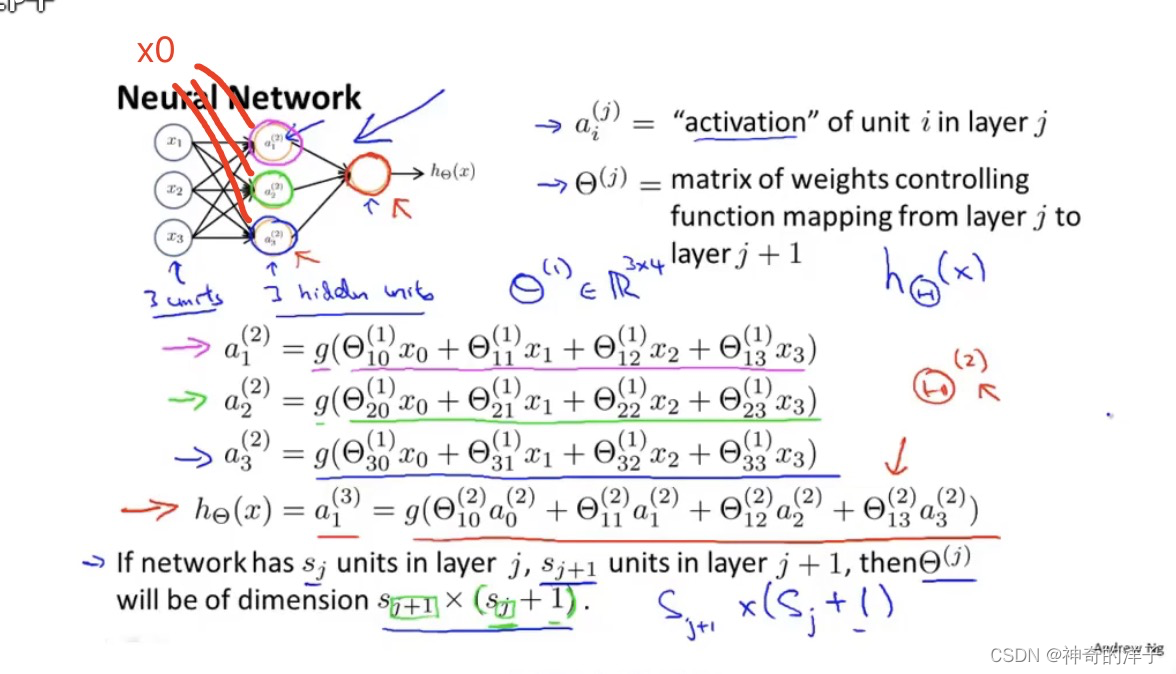
theta表示权重,下标表示所代表的那个位置,theta10 表示第一层的第0个位置,theta上标1表示第一层
注意theta是一个矩阵,为什么theta 1 是3*4的矩阵,因为输入层还有1个偏置单元x0
一般定义,如果神经网络在第j层有sj个单元, 在j+1 层有s j+1 个单元,则theta(j)是一个s j+1 乘(sj +1) 的矩阵。即第1层有3个单元,第2层有3个单元,则theta(1)是一个 3乘 4 的矩阵。
个人推测:看下图 a1(2),a2(2),a3(2) 后面就是一个线性方程,把theta 转化成一个矩阵
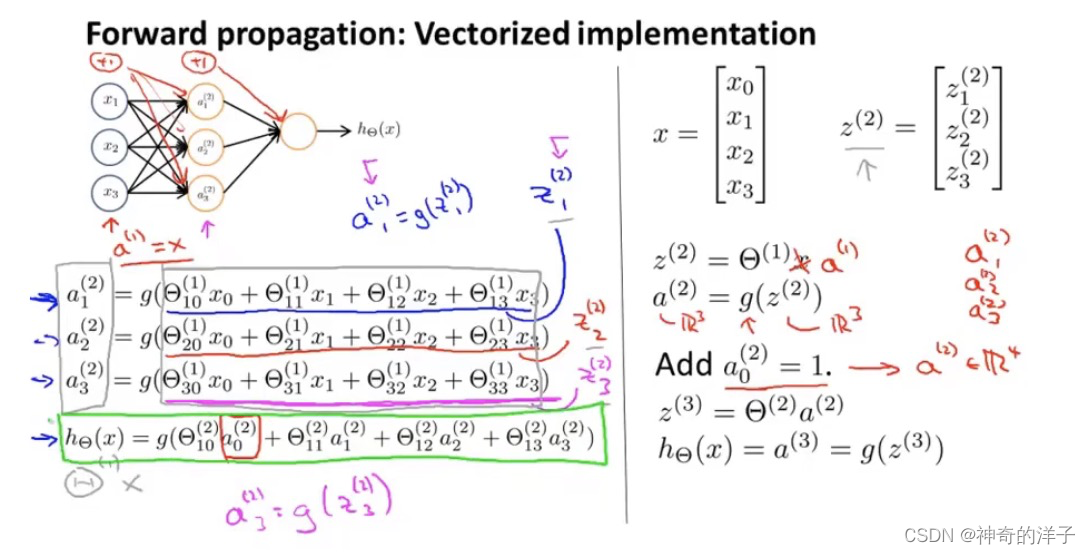
8.4 模型展示II
x1与a1 是加入的偏置项,a(2)是一个三维向量,a1(2),a2(2),a3(2)是其中的元素,都是由实数去组成。如果加入偏置项,a(2)就是一个4维向量。注意最后的h(x)=a(3),因为a(3)是一个常数,所以最后的h(x)也是一个常数,用到逻辑回归,所以数字是表示一个概率
在神经网络当中,根据theta 选择不同的参数,可以得到隐藏层更好的特征
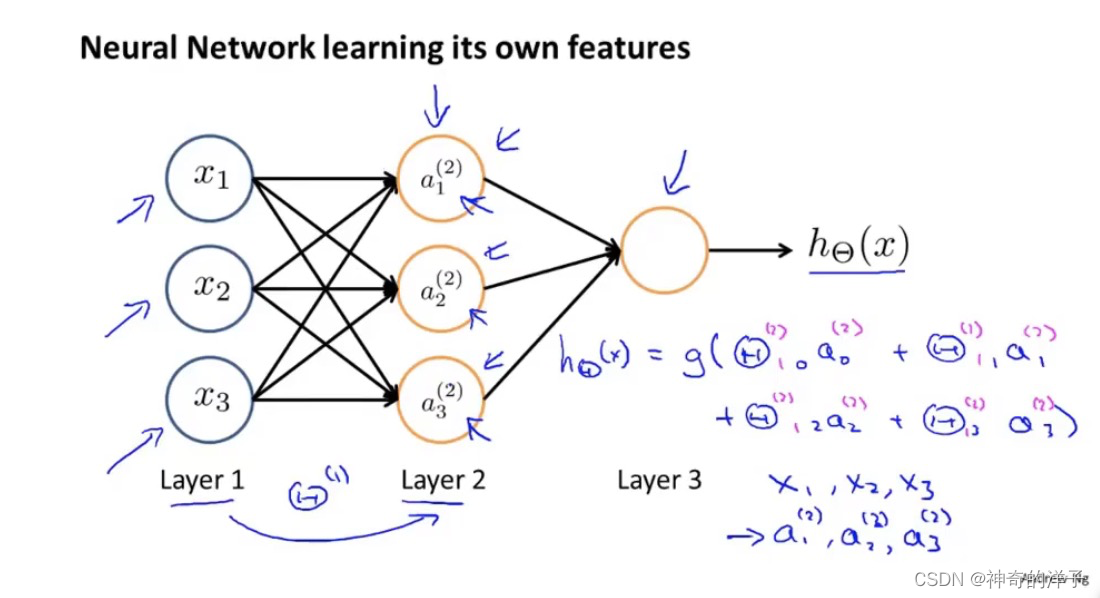
我们可以把𝑎0, 𝑎1, 𝑎2, 𝑎3看成更为高级的特征值,也就是𝑥0, 𝑥1, 𝑥2, 𝑥3的进化体,并且它们 是由 𝑥与决定的,因为是梯度下降的,所以𝑎是变化的,并且变得越来越厉害,所以这些更 高级的特征值远比仅仅将 𝑥次方厉害,也能更好的预测新数据。
这就是神经网络相比于逻辑回归和线性回归的优势
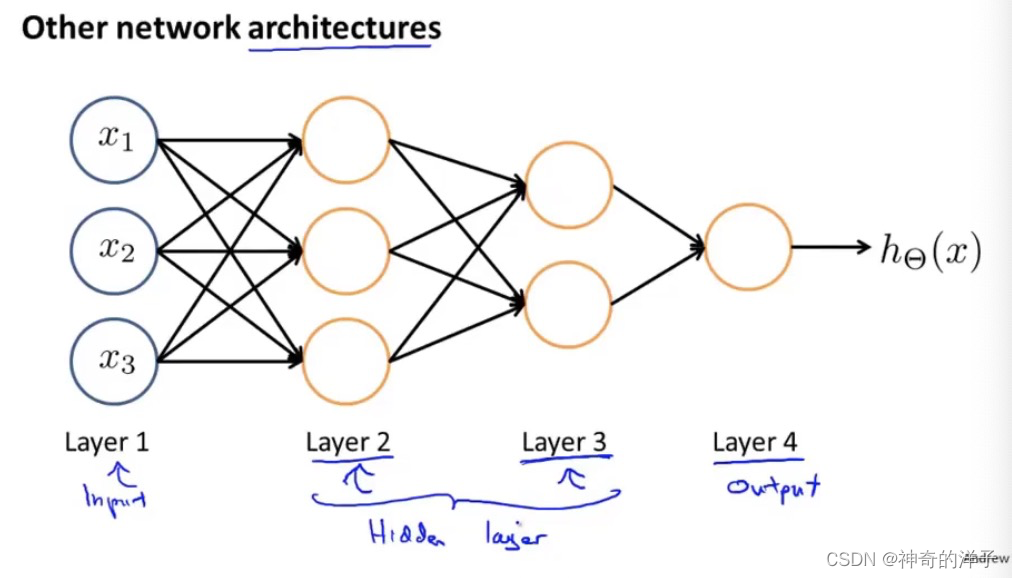
根据前向传播的原理,从输入层传递到隐藏层1,再前向传播到隐藏层2,最后到达输出层
8.5 例子与直观理解神经网络 I
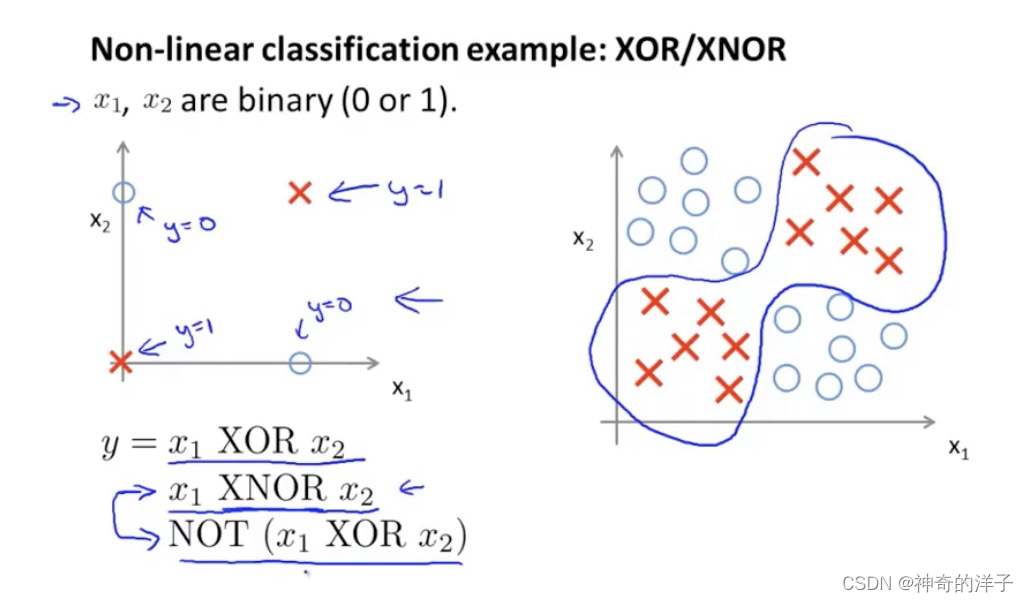
异或,以及假异或(当两数异或为真时,取假)
先看与的例子,假设函数 h(x)=g(-30+20x1+20x2) 这里的参数已经确定好了,S型g(z)的激活函数如下图,其值范围是0-1
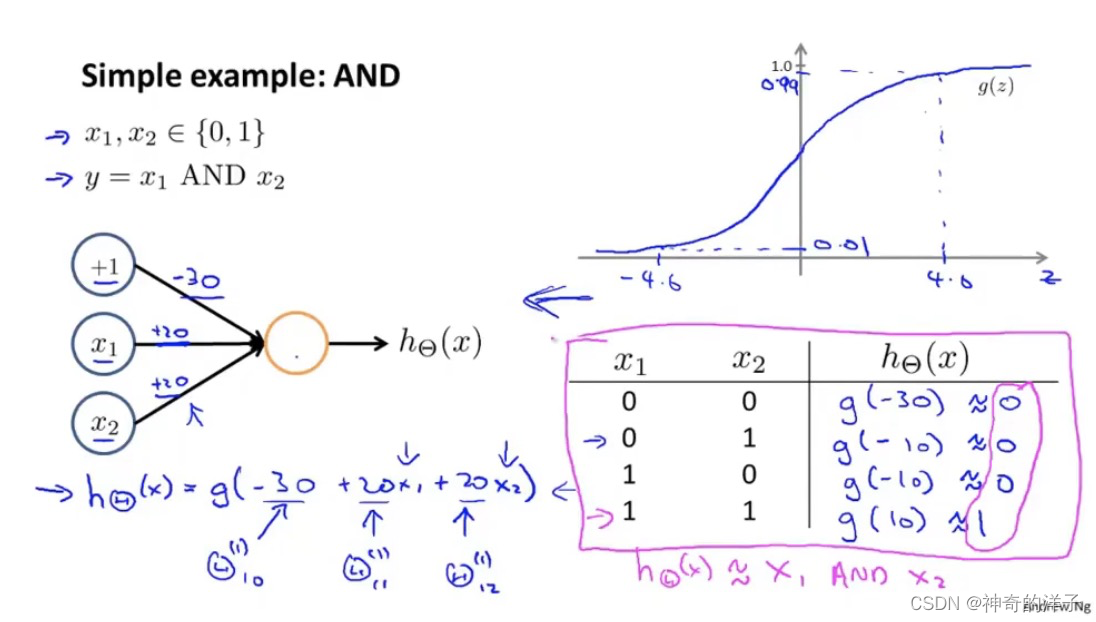
下面是逻辑或的例子

8.6 例子与直观理解神经网络 II
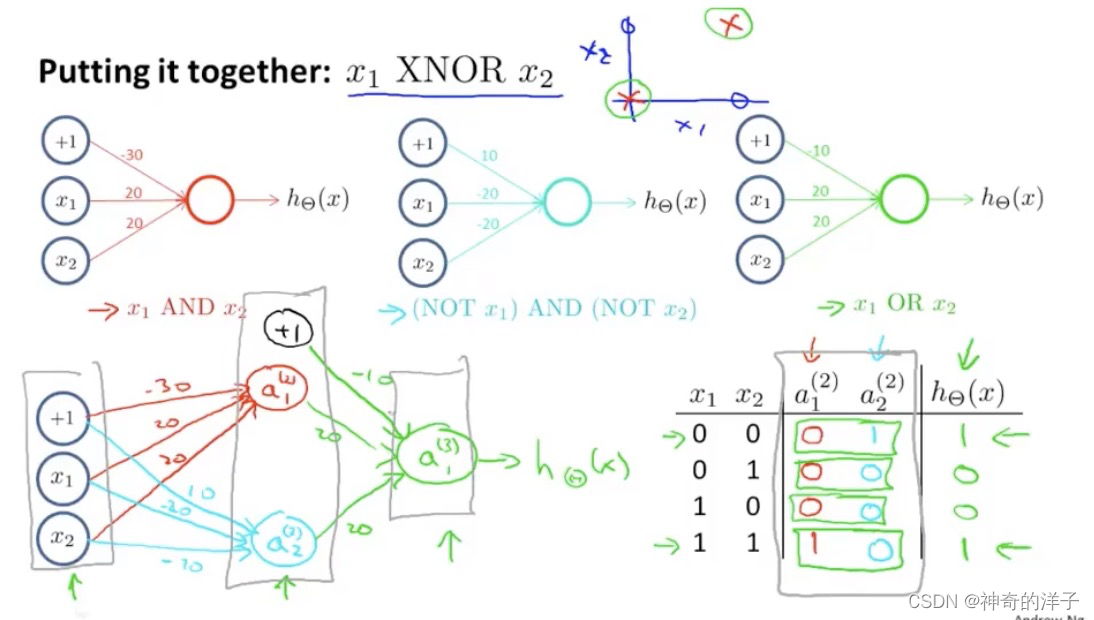
逻辑非的例子,把输入的x1 ,加入一个比较大的负权重即可

我们要得到x1 XNOR x2 的结果,可以分别在输入层计算 x1 and x2 (参数分别为-30 20 20 就是实现了这个功能), 隐藏层计算 (not x1) and (not x2) ,在输出层计算 x1 or x2 。注意最开始输入层的x1 x2 是经过激活函数处理的,如输入x1=0 x2=0 ,则a1(2)=g(1* -30 +0 20 +020 )=g(-30) ,根据计算激活函数Sigmoid函数,g(-30) =0=a1(2),其他同理
一个识别手写数字的例子,最左边经过输入层处理后,中间是隐藏层处理,最后是输出层处理

8.7 神经网络解决多元分类
最后的结果h(x) ,是一个4维向量,表示该图片是马路,汽车,摩托,火车当中的一种
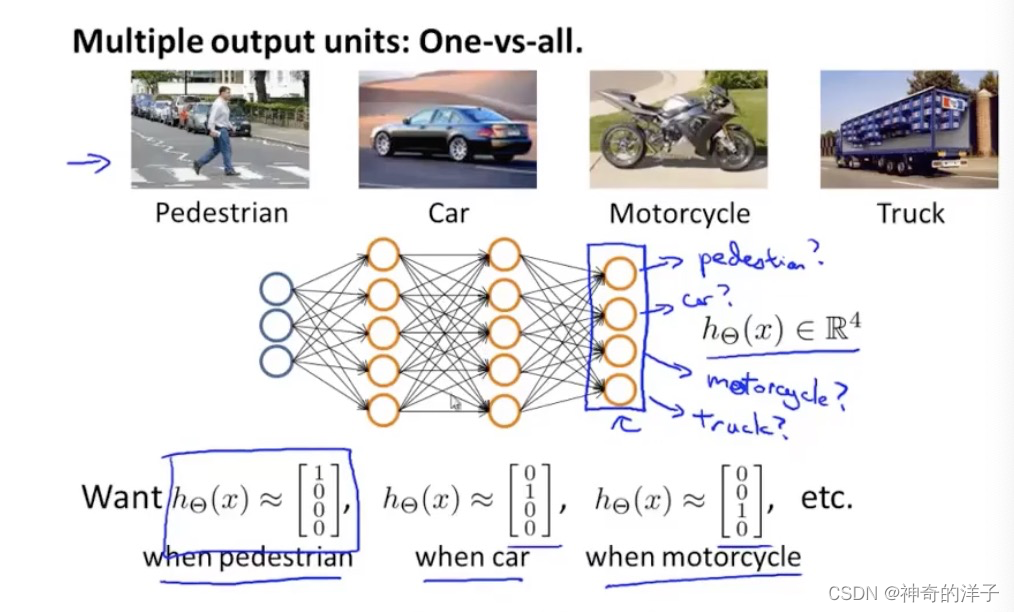
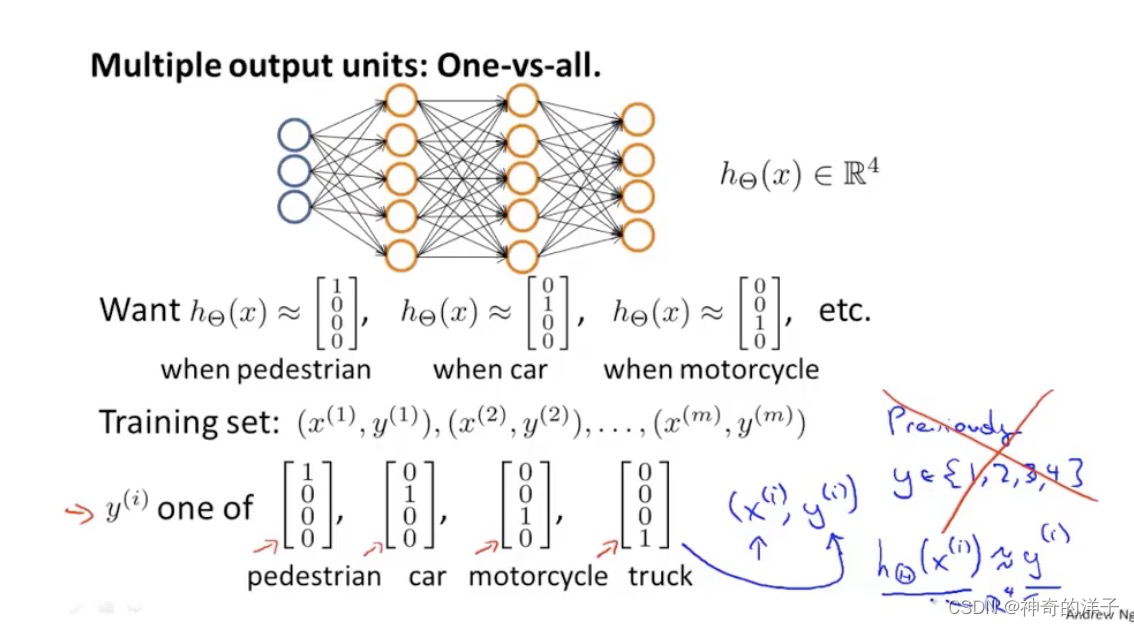
训练集的表示方法,如下图所示。这里的y是一个4维向量,而不是一个数字
第9章
9.1 代价函数
这里讲解神经网络,在分类问题上面的应用
K为输出层的单元数量,S L 代表输出层(L为最后一层的序号),K 要大于等于3,不然没有必要去使用多分类。对于二分类,h(x)是一个实数。而对于多分类问题,h(x) 是一个K维向量
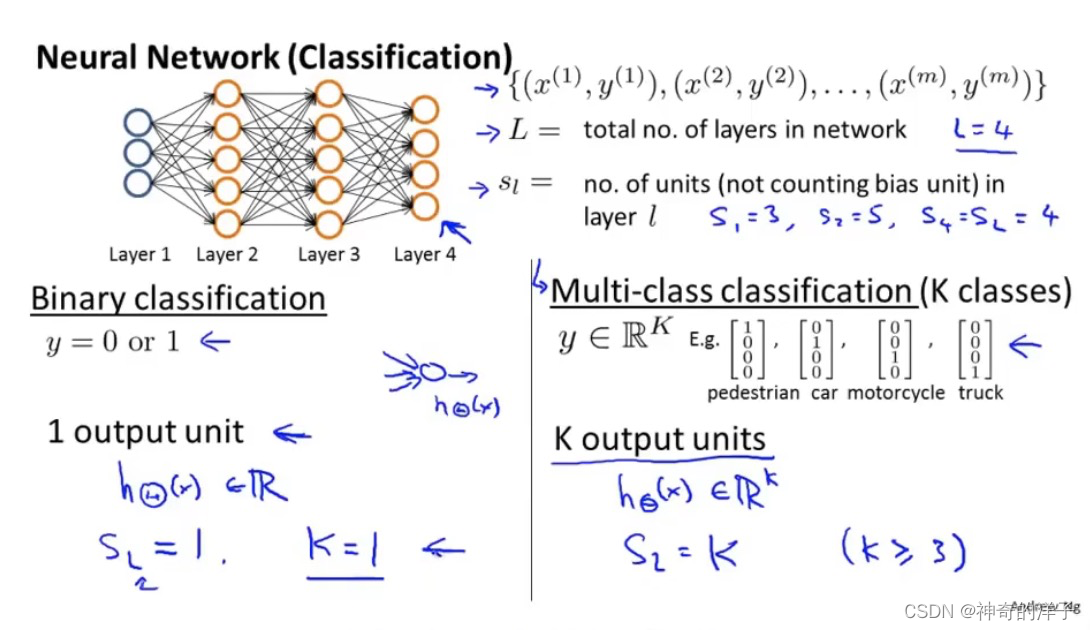
注意这里正则化项,不考虑偏置项,所以下面标从1开始
9.2 反向传播算法
要想得到代价函数的最小值,需要计算J(theta),和J(theta)中 theta ij(l)的所有偏导项

这里是前向传播算法的过程

反向传播算法当中误差的定义,有两点需要理解和注意,g(z(3))求导是复合函数求导,参考链式求导法则
https://blog.csdn.net/bianjingshan/article/details/80508870
第2个,这里的偏微分项如果要求不严谨,忽略掉𝜆 的正则项,把𝜆 lambda 设置为0
看推导可以看李宏毅的推导
https://www.bilibili.com/video/BV1Wv411h7kN?p=2
鲁鹏计算机视觉神经网络
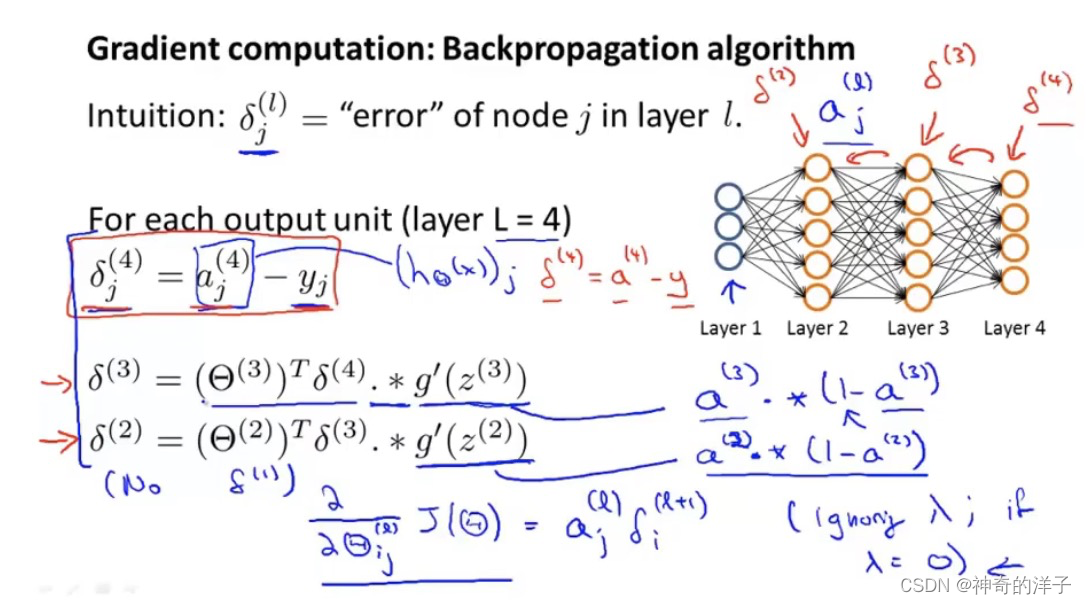
实现反向传播算法的步骤(结合西瓜书101-104页)
上标i是用于循环的,代表训练集中第i组数据,小delta的下标i不参与循环,代表某一层第i个激活项对应的误差。m是样本数
反向传播算法可以求出不同层之间的误差,然后可以用误差来计算代价函数的偏导数。
知道了D可以用来计算偏微分项
循环结束后,大deta 是m个训练样本的积累值
不用计算deta 1 ,因为不用考虑输入层的误差,但是要计算第一层参数的误差,所以大deta 11 表示第一层第一个参数的误差

9.3 理解反向传播算法
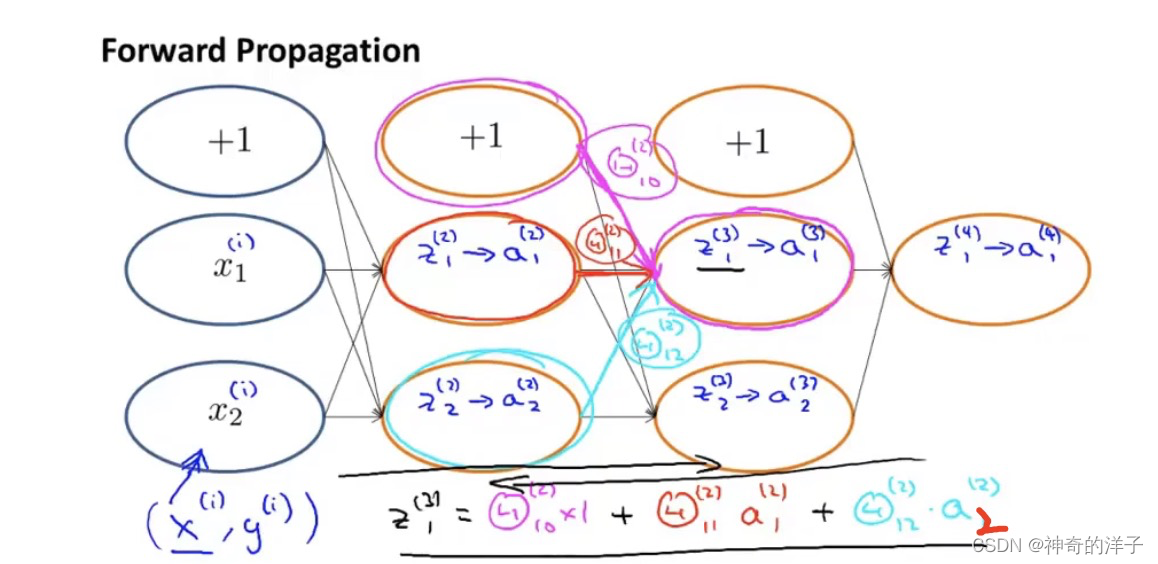
先理解前向传播算法的工作原理
这里输入层,中间两个隐藏层都是2个单元,没有把偏置单元算进去
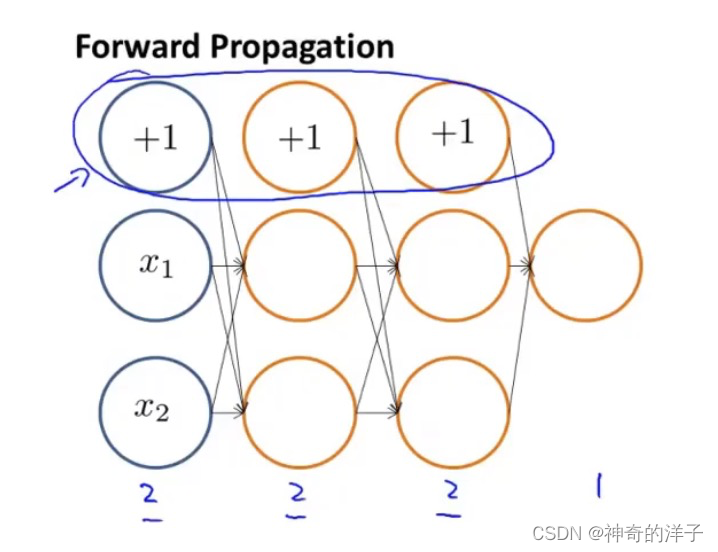
前向传播算法的实现原理
反向传播算法的实现
这里逻辑回归的代价函数,是一个对数函数,但我们可以把它认为是方差函数

这里的deta 是计算代价函数偏导数,也是计算deta 关于z项的加权和,可以看看9.2的那张图
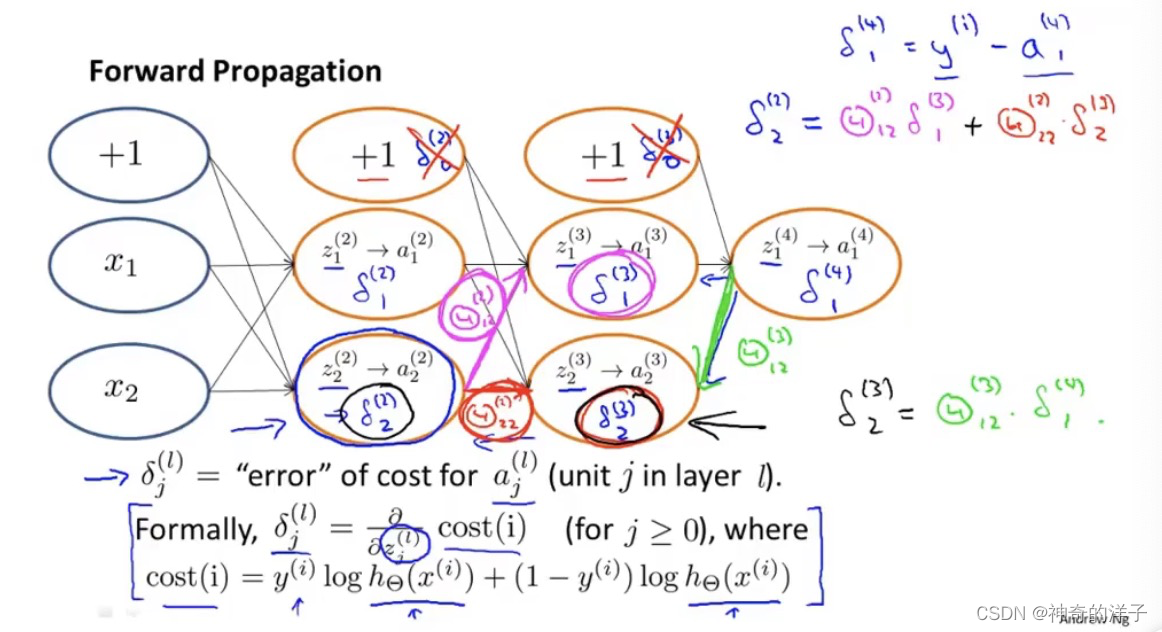
这里9.2 的那张图,上图是用z ,而下图是用theta ,本质上是一样的?
那z等于什么呢,可以看看这张图
9.4 使用技巧:展开参数
矩阵转向量,后面用python实现

9.5 梯度检测
用来计算 反向传播算法的偏导数D是否计算正确
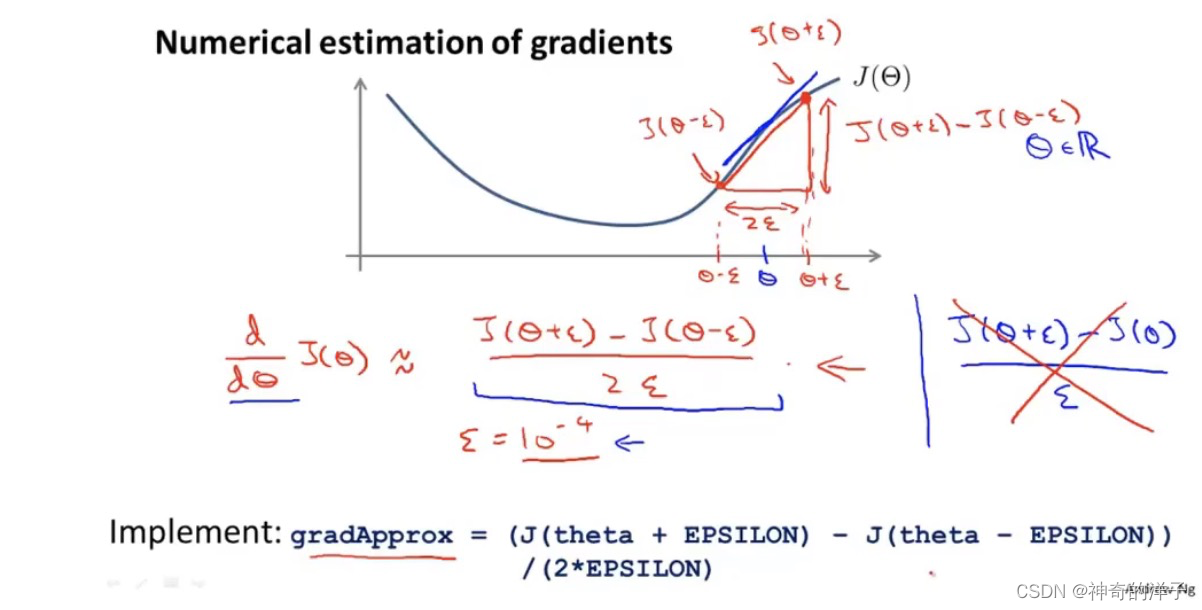
直接用解析式求导


9.6 随机初始化
任何优化算法都需要一些初始的参数。到目前为止我们都是初始所有参数为 0,这样的 初始方法对于逻辑回归来说是可行的,但是对于神经网络来说是不可行的。如果我们令所有 的初始参数都为 0,这将意味着我们第二层的所有激活单元都会有相同的值。同理,如果我 们初始所有的参数都为一个非 0 的数,结果也是一样的
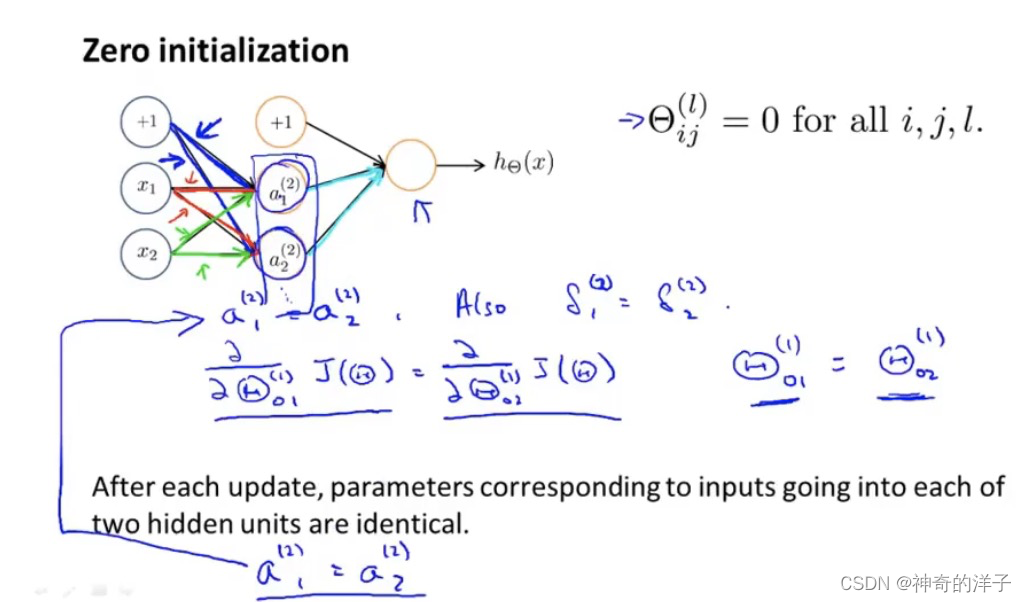

9.7 总结
小结一下使用神经网络时的步骤:
网络结构:第一件要做的事是选择网络结构,即决定选择多少层以及决定每层分别有多 少个单元。
第一层的单元数即我们训练集的特征数量。 最后一层的单元数是我们训练集的结果的类的数量。
如果隐藏层数大于 1,确保每个隐藏层的单元个数相同,通常情况下隐藏层单元的个数
越多越好。
我们真正要决定的是隐藏层的层数和每个中间层的单元数。
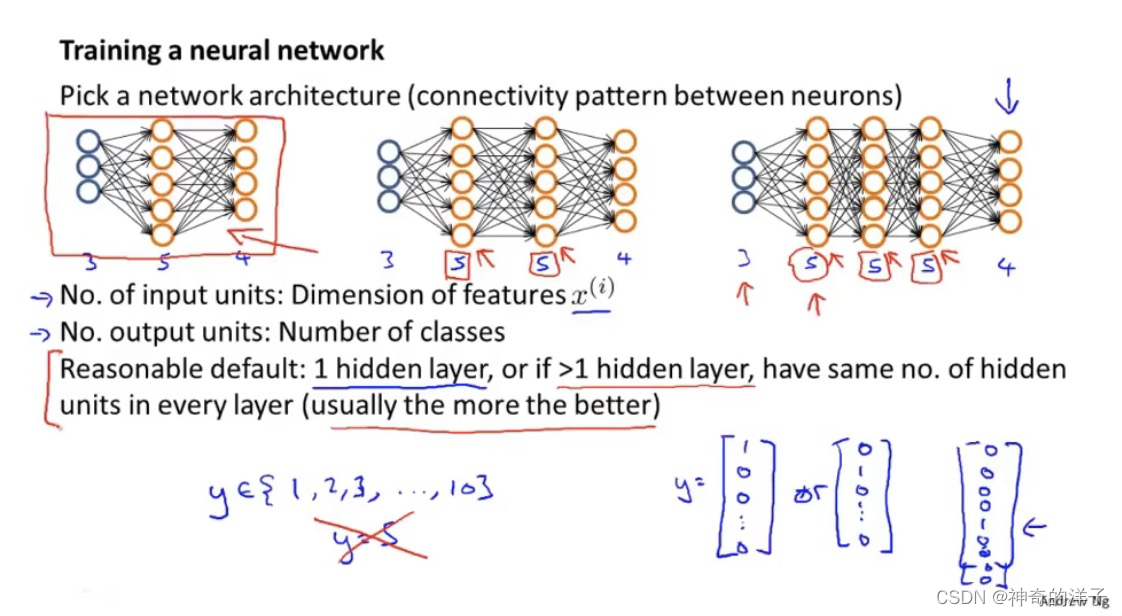
训练神经网络:
- 参数的随机初始化
- 利用正向传播方法计算所有的h𝜃 (𝑥)
- 编写计算代价函数 𝐽 的代码
- 利用反向传播方法计算所有偏导数
- 利用数值检验方法检验这些偏导数
- 使用优化算法来最小化代价函数


在利用反向传播算法求得代价函数的偏导数后,再利用梯度下降或者更高级的算法求得代价函数最小值
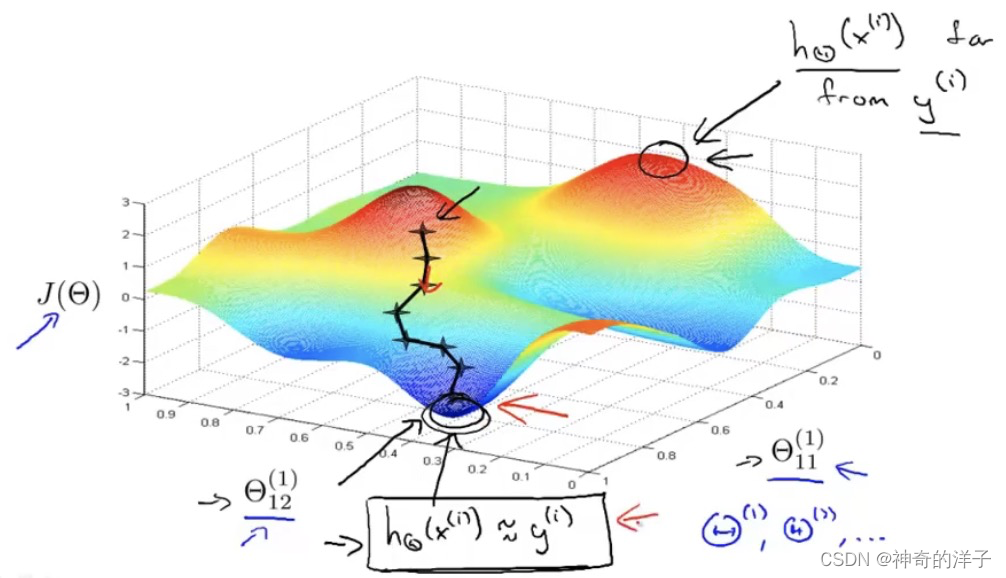
9.8 自动驾驶
基于反向传播算法的神经网络 ,应用于自动驾驶上
第10章
10.1 决定下一步做什么
训练误差大,下一步需要怎么做减少误差
1.尝试减少特征的数量
2.尝试获得更多的特征
3.尝试增加多项式特征
4.尝试减少正则化程度𝜆
5.尝试增加正则化程度𝜆

10.2 评估假设
线性回归训练和测试误差计算方式

逻辑回归训练和测试误差计算方式
这里误差率= 测试集判断错误的数量/测试集总数

10.3 模型选择和训练,验证,测试集
参数在训练集上误差很小,但是在真实数据上误差很大,这个就是过拟合

如果我们选出10个模型,用测试集选择代价函数最小的一个模型,多项次次数为d,再用测试集去验证这个模型,那这个多项式次数为d表现一定好的(举行比赛又当裁判的感觉)

建议的方式是分成训练集,验证集和测试集。在训练集上训练好模型得到参数,然后在交叉验证集上选择代价函数最小的一个模型(由验证集选出最合适的假设函数),最后用测试集进行泛化的评价
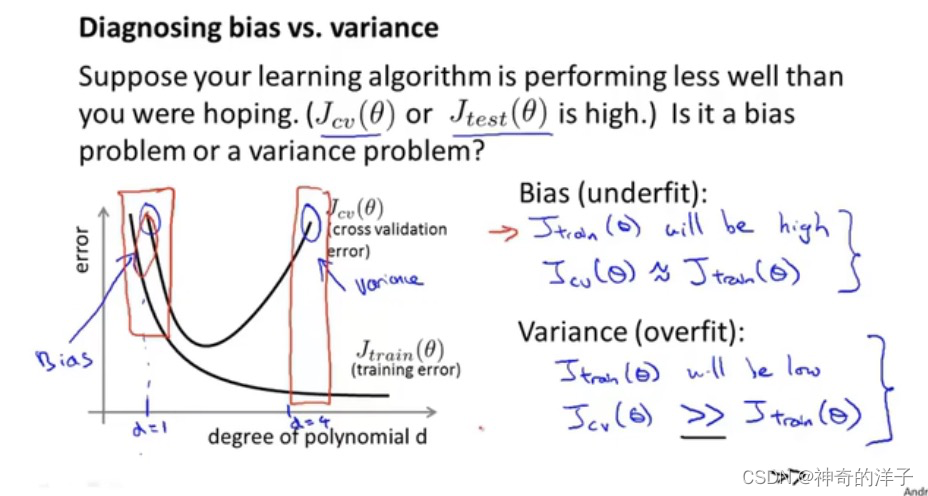
10.4 诊断偏差与方差
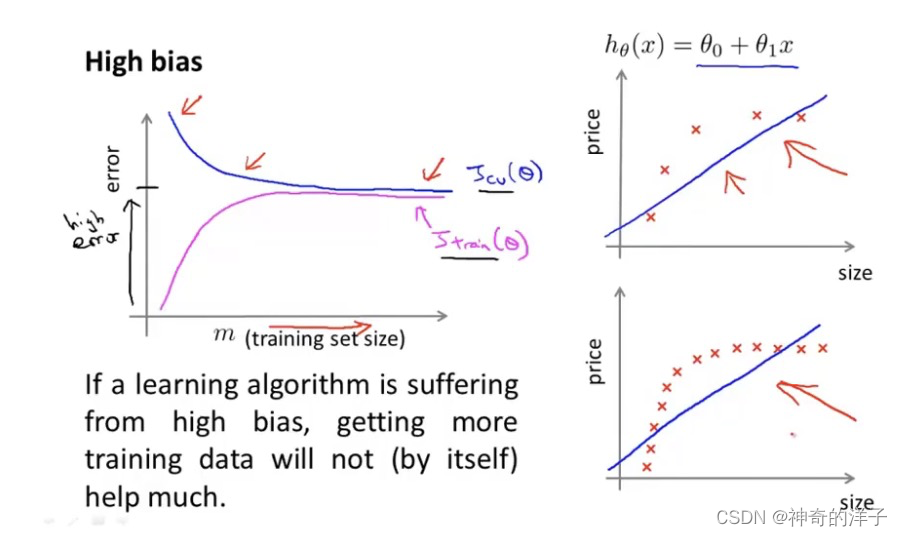
高偏差:训练误差大,交叉验证误差约等于训练误差,表示模型欠拟合
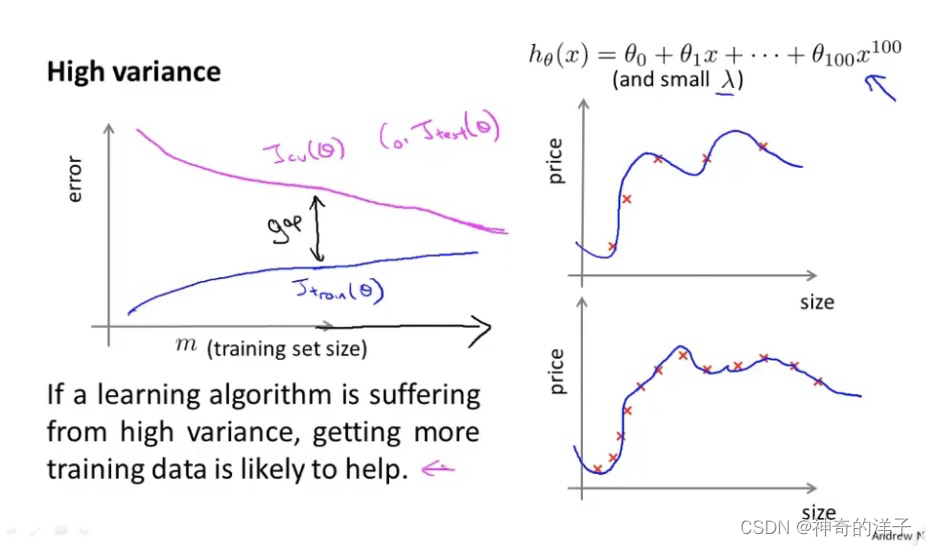
高方差:训练误差小,但交叉验证误差远远大于训练误差,表示模型过拟合
随着多项式次数d增加,训练误差逐步在减少,而交叉验证误差是先减少后增加
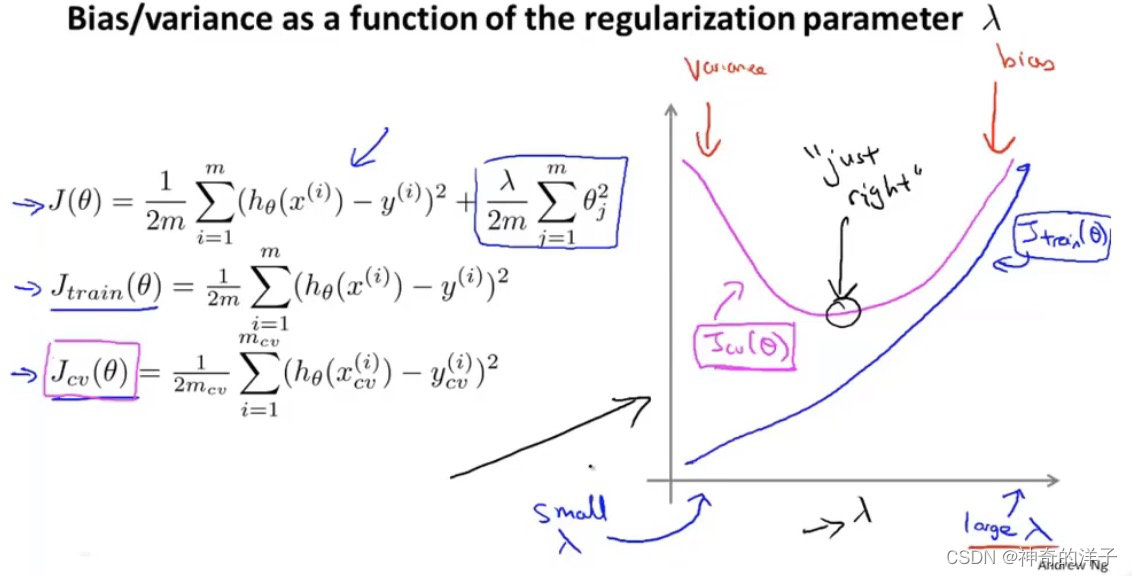
10.5 正则化和偏差、方差
在我们在训练模型的过程中,一般会使用一些正则化方法来防止过拟合。但是我们可能 会正则化的程度太高或太小了,即我们在选择 λ 的值时也需要思考与刚才选择多项式模型次 数类似的问题
正则化和验证集是两种选择模型的方法,我们应该先进行正则化lambda的,然后采用验证集。但是注意,计算训练误差都是不考虑正则项的
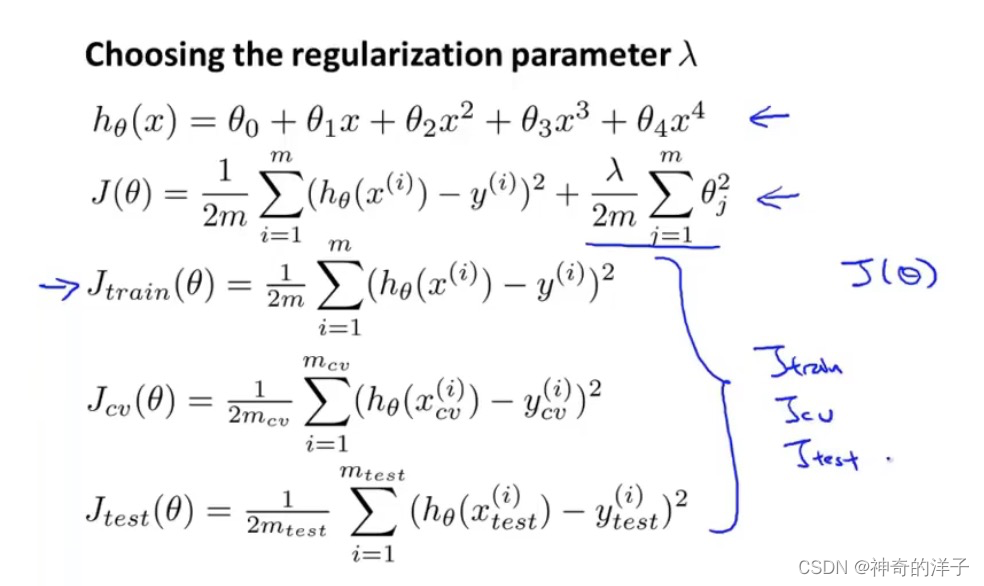
依次选择正则化lambda的参数,然后进行训练,依次选出最小代价函数最小的假设函数。然后到交叉验证集进行验证,选择交叉验证误差最小的多项式子次数,然后用该模型到测试集上去验证测试误差 
最后画一个图来表示正则项lambda,对于训练误差和交叉验证误差的影响。
当 𝜆 较小时,训练集误差较小(过拟合)而交叉验证集误差较大
随着 𝜆 的增加,训练集误差不断增加(欠拟合),而交叉验证集误差则是先减小后 增加
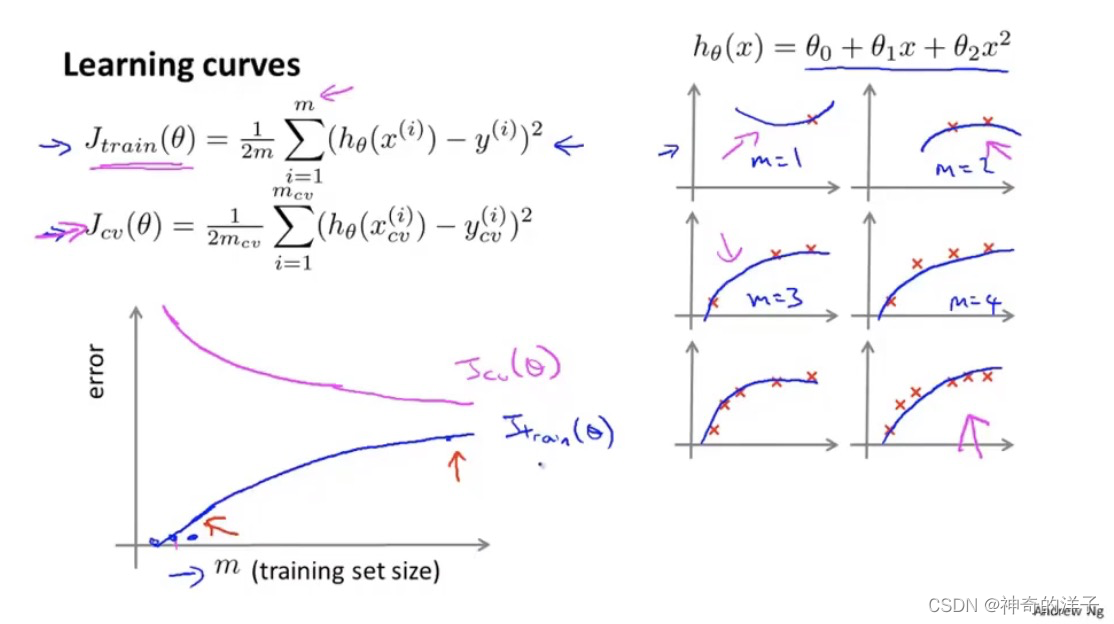
10.6 学习曲线
学习曲线的作用帮助我们来诊断某个学习算法是否处于偏差,方差的问题,或者两者都有
当样本m数量增大时,训练误差会增大,因为很难保证每个点都命中的训练集;而交叉验证误差会变小,因为训练样本多了,模型的泛化能力变好
高偏差(欠拟合)的学习曲线如下图
随着样本数增多,训练误差和交叉验证误差都不会改变,出于一个水平线的位置
而高方差(过拟合)的话,增加样本数量,训练误差增大,交叉验证误差会减小
10.7 决定接下来做什么
有了学习曲线,我们可以看出是高偏差还是高方差,然后用下面方法进行修复
- 获得更多的训练实例——解决高方差
- 尝试减少特征的数量——解决高方差
- 尝试获得更多的特征——解决高偏差
- 尝试增加多项式特征——解决高偏差
- 尝试减少正则化程度 λ——解决高偏差
- 尝试增加正则化程度 λ——解决高方差

使用较小的神经网络,类似于参数较少的情况,容易导致高偏差和欠拟合,但计算代 价较小使用较大的神经网络,类似于参数较多的情况,容易导致高方差和过拟合,虽然计算 代价比较大,但是可以通过正则化手段来调整而更加适应数据。
通常选择较大的神经网络并采用正则化处理会比采用较小的神经网络效果要好。
对于神经网络中的隐藏层的层数的选择,通常从一层开始逐渐增加层数,为了更好地 作选择,可以把数据分为训练集、交叉验证集和测试集,针对不同隐藏层层数的神经网络训练神经网络, 然后选择交叉验证集代价最小的神经网络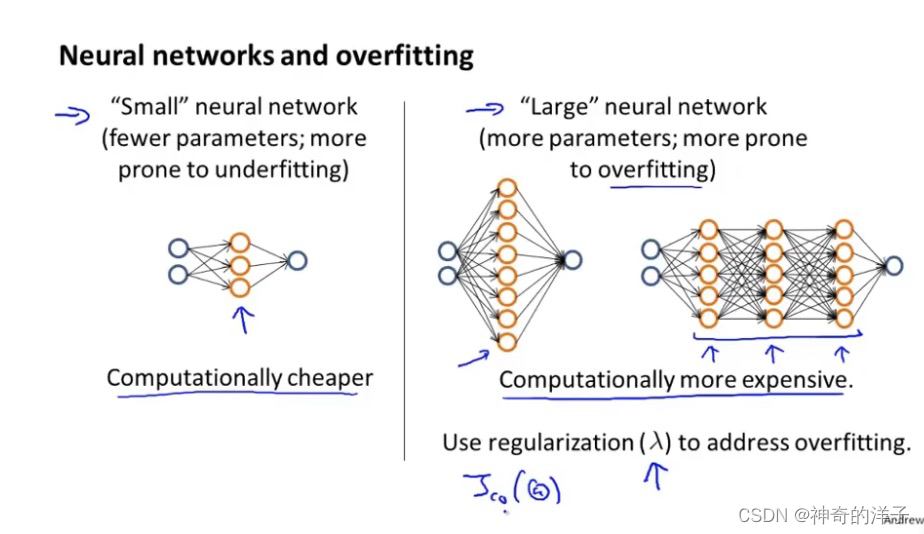
11.1 确定执行的优先级


为了构建这个分类器算法,我们可以做很多事,例如:
- 收集更多的数据,让我们有更多的垃圾邮件和非垃圾邮件的样本(蜜罐)
- 基于邮件的路由信息开发一系列复杂的特征
- 基于邮件的正文信息开发一系列复杂的特征,包括考虑截词的处理
- 为探测刻意的拼写错误(把 watch 写成 w4tch)开发复杂的算法
我们将在随后的课程中讲误差分析,我会告诉你怎样用一个更加系统性的方法,从一 堆不同的方法中,选取合适的那一个
11.2 误差分析
构建一个学习算法的推荐方法为:
- 从一个简单的能快速实现的算法开始,实现该算法并用交叉验证集数据测试这个算 法
- 绘制学习曲线,决定是增加更多数据,或者添加更多特征,还是其他选择
- 进行误差分析:人工检查交叉验证集中我们算法中产生预测误差的实例(
可以用单一的数值指标,即通过某个实数来评估你的学习算法,去算出误差率),看看这些实例是否有某种系统化的趋势

11.3 不对称性分类的误差评估
正例和负例的比率处于一个极端的情况,叫偏斜类问题

对于偏斜类问题,单一的数值指标,即通过某个实数来评估你的学习算法,就不管用了,因为从准确率99.3%,到准确率99.5% 。看似数值提高了,但是实际效果没有什么帮助。
有另外一种评估度量值,叫查准率和召回率(查全率,西瓜书)
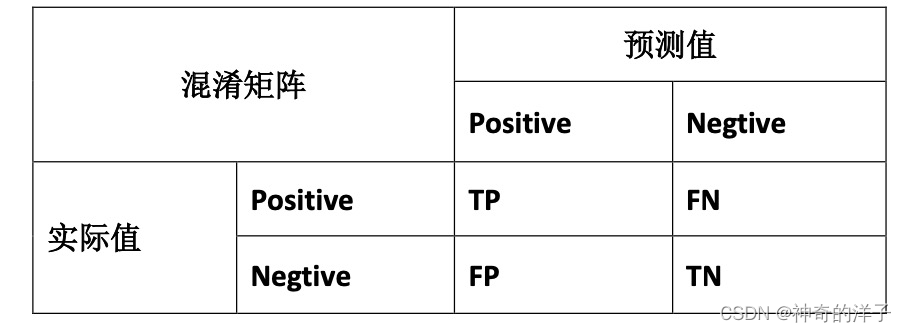
查准率(Precision)和查全率(Recall) 我们将算法预测的结果分成四种情况: 1. 正确肯定(TruePositive,TP):预测为真,实际为真
2. 正确否定(TrueNegative,TN):预测为假,实际为假
3. 错误肯定(FalsePositive,FP):预测为真,实际为假
4. 错误否定(FalseNegative,FN):预测为假,实际为真
则:查准率=TP/(TP+FP)。例,在所有我们预测有恶性肿瘤的病人中,实际上有恶性肿 瘤的病人的百分比,越高越好。
查全率(召回率)=TP/(TP+FN)。例,在所有实际上有恶性肿瘤的病人中,成功预测有恶性肿瘤的 病人的百分比,越高越好。
这样,对于我们刚才那个总是预测病人肿瘤为良性的算法,其查全率是 0
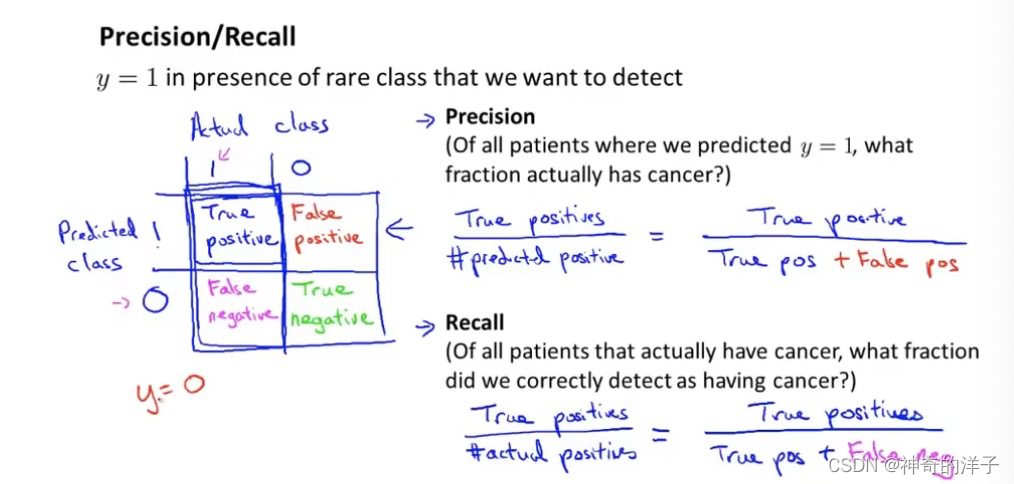
对于分类问题,查准率和召回率高,这个算法就表现得好
偏斜类问题 用查准率和召回率,比用分类误差或分类准确性好的多
11.4 查准率和召回率的权衡
在之前的课程中,我们谈到查准率和召回率,作为遇到偏斜类问题的评估度量值。在 很多应用中,我们希望能够保证查准率和召回率的相对平衡。
在这节课中,我将告诉你应该怎么做,同时也向你展示一些查准率和召回率作为算法 评估度量值的更有效的方式。继续沿用刚才预测肿瘤性质的例子。假使,我们的算法输出的 结果在 0-1 之间,我们使用阀值 0.5 来预测真和假。
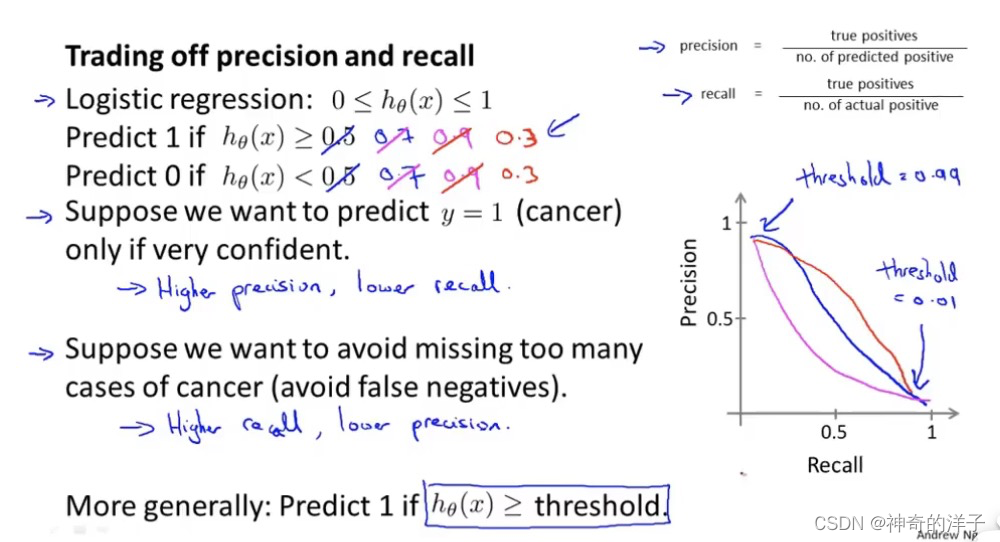
查准率(Precision)=TP/(TP+FP) 例,在所有我们预测有恶性肿瘤的病人中,实际上有恶 性肿瘤的病人的百分比,越高越好。
查全率(Recall)=TP/(TP+FN)例,在所有实际上有恶性肿瘤的病人中,成功预测有恶性肿 瘤的病人的百分比,越高越好。
如果我们希望只在非常确信的情况下预测为真(肿瘤为恶性),即我们希望更高的查准率,我们可以使用比 0.5 更大的阀值,如 0.7,0.9(即阙值为0.7,我们才认为他患有肿瘤)。这样做我们会减少错误预测病人为恶 性肿瘤的情况,同时却会增加未能成功预测肿瘤为恶性的情况。
如果我们希望提高查全率,尽可能地让所有有可能是恶性肿瘤的病人都得到进一步地 检查、诊断,我们可以使用比 0.5 更小的阀值,如 0.3。
我们可以将不同阀值情况下,查全率与查准率的关系绘制成图表,曲线的形状根据数 据的不同而不同:
评估查准率和召回率的方法,计算F值,可以用它衡量算法好坏的标准
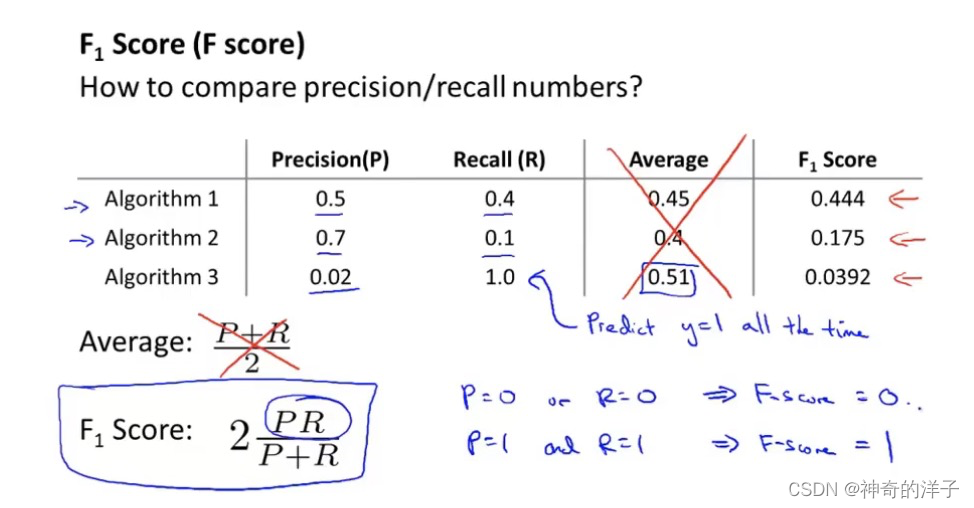
11.5 机器学习数据
对数据的要求是要包含足够多的特征,不然白搭。对算法的要求:要包含足够的参数
多参数保证偏差小,大量数据保证方差小,二合一完美
但是这里有个关键的假设,是特征值含有足够的信息量,有一类很好的假设函数,然后有大量的训练集

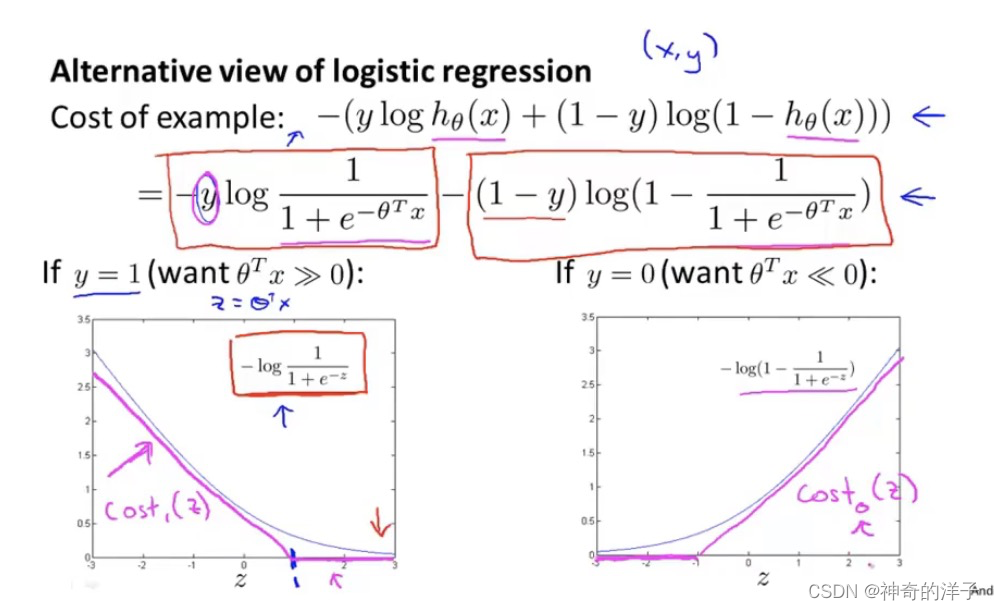
12.1 优化目标(支持向量机)
逻辑回归代价函数,跟支持向量机的函数图像对比,洋红色的图像是支持向量机的代价函数图像
下面这张图是分别为正样本(y=1),和负样本(y=0)的代价函数图,如果y=1,当z(即 theta * x)远大于0的时候,代价函数值为0;反之y=0,当z(即 theta * x)远小于0的时候,代价函数值为0
支持向量机与逻辑回归的代价函数相比,常数项用C表示,不再用1/m表示,而正则项参数不再用langbuda表示(我们通过控制langbuda来找到最小的A,或者是保持正则化参数足够小),而用C表示。在逻辑回归中,langbuda越大表示权重越高,而支持向量机当中,C越小表示参数的权重越大

12.2 直观上对于大间隔的理解
支持向量机有一个安全距离,theta转置乘以x大于等于1,才认为y=1

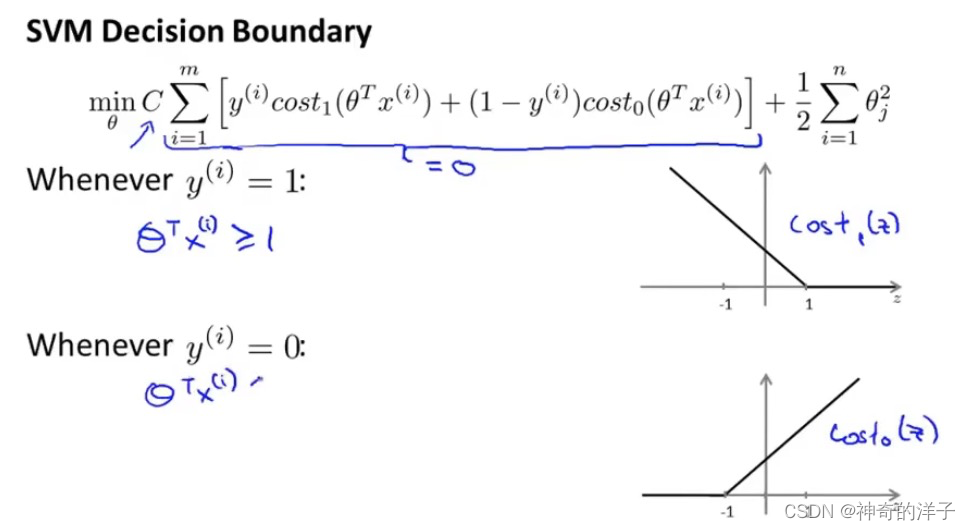

支持向量机里面的距离样本的距离
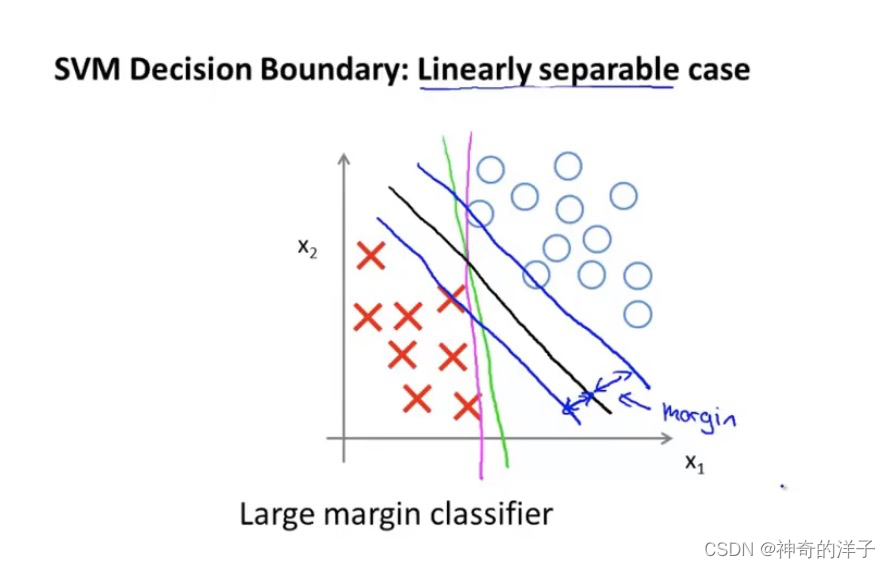
大间距分类器,如果C太大(可以理解成过拟合?),有异常点,就会把决策边界变成洋红色的线,C理解成1/langbuda,就是正则化参数,如果langbuda太大,langbuda就会很小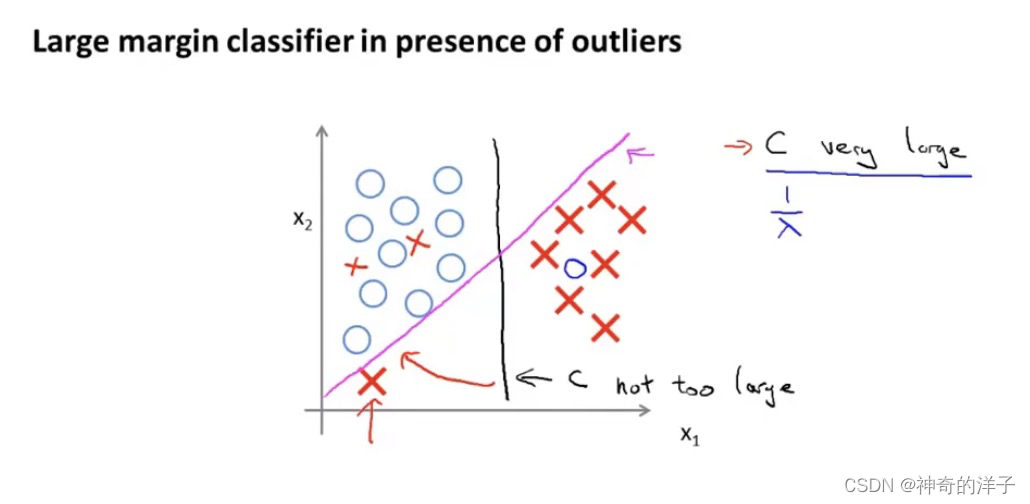
12.3 大间隔分类器的数学原理
选学,暂时没看,推荐李航老师的统计学习方法
12.4 核函数1
12.5 核函数2
12.6 使用SVM
12.3 -12.6 这部分没有听懂,需要查其他学习资料