redis RDB设计与实现
文章目录
- redis RDB设计与实现
- RDB功能
- RDB文件的创建和保存
- SAVE 和 BGSAVE
- RDB保存冲突
- RDB文件的载入
- 自动保存
- RDB 文件结构
RDB功能
为了使Redis储存在内存中的数据库状态保存到磁盘里面防止丢失,Redis提供了RDB持久化功能,将Redis内存中的数据库状态保存到磁盘里面,避免数据意外丢失。
RDB持久化既可以手动执行,也可以根据服务器配置选项定期执行,该功能可以将某个时间点上的数据库状态保存到一个RDB文件中。
RDB持久化功能所生成的RDB文件是一个经过压缩的二进制文件,通过该文件可以还原生成RDB文件时的数据库状态。
RDB文件的创建和保存
SAVE 和 BGSAVE
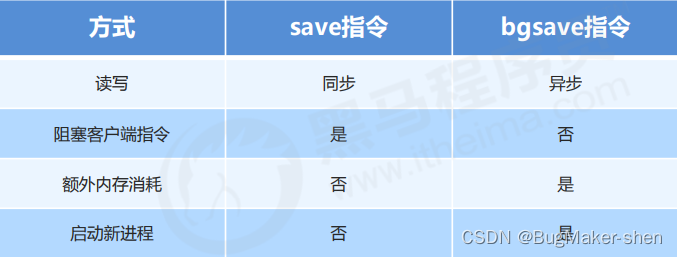
有两个Redis命令可以用于生成RDB文件,一个是SAVE, 另一个是BGSAVE。
- SAVE命令会阻塞Redis服务器进程,直到RDB文件创建完毕为止,在服务器进程阻塞期间,服务器不能处理任何命令请求。
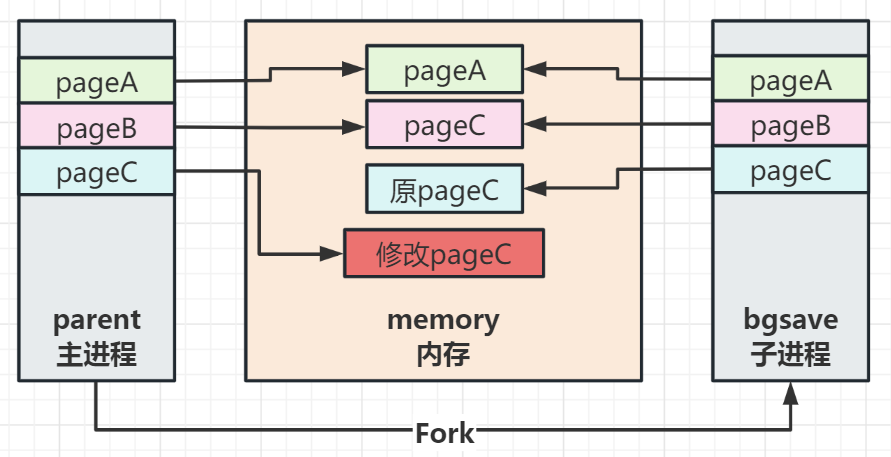
- BGSAVE 命令会派生出一个子进程,然后由子进程负责创建RDB文件,服务器进程(父进程)继续处理命令请求。
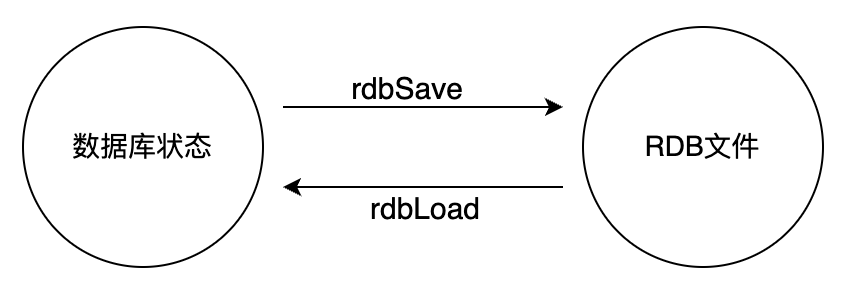
创建RDB文件的实际工作由rdb.c/rdbSave函数完成,SAVE 命令和BGSAVE命令会以不同的方式调用这个函数,通过以下伪代码可以明显地看出这两个命令之间的区别:
def SAVE():rdbSave()def BGSAVE():pid = fork()if pid == 0:# 子进程保存 RDBrdbSave()else if pid > 0:# 父进程继续处理请求,并等待子进程的完成信号handle_request()else:# pid == -1# 处理 fork 错误handle_fork_error()
RDB保存冲突
SAVE 命令执行时的服务器状态
前面提到过,当SAVE命令执行时,Redis 服务器会被阻塞,所以当SAVE命令正在执行时,客户端发送的所有命令请求都会被拒绝。
只有在服务器执行完SAVE命令、重新开始接受命令请求之后,客户端发送的命令才会被处理。
BGSAVE 命令执行时的服务器状态
因为BGSAVE命令的保存工作是由子进程执行的,所以在子进程创建RDB文件的过程中,Redis 服务器仍然可以继续处理客户端的命令请求,但是,在BGSAVE命令执行期间,服务器处理SAVE、BGSAVE、BGREWRITEAOF三个命令的方式会和平时有所不同。
- 在执行 SAVE 命令之前, 服务器会检查BGSAVE 是否正在执行当中, 如果是的话, 服务器就不调用 rdbSave ,而是向客户端返回一个出错信息, 告知在 BGSAVE 执行期间, 不能执行SAVE 。这样做可以避免 SAVE 和 BGSAVE调用的两个 rdbSave 交叉执行, 造成竞争条件。
- 当 BGSAVE 正在执行时, 调用新 BGSAVE 命令的客户端会收到一个出错信息, 告知 BGSAVE 已经在执行当中。
- BGREWRITEAOF 和 BGSAVE 不能同时执行:
- 如果 BGSAVE 正在执行,那么BGREWRITEAOF 的重写请求会被延迟到 BGSAVE 执行完毕之后进行,执行 BGREWRITEAOF 命令的客户端会收到请求被延迟的回复。
- 如果 BGREWRITEAOF 正在执行,那么调用 BGSAVE 的客户端将收到出错信息,表示这两个命令不能同时执行。
BGREWRITEAOF 和 BGSAVE 两个命令在操作方面并没有什么冲突的地方, 不能同时执行它们只是一个性能方面的考虑: 并发出两个子进程, 并且两个子进程都同时进行大量的磁盘写入操作, 这怎么想都不会是一个好主意。
RDB文件的载入
和使用SAVE命令或者BGSAVE命令创建RDB文件不同,RDB文件的载入工作是在服务器启动时自动执行的,所以Redis并没有专门用于载人RDB文件的命令,只要Redis服务器在启动时检测到RDB文件存在,它就会自动载入RDB文件。
载入时的服务器状态
服务器在载入RDB文件期间,会一直处于阻塞状态,直到载入工作完成为止。
自动保存
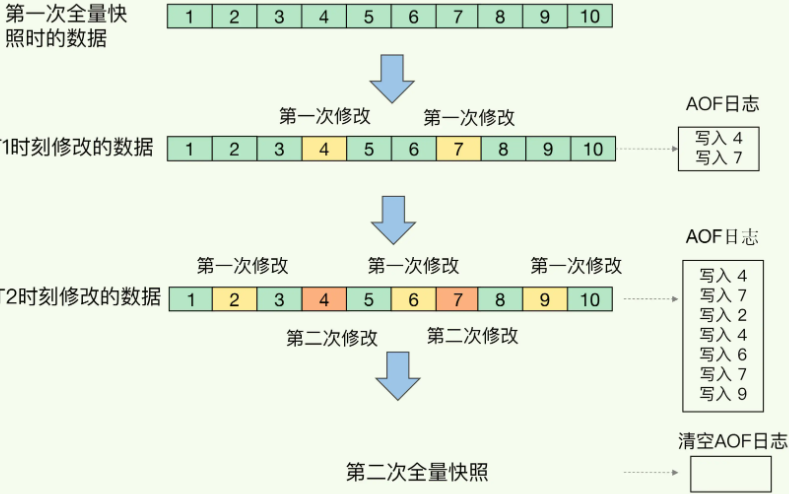
因为BGSAVE命令可以在不阻塞服务器进程的情况下执行,所以Redis允许用户通过设置服务器配置的save选项,让服务器每隔一段时间自动执行一次BGSAVE命令。
用户可以通过save选项设置多个保存条件,但只要其中任意一个条件被满足,服务器就会执行BGSAVE命令。
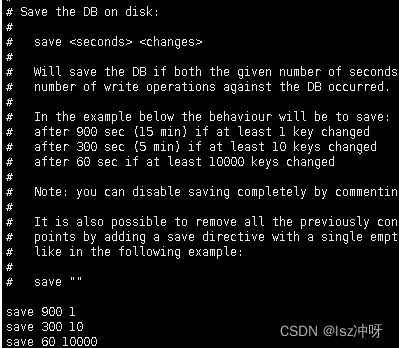
举个例子,如果我们向服务器提供以下配置:
save 900 1
save 300 10
save 60 10000
那么只要满足以下三个条件中的任意一个,BGSAVE命令就会被执行:
服务器在900秒之内,对数据库进行了至少1次修改。
服务器在300秒之内,对数据库进行了至少10次修改。
服务器在60秒之内,对数据库进行了至少10000次修改。
自动保存机制:
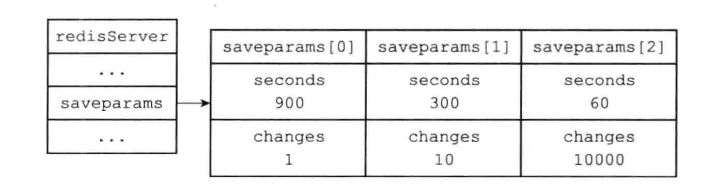
开启redis服务以后,服务器程序会根据save选项所设置的保存条件,设置服务器状态redisServer结构的saveparams属性:
struct redisServer {// ...// 记录了保存条件的数组struct saveparam *saveparams;// ...
};
saveparams属性是一个数组,数组中的每个元素都是一个saveparam结构,每个saveparam结构都保存了一个save选项设置的保存条件:
struct saveparam {// 秒速time_t seconds;// 修改数int changes;
};
比如说,如果save选项的值为以下条件:
save 900 1
save 300 10
save 60 10000
那么服务器状态中的saveparams数组将会是下图所示:
dirty计数器和lastsave属性
除了saveparams数组之外,服务器状态还维持着一个dirty计数器,以及一个lastsave属性:
- dirty计数器记录距离上一次成功执行SAVE命令或者BGSAVE命令之后,服务器对数据库状态(服务器中的所有数据库)进行了多少次修改(包括写入、删除、更新等操作)。
- lastsave属性是一个UNIX时间戳,记录了服务器上一次成功执行SAVE命令或者BGSAVE命令的时间。
struct redisServer {// ...// 修改计数器long long dirty;// 上一次保存的时间time_t lastsave;// ...
};
当服务器成功执行一个数据库修改命令之后,程序就会对dirty计数器进行更新。修改了多少次数据库,dirty计数器的值就增加多少。
检查保存条件是否满足
Redis的服务器周期性操作函数serverCron默认每隔100毫秒就会执行一次,该函数用于对正在运行的服务器进行维护,它的其中一项工作就是检查save选项所设置的保存条件是否已经满足,如果满足的话,就执行BGSAVE命令。
以下伪代码展示了serverCron 函数检查保存条件的过程:

程序会遍历并检查saveparams数组中的所有保存条件,只要有任意一个条件被满足,那么服务器就会执行BGSAVE命令。
RDB 文件结构
一个RDB文件可以分为以下几个部分:
+-------+-------------+-----------+-----------------+-----+-----------+
| REDIS | RDB-VERSION | SELECT-DB | DB-DATA | KEY-VALUE-PAIRS | EOF | CHECK-SUM |
+-------+-------------+-----------+-----------------+-----+-----------+|<-------- DB-DATA ---------->|
REDIS:
文件的最开头保存着 REDIS 五个字符,标识着一个 RDB 文件的开始。
在读入文件的时候,程序可以通过检查一个文件的前五个字节,来快速地判断该文件是否有可能是 RDB 文件。
RDB-VERSION
一个四字节长并且以字符表示的整数,记录了该文件所使用的 RDB 版本号。
目前的 RDB 文件版本为 0006 。
因为不同版本的 RDB 文件互不兼容,所以在读入程序时,需要根据版本来选择不同的读入方式。
DB-DATA
这个部分在一个 RDB 文件中会出现任意多次,每个 DB-DATA 部分保存着服务器上一个非空数据库的所有数据。
SELECT-DB
这部分保存着跟在后面的键值对所属的数据库号码。
在读入 RDB 文件时,程序会根据这个域的值来切换数据库,确保数据被还原到正确的数据库上。
KEY-VALUE-PAIRS
因为空的数据库不会被保存到 RDB 文件,所以这个部分至少会包含一个键值对的数据。
每个键值对的数据使用以下结构来保存:
+----------------------+---------------+-----+-------+
| OPTIONAL-EXPIRE-TIME | TYPE-OF-VALUE | KEY | VALUE |
+----------------------+---------------+-----+-------+
OPTIONAL-EXPIRE-TIME 域是可选的,如果键没有设置过期时间,那么这个域就不会出现; 反之,如果这个域出现的话,那么它记录着键的过期时间,在当前版本的 RDB 中,过期时间是一个以毫秒为单位的 UNIX 时间戳。
KEY 域保存着键,格式和REDIS_ENCODING_RAW 编码的字符串对象一样。
TYPE-OF-VALUE 域记录着 VALUE 域的值所使用的编码, 根据这个域的指示, 程序会使用不同的方式来保存和读取 VALUE 的值。
保存 VALUE 的详细格式如下:
REDIS_ENCODING_INT 编码的 REDIS_STRING 类型对象:
如果值可以表示为 8 位、 16 位或 32 位有符号整数,那么直接以整数类型的形式来保存它们:
+---------+
| integer |
+---------+
比如说,整数 8 可以用 8 位序列 00001000 保存。
当读入这类值时,程序按指定的长度读入字节数据,然后将数据转换回整数类型。
另一方面,如果值不能被表示为最高 32 位的有符号整数,那么说明这是一个 long long 类型的值,在 RDB 文件中,这种类型的值以字符序列的形式保存。
一个字符序列由两部分组成:
+-----+---------+
| LEN | CONTENT |
+-----+---------+
其中, CONTENT 域保存了字符内容,而 LEN 则保存了以字节为单位的字符长度。
当进行载入时,读入器先读入 LEN ,创建一个长度等于 LEN 的字符串对象,然后再从文件中读取 LEN 字节数据,并将这些数据设置为字符串对象的值。
REDIS_ENCODING_RAW 编码的 REDIS_STRING 类型值有三种保存方式:
-
如果值可以表示为 8 位、 16 位或 32 位长的有符号整数,那么用整数类型的形式来保存它们。
-
如果字符串长度大于 20 ,并且服务器开启了 LZF 压缩功能 ,那么对字符串进行压缩,并保存压缩之后的数据。
经过 LZF 压缩的字符串会被保存为以下结构:
+----------+----------------+--------------------+| LZF-FLAG | COMPRESSED-LEN | COMPRESSED-CONTENT |+----------+----------------+--------------------+LZF-FLAG 告知读入器,后面跟着的是被 LZF 算法压缩过的数据。
COMPRESSED-CONTENT 是被压缩后的数据, COMPRESSED-LEN 则是该数据的字节长度。
-
在其他情况下,程序直接以普通字节序列的方式来保存字符串。比如说,对于一个长度为 20 字节的字符串,需要使用 20 字节的空间来保存它。
这种字符串被保存为以下结构:
+-----+---------+| LEN | CONTENT |+-----+---------+LEN 为字符串的字节长度, CONTENT 为字符串。
当进行载入时,读入器先检测字符串保存的方式,再根据不同的保存方式,用不同的方法取出内容,并将内容保存到新建的字符串对象当中。
REDIS_ENCODING_LINKEDLIST 编码的 REDIS_LIST 类型值保存为以下结构:
+-----------+--------------+--------------+-----+--------------+
| NODE-SIZE | NODE-VALUE-1 | NODE-VALUE-2 | ... | NODE-VALUE-N |
+-----------+--------------+--------------+-----+--------------+
其中 NODE-SIZE 保存链表节点数量,后面跟着 NODE-SIZE 个节点值。节点值的保存方式和字符串的保存方式一样。
当进行载入时,读入器读取节点的数量,创建一个新的链表,然后一直执行以下步骤,直到指定节点数量满足为止:
- 读取字符串表示的节点值。
- 将包含节点值的新节点添加到链表中。
REDIS_ENCODING_HT 编码的 REDIS_SET 类型值保存为以下结构:
+----------+-----------+-----------+-----+-----------+
| SET-SIZE | ELEMENT-1 | ELEMENT-2 | ... | ELEMENT-N |
+----------+-----------+-----------+-----+-----------+
SET-SIZE 记录了集合元素的数量,后面跟着多个元素值。元素值的保存方式和字符串的保存方式一样。
载入时,读入器先读入集合元素的数量 SET-SIZE ,再连续读入 SET-SIZE 个字符串,并将这些字符串作为新元素添加至新创建的集合。
REDIS_ENCODING_SKIPLIST 编码的 REDIS_ZSET 类型值保存为以下结构:
+--------------+-------+---------+-------+---------+-----+-------+---------+
| ELEMENT-SIZE | MEB-1 | SCORE-1 | MEB-2 | SCORE-2 | ... | MEB-N | SCORE-N |
+--------------+-------+---------+-------+---------+-----+-------+---------+
其中 ELEMENT-SIZE 为有序集元素的数量, MEB-i 为第 i 个有序集元素的成员, SCORE-i 为第 i 个有序集元素的分值。
当进行载入时,读入器读取有序集元素数量,创建一个新的有序集,然后一直执行以下步骤,直到指定元素数量满足为止:
- 读入字符串形式保存的成员 member。
- 读入字符串形式保存的分值 score ,并将它转换为浮点数。
- 添加 member 为成员、 score 为分值的新元素到有序集。
REDIS_ENCODING_HT 编码的 REDIS_HASH 类型值保存为以下结构
+-----------+-------+---------+-------+---------+-----+-------+---------+
| HASH-SIZE | KEY-1 | VALUE-1 | KEY-2 | VALUE-2 | ... | KEY-N | VALUE-N |
+-----------+-------+---------+-------+---------+-----+-------+---------+
ASH-SIZE 是哈希表包含的键值对的数量, KEY-i 和 VALUE-i 分别是哈希表的键和值。
载入时,程序先创建一个新的哈希表,然后读入 HASH-SIZE ,再执行以下步骤 HASH-SIZE 次:
- 读入一个字符串。
- 再读入另一个字符串。
- 将第一个读入的字符串作为键,第二个读入的字符串作为值,插入到新建立的哈希中。
REDIS_LIST 类型、 REDIS_HASH 类型和 REDIS_ZSET 类型都使用了REDIS_ENCODING_ZIPLIST 编码, ziplist 在 RDB 中的保存方式如下:
+-----+---------+
| LEN | ZIPLIST |
+-----+---------+
载入时,读入器先读入 ziplist 的字节长,再根据该字节长读入数据,最后将数据还原成一个 ziplist 。
REDIS_ENCODING_INTSET 编码的 REDIS_SET 类型值保存为以下结构:
+-----+--------+
| LEN | INTSET |
+-----+--------+
载入时,读入器先读入 intset 的字节长度,再根据长度读入数据,最后将数据还原成 intset 。
参考资料:
《redis设计与实现》
https://blog.csdn.net/zhaokejin521/article/details/79616148