Python 中的 urllib.parse 模块提供了很多解析和组建 URL 的函数。
urlunparse() 通过长度为6的可迭代对象,组建URL
urlunsplit() 通过长度为5的可迭代对象,组建URL
urljoin() 将两个链接参数拼接为完整URL
urlencode() 将字典转换为请求参数
parse_qs() 将请求参数转换为字典
parse_qsl() 将请求参数转换为元组组成的列表
quote() url中文编码
unquote() url中文解码
解析url( urlparse() )
urlparse() 函数可以将 URL 解析成 ParseResult 对象,实现url的识别和分段。
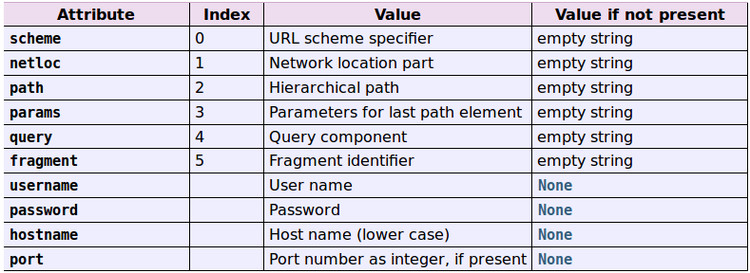
标准链接格式为:scheme://netloc/path;params?query#fragment
对象中包含了六个元素,分别为:
协议(scheme)
域名(netloc)
路径(path)
路径参数(params)
查询参数(query)
片段(fragment)
from urllib.parse import urlparseurl='https://blog.csdn.net/weixin_43848614/article/details/104607669'parsed_result=urlparse(url)print('parsed_result 的数据类型:', type(parsed_result))
print('parsed_result 包含了: ',len(parsed_result),'个元素')
print(parsed_result)print('scheme :', parsed_result.scheme)
print('netloc :', parsed_result.netloc)
print('path :', parsed_result.path)
print('params :', parsed_result.params)
print('query :', parsed_result.query)
print('fragment:', parsed_result.fragment)
print('hostname:', parsed_result.hostname)
结果为:
parsed_result 的数据类型: <class 'urllib.parse.ParseResult'>
parsed_result 包含了: 6 个元素
ParseResult(scheme='https', netloc='blog.csdn.net', path='/weixin_43848614/article/details/104607669', params='', query='', fragment='')
scheme : https
netloc : blog.csdn.net
path : /weixin_43848614/article/details/104607669
params :
query :
fragment:
hostname: blog.csdn.net
urllib.parse.ParseResult 对象的元素,可以通过索引获取
# urllib.parse.ParseResult 对象的元素,可以通过索引获取
from urllib.parse import urlparseurl='https://i.csdn.net/#/uc/profile'parsed_result=urlparse(url)print(parsed_result[0])for i in range(0,6):print('第',(i + 1),'个元素:',parsed_result[i])
结果为:
https
第 1 个元素: https
第 2 个元素: i.csdn.net
第 3 个元素: /
第 4 个元素:
第 5 个元素:
第 6 个元素: /uc/profile
参数
参数 作用
urlstring 必填,待解析的url
scheme 默认的协议,如http,https。链接没有协议信息时生效
allow_fragments 是否忽略fragment,如果设置False,fragment部分会被忽略,解析为path、params或者query的一部分,而fragment部分为空。当URL不包含params和query时候,fragment会被解析为path一部分
解析url( urlsplit() )
urlsplit() 函数也能对 URL 进行拆分,所不同的是, urlsplit() 并不会把 路径参数(params) 从 路径(path) 中分离出来,只返回五个参数值,params会合并到path中。
当 URL 中路径部分包含多个参数时,使用 urlparse() 解析是有问题的
这时可以使用 urlsplit() 来解析:
组建URL
组建URL urlunparse()
urlunparse()接收一个是一个长度为6的可迭代对象,将URL的多个部分组合为一个URL。若可迭代对象长度不等于6,则抛出异常。
from urllib.parse import urlunparse
url_compos = ['http','www.baidu.com','index.html','user= haoweixl','a=6','comment']
print(urlunparse(url_compos))
结果为:
http://www.baidu.com/index.html;user= haoweixl?a=6#comment
若可迭代对象长度不等于6,则抛出异常。
# 若可迭代对象长度不等于6,则抛出异常。from urllib.parse import urlunparse
url_compos = ['http','www.baidu.com','index.html','user= haoweixl','a=6','comment','China']
print(urlunparse(url_compos))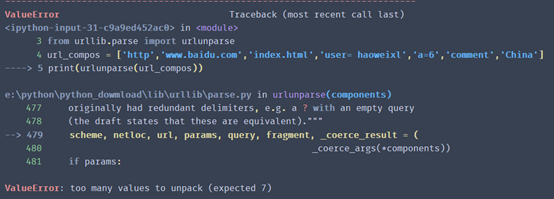
urlunsplit()
与 urlunparse()类似,传入对象必须是可迭代对象,且长度必须是5
from urllib.parse import urlunsplit
url_compos = ['http','www.baidu.com','index.html','user= haoweixl','a = 2']
print(urlunsplit(url_compos))urlunsplit()
结果为:
http://www.baidu.com/index.html?user= haoweixl#a = 2
urljoin()组接url,
注:连接两个参数的url, 将第二个参数中缺的部分用第一个参数的补齐,如果第二个有完整的路径,则以第二个为主。
# 连接两个参数的url, 将第二个参数中缺的部分用第一个参数的补齐,如果第二个有完整的路径,则以第二个为主
from urllib.parse import urljoinprint(urljoin('www.baidu.com', '?category=2#comment'))
print(urljoin('www.baidu.com', 'https://blog.csdn.net/nav/python'))
结果为:
www.baidu.com?category=2#comment
https://blog.csdn.net/nav/python
查询参数的构造与解析
使用 urlencode() 函数可以将一个 dict 转换成合法的查询参数:
dict1 = {'key1': 'one', 'key2': 3, 'key3': '中国', 'key4': '加油' } # 字典类型
import urllib.parse
print( urllib.parse.urlencode(dict1) )
结果为:
key1=one&key2=3&key3=%E4%B8%AD%E5%9B%BD&key4=%E5%8A%A0%E6%B2%B9
使用 parse_qs() 来将查询参数解析成 dict。
dict1 = {'key1': 'one', 'key2': 3, 'key3': '中国', 'key4': '加油' } # 字典类型
import urllib.parse
query_str = urllib.parse.urlencode(dict1)
print("将字典转换为字符串: ", query_str)
query_dic = urllib.parse.parse_qs(query_str)
print("将字符串还原为字典: ", query_dic)
结果为:
将字典转换为字符串: key1=one&key2=3&key3=%E4%B8%AD%E5%9B%BD&key4=%E5%8A%A0%E6%B2%B9
将字符串还原为字典: {'key1': ['one'], 'key2': ['3'], 'key3': ['中国'], 'key4': ['加油']}
parse_qsl() 将请求参数转换为元组组成的列表
# parse_qsl() 将请求参数转换为元组组成的列表
dict1 = {'key1': 'one', 'key2': 3, 'key3': '中国', 'key4': '加油' } # 字典类型
import urllib.parse
query_str = urllib.parse.urlencode(dict1)
print("将字典转换为字符串: ", query_str)
query_list = urllib.parse.parse_qsl(query_str)
print("将字符串还原为元组组成的列表: ", query_list)
结果为:
将字典转换为字符串: key1=one&key2=3&key3=%E4%B8%AD%E5%9B%BD&key4=%E5%8A%A0%E6%B2%B9
将字符串还原为元组组成的列表: [('key1', 'one'), ('key2', '3'), ('key3', '中国'), ('key4', '加油')]
quote() url中文编码
url中出现中文可能会乱码,所以中文路径需要转化,就用到了quote方法。
from urllib.parse import quote
keyword = "雪景"
url = 'https://www.baidu.com/s?wd=' + quote(keyword)
print(url)
结果为:
https://www.baidu.com/s?wd=%E9%9B%AA%E6%99%AF
unquote() url中文解码
有了quote方法转换,也需要有unquote方法对URL进行解码
from urllib.parse import unquote
url = 'https://www.baidu.com/s?wd=%E9%9B%AA%E6%99%AF'
fragment = '%E9%9B%AA%E6%99%AF'
print(unquote(url))
print(unquote(fragment))
结果为;
https://www.baidu.com/s?wd=雪景
雪景
参考博客链接:https://www.cnblogs.com/-wenli/p/10894562.html








![The server selected protocol version TLS10 is not accepted by client preferences [TLS12]](https://img-blog.csdnimg.cn/20210428163637794.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80NzE4MDgyNA==,size_16,color_FFFFFF,t_70)