Urlparse这个第三方模块中包含的函数有urljoin、urlsplit、urlunsplit、urlparse等。
1.urlparse.urlparse(urlstring[, scheme[, allow_fragments]])
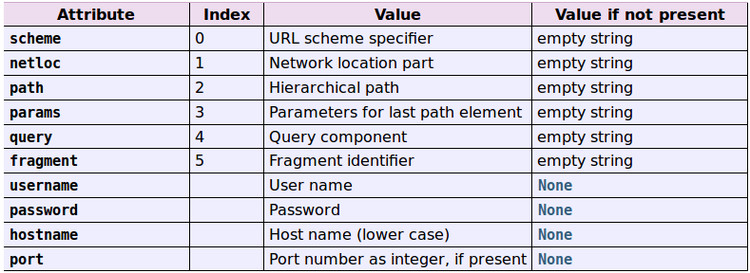
urlparse将urlstring解析成6个部分,它从urlstring中取得URL,并返回元组 (scheme, netloc, path, parameters, query, fragment),但是实际上是基于namedtuple,是tuple的子类。它支持通过名字属性或者索引访问的部分URL,每个组件是一串字符,也有可能是空的。组件不能被解析为更小的部分,%后面的也不会被解析,分割符号并不是解析结果的一部分,除非用斜线转义,注意,返回的这个元组非常有用,例如可以用来确定网络协议(HTTP、FTP等等 )、服务器地址、文件路径,等等。如下图所示

(1)引入urlparse模块,这里只引入了urlparse方法,如果你想要用所有的方法,你需要import urlparse
from urlparse import urlparse(2)我们将下面的url地址进行拆解,将拆解的结果存放到parsed中.
parsed=urlparse('http://user:pass@Netloc:80/path;parameters?query=argument#fragment')(3)之后,我们通过parsed的各个属性来访问不同的部分
from urlparse import urlparseparsed = urlparse('url地址')print 'scheme :'+ parsed.scheme #网络协议print 'netloc :'+ parsed.netloc #服务器位置(也可呢能有用户信息)print 'path :'+ parsed.path #网页文件在服务器中存放的位置print 'params :'+ parsed.params #可选参数print 'query :'+ parsed.query #连接符(&)连接键值对print 'fragment:'+ parsed.fragment #拆分文档中的特殊猫print 'username:'+ parsed.username #用户名print 'password:'+ parsed.password #密码print 'hostname:'+ parsed.hostname #服务器名称或者地址print 'port :', parsed.port #端口(默认是80)>>> import urlparse
>>> url=urlparse.urlparse('http://www.baidu.com/index.php?username=guol')
>>> print url
ParseResult(scheme='http', netloc='www.baidu.com', path='/index.php', params='', query='username=guol', fragment='')
>>> print url.netloc
www.baidu.com2.urlparse.urlunparse(parts)
urlunparse是urlparse的逆方法
从一个元组构建一个url,元组类似urlparse返回的,它接收元组(scheme, netloc, path, parameters, query, fragment)后,会重新组成一个具有正确格式的URL,以便供Python的其他HTML解析模块使用。
>>> import urlparse
>>> url=urlparse.urlparse('http://www.baidu.com/index.php?username=guol')
>>> print url
ParseResult(scheme='http', netloc='www.baidu.com', path='/index.php', params='', query='username=guol', fragment='')
>>> u=urlparse.urlunparse(url)
>>> print u
http://www.baidu.com/index.php?username=guol3.urlparse.urlsplit(urlstring[, scheme[, allow_fragments]])
主要是分析urlstring,返回一个包含5个字符串项目的元组:协议、位置、路径、查询、片段。allow_fragments为False时,该元组的组后一个项目总是空,不管urlstring有没有片段,省略项目的也是空。urlsplit()和urlparse()差不多。不过它不切分URL的参数。
4.urlparse.urlunsplit(parts)
>>> import urlparse
>>> url=urlparse.urlparse('http://www.baidu.com/index.php?username=guol')
>>> print url
ParseResult(scheme='http', netloc='www.baidu.com', path='/index.php', params='', query='username=guol', fragment='')
>>> url=urlparse.urlsplit('http://www.baidu.com/index.php?username=guol')
>>> print url
SplitResult(scheme='http', netloc='www.baidu.com', path='/index.php', query='username=guol', fragment='')urlunsplit使用urlsplit()返回的值组合成一个url
5.urlparse.urljoin(base, url[, allow_fragments])
urljoin主要是拼接URL,它以base作为其基地址,然后与url中的相对地址相结合组成一个绝对URL地址。函数urljoin在通过为URL基地址附加新的文件名的方式来处理同一位置处的若干文件的时候格外有用。需要注意的是,如果基地址并非以字符/结尾的话,那么URL基地址最右边部分就会被这个相对路径所替换。如果希望在该路径中保留末端目录,应确保URL基地址以字符/结尾。
>>> import urlparse
>>> urlparse.urljoin('http://www.oschina.com/tieba','index.php')
'http://www.oschina.com/index.php'
>>> urlparse.urljoin('http://www.oschina.com/tieba/','index.php')
'http://www.oschina.com/tieba/index.php'总结:
urlparse和urlsplit方法类似,urlunparse和urlunsplit类似,只不过是少了一个字符串。
import urlparseurl = urlparse.urlparse('http://www.baidu.com/index.php?username=guol')
print url
print urlparse.urlunparse(url)
url = urlparse.urlsplit('http://www.baidu.com/index.php?username=guol')
print url
print urlparse.urlunsplit(url)
print urlparse.urljoin('http://www.oschina.com/tieba','index.php')
print urlparse.urljoin('http://www.oschina.com/tieba/','index.php')
ParseResult(scheme='http', netloc='www.baidu.com', path='/index.php', params='', query='username=guol', fragment='')
http://www.baidu.com/index.php?username=guol
SplitResult(scheme='http', netloc='www.baidu.com', path='/index.php', query='username=guol', fragment='')
http://www.baidu.com/index.php?username=guol
http://www.oschina.com/index.php
http://www.oschina.com/tieba/index.php







![The server selected protocol version TLS10 is not accepted by client preferences [TLS12]](https://img-blog.csdnimg.cn/20210428163637794.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80NzE4MDgyNA==,size_16,color_FFFFFF,t_70)