MLIR 意思为:多级中间表示,是一种新的IR表示。MLIR 是 LLVM 项目的子项目。
MLIR 是一种新型的编译器框架,其设计中参考了已有的编译器优点,规避了一些缺陷。包括了中间表示的定义、转换以及优化等功能,极大地方便了新型编译器的开发和调试工作。同时,MLIR 也包含了很多现成的工具可直接使用(batteries included)。
MLIR 包揽了编译器设计中的通用部分,使得编译器的开发人员可以专注于核心的语义分析、中间表示的设计和变换,以此降低开发成本,提高开发效率和提高成品质量。
基本知识
深度学习模型的编译器推理引擎(依照实现方式分类):
解释型推理引擎
包含模型解析器和模型解释器,部分推理引擎可能会有模型优化器。
- 模型解析器:负责读取和解析模型文件,将模型转为适用于解释器的内存格式。
- 模型解释器:分析内存格式的模型,接受模型的输入数据,然后根据模型结构依次执行相应的模型内部算子,最后产生模型输出。
- 模型优化器:负责将原始模型变换为等价的、具有更快的推理速度的模型。
编译型推理引擎
包含模型解析器和模型编译器。
- 模型编译器:负责将模型编译为计算设备(CPU, GPU等)可直接处理的机器码。同时,在编译的过程中可能会应用各种优化方式来提高生成的机器码的效率。
- 因为机器码可以直接被计算设备处理而无需额外的解释器参与,消除了解释器调度的开销。
- 编译型推理引擎生成的机器码更加靠近底层,相比较解释型推理引擎,编译器有更多的优化机会来到更高的执行效率。
因为目前对于推理引擎的执行速度要求越来越高,所以编译型推理引擎也逐渐成为高速推理引擎的发展方向。常用的推理性引擎有 Apache TVM, oneDNN, PlaidML, TensorFlow XLA, TensorFlow Runtime 等。
为便于优化,推理引擎会把模型转为中间表示(IR),然后对 IR 进行优化和变换,最终生成目标模型(解释型推理引擎)或目标机器码(编译型推理引擎)。
由于目前新的编程语言层出不穷,因此出现了各种各样的 IR,如下图所示:其中的 AST(Abstract Syntax Tree)为抽象语法树。
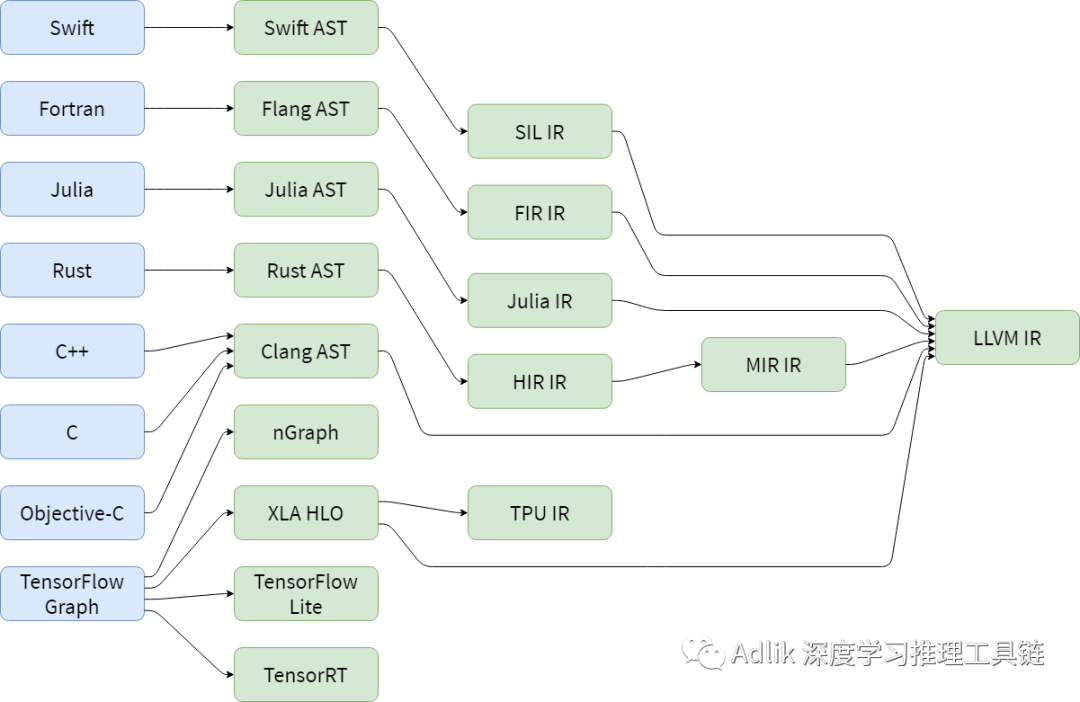
可以看到不同的推理引擎和编译器都有自己的一套IR和优化方案,同时每种优化方案可能都需要从头开始,最终可能导致软件的碎片化和重复的开发工作。
MLIR Introduction
MLIR 是一种新型的用于构建可复用、可扩展的编译器框架。MLIR 旨在解决上述说的软件碎片化、改善异构硬件的编译、降低构建特定领域编译器的成本、同时将现有的多种编译器链接到一起。
MLIR 最终想在统一的架构中支持多种不同需求的混合 IR。
MLIR 是一种支持硬件特定操作的通用 IR。因此,对围绕 MLIR 的基础架构进行的任何操作(例如编译器的 pass)都将产生良好的效果;许多目标都可以使用该基础架构。
MLIR 虽然是一种强大的框架,但是不支持底层的机器码生成算法(如,寄存器分配和指令调度),这些通常由底层优化器 LLVM 负责。
MLIR 的设计中也被整合了其他的经验教训。例如,LLVM 有一个不明显的设计缺陷,会阻止多线程编译器同时处理 LLVM 模块中的多个函数。MLIR 通过限制 SSA 作用域来减少使用-定义链,并用显式的符号引用代替跨函数引用来解决这些问题。
MLIR 是一个重要应用领域是Maching Learning,这里用下图的 tensorflow (使用数据流图作为数据结构)编译生态系统举例说明:
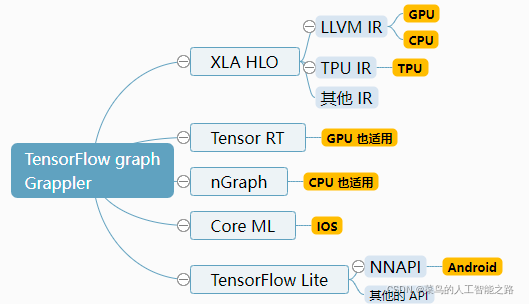
- 将 graph 转为 XLA 高级优化器(XLA HLO)表示,反之,这种表示亦可调用适合 CPU 或 GPU 的 LLVM 编译器,或者可以继续使用适合 TPU 的 XLA。
- 将 graph 转化为 TensorRT、nGraph 或另一种适合特定硬件指令集的编译器格式。
- 将 graph 转化为 TensorFlow Lite 格式,然后在 TensorFlow Lite 运行时内部执行此图,或者通过 Android 神经网络 API (NNAPI) 或相关技术将其进一步转化,以在 GPU 或 DSP 上运行。
整个编译流程先将 TensorFlow 的图转化为 XLA HLO,即一种类似高级语言的图的中间表达形式,可以基于此进行一些 High-Level 的优化。接着将 XLA HLO 翻译为 LLVM IR,使用 LLVM 编译成各种硬件的汇编语言,从而运行在硬件上进行数值计算。
除此之外,有时甚至会采用更复杂的途径,包括在每层中执行多轮优化。例如,Grappler 框架便能优化 TensorFlow 中的 tensor 布局和运算。
下图的绿色阴影部分是基于 SSA(Static Single-Assignment,单静态赋值)的IR,然而这种编译方式的缺点是:构建这种编译系统的开销比较大,每一层的设计实现会有重复部分,同一个层次的IR彼此之间虽然相似,但是存在天生的“隔离”,升级优化缺乏迁移性(优化一个模块,并不能惠及到同层次的其他模块)。因此,目前的问题在于各种IR之间转换的效率和可迁移性不高。
SSA(Static Single-Assignment,单静态赋值)是一种高效的数据流分析技术,目前几乎所有的现代编译器,如GCC、Open64、LLVM都有将SSA技术的支持。在SSA中间表示中,可以保证每个被使用的变量都有唯一的定义,即SSA能带来精确的使用–定义关系。

对上述问题,MLIR 希望为各种 DSL(Domain-Specific Language,领域特定语言)提供一种中间表达形式,将他们集成为一套生态系统,使用一种一致性强的方式编译到特定硬件平台的汇编语言上。利用这样的形式,MLIR就可以利用它模块化、可扩展的特点来解决IR之间相互配合的问题。

MLIR dialect
MLIR dialect 中的 dialect 在部分文献中被翻译为“方言”。
MLIR 通过“方言”来定义不同层次的中间表示,每一个“方言”都有自己唯一的名字空间。开发者可以创建自定义“方言”,并在“方言”内部定义操作、类型、属性以及它们的语义。
MLIR 推荐使用“方言”对 MLIR 进行扩展。有一个统一的中间表示框架降低了开发新编译器的成本。
除了可以使用 C++ 语言对“方言”进行定义之外,MLIR 也提供了一种声明式的方式来定义“方言”,即用户通过编写 TableGen 格式的文件来定义“方言”,然后使用 TableGen 工具生成对应的 C++ 头文件、源文件以及对应的文档。
MLIR 也提供了一个框架用于在“方言”之间或者方言内部进行转换。
MLIR 使用“操作”来描述不同层次的抽象和计算,操作是可扩展的,用户可以创建自定义的操作并规定其语义。MLIR 也支持用户通过声明式的方式(TableGen)来创建自定义操作。
MLIR 中的每个值都有对应的“类型”,MLIR 内置了一些原始类型(比如整数)和聚合类型(张量和内存缓冲区)。MLIR 的类型系统也允许用户对其进行扩展,创建自定义的类型以及规定其语义。
MLIR 中,用户可以通过指定操作的“属性”控制操作的行为。操作可以定义自身的属性,比如卷积操作的 stride 属性等。
MLIR dialect 转换
MLIR 中定义操作的时候可以定义其规范化的行为,以便后续的优化过程更为方便地进行。MLIR 以一种贪婪策略不断地应用规范化变换,直到 IR 收敛为止。比如将 x+2 和 2+x 统一规范化为 x+2。
MLIR 中进行方言内部或之间的转换时:
(1)用户首先要定义一个转换目标。转换目标规定了生成的目标中可以出现哪些操作。
(2)用户需要指定一组重写模式。重写模式定义了操作之间的转换关系。
(3)框架根据用户指定的转换目标和重写模式执行转换。
这个转换过程会自动检测转换方式,例如如果指定了 A → B 和 B → C 的重写模式,框架会自动完成 A → C 的转换过程。
MLIR 也支持用户通过声明式的方式(TableGen)来创建自定义的重写。
MLIR Users
ONNX MLIR:将 ONNX 格式的深度学习网络模型转换为能在不同二进制执行的二进制格式。
PlaidML:一个开源的 tensor 编译器,允许在不同的硬件平台上运行深度学习模型。
TensorFlow:TensorFlow 项目的 XLA 和 TensorFlow Lite 模型转换器用到了 MLIR。
TensorFlow Runtime (TFRT):全新的高性能底层进行时。旨在提供一个统一、可扩展的基础架构层,在各种领域特定硬件上实现一流性能。高效利用多线程主机的 CPU,支持完全异步的编程模型,同时专注于底层效率。
Verona:一种新的研究型的编程语言,用于探索并发所有权。其提供了一个可以与所有权无缝集成新的并发模型。
参考文献
MLIR 主页:https://mlir.llvm.org/
MLIR 语言:https://mlir.llvm.org/docs/LangRef/
深度学习编译:MLIR初步_Adenialzz的博客-CSDN博客