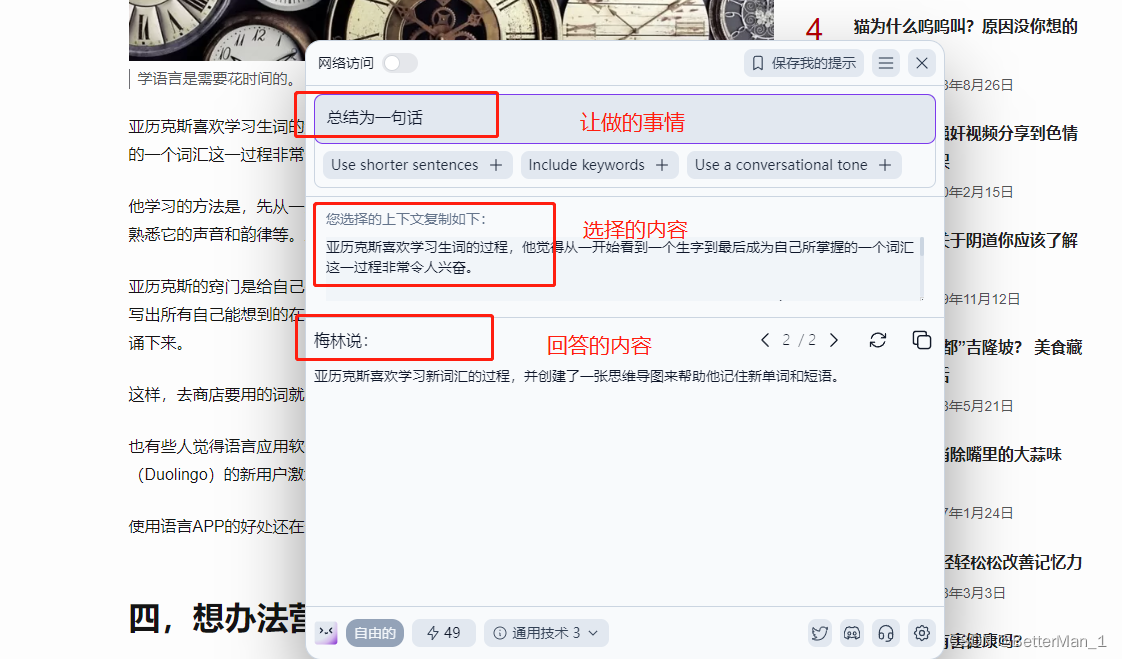
当前各大电商互联网平台上拥有海量的商品数据,为商品撰写一个精准且具有吸引力的标题文案,对于业务场景的转化以及用户使用体验的提升都有极大帮助。然而由于商品库规模庞大,人工运营编写商品文案的成本太高,并且对于智能推荐、营销等需要及时动态展示的场景,全部采用人工来编写多样化、个性化的文案基本是不现实的。因此,基于机器智能的文案生成技术,对于成本控制,以及大规模动态文案生成场景,不失为一种高效的解决方案。
机器智能文案生成技术虽然被业界广泛研究并在特定场景得到深入的应用,但依然是充满挑战的一项任务。尤其对于电商标题文案生成来说,智能生成的文案不能太过自由、超纲发挥,至少需要满足 2 点条件:文案准确地陈述商品的真实属性、文案包含了商品重要信息、文案能够突出显示商品的特色亮点;除此之外我们还希望文案具有阅读流畅、文采、吸引用户等加分项。总之,对于电商标题文案生成任务,首先需要依赖一套可控的文案生成技术、保证文案的准确全面,其次需要依赖外部知识、使得生成文案更具吸引力和多样性。随着近年来超大规模语言模型(LLM)不断取得了新的进展、突破,为我们解决电商标题文案生成任务提供了诸多的启发,借助 LLM 预训练模型内部的世界知识、再结合前沿的 ChatGPT 模型训练手段,极大的提升了文案生成效果。
在超大规模语言模型(LLM)阵营中 OpenAI 发布的 GPT 系列模型有着举足轻重的地位,模型参数规模从 GPT-1 的亿级别提升到 GPT-3 的千亿级、训练数据也相应地从 GB 级别提升到了 TB 级别,并且发布于 2020 年的 GPT-3 展现出来的零/少样本学习能力,能够广泛的适用于各种自然语言理解和生成任务,在当时让整个社区大为震撼。临近 2022 年末,OpenAI 发布了对话场景下的 ChatGPT,再次震撼社区、大量用户涌入试用、在社交媒体上传阅讨论相关话题,仅一周时间注册用户就突破百万,可见 ChatGPT 带来的影响力之大。在感慨 LLM 突飞猛进的同时,作为技术同学,我们一直在思考 ChatGPT 这种前沿的技术进步能够为我们真实的业务场景带来什么启示。随着对 ChatGPT、InstructGPT 以及基于人类反馈的强化学习(RLHF)等技术的了解,我们发现 ChatGPT 的对话场景和电商标题文案场景具有诸多相似之处,ChatGPT 的重要动机在于让模型生成内容不是随意发挥、而是对齐人类偏好,而前面提到电商标题文案也有这类诉求,因此我们探索将 ChatGPT 部分模型训练优化思路借鉴过来解决可控文案生成问题。
接下来本文将会详细介绍如何借鉴 ChatGPT 模型训练优化思路的方法、展示效果上带来的提升以及对未来的一些规划展望。另外虽然本文将会以酒店民宿场景下的标题文案生成为例,但其实方法具有场景普适性,适合大多数具有可控诉求的商品标题文案生成问题。
方法
问题定义
本文将以酒店民宿场景下的标题文案生成为例,来介绍如何借鉴 ChatGPT 模型训练优化的思路。该问题具体来说,就是给定房源的结构化和非结构化信息(其中结构化包括房型/风格/配套设施等,非结构化信息包括房东描述/周边介绍等),生成描述房源对应的标题,要求标题能够客观且全面的展现房源真实信息并能够突出房源特色亮点。
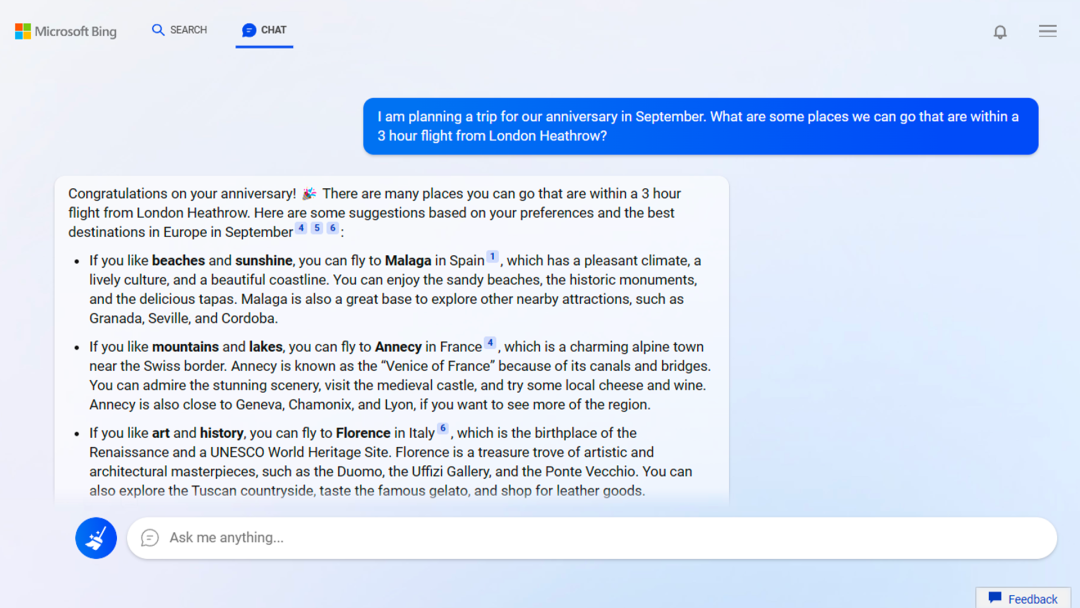
整套房源标题文案生成的核心流程如下所示:
其中从结构化成分属性到标题生成的过程就是本文要解决的文案生成问题,问题输入&输出定义如下:

相关方法
由于为房源生成的标题文案,既不能产生无中生有的信息、也不能缺失重要成分,而且还希望能够引入外部知识来丰富标题。因而相关的解决方案应该是受限的、可控的,生成的标题是满足特定约束条件的,目前较为成熟的方法分两类:
(1)基于规则模版的生成,由人工结合专业领域知识来编排出小规模的模版库,然后将结构化信息送入模版解析器中,完成模版的挑选以及信息点位的填充。
(2)基于深度模型的生成,利用预训练 LLM 模型学习到的大量知识,在结构化输入到标题输出的数据集上进行微调训练,同时为了确保输出标题可控,会引入辅助训练任务以及特定的解码策略。
在我们实践过程中发现以上两类方法各有优缺点,规则模版的问题在于依赖专业知识、泛化能力不足、生成的标题较为刻板,而深度模型微调的问题主要在于训练数据的构建成本以及难以保证标题的可控性。不过考虑到泛化性、解耦专业知识的优势,我们的房源标题生成方案选用了深度生成模型,下文会详细介绍我们是如何克服该方案的困难和不足。
本文方法
在项目第一期优化时,我们采用的方案是直接对中文预训练 GPT-2 模型进行微调训练,通过 case 分析发现该方法相对于规则模版,生成的标题信息更为丰富、多样,同时也发现一些问题,比如一些高频设施会出现在标题中、特色非标的设施不能够得到展示等。与此同时 2022 年底 ChatGPT 发布了,随着社交媒体上的爆火,我们也在学习思考 ChatGPT 的一些技术细节,发现其跟文案生成有着类似的动机:让预训练模型生成的内容能够对齐人类偏好。因此在项目二期优化阶段,我们尝试以较低成本来借鉴 ChatGPT 的模型训练思路,最终将其集成到了房源标题文案生成项目,当然这里介绍的方法也可适用于其它需要可控性的文案生成业务场景中。接下来会介绍完整的房源标题文案生成方法。
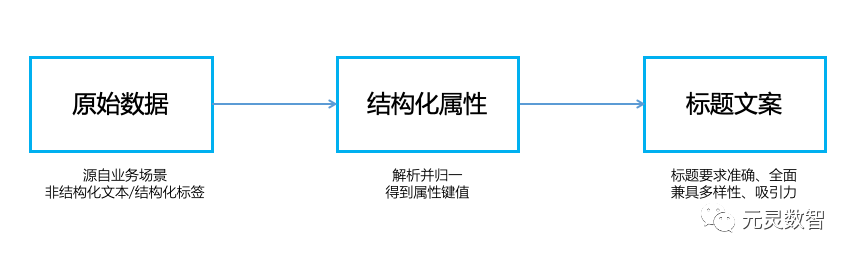
与 ChatGPT 训练流程类似,存在 3 个阶段:
1. 构建高质量精选训练集,格式为:<结构化属性, 优质标题>,以 LM 为训练目标对 GPT-2 进行微调训练,得到若干 GPT-2-finetuned 模型;
2. 全局随机采样房源结构化属性,得到生成的候选标题,人工对标题标注质量顺序,并利用该数据训练一个质量判别模型;
3. 利用 GPT-2-finetuned 模型大规模生成标题,然后利用上步得到的质量判别模型进行过滤,得到规模更大的训练集,并对 GPT-2-finetuned 进行二次微调训练,得到最终的生成模型。
下文会详细展开介绍这三个阶段。
首先,高质量精选数据的构建以及第一次微调。互联网上有较多业务数据跟我们的业务场景相似,保守估计头部几家平台大概有百万级数据可用,我们抓取这部分数据并做了脱敏处理。不过由于质量参差不齐,数据不能够直接用来进行训练,为此我们结合平台的线上销量/用户评分/点赞/信息丰富度等特征,设计了一些高准确率的过滤策略,得到大约万级别的精选训练数据。此外在模型微调训练时,我们尝试了较多种结构化属性到 prompt 文本的方法,并且注意到类目识别辅助任务的添加对效果提升有一定帮助。同时通过对不同 prompt、超参的调整得到多个 GPT-2-finetuned 版本模型,为后续优化做准备。
其次,质量判别模型的训练。从全量抓取的房源数据随机采样,然后利用 GPT-2-finetuned 模型以及解码策略的调整,来得到一个房源的多个生成标题,这份数据作为标注的候选。人工对标注候选集中多个标题进行排序调整,排序的先后表示质量的好坏,这个我们在人工标注时有一套较为详细的标准,比如特色设施有无显示、房型风格有无修饰成分、特色景观有无短语概述等。标注完成之后,得到数据格式假设为:(X, [t1, t2, t3]),其中 X 表示房源结构化属性,[t1,t2,t3] 表示按质量好坏排序的生成标题,然后利用 pair-wise 损失函数为目标来训练一个质量判别模型:
其中 M 是 GPT-2-finetuned 模型,输入 X 和 t,输出 0.0~1.0 之间的质量判别分数,分数越高质量越好。由于对生成标题再排序的标注成本较低,并且能够较好的代表人工对标题的偏好,因而训练得到质量判别模型一定程度上也能够代表人对标题的偏好。
最后,基于大规模训练数据的二次微调。设置一些松散的质量筛选条件后,可得到大规模房源数据,用第一阶段的 GPT-2-finetuned 模型生成候选标题,再经过质量判别模型将其中得分较低的数据过滤掉,最终得到第二次微调训练数据,可在 GPT-2-finetuned 基础上仿照上述方法进行二次微调训练,如此,经过 2 轮的迭代,完成语言模型的训练。
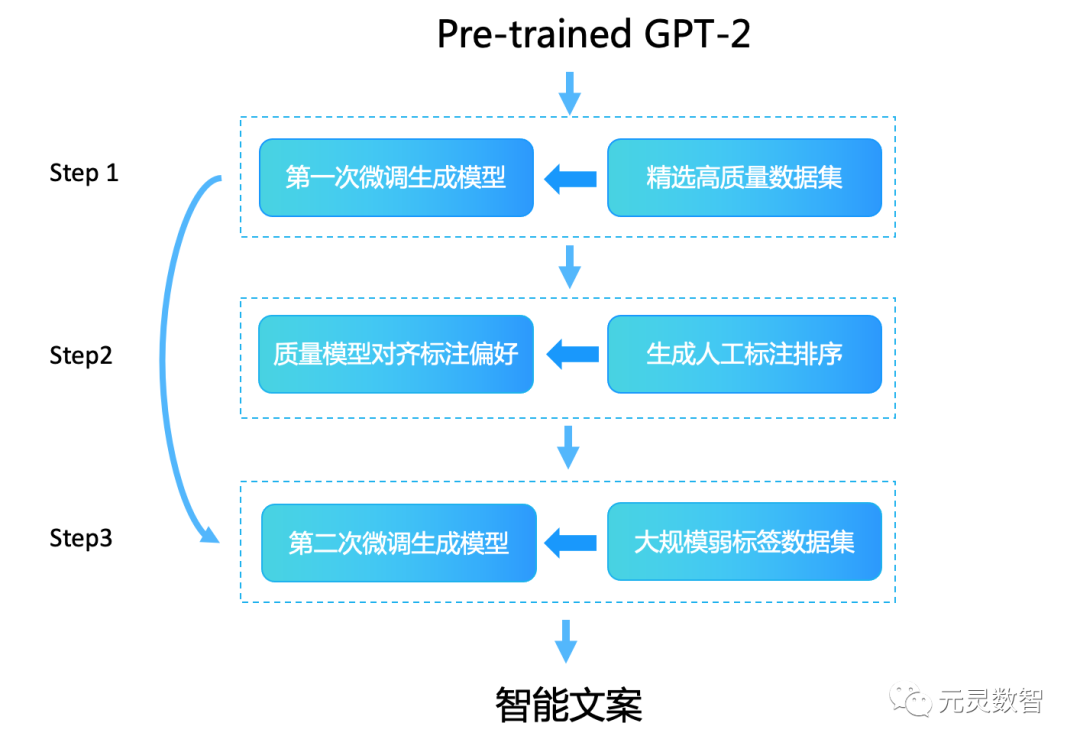
整体上来看,第一阶段是我们的原始方案,第二和第三阶段的思路借鉴自 ChatGPT 模型的部分思路,跟 ChatGPT 异同之处主要有以下几方面:
效果
通过借鉴 ChatGPT 训练思路,我们引入了第二和第三阶段的训练优化,经过人工评估文案生成结果,发现带来较大效果提升。这里我们选取一些较为典型的 case 进行分析,来对比原始方法中仅第一阶段微调模型的差异。
#CASE1

改进方法能够将更体现房源特色的“代买景区门票”服务以及“投影仪”设施等卖点展示在标题中,这一点在我们迭代原始方法时就注意到了,原始模型更倾向于生成那些高频出现的属性,但不一定是房源最具特色的属性,在第二阶段质量标注细则中我们也特意强化了这一点,因此改进方法能够表现更优。
#CASE2

改进方法的一个优势在于能够更细粒度的对属性进行表述,比如“海景”景观属性,原始方法仅罗列了出来,而改进方法能够为特色景观搭配一句诗词。还有“落地窗”以及“投影仪”这样的卖点设施,改进方法都能够添加更多的修饰成分在里面,这一点同样是第二三阶段对齐人类偏好的结果。
#CASE3

改进方法除了在内容上突出强调、增强修饰成分外,我们观察到还对标题中属性的顺序进行了调整, 比如上面例子中,将“北欧风格”、“落地窗”、“团建”这些更具特色卖点的属性调整到了标题前面,这一点同样也对齐了我们的质量标注细则要求。
结束语
近年来随着以 Transformer 为骨架的超大规模语言模型不断取得技术突破,AIGC 赛道愈发火热,从 2022 年中的 Stable Diffusion 多模态图像生成模型到 2022 年末的 ChatGPT 多轮对话语言模型,其生成的内容让人有些真假难辨,而且有的人已经从中嗅到商业化的可能,就连国外权威的图库网站、问答网站都甚至发出对此类生成内容的禁封,由此可见以大规模语言模型为基石的智能生成能力的进展有多迅猛。AI 技术日新月异,作为技术同学,一方面我们持续关注着前沿 AIGC 技术的进展,另一方面我们也立足当下进行思考,借鉴 ChatGPT 部分模型优化思路到具体的商品标题文案生成业务场景中,提升标题文案的准确可控、多样性以及吸引力,其中不足之处在于,没能够引入强化学习机制对模型进行调优,未来我们会持续不断进行迭代优化,并在合适的时候向社区开源我们的代码和模型。
可搜索公众号元灵数智,在底部菜单了解我们 - 用户交流获取官方技术交流群二维码,进群与业内大佬进行技术交流。