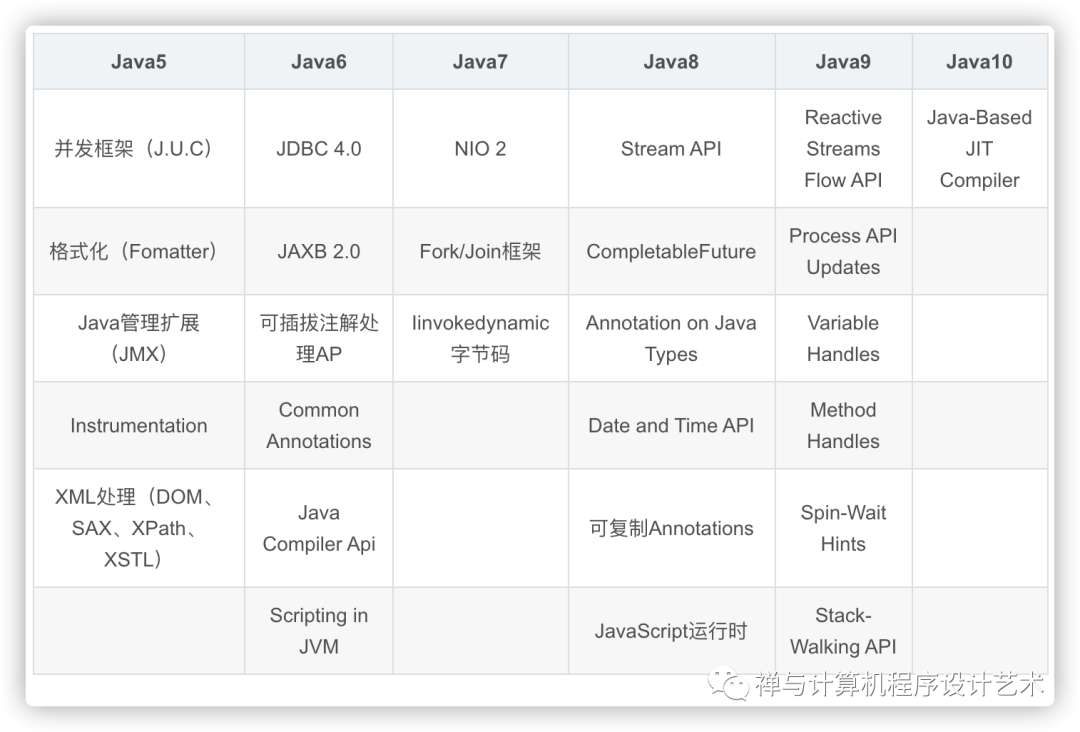
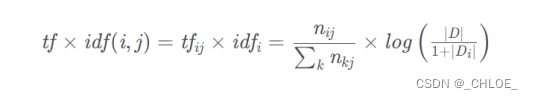文章目录
- 一、项目概述
- 1.项目背景
- 2.环境配置
- 下载ffmpeg
- 设置环境变量
- 二、项目实施
- 1.导入需要的库
- 2.设置请求参数
- 3.基本处理
- 4.下载视频
- 5.视频和音频合并成完整的视频
- 6.3种下载方式的分别实现
- 7.主函数
- 三、项目分析和说明
- 1.结果测试
- 改进说明
- 2.软件打包
- 3.改进分析
- 4.合法性说明
如有需要购买用于个人或公司使用的小伙伴可选择百度云或者华为云服务器,点击华为云服务器优惠链接或扫描下方二维码即可享受采购季优惠价:

一、项目概述
1.项目背景
有一天,我突然想找点事做,想起一直想学但是没有学的C语言,就决定来学一下。
可是怎么学呢?看书的话太无聊,报班学呢又快吃土了没钱,不如去B站看看?
果然,关键字C语言搜索,出现了很多C语言的讲课视频:

B站https://www.bilibili.com/是一个很神奇的地方,简直就是一个无所不有的宝库,几乎可以满足你一切的需求和视觉欲。不管你是想看动画、番剧 ,还是游戏、鬼畜 ,亦或科技和各类教学视频 ,只要你能想到的,基本上都可以在B站找到。对于程序猿或即将成为程序猿的人来说,B站上的编程学习资源是学不完的,可是B站没有提供下载的功能,如果想保存下载在需要的时候看,那就是一个麻烦了。我也遇到了这个问题,于是研究怎么可以实现一键下载视频,最终用Python这门神奇的语言实现了。
2.环境配置
这次项目不需要太多的环境配置,最主要的是有ffmpeg(一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源计算机程序)并设置环境变量就可以了。ffmpeg主要是用于将下载下来的视频和音频进行合并形成完整的视频。
下载ffmpeg
可点击https://download.csdn.net/download/CUFEECR/12234789或进入官网http://ffmpeg.org/download.html进行下载,并解压到你想保存的目录。
设置环境变量
- 复制ffmpeg的bin路径,如
xxx\ffmpeg-20190921-ba24b24-win64-shared\bin - 此电脑右键点击属性,进入控制面板\系统和安全\系统
- 点击高级系统设置→进入系统属性弹窗→点击环境变量→进入环境变量弹窗→选择系统变量下的Path→点击编辑点击→进入编辑环境变量弹窗
- 点击新建→粘贴之前复制的bin路径
- 点击确定,逐步保存退出
动态操作示例如下:

除了ffmpeg,还需要安装pyinstaller库用于程序打包。
可用以下命令进行安装:
pip install pyinstaller
如果遇到安装失败或下载速度较慢,可换源:
pip install pyinstaller -i https://pypi.doubanio.com/simple/
二、项目实施
1.导入需要的库
import json
import os
import re
import shutil
import ssl
import time
import requests
from concurrent.futures import ThreadPoolExecutor
from lxml import etree
导入的库包括用于爬取和解析网页的库,还包括创建线程池的库和进行其他处理的库,大多数都是Python自带的,如有未安装的库,可使用pip install xxx命令进行安装。
2.设置请求参数
# 设置请求头等参数,防止被反爬
headers = {'Accept': '*/*','Accept-Language': 'en-US,en;q=0.5','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36'
}
params = {'from': 'search','seid': '9698329271136034665'
}
设置请求头等参数,减少被反爬的可能。
3.基本处理
def re_video_info(text, pattern):'''利用正则表达式匹配出视频信息并转化成json'''match = re.search(pattern, text)return json.loads(match.group(1))def create_folder(aid):'''创建文件夹'''if not os.path.exists(aid):os.mkdir(aid)def remove_move_file(aid):'''删除和移动文件'''file_list = os.listdir('./')for file in file_list:# 移除临时文件if file.endswith('_video.mp4'):os.remove(file)passelif file.endswith('_audio.mp4'):os.remove(file)pass# 保存最终的视频文件elif file.endswith('.mp4'):if os.path.exists(aid + '/' + file):os.remove(aid + '/' + file)shutil.move(file, aid)
主要包括两方面的基本处理,为正式爬取下载做准备:
- 利用正则表达式提取信息
通过requests库请求得到请求后的网页,属于文本,通过正则表达式提取得到关于将要下载的视频的有用信息,便于后一步处理。 - 文件处理
将下载视频完成后的相关文件进行处理,包括删除生成的临时的音视频分离的文件和移动最终视频文件到指定文件夹。
4.下载视频
def download_video_batch(referer_url, video_url, audio_url, video_name, index):'''批量下载系列视频'''# 更新请求头headers.update({"Referer": referer_url})# 获取文件名short_name = video_name.split('/')[2]print("%d.\t视频下载开始:%s" % (index, short_name))# 下载并保存视频video_content = requests.get(video_url, headers=headers)print('%d.\t%s\t视频大小:' % (index, short_name),round(int(video_content.headers.get('content-length', 0)) / 1024 / 1024, 2), '\tMB')received_video = 0with open('%s_video.mp4' % video_name, 'ab') as output:headers['Range'] = 'bytes=' + str(received_video) + '-'response = requests.get(video_url, headers=headers)output.write(response.content)# 下载并保存音频audio_content = requests.get(audio_url, headers=headers)print('%d.\t%s\t音频大小:' % (index, short_name),round(int(audio_content.headers.get('content-length', 0)) / 1024 / 1024, 2), '\tMB')received_audio = 0with open('%s_audio.mp4' % video_name, 'ab') as output:headers['Range'] = 'bytes=' + str(received_audio) + '-'response = requests.get(audio_url, headers=headers)output.write(response.content)received_audio += len(response.content)return video_name, indexdef download_video_single(referer_url, video_url, audio_url, video_name):'''单个视频下载'''# 更新请求头headers.update({"Referer": referer_url})print("视频下载开始:%s" % video_name)# 下载并保存视频video_content = requests.get(video_url, headers=headers)print('%s\t视频大小:' % video_name, round(int(video_content.headers.get('content-length', 0)) / 1024 / 1024, 2), '\tMB')received_video = 0with open('%s_video.mp4' % video_name, 'ab') as output:headers['Range'] = 'bytes=' + str(received_video) + '-'response = requests.get(video_url, headers=headers)output.write(response.content)# 下载并保存音频audio_content = requests.get(audio_url, headers=headers)print('%s\t音频大小:' % video_name, round(int(audio_content.headers.get('content-length', 0)) / 1024 / 1024, 2), '\tMB')received_audio = 0with open('%s_audio.mp4' % video_name, 'ab') as output:headers['Range'] = 'bytes=' + str(received_audio) + '-'response = requests.get(audio_url, headers=headers)output.write(response.content)received_audio += len(response.content)print("视频下载结束:%s" % video_name)video_audio_merge_single(video_name)
这部分包括系列视频的批量下载和单个视频的下载,两者的大体实现原理近似,但是由于两个函数的参数有差别,因此分别实现。
在具体的实现中,首先更新请求头,请求视频链接并保存视频(无声音),再请求音频链接并保存音频,在这个过程中得到相应的视频和音频文件的大小。
5.视频和音频合并成完整的视频
def video_audio_merge_batch(result):'''使用ffmpeg批量视频音频合并'''video_name = result.result()[0]index = result.result()[1]import subprocessvideo_final = video_name.replace('video', 'video_final')command = 'ffmpeg -i "%s_video.mp4" -i "%s_audio.mp4" -c copy "%s.mp4" -y -loglevel quiet' % (video_name, video_name, video_final)subprocess.Popen(command, shell=True)print("%d.\t视频下载结束:%s" % (index, video_name.split('/')[2]))def video_audio_merge_single(video_name):'''使用ffmpeg单个视频音频合并'''print("视频合成开始:%s" % video_name)import subprocesscommand = 'ffmpeg -i "%s_video.mp4" -i "%s_audio.mp4" -c copy "%s.mp4" -y -loglevel quiet' % (video_name, video_name, video_name)subprocess.Popen(command, shell=True)print("视频合成结束:%s" % video_name)
这个过程也是批量和单个分开,大致原理差不多,都是调用subprogress模块生成子进程,Popen类来执行shell命令,由于已经将ffmpeg加入环境变量,所以shell命令可以直接调用ffmpeg来合并音视频。
6.3种下载方式的分别实现
def batch_download():'''使用多线程批量下载视频'''# 提示输入需要下载的系列视频对应的idaid = input('请输入要下载的视频id(举例:链接https://www.bilibili.com/video/av91748877?p=1中id为91748877),默认为91748877\t')if aid:passelse:aid = '91748877'# 提示选择清晰度quality = input('请选择清晰度(1代表高清,2代表清晰,3代表流畅),默认高清\t')if quality == '2':passelif quality == '3':passelse:quality = '1'acc_quality = int(quality) - 1# ssl模块,处理https请求失败问题,生成证书上下文ssl._create_default_https_context = ssl._create_unverified_context# 获取视频主题url = 'https://www.bilibili.com/video/av{}?p=1'.format(aid)html = etree.HTML(requests.get(url, params=params, headers=headers).text)title = html.xpath('//*[@id="viewbox_report"]/h1/span/text()')[0]print('您即将下载的视频系列是:', title)# 创建临时文件夹create_folder('video')create_folder('video_final')# 定义一个线程池,大小为3pool = ThreadPoolExecutor(3)# 通过api获取视频信息res_json = requests.get('https://api.bilibili.com/x/player/pagelist?aid={}'.format(aid)).json()video_name_list = res_json['data']print('共下载视频{}个'.format(len(video_name_list)))for i, video_content in enumerate(video_name_list):video_name = ('./video/' + video_content['part']).replace(" ", "-")origin_video_url = 'https://www.bilibili.com/video/av{}'.format(aid) + '?p=%d' % (i + 1)# 请求视频,获取信息res = requests.get(origin_video_url, headers=headers)# 解析出视频详情的jsonvideo_info_temp = re_video_info(res.text, '__playinfo__=(.*?)</script><script>')video_info = {}# 获取视频品质quality = video_info_temp['data']['accept_description'][acc_quality]# 获取视频时长video_info['duration'] = video_info_temp['data']['dash']['duration']# 获取视频链接video_url = video_info_temp['data']['dash']['video'][acc_quality]['baseUrl']# 获取音频链接audio_url = video_info_temp['data']['dash']['audio'][acc_quality]['baseUrl']# 计算视频时长video_time = int(video_info.get('duration', 0))video_minute = video_time // 60video_second = video_time % 60print('{}.\t当前视频清晰度为{},时长{}分{}秒'.format(i + 1, quality, video_minute, video_second))# 将任务加入线程池,并在任务完成后回调完成视频音频合并pool.submit(download_video_batch, origin_video_url, video_url, audio_url, video_name, i + 1).add_done_callback(video_audio_merge_batch)pool.shutdown(wait=True)time.sleep(5)# 整理视频信息if os.path.exists(title):shutil.rmtree(title)os.rename('video_final', title)try:shutil.rmtree('video')except:shutil.rmtree('video')def multiple_download():'''批量下载多个独立视频'''# 提示输入所有aidaid_str = input('请输入要下载的所有视频id,id之间用空格分开\n举例:有5个链接https://www.bilibili.com/video/av89592082、https://www.bilibili.com/video/av68716174、https://www.bilibili.com/video/av87216317、\nhttps://www.bilibili.com/video/av83200644和https://www.bilibili.com/video/av88252843,则输入89592082 68716174 87216317 83200644 88252843\n默认为89592082 68716174 87216317 83200644 88252843\t')if aid_str:passelse:aid_str = '89592082 68716174 87216317 83200644 88252843'if os.path.exists(aid_str):shutil.rmtree(aid_str)aids = aid_str.split(' ')# 提示选择视频质量quality = input('请选择清晰度(1代表高清,2代表清晰,3代表流畅),默认高清\t')if quality == '2':passelif quality == '3':passelse:quality = '1'acc_quality = int(quality) - 1# 创建文件夹create_folder(aid_str)# 创建线程池,执行多任务pool = ThreadPoolExecutor(3)for aid in aids:# 将任务加入线程池pool.submit(single_download, aid, acc_quality)pool.shutdown(wait=True)time.sleep(5)# 删除临时文件,移动文件remove_move_file(aid_str)def single_download(aid, acc_quality):'''单个视频实现下载'''# 请求视频链接,获取信息origin_video_url = 'https://www.bilibili.com/video/av' + aidres = requests.get(origin_video_url, headers=headers)html = etree.HTML(res.text)title = html.xpath('//*[@id="viewbox_report"]/h1/span/text()')[0]print('您当前正在下载:', title)video_info_temp = re_video_info(res.text, '__playinfo__=(.*?)</script><script>')video_info = {}# 获取视频质量quality = video_info_temp['data']['accept_description'][acc_quality]# 获取视频时长video_info['duration'] = video_info_temp['data']['dash']['duration']# 获取视频链接video_url = video_info_temp['data']['dash']['video'][acc_quality]['baseUrl']# 获取音频链接audio_url = video_info_temp['data']['dash']['audio'][acc_quality]['baseUrl']# 计算视频时长video_time = int(video_info.get('duration', 0))video_minute = video_time // 60video_second = video_time % 60print('当前视频清晰度为{},时长{}分{}秒'.format(quality, video_minute, video_second))# 调用函数下载保存视频download_video_single(origin_video_url, video_url, audio_url, title)def single_input():'''单个文件下载,获取参数'''# 获取视频aidaid = input('请输入要下载的视频id(举例:链接https://www.bilibili.com/video/av89592082中id为89592082),默认为89592082\t')if aid:passelse:aid = '89592082'# 提示选择视频质量quality = input('请选择清晰度(1代表高清,2代表清晰,3代表流畅),默认高清\t')if quality == '2':passelif quality == '3':passelse:quality = '1'acc_quality = int(quality) - 1# 调用函数进行下载single_download(aid, acc_quality)
在一般情形下,下载的需求包含3种情况:
- 单个视频的下载
只有一个视频,没有和它属于同一个系列的其他视频,如下图

此时,除了右下方的相关推荐中的视频,没有其他视频,右上方只有弹幕列表、没有视频列表。为了代码的复用,将单个视频下载时提示用户输入需求的代码单独提取出来作为single_input(),下载的函数另外作为single_download(aid, acc_quality)函数实现,在该函数中:
通过视频链接如https://www.bilibili.com/video/av89592082解析网页,得到相应的字符串并转化成json,如下:

字符串json格式化可使用https://www.sojson.com/editor.html进行在线转化。
获取到视频的标题、根据输入确定的视频质量、持续时长、视频链接和音频链接,并调用download_video_single()函数下载该视频。 - 多个视频的下载
这里,多个视频之间是没有关系的,多个视频的下载实际上是先获取到所有的aid,并进行循环,对每个视频链接传入参数调用单个视频下载的函数即可。同时设立线程池,大小为3,既不会对资源有太大的要求,也能实现多任务、提高下载效率。 - 系列视频的下载
此时,多个视频属于同一系列,如https://www.bilibili.com/video/av91748877是一个课程系列,如下

显然,此时右上方有视频列表,标明了有65个子视频,每个视频用p标识,如第2个视频就是https://www.bilibili.com/video/av91748877?p=2。对于所有视频,先获取到视频的相关信息,再加入进程池进行下载,并在任务结束之后回调函数video_audio_merge_batch()合并音视频,并进行文件整理。
7.主函数
def main():'''主函数,提示用户进行三种下载模式的选择'''download_choice = input('请输入您需要下载的类型:\n1代表下载单个视频,2代表批量下载系列视频,3代表批量下载多个不同视频,默认下载单个视频\t')# 批量下载系列视频if download_choice == '2':batch_download()# 批量下载多个单个视频elif download_choice == '3':multiple_download()# 下载单个视频else:single_input()if __name__ == '__main__':'''调用主函数'''main()
主函数中实现3种下载方式对应的函数的分别调用。
三、项目分析和说明
1.结果测试
对3种方式进行测试的效果如下:



3种下载情景的测试效果均较好,下载速度也能与一般的下载速度相媲美。
代码可点击https://download.csdn.net/download/CUFEECR/12243122或https://github.com/corleytd/Python_Crawling/blob/master/bilibili_downloader_1.py进行下载。
改进说明
B站网站也一直在变化,所以对于下载可能也会有一些变化,所以将改进的地方在下面列举出来:
- 网址参数变化
举例说明:
这段时间发现B站一个视频系列的链接变成https://www.bilibili.com/video/BV1x7411M74h?p=65,即是无规律的字符串(可能是经过某种算法编码或加密得到的),现在从链接中不能得到视频(系列)的aid,这时候可以借助浏览器工具抓包查看数据来找到该视频的aid,如下:

在左侧寻找stat开头的请求,后边的参数即为aid,该请求api的完整链接为https://api.bilibili.com/x/web-interface/archive/stat?aid=91748877,所以可以直接在该链接中获取aid,也可以查看该请求的具体内容,可以看到第一个数据就是aid,我们也可以看到随机字符串就是bvid,可能是建立了aid和bvid的一一映射,找到aid就可以正常下载了。
2.软件打包
在命令行中,使路径位于代码所在路径运行
pyinstaller bilibili_downloader_1.py
打印
136 INFO: PyInstaller: 3.6
137 INFO: Python: 3.7.4
138 INFO: Platform: Windows-10-10.0.18362-SP0
140 INFO: wrote xxxx\Bili_Video_Batch_Download\bilibili_downloader_1.spec
205 INFO: UPX is not available.
209 INFO: Extending PYTHONPATH with paths
['xxxx\\Bili_Video_Batch_Download','xxxx\\Bili_Video_Batch_Download']
210 INFO: checking Analysis
211 INFO: Building Analysis because Analysis-00.toc is non existent
211 INFO: Initializing module dependency graph...
218 INFO: Caching module graph hooks...
247 INFO: Analyzing base_library.zip ...
5499 INFO: Caching module dependency graph...
5673 INFO: running Analysis Analysis-00.toc
5702 INFO: Adding Microsoft.Windows.Common-Controls to dependent assemblies of final executablerequired by xxx\python\python37\python.exe
6231 INFO: Analyzing xxxx\Bili_Video_Batch_Download\bilibili_downloader_1.py
7237 INFO: Processing pre-safe import module hook urllib3.packages.six.moves
10126 INFO: Processing pre-safe import module hook six.moves
14287 INFO: Processing module hooks...
14288 INFO: Loading module hook "hook-certifi.py"...
14296 INFO: Loading module hook "hook-cryptography.py"...
14936 INFO: Loading module hook "hook-encodings.py"...
15093 INFO: Loading module hook "hook-lxml.etree.py"...
15097 INFO: Loading module hook "hook-pydoc.py"...
15099 INFO: Loading module hook "hook-xml.py"...
15330 INFO: Looking for ctypes DLLs
15334 INFO: Analyzing run-time hooks ...
15339 INFO: Including run-time hook 'pyi_rth_multiprocessing.py'
15344 INFO: Including run-time hook 'pyi_rth_certifi.py'
15355 INFO: Looking for dynamic libraries
15736 INFO: Looking for eggs
15737 INFO: Using Python library xxx\python\python37\python37.dll
15757 INFO: Found binding redirects:
[]
15776 INFO: Warnings written to xxxx\Bili_Video_Batch_Download\build\bilibili_downloader_1\war
n-bilibili_downloader_1.txt
15942 INFO: Graph cross-reference written to xxxx\Bili_Video_Batch_Download\build\bilibili_dow
nloader_1\xref-bilibili_downloader_1.html
15967 INFO: checking PYZ
15968 INFO: Building PYZ because PYZ-00.toc is non existent
15968 INFO: Building PYZ (ZlibArchive) xxxx\Bili_Video_Batch_Download\build\bilibili_downloade
r_1\PYZ-00.pyz
16944 INFO: Building PYZ (ZlibArchive) xxxx\Bili_Video_Batch_Download\build\bilibili_downloade
r_1\PYZ-00.pyz completed successfully.
16980 INFO: checking PKG
16981 INFO: Building PKG because PKG-00.toc is non existent
16981 INFO: Building PKG (CArchive) PKG-00.pkg
17030 INFO: Building PKG (CArchive) PKG-00.pkg completed successfully.
17034 INFO: Bootloader xxx\python\python37\lib\site-packages\PyInstaller\bootloader\Windows-64bit\run.exe
17034 INFO: checking EXE
17035 INFO: Building EXE because EXE-00.toc is non existent
17035 INFO: Building EXE from EXE-00.toc
17037 INFO: Appending archive to EXE xxxx\Bili_Video_Batch_Download\build\bilibili_downloader_
1\bilibili_downloader_1.exe
17046 INFO: Building EXE from EXE-00.toc completed successfully.
17053 INFO: checking COLLECT
17053 INFO: Building COLLECT because COLLECT-00.toc is non existent
17055 INFO: Building COLLECT COLLECT-00.toc
出现INFO: Building EXE from EXE-00.toc completed successfully. 即打包成功。
在当前路径下找到dist或build目录下的bilibili_downloader_1目录下的bilibili_downloader_1.exe,即是打包后的软件。
点击打开即可进行选择和输入,开始下载相应视频。
测试示例如下:

在bilibili_downloader_1.exe的同级目录下可以看到下载保存的视频。
3.改进分析
该项目是小编进行B站视频下载的首次尝试,难免有很多不足,在实现的过程中和后期的总结中,可以看出还存在一些问题:
- 还不能下载B站上的所有视频,目前局限于各种普通视频教程,不能下载直播视频、大会员番剧等,可以在后期进一步优化;
- 代码过于繁琐,有不少功能类似的重复代码,可以进一步简化、提高代码的复用性;
- 没有采取适当的措施应对B站的反爬,可能会因为请求过多而无法正常下载。
可以在后期进行优化,使整个程序更加健壮。
4.合法性说明
- 本项目的出发点是方便地下载B站上的学习视频,可以更好地学习各类教程,这对程序猿来说也是一种福利,但是绝不用与其他商业目的,所有读者可以参考执行思路和程序代码,但不能用于恶意和非法目的(恶意频繁下载视频、非法盈利等),如有违者请自行负责。
- 本项目在实施的过程中可能参考了其他大佬的实现思路,如有侵犯他人利益,请联系更改或删除。
- 本项目是B站视频批量下载系列的第一篇,有很多尚待改进的地方,后期会继续更新,欢迎各位读者交流指正,以期不断改进。