文章目录
- IO流
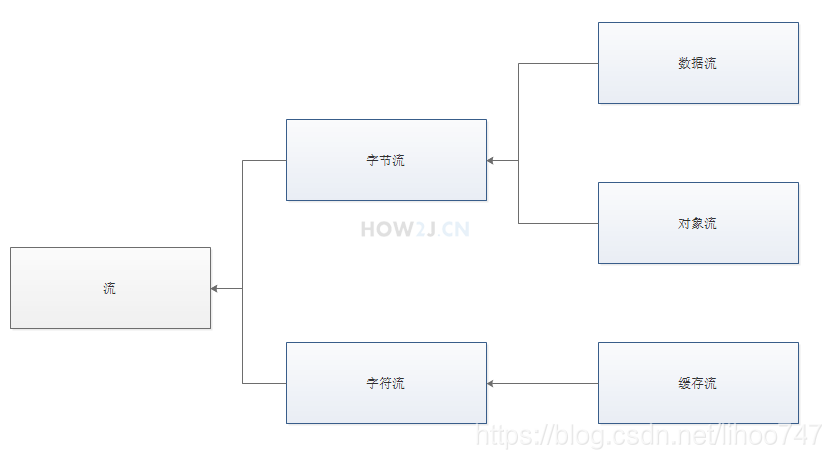
- IO流分类
- FileInputStream
- 输入流框架
- 相对路径
- 读取过程详解
- available()
- skip(long n)
- FileOutputStream
- 输入流框架
- FileReader
- FileWriter
- 文件复制
- FileInputStream 、FileOutputStream
- FileReader 、FileWriter
- 缓冲流
- BufferedReader
- 数据专属流
- DataOutputStream
- DataInputDtream
- 标准输出流
- 日志框架log 输出方向
- File
- 目录拷贝
- 对象流 ObjectOutputStream ObjectInputStream
- IO、Properties
IO流

IO流分类
- 以内存为参照物
- 往内存中去,输入流,读
- 从内存中出,输出流,写 - 读取方式不同
- 按照字节读取数据,一次读取一个字节byte,相当于8个二进制位。这类流的读取方式是万能的,什么类型的文件都可以读取:文本文件、图片、声音文件、视频
- 按照字符读取数据,一次读取一个字符,这种流是为了方便读取普通文本而存在的。这种流不能读取图片、声音、视频等文件,只能读取纯文本文件【word文档不可以,因为word有格式】
例:txt文件的内容:o中国o
【在Windows系统中:字母占一个字节、汉字占两个字节】 按照字节流读取:第一次:读取“o”;第二次:读取“中”字符的一半;第三次:读取“中”字符的另外一半。 按照字符流读取:第一次:读取“o”;第二次读取字符“中”。
-
四大家族:以“Stream”结尾的都是字节流;以“reader”“writer”结尾的都是字符流
-
所有的流都实现了Java.io.Closeable接口,都有close()方法。流毕竟是一个管道,联通内存与硬盘,用完之后一定要关闭。
- InputStream 字节输入流
- OutputStream 字节输出流
- Reader 字符输入流
- Writer 字符输出流
-
所有的输出流都是可刷新的,都有flush()方法。实现了java.io.Flushable接口。输出流在最终输出之后,一定记得flush()刷新,这个刷新表示管道当中剩余的数据强行输出完(清空管道),刷新的作用就是清空管道。


FileInputStream
输入流框架

package Advance.io;import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;/*** java.io.FileInputStream:* 文件字节输入流,万能* 构建输入流框架* */
public class FileInputStreamTest01 {public static void main(String[] args) {//创建字节输入流对象//文件路径:E:\Javatest 里面有一个temp.txt文档//编译器会自动把 \ 变成 \\ ,因为java中 \ 表示转义//FileInputStream fis = new FileInputStream("E:\\Javatest\\temp.txt"); //处理异常/* //处理异常try {FileInputStream fis = new FileInputStream("E:\\Javatest\\temp.txt");} catch (FileNotFoundException e) {// TODO Auto-generated catch blocke.printStackTrace();}*///关闭流:无论程序执行如何,最后程序都需要关闭——finally//将创建的流放到try,catch语句块外面FileInputStream fis = null;try { fis = new FileInputStream("E:\\Javatest\\temp.txt");//读取信息int readData = fis.read(); //该方法是读取到的字节 读取到的字节本身 a的ASCII码System.out.println(readData); //读取该文档的第一个字节} catch (FileNotFoundException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (IOException e) { //处理读取信息时的异常// TODO Auto-generated catch blocke.printStackTrace();}finally {//finally语句块可以确保流一定关闭if(fis!=null) { //关闭流的前提是:流不为空 :避免空指针异常try {fis.close();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}}}
}相对路径
- 相对路径是从当前所在位置开始作为起点开始找。
- 编译器的默认当前路径:工程Project是当前的根


读取过程详解

package Advance.io;import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;public class FileInputStreamTest03 {public static void main(String[] args) {//创建字节流//处理异常//关闭流FileInputStream fis =null;try {//设置相对路径 :相对路径是从当前所在位置开始作为起点开始找//编译器的默认当前路径:工程Project是当前的根fis = new FileInputStream("src/source/temp.txt");//读取信息: 采用byte数组 一次读取多个字节 最多读取数组.length个字节/** byte[] bytes = new byte[4]; //一次最多读取4个字节* int readCount = fis.read(bytes); //读取到的字节数量,不是字节本身System.out.println("第一次读取到的字节数——"+readCount); //4//此时内存的byte数组里面存有数据,转为String类型//String(bytes);System.out.println(new String(bytes)); //abcdreadCount = fis.read(bytes);System.out.println("第二次读取到的字节数——"+readCount); //2System.out.println(new String(bytes)); //efcd//程序期望输出整个文件内容//byte数组转String,从下标0开始,到下标readCount结束System.out.println(new String(bytes,0,readCount)); readCount = fis.read(bytes);System.out.println("第三次读取到的字节数——"+readCount); //-1System.out.println(new String(bytes,0,readCount)); //没有内容*///读取信息: 采用byte数组 一次读取多个字节 最多读取数组.length个字节byte[] bytes = new byte[4]; //一次最多读取4个字节int readCount =0;while((readCount =fis.read(bytes))!=-1) {System.out.print(new String(bytes,0,readCount));}} catch (FileNotFoundException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}finally {if(fis !=null) { //流不为空,避免空指针异常try {fis.close();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}}}
}
available()
- int available(); 返回流当中剩余没有读到的字节数量
- 当数据没有读取的时候,调用该方法,获得的是总字节数量,那么在建立byte数组时,可以设置数组长度来匹配文件字节数。但是这种方法不适合大的文件,因为byte数组不能太大。
package Advance.io;import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;/** FileInputStream其他的常用方法* int available(); 返回流当中剩余没有读到的字节数量* long skip(long n); 跳过几个字节不读* * */
public class FileInputStreamTest04 {public static void main(String[] args) {//创建流//处理异常//关闭流FileInputStream fis =null;try {fis = new FileInputStream("src/source/temp.txt");System.out.println("总字节数——"+fis.available());//读取信息 //读取一个字节int readByte = fis.read();//剩余多少字节System.out.println("剩下字节数——"+fis.available());} catch (FileNotFoundException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}finally {if(fis!=null) {try {fis.close();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}}}
}skip(long n)
- long skip(long n); 跳过几个字节不读
FileOutputStream
- 文件字节输出流,负责写数据
输入流框架

- 在文件中写入字符串时,使用到字符串转byte方法:getBytes();

- 在java编译器相对路径写入信息时,如果指定的文件不存在,系统会先新建一个文件,再进行写入。当写在根目录下时,发现目录栏没有新建该文件,此时刷新一下就可以。

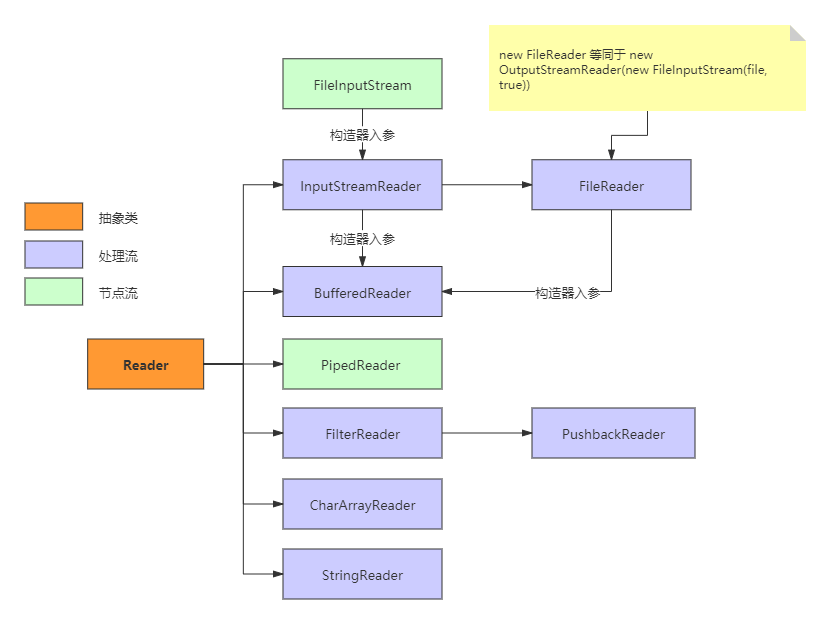
FileReader
- 文件字符输入流:只能读取普通文本
- 读取文本时,比较方便、快捷
- FileReader使用的是char数组
package Advance.io;import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;public class FileReaderTest01 {public static void main(String[] args) {//创建字符流FileReader fr = null;try {fr= new FileReader("src/source/tempChar.txt");//读取信息char[] c = new char[4]; //一次读取4个字符int readCount =0;while((readCount=fr.read(c))!=-1) {//下面两行代码,输出结果一致。笔者没有弄懂//按理来说,如果最后一个数组存入的数据不满数组的长度,那么readCount 到之后的数组//之内存储的应该是上一次数组存储的元素//那么,输出c时,上一次的数组元素依旧会输出;但是输出从0到readcount的长度的数组则不会//但是这两行代码输出结果一样System.out.print(c);//System.out.print(new String(c,0,readCount));}} catch (FileNotFoundException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();} finally {//关闭流if(fr !=null) {try {fr.close();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}}}
}FileWriter
- 字符输出流
- 在FileOutputStream中,写信息时,需要进行String转换为byte类型,再将byte数组写进去。而在FileWriter中的writer方法可以直接接收字符串,方便程序的写入

文件复制
- 文件复制原理:想让文件从D盘移到C盘,需要利用内存作中介,内存一边从D盘读取,一边从C盘写出。

FileInputStream 、FileOutputStream

package Advance.io;import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;//使用FileInputStream和FlieOutputStream完成文件的拷贝//拷贝的过程是一边读,一边写
public class Copy01 {public static void main(String[] args) {//创建流FileInputStream fis = null;FileOutputStream fos =null;//处理异常try {fis = new FileInputStream("H:\\temp.txt");fos= new FileOutputStream("E:\\temp.txt");//核心:边读边写byte[] bytes =new byte[1024*1024]; //1mb 一次最多拷贝1MBint readCount = 0;while((readCount=fis.read(bytes))!=-1) {fos.write(bytes,0,readCount);}//刷新fos.flush();} catch (FileNotFoundException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}finally {//分开处理异常//一起处理,当一个异常,会影响另外一个关闭if(fis!=null) {try {fis.close();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}if(fos!=null) {try {fos.close();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}}}
}FileReader 、FileWriter
package Advance.io;import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;/** 使用FileReader、FileWriter进行拷贝* */
public class Copy02 {public static void main(String[] args) {//建立FileReader fr = null;FileWriter fw = null;try {fr =new FileReader("H:\\tempChar.txt");fw= new FileWriter("E:\\tempChar.txt");//复制int readCount =0;char[] c = new char[1024*512]; //char是两个字节 1MBwhile((readCount =fr.read(c))!=-1 ){fw.write(c,0,readCount);}//刷新fw.flush();} catch (FileNotFoundException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}finally {if(fr!=null) {try {fr.close();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}if(fw!=null) {try {fw.close();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}} }
}缓冲流
BufferedReader
- 带有缓冲区的字符输入流
- 使用这个流的时候不需要自定义char数组、byte数组。自带缓冲
- 由于Buffered构造方法需要传入一个reader类型的参数,所以在创建Buffered时候,需要创建一个reader类型的参数,传入是参数对应的流属于结点流。当需要Buffered处理非Reader类型的数据时,需要采用格式转换,转换为reader类型的数据,再传入Buffered。
- BufferReader优点:
- 读取一行文字:readLine();


- 读取一行文字:readLine();
package Advance.io;import java.io.*;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.InputStreamReader;public class BufferedReaderTest01 {public static void main(String[] args) throws Exception {FileReader reader =new FileReader("src/Advance/io/Copy02.java");//当一个流的构造方法需要一个流,那么传入的这个流称为节点流//外部负责包装的流:包装流、处理流//FileReader:节点流 ; BufferedReader :处理流。BufferedReader br = new BufferedReader(reader);//读取信息//使用readLine 读取一行信息String s =null;while((s=br.readLine())!=null) {System.out.println(s);}//关闭流//对应包装流来说,只需要关闭最外层的流就可以,里面的结点流会自动关闭br.close();System.out.println("===============================");//BUfferReader需要传入一个Reader类型的参数//当需要传入的数据属于字节流时,需要使用转换FileInputStream fis = new FileInputStream("src/Advance/io/Copy01.java");//转换类型InputStreamReader isr= new InputStreamReader(fis);BufferedReader bfr = new BufferedReader(isr);//读取信息......bfr.close();}
}数据专属流
DataOutputStream
- 这个流可以将数据连同数据类型一并写入文件。该文件不是普通文档,使用记事本打不开。

DataInputDtream
- DataOutputStream写入的文件,只能使用DataInputDtream读取,并且读取的时候需要提前知道写入的顺序。读的顺序需要和写的顺序一致,才能正常的取出数据。加密!!

标准输出流

日志框架log 输出方向
package Advance.io;import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.PrintStream;public class PrintStreamTest01 {public static void main(String[] args) throws Exception {PrintStream ps =System.out;ps.print("hello world!");//标准输出流不需要手动关闭/*** System类使用过的方法* System.gc(); 运行垃圾回收器。* System.currentTimeMillis() 返回以毫秒为单位的当前时间。* System.exit(status); 终止当前正在运行的 Java 虚拟机。* System.arraycopy(src, srcPos, dest, destPos, length); 从指定源数组中复制一个数组,复制从指定的位置开始,到目标数组的指定位置结束。* * *///标准输出流更改输出方向//标准输出流不再指向控制台,指向log文件PrintStream printStream = new PrintStream(new FileOutputStream("log"));//修改输出方向,输出方向修改为log文件System.setOut(printStream); //重新分配“标准”输出流。System.out.println("hello world");System.out.println("hello java");}
}File
- File :文件和目录路径名的抽象表达形式。
- 一个File可能对应的是目录,也可能对应的是文件
- File类和四大家族没有关系,所以File类不能完成文件的读和写
- File常用方法:
- File(String pathname) 构造方法: 通过将给定路径名字符串转换为抽象路径名来创建一个新 File 实例。
- boolean exists() 测试此抽象路径名表示的文件或目录是否存在。
- String getAbsolutePath() 返回此抽象路径名的绝对路径名字符串。
- String getParent() 返回此抽象路径名父目录的路径名字符串;如果此路径名没有指定父目录,则返回 null。
- File getParentFile() 返回此抽象路径名父目录的抽象路径名;如果此路径名没有指定父目录,则返回 null。
- String getName() 返回由此抽象路径名表示的文件或目录的名称。
- File[] listFiles() 返回一个抽象路径名数组,这些路径名表示此抽象路径名表示的目录中的文件。
import java.io.File;public class FileTest01 {public static void main(String[] args) throws Exception{//创建一个File对象File f1 = new File("E:\\Javatest\\file");//判断指定file是否存在System.out.println(f1.exists());//如果指定file不存在,if(!f1.exists()) {//以文件的形式创建出来//f1.createNewFile();//以目录形式创建出来f1.mkdir();}File f2 = new File("h:\\file");//获取文件的父路径String parentPath = f2.getParent();System.out.println(parentPath);//获取绝对路径System.out.println("获取的绝对路径——"+f2.getParentFile().getAbsolutePath());//获得文件名System.out.println("文件名"+f1.getName());//判断file是否是一个目录System.out.println(f1.isDirectory());//判断file是否是一个文件System.out.println(f1.isFile());//获得文件最后一次修改时间long haomiao = f1.lastModified(); //毫秒是从1970年到现在的总时间//转换日期Date time = new Date(haomiao);//日期格式话SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss SSS");String strtime = sdf.format(time);System.out.println(strtime);//获取文件大小System.out.println(f1.length());//获取当前目录下的所有子文件File[] files = f1.listFiles();for(File f :files) {System.out.println(f);}}
}目录拷贝

package homework;import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;/*** 将E:\Javatest文件夹的东西拷贝到H盘* FileInputStream * FileOutputDtream* File* */public class FileCopy {public static void main(String[] args) {//拷贝源File srcFile = new File("E:\\Javatest\\file");//拷贝目标File desFile = new File("H:\\"); //调用方法拷贝copyDir(srcFile,desFile);}/*** 拷贝目录方法* @param srcFile :拷贝源* @param desFile :拷贝目标*/private static void copyDir(File srcFile, File desFile) {//递归停止条件:如果是文件的话,递归结束if(srcFile.isFile()) {//确定是文件,进行拷贝:但是拷贝时是递归到了最后一层,将文件拷贝到其他盘时//也需要建立对应的路径//建立完路径之后,相当于在目的准备好了房子 ,下一步就是搬文件//FileInputStream FileOutputStreamFileInputStream fs =null;FileOutputStream fos =null;try {fs =new FileInputStream(srcFile);//System.out.println("========"+desFile.getAbsolutePath()+srcFile.getAbsolutePath().substring(12));fos= new FileOutputStream(desFile.getAbsolutePath()+srcFile.getAbsolutePath().substring(12));//拷贝int readCount =0;byte[] bytes = new byte[1024*1024];while((readCount=fs.read(bytes))!=-1) {fos.write(bytes,0,readCount);}//刷新fos.flush();} catch (FileNotFoundException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}finally {if(fs!=null) {try {fs.close();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}if(fos!=null) {try {fos.close();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}}return;}//获取源下面的子目录File[] srcFiles = srcFile.listFiles();//System.out.println(srcFiles.length);for(File f : srcFiles) { //取出源文件夹中的子文件 //如果File是文件夹的话,在目标目录新建对应目录if(f.isDirectory()) {//System.out.println("获取文件的绝对路径——"+f.getAbsoluteFile());// E:\Javatest\file\a 源目录// H:\file 目标目录//实际上,拷贝就是将目标文件夹放到目标地,那么拷贝完成后//新的拷贝后的路径,就是目标地+目标文件String srcDir = f.getAbsolutePath();//System.out.println(srcDir.substring(12)); //file\a 截取字符String desDir =desFile.getAbsolutePath()+srcDir.substring(12);System.out.println(desDir);//新建File newFile = new File(desDir);if(!newFile.exists()) {newFile.mkdirs();}}//递归copyDir(f,desFile);}}
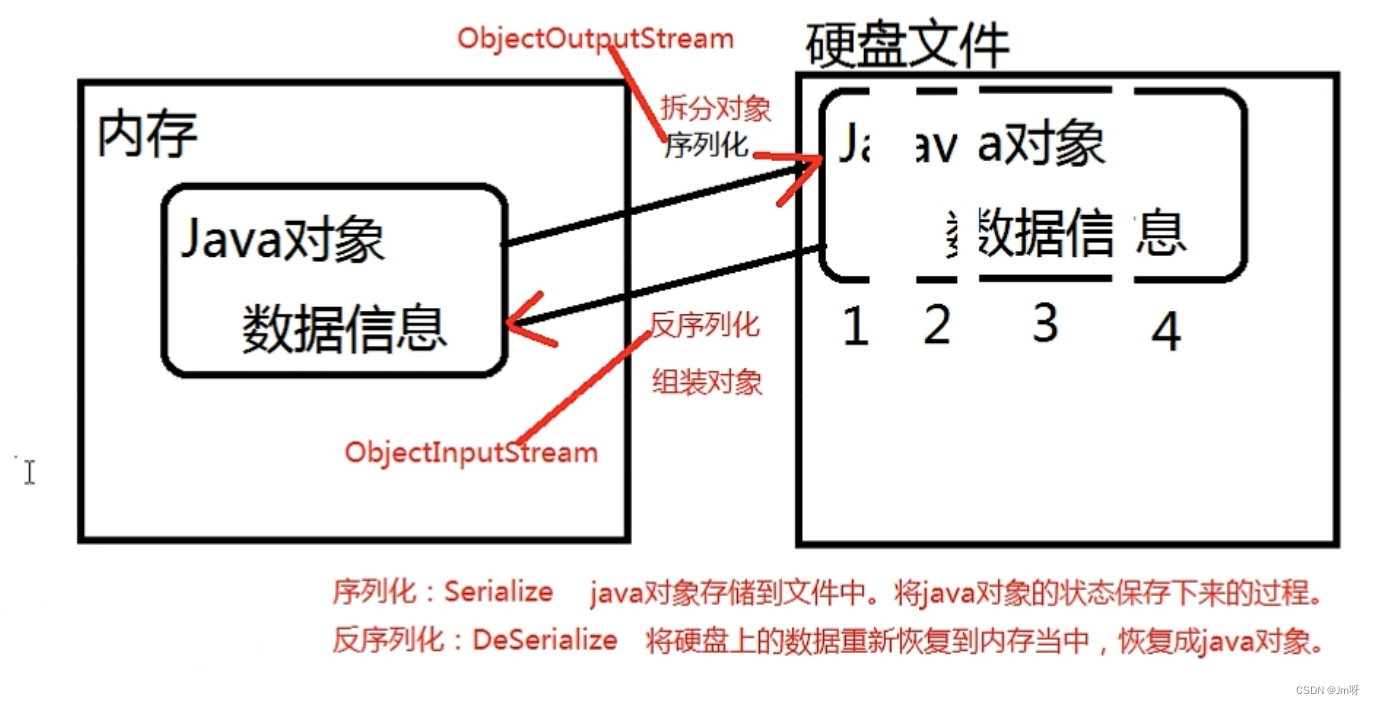
}对象流 ObjectOutputStream ObjectInputStream
- 对象的序列化 反序列化 。
- 参与序列化和反序列化的对象必须实现Serializable接口。否则出现NotSerializableException异常。Serializable接口只是一个标志接口,这个接口没有代码,起到了标识作用,java虚拟机看到这个类实现了这个接口之后,会为该类自动生成一个序列化版本号。


package Advance.io.bean;import java.io.FileInputStream;
import java.io.ObjectInputStream;public class ObjectOutputStreamTest02 {public static void main(String[] args) throws Exception{ObjectInputStream ois = new ObjectInputStream(new FileInputStream("src/source/students"));//反序列化 读Object obj = ois.readObject();//反序列化一个学生对象,调用学生对象的toString方法System.out.println(obj);ois.close();}
}- 当存储多个对象反序列话、序列话时,可以使用集合。
- 当对于对象的某个属性,不希望它序列化、反序列化时,添加transient关键字


- 在序列化一次之后【字节码文件】,再次对代码进行修改【生成新的字节码文件】,反序列化会出现异常——序列化版本号的作用!
- 优点: java语言中进行类的区分时,先根据类名进行区分,如果类名一样,再依靠序列化版本号进行区分。——不同的开发人员编写的类名一致时、内容不同时,这时序列化版本号就发挥作用了,对于java虚拟机来说,当两个类都实现了Serialiable接口后,就具备了默认的版本号,两个同名类的版本号不一致,就可以区分出来。
- 缺陷:自动化生成版本号,一旦代码确定生成版本号,不可更改。一旦修改,必定会重新编译,此时生成全新的序列化版本号,java虚拟机会认为是一个全新的类。
- 最终建议:序列化版本号手写赋值,不建议自动生成

IO、Properties
- Io文件的读和写;Properties是一个map集合,Key和Value都是String类型,key重复时,会异常报错;不要写中文。
- 当value对应的是类的路径是,采用点,而不是反斜杠。
- 无需更改代码就可以获得动态信息。在编程时,经常更改的数据,可以单独写到一个文档中,使用程序动态读取,将来只需要更改这个文件的内容,java代码不需要更改,不需要重写编译,服务器也不需要重启,就可以拿到动态信息。类似于以上机制的文件被称为配置文件。

配置文件的格式为:key=valuekey=value这种配置文件被称为属性配置文件。
java中规范要求:属性配置文件建议以properties结尾,非强制要求。
在属性配置文件中,key重复时,会异常报错;使用“#”进行注释